

Жадаю падзяліцца з вамі маім першым паспяховым досведам аднаўлення поўнай працаздольнасці базы дадзеных Postgres.

Я працую паў-DevOps інжынерам у буйной IT-кампаніі. Наша кампанія займаецца распрацоўкай праграмнага забеспячэння для высоканагружаных сэрвісаў, я ж адказваю за працаздольнасць, суправаджэнне і дэплой. Перада мной паставілі стандартную задачу: абнавіць дадатак на адным серверы. Прыкладанне напісана на Django, падчас абнаўлення выконваюцца міграцыі (змена структуры базы дадзеных), і перад гэтым працэсам мы здымаем поўны дамп базы дадзеных праз стандартную праграму pg_dump на ўсялякі выпадак.
Падчас зняцця дампа ўзнікла непрадбачаная памылка (версія Postgres - 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed.
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
pg_dump: The command was: COPY public.ws_log_smevlog [...]
pg_dunp: [parallel archtver] a worker process dled unexpectedly Памылка "invalid page in block" кажа аб праблемах на ўзроўні файлавай сістэмы, што вельмі нядобра. На розных форумах прапаноўвалі зрабіць FULL VACUUM з опцыяй zero_damaged_pages для вырашэння дадзенай праблемы.
Падрыхтоўка да аднаўлення
УВАГА! Абавязкова зрабіце рэзервовую копію Postgres перад любой спробай аднавіць базу даных. Калі ў вас віртуальная машына, спыніце базу дадзеных і зрабіце снэпшот. Калі няма магчымасці зрабіць снэпшот, спыніце базу і скапіруйце змесціва каталога Postgres (уключаючы wal-файлы) у надзейнае месца. Галоўнае ў нашай справе - не зрабіць горш. Прачытайце .
Паколькі ў цэлым база ў мяне працавала, я абмежаваўся звычайным дампам базы дадзеных, але выключыў табліцу з пашкоджанымі дадзенымі (опцыя -T, -exclude-table=TABLE у pg_dump).
Сервер быў фізічным, зняць снэпшот было немагчыма. Бекап зняты, рухаемся далей.
Праверка файлавай сістэмы
Перад спробай узнаўлення базы дадзеных неабходна пераканацца, што ў нас усё ў парадку з самай файлавай сістэмай. І ў выпадку памылак выправіць іх, паколькі ў адваротным выпадку можна зрабіць толькі горш.
У маім выпадку файлавая сістэма з базай дадзеных была прымантаваная ў "/srv" і тып быў ext4.
Спыняем базу дадзеных: systemctl stop postgresql@9.5-main.service і правяраем, што файлавая сістэма нікім не выкарыстоўваецца і яе можна адмантаваць з дапамогай каманды таксама:
lsof +D /srv
Мне прыйшлося яшчэ спыніць базу дадзеных redis, бо яна таксама выкарыстоўвалася. "/srv". Далей я адмантаваў / срв (umount).
Праверка файлавай сістэмы была выканана з дапамогай утыліты e2fsck з ключыкам -f (Force checking even if filesystem is marked clean):
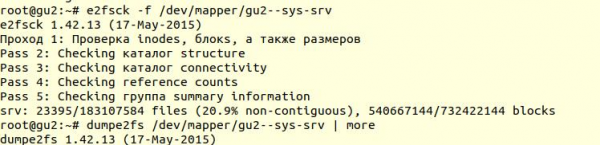
Далей з дапамогай утыліты dumpe2fs (sudo dumpe2fs /dev/mapper/gu2-sys-srv | grep checked) можна пераканацца, што праверка сапраўды была праведзена:

e2fsck кажа, што праблем на ўзроўні файлавай сістэмы ext4 не знойдзена, а гэта значыць, што можна працягваць спробы аднавіць базу дадзеных, а дакладней вярнуцца да vacuum full (само сабой, неабходна прымантаваць файлавую сістэму назад і запусціць базу дадзеных).
Калі ў вас сервер фізічны, то абавязкова праверце стан дыскаў (праз smartctl -a /dev/XXX) альбо RAID-кантролера, каб пераканацца, што праблема не на апаратным узроўні. У маім выпадку RAID апынуўся "жалезны", таму я папытаў мясцовага адміна праверыць стан RAID (сервер быў у некалькіх сотнях кіламетраў ад мяне). Ён сказаў, што памылак няма, а гэта значыць, што мы сапраўды можам пачаць аднаўленне.
Спроба 1: zero_damaged_pages
Падлучаемся да базы праз psql акаўнтам, якія валодаюць правамі суперкарыстача. Нам патрэбен менавіта суперкарыстач, т.я. опцыю zero_damaged_pages можа мяняць толькі ён. У маім выпадку гэта postgres:
psql -h 127.0.0.1 -U postgres -s [database_name]
опцыя zero_damaged_pages патрэбна для таго, каб праігнараваць памылкі чытання (з сайта postgrespro):
Пры выяўленні пашкоджанага загалоўка старонкі Postgres Pro звычайна паведамляе пра памылку і перарывае бягучую транзакцыю. Калі параметр zero_damaged_pages уключаны, замест гэтага сістэма выдае папярэджанне, абнуляе пашкоджаную старонку ў памяці і працягвае апрацоўку. Гэтыя паводзіны разбураюць дадзеныя, а менавіта ўсе радкі ў пашкоджанай старонцы.
Уключаем опцыю і спрабуем рабіць full vacuum табліцы:
VACUUM FULL VERBOSE 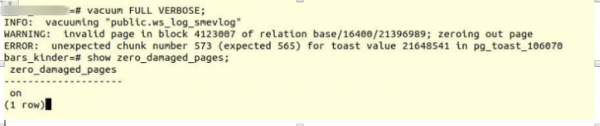
Нажаль, няўдача.
Мы сутыкнуліся з аналагічнай памылкай:
INFO: vacuuming "“public.ws_log_smevlog”
WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page
ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070– механізм захоўвання "доўгіх дадзеных" у Poetgres, калі яны не змяшчаюцца ў адну старонку (па змаўчанні 8кб).
Спроба 2: reindex
Першая рада з гугла не дапамог. Пасля некалькіх хвілін пошуку я знайшоў другую раду - зрабіць. reindex пашкоджанай табліцы. Гэтая рада я сустракаў у шматлікіх месцах, але ён не выклікаў даверу.
reindex table ws_log_smevlog 
reindex завяршыўся без праблем.
Аднак гэта не дапамагло, VACUUM FULL аварыйна завяршаўся з аналагічнай памылкай. Паколькі я абвык да няўдач, я стаў шукаць парад у інтэрнэце далей і натыкнуўся на даволі цікавую. .
Спроба 3: SELECT, LIMIT, OFFSET
У артыкуле вышэй прапаноўвалі паглядзець табліцу парадкова і выдаліць праблемныя дадзеныя. Для пачатку неабходна было прагледзець усе радкі:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; doneУ маім выпадку табліца змяшчала 1 628 991 радкоў! Па-добраму неабходна было паклапаціцца аб , Але гэта тэма для асобнага абмеркавання. Была субота, я запусціў вось гэтую каманду ў tmux і пайшоў спаць:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; doneДа раніцы я вырашыў праверыць, як ідуць справы. На маё здзіўленне, я выявіў, што за 20 гадзін было прасканавана толькі 2% дадзеных! Чакаць 50 дзён я не хацеў. Чарговы поўны правал.
Але я не стаў здавацца. Мне стала цікава, чаму ж сканіраванне ішло так доўга. З дакументацыі (зноў на postgrespro) я даведаўся:
OFFSET паказвае прапусціць паказаны лік радкоў, перш чым пачаць выдаваць радкі.
Калі пазначана і OFFSET, і LIMIT, спачатку сістэма прапускае OFFSET радкоў, а затым пачынае падлічваць радкі для абмежавання LIMIT.Ужываючы LIMIT, важна выкарыстоўваць таксама прапанову ORDER BY, каб радкі выніку выдаваліся ў вызначаным парадку. Інакш будуць вяртацца непрадказальныя падмноствы радкоў.
Відавочна, што вышэйнапісаная каманда была памылковай: па-першае, не было order by, вынік мог атрымацца памылковым. Па-другое, Postgres спачатку павінен быў прасканаваць і прапусціць OFFSET-радок, і з узрастаннем OFFSET прадукцыйнасць зніжалася б яшчэ мацней.
Спроба 4: зняць дамп у тэкставым выглядзе
Далей мне ў галаву прыйшла, здавалася б, геніяльная ідэя: зняць дамп у тэкставым выглядзе і прааналізаваць апошні запісаны радок.
Але для пачатку, азнаёмімся са структурай табліцы ws_log_smevlog:
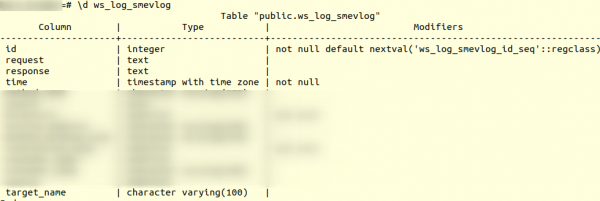
У нашым выпадку ў нас ёсць слупок "Ідэнтыфікатар", які змяшчаў унікальны ідэнтыфікатар (лічыльнік) радка. План быў такі:
- Пачынаем здымаць дамп у тэкставым выглядзе (у выглядзе sql-каманд)
- У пэўны момант часу зняцця дампа б перапынілася з-за памылкі, але тэктавы файл усё роўна захаваўся б на дыску
- Глядзім канец тэкставага файла, тым самым мы знаходзім ідэнтыфікатар (id) апошняга радка, які зняўся паспяхова
Я пачаў здымаць дамп у тэкставым выглядзе:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dumpЗняцце дампа, як і чакалася, перапыніўся з той жа самай памылкай:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 Далей праз хвост я прагледзеў канец дампа (tail -5 ./my_dump.dump) выявіў, што дамп перапыніўся на радку з id 186 525. «Значыць, праблема ў радку з id 186 526, яна бітая, яе і трэба выдаліць!» Але, зрабіўшы запыт у базу дадзеных:
«select * from ws_log_smevlog where id=186529» выявілася, што з гэтым радком усё нармальна ... Радкі з індэксамі 186 - 530 таксама працавалі без праблем. Чарговая "геніяльная ідэя" правалілася. Пазней я зразумеў, чаму так адбылося: пры выдаленнізмене дадзеных з табліцы яны не выдаляюцца фізічна, а пазначаюцца як «мёртвыя картэжы», далей прыходзіць autovacuum і пазначае гэтыя радкі выдаленымі і дазваляе выкарыстоўваць гэтыя радкі паўторна. Для разумеючы, калі дадзеныя ў табліцы мяняюцца і ўключаны autovacuum, то яны не захоўваюцца паслядоўна.
Спроба 5: SELECT, FROM, WHERE id=
Няўдачы робяць нас мацнейшымі. Не варта ніколі здавацца, трэба ісці да канца і верыць у сябе і свае магчымасці. Таму я вырашыў паспрабаваць яшчэ адзін варыянт: проста прагледзець усе запісы ў базе дадзеных па адным. Ведаючы структуру маёй табліцы (гл. вышэй), у нас ёсць поле id, якое з'яўляецца унікальным (першасным ключом). У табліцы ў нас 1 628 991 радкоў і id ідуць па парадку, а гэта значыць, што мы можам проста перапыніць іх па адным:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneКалі хто не разумее, каманда працуе наступным чынам: праглядае парадкова табліцу і адпраўляе stdout у / DEV / нуль, але калі каманда SELECT правальваецца, то выводзіцца тэкст памылкі (stderr адпраўляецца ў кансоль) і выводзіцца радок, утрымоўвальная памылку (дзякуючы ||, які азначае, што ў select узніклі праблемы (код звароту каманды не 0)).
Мне пашанцавала, у мяне былі створаны індэксы па полі id:

А гэта значыць, што знаходжанне радка з патрэбным id не павінен займаць шмат часу. У тэорыі павінна спрацаваць. Што ж, запускаем каманду ў tmux і ідзем спаць.
Да раніцы я выявіў, што прагледжана каля 90 000 запісаў, што складае крыху больш за 5%. Выдатны вынік, калі параўноўваць з папярэднім спосабам (2%)! Але чакаць 20 дзён не хацелася…
Спроба 6: SELECT, FROM, WHERE id >= and id
У заказчыка пад БД быў выдзелены выдатны сервер: двухпрацэсарны Intel Xeon E5-2697 v2, у нашым размяшчэнні было цэлых 48 патокаў! Нагрузка на серверы была сярэдняя, мы без асаблівых праблем маглі забраць каля 20 патокаў. Аператыўнай памяці таксама было дастаткова: аж 384 гігабайт!
Таму каманду трэба было распаралеліць:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneТут можна было напісаць прыгожы і элегантны скрыпт, але я абраў найболей хуткі спосаб распаралельвання: разбіць дыяпазон 0-1628991 уручную на інтэрвалы па 100 000 запісаў і запусціць асобна 16 каманд выгляду:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneАле гэта не ўсё. Па ідэі, падлучэнне да базы дадзеных таксама адымае нейкі час і сістэмныя рэсурсы. Падключаць 1 было не вельмі разумна, пагадзіцеся. Таму давайце пры адным падключэнні здабываць 628 радкоў замест адной. У выніку каманда змянілася ў гэта:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; doneАдкрываем 16 вокнаў у сесіі tmux і запускаем каманды:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Праз дзень я атрымаў першыя вынікі! А менавіта (значэнні XXX і ZZZ ужо не захаваліся):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070
146000Гэта значыць, што ў нас тры радкі змяшчаюць памылку. id першага і другога праблемнага запісу знаходзіліся паміж 829 000 і 830 000, id трэцім - паміж 146 000 і 147 000. Далей нам трэба было проста знайсці дакладнае значэнне id праблемных запісаў. Для гэтага праглядаем наш дыяпазон з праблемнымі запісамі з крокам 1 і ідэнтыфікуем id:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
шчаслівы фінал
Мы знайшлі праблемныя радкі. Заходзім у базу праз psql і спрабуем іх выдаліць:
my_database=# delete from ws_log_smevlog where id=829417;
DELETE 1
my_database=# delete from ws_log_smevlog where id=829449;
DELETE 1
my_database=# delete from ws_log_smevlog where id=146911;
DELETE 1Да майго здзіўлення, запісы выдаліліся без якіх-небудзь праблем нават без опцыі zero_damaged_pages.
Затым я падключыўся да базы, зрабіў VACUUM FULL (думаю рабіць было неабавязкова), і, нарэшце, паспяхова зняў бекап з дапамогай pg_dump. Дамп зняўся без якіх-небудзь памылак! Праблему ўдалося вырашыць такім вось тупейшым спосабам. Радасці не было мяжы, пасля столькіх няўдач удалося знайсці рашэнне!
Падзякі і заключэнне
Вось такі атрымаўся мой першы досвед аднаўлення рэальнай базы дадзеных Postgres. Гэты досвед я запомню надоўга.
Ну і напрыканцы, хацеў бы сказаць дзякуй кампаніі PostgresPro за перакладзеную дакументацыю на рускую мову і за , якія вельмі моцна дапамаглі падчас аналізу праблемы.
Крыніца: habr.com
