

Заўв. перав.: Супрацоўнікі сусветна вядомага сэрвісу Tinder нядаўна падзяліліся некаторымі тэхнічнымі дэталямі міграцыі сваёй інфраструктуры на Kubernetes. Працэс заняў амаль два гады і выліўся ў запуск на K8s вельмі маштабнай платформы, якая складаецца з 200 сэрвісаў, размешчаных на 48 тысяч кантэйнераў. З якімі цікавымі складанасцямі сутыкнуліся інжынеры Tinder і да якіх вынікаў дашлі чытайце ў гэтым перакладзе.

Навошта?
Амаль два гады таму Tinder вырашыў перавесці сваю платформу на Kubernetes. Kubernetes дазволіў бы камандзе Tinder правесці кантэйнерызацыю і перайсці на эксплуатацыю з мінімальнымі намаганнямі з дапамогай нязменнага разгортвання (immutable deployment). У гэтым выпадку зборка прыкладанняў, іх дэплой і сама інфраструктура былі б адназначна вызначаны кодам.
Таксама мы шукалі вырашэнне праблемы з маштабаванасцю і стабільнасцю. Калі маштабаванне набыло крытычнае значэнне, нам часта даводзілася па некалькі хвілін чакаць запуску новых экзэмпляраў EC2. Вельмі ўжо прывабнай для нас стала ідэя запуску кантэйнераў і пачала абслугоўванне трафіку за секунды замест хвілін.
Працэс аказаўся няпростым. У час нашай міграцыі ў пачатку 2019-га кластар Kubernetes дасягнуў крытычнай масы і мы пачалі сутыкацца з рознымі праблемамі з-за аб'ёму трафіку, памеру кластара і DNS. Па шляху мы вырашылі масу цікавых задач, злучаных з пераносам 200 сэрвісаў і абслугоўваннем кластара Kubernetes, які складаецца з 1000 вузлоў, 15000 pod'аў і 48000 працавальных кантэйнераў.
Як?
Пачынаючы са студзеня 2018-га, мы прайшлі праз розныя этапы міграцыі. Мы пачалі з кантэйнерызацыі ўсіх нашых сэрвісаў і іх разгортвання ў тэставых хмарных асяродках Kubernetes. Пачынаючы з кастрычніка, мы пачалі метадычна пераносіць усе існуючыя сэрвісы ў Kubernetes. Да сакавіка наступнага года мы скончылі перасяленне і зараз платформа Tinder працуе выключна на Kubernetes.
Зборка вобразаў для Kubernetes
У нас больш за 30 рэпазітараў зыходнага кода для мікрасэрвісаў, якія працуюць у кластары Kubernetes. Код у гэтых рэпазітарах напісаны на розных мовах (напрыклад, на Node.js, Java, Scala, Go) з мноствам runtime-акружэнняў для адной і той жа мовы.
Сістэма зборкі распрацавана такім чынам, каб забяспечваць цалкам наладжвальны "кантэкст зборкі" для кожнага мікрасэрвісу. Звычайна ён складаецца з Dockerfile і спісу shell-каманд. Іх змесціва цалкам наладжвальнае, і ў той жа час усе гэтыя кантэксты зборкі напісаны ў адпаведнасці са стандартызаваным фарматам. Стандартызацыя кантэкстаў зборкі дазваляе адной адзінай сістэме зборкі апрацоўваць усе мікрасэрвісы.
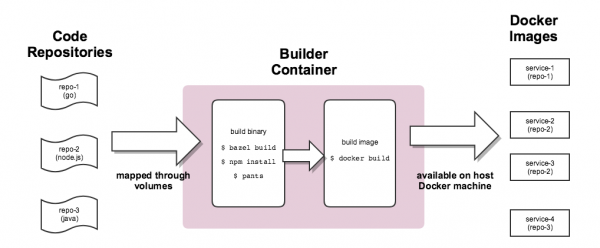
Малюнак 1-1. Стандартызаваны працэс зборкі праз кантэйнер-зборшчык (Builder)
Для дасягнення максімальнай узгодненасці паміж асяроддзямі выканання (runtime environments) адзін і той жа працэс зборкі выкарыстоўваецца падчас распрацоўкі і тэсціравання. Мы сутыкнуліся з вельмі цікавай задачай: прыйшлося распрацаваць спосаб, які гарантуе ўзгодненасць зборачнага асяроддзя па ўсёй платформе. Для гэтага ўсе зборачныя працэсы праводзяцца ўнутры спецыяльнага кантэйнера. Будаўнік.
Яго рэалізацыя кантэйнера запатрабавала прасунутых прыёмаў працы з Docker. Builder успадкоўвае лакальны ID карыстача і сакрэты (напрыклад, ключ SSH, уліковыя дадзеныя AWS і т. д.), якія патрабуюцца для доступу да зачыненых рэпазітараў Tinder. Ён мантуе лакальныя дырэкторыі, якія змяшчаюць зыходнікі, каб натуральным чынам захоўваць артэфакты зборкі. Падобны падыход павялічвае прадукцыйнасць, паколькі ўхіляе запатрабаванне ў капіяванні артэфактаў зборкі паміж кантэйнерам Builder і хастом. Якія захоўваюцца артэфакты зборкі можна выкарыстоўваць паўторна без дадатковай налады.
Для некаторых сэрвісаў нам прыйшлося ствараць яшчэ адзін кантэйнер, каб супаставіць асяроддзе кампіляцыі з асяроддзем выканання (напрыклад, падчас усталёўкі бібліятэка Node.js bcrypt генеруе спецыфічныя для платформы бінарныя артэфакты). У працэсе кампіляцыі патрабаванні могуць адрознівацца для розных сэрвісаў, і канчатковы Dockerfile складаецца на лета.
Архітэктура кластара Kubernetes і міграцыя
Упраўленне памерам кластара
Мы вырашылі выкарыстоўваць kube-aws для аўтаматызаванага разгортвання кластара на асобніках EC2 ад Amazon. У самым пачатку ўсё працавала ў адным агульным куле вузлоў. Мы хутка ўсвядомілі неабходнасць падзелу працоўных нагрузак па памерах і тыпах асобнікаў для больш эфектыўнага выкарыстання рэсурсаў. Логіка была ў тым, што запуск некалькіх нагружаных шматструменных pod'ов апыняўся больш прадказальным па прадукцыйнасці, чым іх суіснаванне з вялікім лікам однопоточных pod'ов.
У выніку мы спыніліся на:
- m5.4xlarge - Для маніторынгу (Prometheus);
- c5.4xвялікі - Для працоўнай нагрузкі Node.js (аднаструменная працоўная нагрузка);
- c5.2xвялікі - для Java і Go (шматструменная працоўная нагрузка);
- c5.4xвялікі - Для кантрольнай панэлі (3 вузла).
Міграцыя
Адным з падрыхтоўчых крокаў для міграцыі са старой інфраструктуры на Kubernetes стала перанакіраванне існуючага прамога ўзаемадзеяння паміж сэрвісамі ў новыя балансавальнікі нагрузкі (Elastic Load Balancers, ELB). Яны былі створаны ў пэўнай падсетцы віртуальнага прыватнага аблокі (VPC). Гэтая падсетка была падлучаная да VPC Kubernetes. Гэта дазволіла нам пераносіць модулі паступова, не улічваючы пэўны парадак залежнасцяў ад сэрвісаў.
Гэтыя endpoints былі створаны з выкарыстаннем узважаных набораў DNS-запісаў, у якіх CNAME паказвалі на кожны новы ELB. Для пераключэння мы дадавалі новы запіс, паказвальную на новы ELB службы Kubernetes з вагай, роўнай 0. Затым усталёўвалі Time To Live (TTL) набору запісаў на 0. Пасля гэтага старыя і новыя важніцы каэфіцыенты павольна карэктаваліся, і ў канчатковым выніку 100% нагрузкі накіроўваліся на новы сервер. Пасля завяршэння пераключэння значэнне TTL вярталася на больш адэкватны ўзровень.
Наяўныя ў нас Java-модулі спраўляліся з нізкім TTL DNS, а Node-прыкладанні – не. Адзін з інжынераў перапісаў частку кода пула злучэнняў, і абгарнуўшы яго ў мэнэджара, які абнаўляў пулы кожныя 60 секунд. Абраны падыход спрацаваў вельмі добра і без прыкметнага зніжэння прадукцыйнасці.
ўрокі
Межы сеткавай фабрыкі
Раніцай 8 студзеня 2019 года платформа Tinder нечакана «ўпала». У адказ на незвязанае павелічэнне часу чакання платформы раней той жа раніцай у кластары ўзрасла колькасць pod'ов і вузлоў. Гэта прывяло да вычарпання кэша ARP на ўсіх нашых вузлах.
Ёсць тры параметры Linux, звязаных з кэшам ARP:

()
gc_thresh3 - Гэта жорсткі мяжа. З'яўленне ў логу запісаў выгляду "neighbor table overflow" азначала, што нават пасля сінхроннага збору смецця (GC) у кэшы ARP апынялася нядосыць месцы для захоўвання суседняга запісу. У гэтым выпадку ядро проста поўнасцю адкідала пакет.
мы выкарыстоўваем у якасці сеткавай фабрыкі (network fabric) у Kubernetes. Пакеты перадаюцца праз VXLAN. VXLAN уяўляе сабой L2-тунэль, падняты па-над L3-сеткай. Тэхналогія выкарыстоўвае інкапсуляцыю MAC-in-UDP (MAC Address-in-User Datagram Protocol) і дазваляе пашыраць сеткавыя сегменты 2-га ўзроўню. Транспартны пратакол у фізічнай сетцы цэнтра апрацоўкі дадзеных – IP плюс UDP.
Малюнак 2-1. Дыяграма Flannel ()
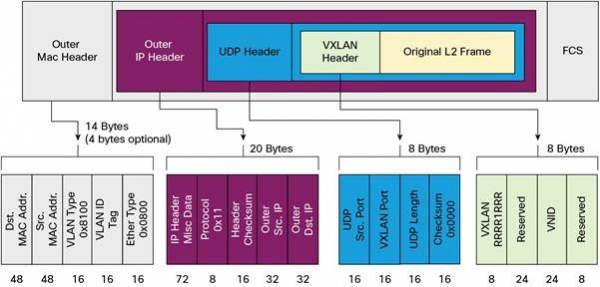
Малюнак 2-2. Пакет VXLAN ()
Кожны працоўны вузел Kubernetes вылучае віртуальную адрасную прастору з маскай /24 з большага блока /9. Для кожнага вузла гэта адзін запіс у табліцы маршрутызацыі, адзін запіс у табліцы ARP (на інтэрфейсе flannel.1) і адзін запіс у табліцы камутацыі (FDB). Яны дадаюцца пры першым запуску працоўнага вузла ці пры выяўленні кожнага новага вузла.
Акрамя таго, сувязь вузел-pod (ці pod-pod) у канчатковым выніку ідзе праз інтэрфейс eth0 (як паказана на дыяграме Flannel вышэй). Гэта прыводзіць да з'яўлення дадатковага запісу ў табліцы ARP для кожнай адпаведнай крыніцы і адрасата вузла.
У нашым асяроддзі падобны тып сувязі вельмі распаўсюджаны. Для аб'ектаў тыпу сэрвіс у Kubernetes ствараецца ELB і Kubernetes рэгіструе кожны вузел у ELB. ELB нічога не ведае пра pod'ах і абраны вузел можа не з'яўляцца канчатковым пунктам прызначэння пакета. Справа ў тым, што калі вузел атрымлівае пакет ад ELB, ён разглядае яго з улікам правіл Iptables для канкрэтнага сэрвісу і выпадковым чынам выбірае pod на іншым вузле.
На момант збою ў кластары было 605 вузлоў. Па прычынах, выкладзеных вышэй, гэтага аказалася дастаткова, каб пераадолець значэнне gc_thresh3, зададзенае па змаўчанні. Калі такое адбываецца, не толькі пакеты пачынаюць адкідацца, але і ўся віртуальная адрасная прастора Flannel з маскай /24 знікае з табліцы ARP. Сувязь вузел-pod і DNS-запыты перарываюцца (DNS размешчаны ў кластары; падрабязнасці чытайце далей у гэтым артыкуле).
Каб вырашыць гэтую праблему, неабходна павялічыць значэнні gc_thresh1, gc_thresh2 и gc_thresh3 і перазапусціць Flannel для перарэгістрацыі зніклых сетак.
Нечаканае маштабаванне DNS
У працэсе міграцыі мы актыўна выкарыстоўвалі DNS для кіравання трафікам і паступовага пераводу сэрвісаў са старой інфраструктуры на Kubernetes. Мы ўсталёўвалі адносна нізкія значэння TTL для звязаных RecordSets у Route53. Калі старая інфраструктура працавала на асобніках EC2, канфігурацыя нашага распазнавальніка паказвала на DNS Amazon. Мы ўспрымалі гэта як належнае і ўздзеянне нізкага TTL на нашы сэрвісы і сэрвісы Amazon (напрыклад, DynamoDB) заставалася практычна незаўважаным.
Па меры пераносу сэрвісаў у Kubernetes мы выявілі, што DNS апрацоўвае па 250 тысяч запытаў за секунду. У выніку прыкладанні сталі выпрабоўваць сталыя і сур'ёзныя timeout'ы па DNS-запытах. Гэта адбылося нягледзячы на неймаверныя намаганні па аптымізацыі і пераключэнні DNS-правайдэра на CoreDNS (які на піку нагрузкі дасягнуў 1000 pod'аў, якія працуюць на 120 ядрах).
Даследуючы іншыя магчымыя прычыны і рашэнні, мы выявілі , якая апісвае race conditions, якія ўплываюць на фрэймворк фільтрацыі пакетаў Netfilter в Linux. Назіраныя намі timeout'ы разам з які павялічваецца лічыльнікам insert_failed у інтэрфейсе Flannel адпавядалі высновам артыкула.
Праблема ўзнікае на этапе Source і Destination Network Address Translation (SNAT і DNAT) і наступнага ўнясення ў табліцу кантракт. Адным з абыходных шляхоў, які абмяркоўваўся ўнутры кампаніі і прапанаваным супольнасцю, стаў перанос DNS на сам працоўны вузел. У гэтым выпадку:
- SNAT не патрэбен, паколькі трафік застаецца ўсярэдзіне вузла. Яго не трэба праводзіць праз інтэрфейс eth0.
- DNAT не патрэбен, паколькі IP адрасата з'яўляецца лакальным для вузла, а не выпадкова абраным подам па правілах. Iptables.
Мы вырашылі прытрымлівацца гэтага падыходу. CoreDNS быў разгорнуты як DaemonSet у Kubernetes і мы ўкаранілі лакальны DNS-сервер вузла ў resolutionv.conf кожнага pod'a наладзіўшы сцяг -cluster-dns каманды кубелет . Гэтае рашэнне аказалася эфектыўным для timeout'аў DNS.
Аднак мы па-ранейшаму назіралі страту пакетаў і павелічэнне лічыльніка insert_failed у інтэрфейсе Flannel. Такое становішча захоўвалася і пасля ўкаранення абыходнага шляху, паколькі мы здолелі выключыць SNAT і/ці DNAT толькі для DNS-трафіку. Race conditions захоўваліся для іншых тыпаў трафіку. На шчасце, большасць пакетаў у нас – TCP, і пры ўзнікненні праблемы яны проста перадаюцца паўторна. Мы да гэтага часу спрабуем знайсці прыдатнае рашэнне для ўсіх тыпаў трафіку.
Выкарыстанне Envoy для лепшага балансавання нагрузкі
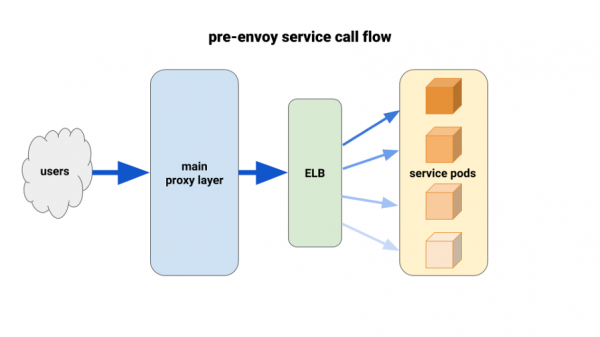
Па меры міграцыі backend-сэрвісаў у Kubernetes мы пачалі пакутаваць ад незбалансаванай нагрузкі паміж pod'амі. Мы выявілі, што з-за HTTP Keepalive злучэнні ELB завісалі на першых гатовых pod'ах кожнага які выкочваецца deployment'а. Такім чынам, асноўная частка трафіку ішла праз невялікі працэнт даступных pod'аў. Першым рашэннем, выпрабаваным намі, стала ўстаноўка параметра MaxSurge на 100% на новых deployment'ах для горшых выпадкаў. Эфект аказаўся нязначным і неперспектыўным у плане буйнейшых deployment'аў.
Яшчэ адно скарыстанае намі рашэнне складалася ў тым, каб штучна нарошчваць запыты на рэсурсы для крытычна важных сэрвісаў. У гэтым выпадку ў размешчаных па суседстве pod'ов было б больш прасторы для манеўру ў параўнанні з іншымі цяжкімі pod'амі. У доўгатэрміновай перспектыве яно б таксама не спрацавала з-за пустога марнавання рэсурсаў. Акрамя таго, нашы Node-прыкладанні былі аднаструменнымі і, адпаведна, маглі задзейнічаць толькі адно ядро. Адзіным рэальным рашэннем было выкарыстанне лепшага балансавання нагрузкі.
Мы даўно хацелі ў поўнай меры ацаніць . Якая склалася сітуацыя дазволіла нам разгарнуць яго вельмі абмежаванай выявай і атрымаць неадкладныя вынікі. Envoy – гэта высокапрадукцыйны проксі сёмага ўзроўню з адкрытым зыходным кодам, распрацаваны для буйных SOA-прыкладанняў. Ён умее ўжываць перадавыя метады балансавання нагрузкі, у тым ліку аўтаматычныя паўторы, circuit breakers і глабальнае абмежаванне хуткасці. (Заўв. перав.: Больш падрабязна пра гэта можна пачытаць у пра Istio, у аснове якога выкарыстоўваецца Envoy.)
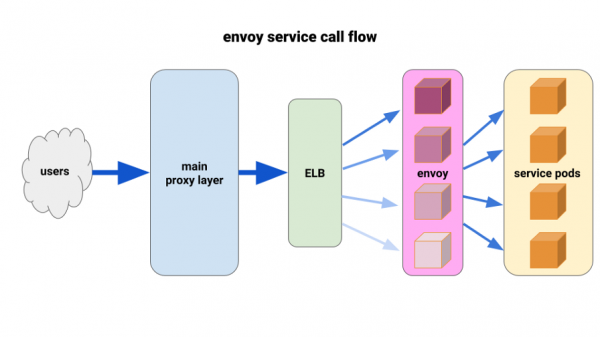
Мы прыдумалі наступную канфігурацыю: мець па Envoy sidecar'у для кожнага pod'а і адзіны маршрут, а кластар - падлучаць да кантэйнера лакальна па порце. Каб звесці да мінімуму патэнцыйнае каскадзіраванне і захаваць невялікі радыус «паразы», мы выкарыстоўвалі парк front-proxy pod'аў Envoy, па адным на кожную зону даступнасці (Availability Zone, AZ) для кожнага сэрвісу. Яны звярталіся да простага механізму выяўлення сэрвісаў, напісанаму адным з нашых інжынераў, які проста вяртаў спіс pod'ов у кожнай AZ для дадзенага сэрвісу.
Затым сэрвісныя front-Envoy'і выкарыстоўвалі гэты механізм выяўлення сэрвісаў з адным upstream-кластарам і маршрутам. Мы задалі адэкватныя timeout'ы, павялічылі ўсе налады circuit breaker'а і дадалі мінімальную канфігурацыю паўтораў, каб дапамагчы з адзінкавымі збоямі і забяспечыць бесперашкодныя разгортванні. Перад кожным з гэтых сэрвісных front-Envoy'яў мы размясцілі TCP ELB. Нават калі keepalive з нашага асноўнага проксі-пласту завісаў на некаторых Envoy pod'ах, яны ўсё ж маглі значна лепш спраўляцца з нагрузкай і былі настроены на балансаванне праз least_request у backend.
Для deployment'аў мы выкарыстоўвалі хук preStop як на pod'ах прыкладанняў, так і на pod'ах sidecar'аў. Хук ініцыяваў памылку ў праверцы стану ў адмінскага endpoint'а, размешчанага на sidecar-кантэйнеры, і засынаў на некаторы час з тым, каб даць магчымасць завяршыцца актыўным злучэнням.
Адна з прычын, па якой мы змаглі так хутка рушыць наперад, звязана з падрабязнымі метрыкамі, якія мы змаглі лёгка інтэграваць у звычайную ўстаноўку Prometheus. Гэта дазволіла нам сапраўды бачыць, што адбываецца, пакуль мы падбіралі параметры канфігурацыі і пераразмяркоўвалі трафік.
Вынікі былі неадкладнымі і відавочнымі. Мы пачалі з самых незбалансаваных сэрвісаў, а на дадзены момант ён функцыянуе ўжо перад 12 найважнейшымі сэрвісамі ў кластары. У гэтым годзе мы плануем пераход на паўнавартасны service mesh з больш прасунутым выяўленнем сэрвісаў, circuit breaking'ом, выяўленнем выкідаў, абмежаваннем хуткасці і трасіроўкай.
Малюнак 3-1. Канвергенцыя CPU аднаго сэрвісу падчас пераходу на Envoy
канчатковы вынік
Дзякуючы атрыманаму досведу і дадатковым даследаванням мы стварылі моцную каманду па інфраструктуры з добрымі навыкамі ў дачыненні да праектавання, разгортвання і эксплуатацыі буйных кластараў Kubernetes. Цяпер усе інжынеры Tinder валодаюць ведамі і вопытам аб тым, як пакаваць кантэйнеры і разгортваць прыкладанні ў Kubernetes.
Калі на старой інфраструктуры ўзнікала патрэбнасць у дадатковых магутнасцях, нам даводзілася па некалькі хвілін чакаць запуску новых экзэмпляраў EC2. Цяпер кантэйнеры пачынаюць запускаюцца і пачынаюць апрацоўваць трафік на працягу некалькіх секунд замест хвілін. Планаванне працы некалькіх кантэйнераў на адным асобніку EC2 таксама забяспечвае палепшаную гарызантальную канцэнтрацыю. У выніку ў 2019-м годзе мы прагназуем значнае зніжэнне затрат на EC2 у параўнанні з мінулым годам.
На міграцыю спатрэбілася амаль два гады, але мы завяршылі яе ў сакавіку 2019-га. У цяперашні час платформа Tinder працуе выключна на кластары Kubernetes, які складаецца з 200 сэрвісаў, 1000 вузлоў, 15 pod'ов і 000 якія працуюць кантэйнераў. Інфраструктура больш не з'яўляецца ўдзелам выключна каманд па эксплуатацыі. Усе нашы інжынеры падзяляюць гэтую адказнасць і кантралююць працэс зборкі і разгортвання сваіх прыкладанняў толькі з дапамогай кода.
PS ад перакладчыка
Чытайце таксама ў нашым блогу цыкл артыкулаў:
- «.
- «.
- «.
- «.
- «.
- «.
- «.
- «.
- «.
- «.
Крыніца: habr.com
