

Гэта артыкул пераклад майго артыкула на medium , якая аказалася даволі папулярнай, напэўна з-за сваёй прастаты. Таму я вырашыў напісаць яе на рускай мове і крыху дапоўніць, каб простаму чалавеку, які не з'яўляецца спецыялістам па працы з дадзенымі стала зразумела, што такое сховішча дадзеных (DW), а што такое возера дадзеных (Data Lake), і як яны разам ужываюцца .
Чаму я захацеў напісаць пра возера звестак? Я працую з дадзенымі і аналітыкай больш за 10 гадоў, і цяпер я сапраўды працую з вялікімі дадзенымі ў Amazon Alexa AI ў Кембрыджы, які ў Бостане, хоць сам жыву ў Вікторыі на востраве Ванкувер і часта бываю і ў Бостане, і ў Сіэтле, і ў Ванкуверы, а часам нават і ў Маскве выступаю на канферэнцыях. Гэтак жа час ад часу я пішу, але пішу ў асноўным на ангельскай, і напісаў ужо , гэтак жа ў мяне ёсць патрэба дзяліцца трэндамі аналітыкі з Паўночнай Амерыцы, і я часам пішу ў .
Я заўсёды працаваў са сховішчамі дадзеных, і з 2015 года стаў шчыльна працаваць з Amazon Web Services, ды і ўвогуле пераключыўся на хмарную аналітыку (AWS, Azure, GCP). Я назіраў эвалюцыю рашэнняў для аналітыкі з 2007 года і сам нават папрацаваў у вендары сховішчаў дадзеных Тэрадата і ўкараняў яе ў Ашчадбанку, тады вось і з'явілася Big Data з Hadoop. Усе сталі казаць, што мінула эра сховішчаў і зараз усё на Hadoop, а потым ужо сталі казаць пра Data Lake, ізноў жа, што зараз ужо сапраўды сховішча дадзеных прыйшоў канец. Але на шчасце (можа для каго і на няшчасце, хто зарабляў шмат грошай на наладзе Hadoop), сховішча дадзеных не сышло.
У гэтым артыкуле мы і разгледзім, што такое возера даных. Артыкул разлічаных на людзей, у якіх мала досведу з сховішчамі дадзенымі ці зусім няма.

На малюнку возера Блед, гэта адно з маіх каханых азёр, хоць я там быў усяго адзін раз, але запомніў яго на ўсё жыццё. Але мы пагаворым аб іншым тыпе возера - возера дадзеных. Магчыма, многія з вас ужо не раз чулі пра гэта гэты тэрмін, але яшчэ адно вызначэнне нікому не пашкодзіць.
Першым чынам вось самыя папулярныя азначэнні Азёры Дадзеных:
"файлавае сховішча ўсіх тыпаў волкіх дадзеных, якія даступныя для аналізу кім-заўгодна ў арганізацыі" – Марцін Фовлер.
«Калі вы думаеце, што вітрына дадзеных гэта бутэлька вады - вычышчанай, запакаванай і пафасаванай для зручнага ўжывання, то возера дадзеных гэта ў нас велізарны рэзервуар з вадой у яе натуральным выглядзе. Карыстальнікі, магу набіраць вады для сябе, ныраць на глыбіню, даследаваць» - Джэймс Дыксан.
Цяпер мы дакладна ведаем, што возера даных гэта пра аналітыку, яно дазваляе нам захоўваць вялікія аб'ёмы дадзеных у іх першапачатковай форме і ў нас ёсць неабходны і зручны доступ да дадзеных.
Я часта люблю спрашчаць рэчы, калі я магу расказаць складаны тэрмін простымі словамі, значыць для сябе я зразумеў, як гэта працуе і для чаго гэта трэба. Як тое, я калупаўся ў iPhone у фотагалерэі, і мяне ахінула, дык гэта ж сапраўднае возера дадзеных, я нават зрабіў слайд для канферэнцый:
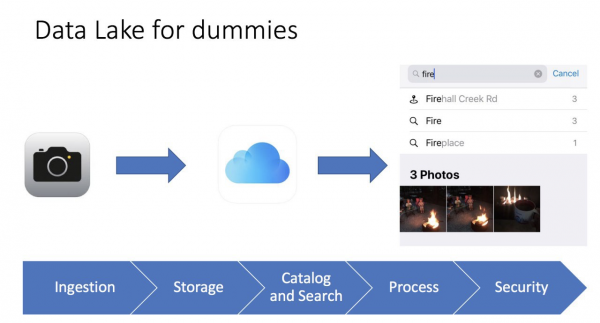
Усё вельмі проста. Мы робім фатаграфію на тэлефон, фатаграфія захоўваецца на тэлефон і можа быць захавана ў iCloud (файлавае сховішча ў воблаку). Таксама тэлефон збірае мета-дадзеныя фатаграфіі: што намалявана, геа метка, час. Як вынік, мы можа выкарыстоўваць зручны інтэрфейс iPhone, Каб знайсці нашу фатаграфію і пры гэтым мы нават бачым паказчыкі, напрыклад, калі я шукаю фатаграфіі са словам агонь (fire), то я знаходжу 3 фатаграфіі з выява вогнішча. Для мяне гэта просты як Business Intelligence інструмент, які працуе вельмі хутка і выразна.
І вядома, нам нельга забываць пра бяспеку (аўтарызацыю і аўтэнтыфікацыю), інакш нашыя даныя могуць лёгка патрапіць у адкрыты доступ. Вельмі шмат навін, пра буйныя карпарацыі і стартапы, у якіх дадзеныя патрапілі ў адчынены доступ з-за халатнасці распрацоўнікаў і не захаванні простых правіл.
Нават такі просты малюнак, дапамагае нам уявіць, што такое возера дадзеных, яго адрозненні ад традыцыйнага сховішча дадзеных і яго асноўныя элементы:
- Загрузка дадзеных (Ingestion) - ключавы кампанент возера дадзеных. Дадзеныя могуць трапляць у сховішча дадзеных двума спосабамі - batch (загрузка з інтэрваламі) і streaming (струмень дадзеных).
- Файлавае сховішча (Storage) - галоўны кампанент Азёры Дадзеных. Нам неабходна, што сховішча было лёгка якое маштабуецца, надзвычай надзейнае і валодала нізкім коштам. Напрыклад, у AWS гэта S3.
- Каталог і Пошук (Catalog and Search) - для таго каб нам пазбегнуць Балоты Дадзеных (гэта калі мы звальваем усе дадзеныя ў адну кучу, і потым немагчыма з імі працаваць), нам неабходна стварыць пласт мета-дадзеных для класіфікацыі дадзеных, каб карыстачы лёгка маглі знайсці дадзеныя, якія ім неабходны для аналізу. Дадаткова можна выкарыстоўваць дадатковыя рашэнні для пошуку, напрыклад ElasticSearch. Пошук дапамагае карыстачу шукаць патрэбныя дадзеныя праз зручныя інтэрфейс.
- Апрацоўка (Process) - гэта крок адказвае за апрацоўку і трансфармацыю дадзеных. Мы можам трансфармаваць дадзеныя, змяняць іх структуры, чысціць і шмат іншага.
- бяспеку (Security) - важна выдаткаваць час на дызайн бяспекі рашэння. Напрыклад, шыфраванне дадзеных падчас захоўвання, апрацоўкі і загрузкі. Важна выкарыстоўваць метады аўтэнтыфікацыі і аўтарызацыі. У заключэнне, патрэбен інструмент аўдыту.
З практычнага пункту гледжання, мы можам характарызаваць возера дадзеных трыма атрыбутамі:
- Збірайце і захоўвайце ўсё што заўгодна - возера дадзеных змяшчае ўсе дадзеныя, як сырыя неапрацаваныя дадзеныя за любы перыяд часу, так і апрацаваных / вычышчаныя дадзеныя.
- Глыбокі аналіз - возера дадзеных дазваляе карыстальнікам даследаваць і аналізаваць дадзеныя.
- Гнуткі доступ - возера дадзеных забяспечвае гнуткі доступ для розных дадзеных і розных сцэнарыяў.
Цяпер можна пагаварыць аб розніцы паміж сховішчам дадзеных і возерам дадзеных. Звычайна людзі пытаюцца:
- А як жа сховішча дадзеных?
- Мы замяняем сховішча дадзеных на возера дадзеных ці мы яго пашыраем?
- Ці можна ўсё ж такі абысціся без возера дадзеных?
Калі коратка, то дакладнага адказу няма. Усё залежыць ад канкрэтнай сітуацыі, навыкаў у камандзе і бюджэту. Напрыклад міграцыя сховішчы дадзеных на Oracle у AWS і стварэнне возера дадзеных даччынай кампаніяй Амазон - Woot - .
З іншага боку, вендар Snowflake заяўляе, што вам больш не трэба думаць пра возера дадзеных, бо іх платформа дадзеных (да 2020 года гэта было сховішча дадзеных), дазваляе вам сумясціць і возера дадзеных і сховішча дадзеных. Я працаваў не шмат са Snowflake, і гэта сапраўды ўнікальны прадукт, які можа так рабіць. Кошт пытання, гэта іншае пытанне.
У заключэнні, маё асабістае меркаванне, што нам усё яшчэ трэба сховішча дадзеных як асноўная крыніца дадзеных для нашай справаздачнасці, і ўсё, што не змяшчаецца, мы захоўваем у возеры дадзеных. Уся роля аналітыкі - гэта даць зручны доступ бізнесу для прыняцця рашэнняў. Як ні круці, але бізнэс карыстачы працу эфектыўней з сховішчам дадзеных, чым возерам дадзеных, напрыклад у Amazon – ёсць Redshift (аналітычнае сховішча дадзеных) і ёсць Redshift Spectrum/Athena (SQL інтэрфейс для возера дадзеных у S3 на базе Hive/Presto). Тое ж адносіцца да іншых сучасных аналітычных сховішчаў дадзеных.
Давайце разгледзім тыповую архітэктура сховішчы дадзеных:
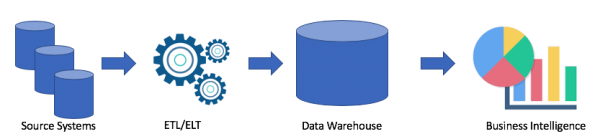
Гэтае класічнае рашэнне. У нас ёсць сістэмы крыніцы, з дапамогай ETL/ELT мы капіюем дадзеныя ў аналітычнае сховішча дадзеных і падлучаем да Business Intelligence рашэнні (маё каханае Tableau, а ваша?).
Такое рашэнне мае наступныя недахопы:
- ETL/ELT аперацыі патрабуюць час і рэсурсы.
- Як правіла памяць для захоўвання дадзеных у аналітычным сховішчы дадзеных не танная (напрыклад Redshift, BigQuery, Teradata), бо нам трэба купляць цэлы кластар.
- Бізнес карыстачы маюць доступ да вычышчаных і часта агрэгаваных дадзеных і ў іх няма магчымасць атрымаць волкія дадзеныя.
Вядома, усё залежыць ад вашага кейса. Калі ў вас няма праблем з вашым сховішчам дадзеных, то вам зусім не патрэбна возера дадзеных. Але калі з'яўляюцца праблемы з недахопам месца, магутнасці ці кошт пытання мае ключавую ролю, то можна разгледзець варыянт возера дадзеных. Менавіта таму возера дадзеных вельмі папулярна. Вось прыклад архітэктуры возера дадзеных:
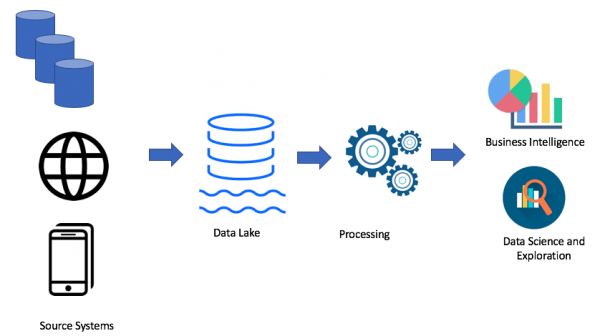
Выкарыстоўваючы падыход возера дадзеных, мы загружаем волкія дадзеныя ў наша возера дадзеных (batch або streaming), далей мы апрацоўваем дадзеныя па неабходнасці. Возера дадзеных дазваляе бізнэс карыстачам ствараць свае ўласныя трансфармацыі дадзеных (ETL/ELT) ці аналізаваць дадзеныя ў рашэннях Business Intelligence (калі ёсць патрэбны драйвер).
Мэта любога аналітычнага рашэння - служыць бізнес карыстальнікам. Таму мы заўсёды мусім працаваць ад патрабаванняў бізнэсу. (У Амазон гэта адзін з прынцыпаў - working backwards).
Працуючы і са сховішчам дадзеных і з возерам дадзеных, мы можам параўнаць абодва рашэнні:
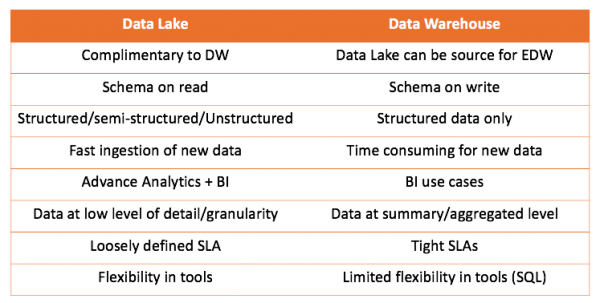
Галоўная выснова, якую можна зрабіць, што сховішча дадзеных, ніяк не спаборнічае з возерам дадзеных, а больш дапаўняе. Але гэта вам вырашаць, што падыходзіць для вашага выпадку. Заўсёды цікава, паспрабаваць самому, і зрабіць правільныя высновы.
Я хацеў бы таксама расказаць па адзін з кейсаў, калі я стаў выкарыстоўваць падыход возера дадзеных. Усё даволі банальна, я паспрабаваў выкарыстаць прыладу ELT (у нас быў Matillion ETL) і Amazon Redshift, маё рашэнне працавала, але не ўкладвалася ў патрабаванні.
Мне неабходна было ўзяць вэб логі, трансфармаваць іх і агрэгаваць, каб падаць дадзеныя для 2х кейсаў:
- Каманда маркетынгу хацела аналізаваць актыўнасць ботаў для SEO
- IT хацела глядзець метрыкі па працы сайтаў
Вельмі просты, вельмі простыя логі. Вось прыклад:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188
192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57
"GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2
arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067
"Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012"
1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"Адзін файл важыў 1-4 мегабайта.
Але была адна цяжкасць. У нас было 7 даменаў па ўсім свеце, і за адзін дзень стваралася 7000 файлаў. Гэта не вельмі большы аб'ём, усяго 50 гігабайт. Але памер нашага кластара Redshift быў таксама невялікім (4 ноды). Загрузка традыцыйным спосабам аднаго файла займала каля хвіліны. Гэта значыць, у ілоб задача не вырашалася. І гэта быў той выпадак, калі я вырашыў выкарыстоўваць падыход возера звестак. Рашэнне выглядала прыкладна так:
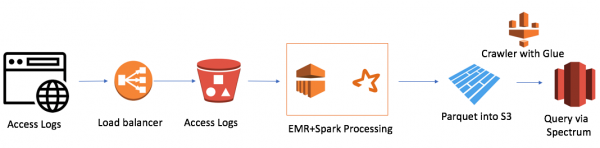
Яно досыць простае (я жадаю заўважыць, што перавага працы ў воблаку гэта прастата). Я выкарыстаў:
- AWS Elastic Map Reduce (Hadoop) як вылічальную магутнасць
- AWS S3 як файлавае сховішча з магчымасць шыфравання дадзеных і размежавання доступу
- Spark як InMemory вылічальную магутнасць і PySpark для логікі і трансфармацыі дадзеных
- Parquet як вынік працы Spark
- AWS Glue Crawler як зборшчык метададзеных аб новых дадзеных і партыцыях
- Redshift Spectrum як SQL інтэрфейс да возера дадзеных для існуючых карыстальнікаў Redshift
Самы маленькі кластар EMR+Spark апрацоўваў увесь пачак файлаў за 30 хвілін. Ёсць і іншыя кейсы для AWS, асабліва шмат звязаных з Alexa, дзе дадзеных вельмі шмат.
Зусім нядаўна я даведаўся адзін з недахопаў возера дадзеных - гэта GDPR. Праблема ў тым, калі кліент просіць яго выдаліць, а дадзеныя знаходзяцца ў адным з файлаў, мы не можам выкарыстоўваць Data Manipulation Language і аперацыю DELETE як у базе даных.
Спадзяюся, артыкул растлумачыў розніцы паміж сховішчам дадзеных і возерам дадзеных. Калі было цікава, то магу перавесці яшчэ свае артыкулы ці артыкулу прафесіяналаў, якіх чытаю. А таксама расказаць пра рашэнні, з якімі працую, і іх архітэктуру.
Крыніца: habr.com
