

Нашы карыстачы пішуць адзін аднаму паведамленні, не ведаючы стомленасці.

Гэта дастаткова шмат. Калі б Вы задаліся мэтай прачытаць усе паведамленні ўсіх карыстальнікаў, гэта заняло б больш за 150 тысяч гадоў. Пры ўмове, што Вы даволі прапампаваны чытальнік і марнуеце на кожнае паведамленне не больш за секунду.
Пры такім аб'ёме дадзеных крытычна важна, каб логіка захоўвання і доступу да іх была пабудавана аптымальна. Інакш у адзін не такі ўжо і цудоўны момант можа высветліцца, што хутка ўсё пойдзе не так.
Для нас гэты момант надышоў паўтара гады таму. Як мы да гэтага прыйшлі і што атрымалася ў выніку — расказваем па парадку.
Гісторыя пытання
У самай першай рэалізацыі паведамлення ВКонтакте працавалі на звязку PHP-бэкэнда і MySQL. Гэтае цалкам звычайнае рашэнне для невялікага студэнцкага сайта. Аднак гэты сайт нястрымна рос і пачаў патрабаваць аптымізаваць структуры дадзеных пад сябе.
У канцы 2009 года было напісана першае сховішча text-engine, а ў 2010 годзе на яго перавялі паведамленні.
У text-engine паведамленні захоўваліся спісамі - свайго роду «паштовымі скрынямі». Кожны такі спіс вызначаецца uid'ом - карыстачом-уладальнікам усіх гэтых паведамленняў. У паведамлення ёсць набор атрыбутаў: ідэнтыфікатар суразмоўцы, тэкст, укладанні і гэтак далей. Ідэнтыфікатар паведамлення ўнутры "скрыні" - local_id, ён ніколі не змяняецца і прызначаецца паслядоўна для новых паведамленняў. Скрыні незалежныя і сябар з сябрам усярэдзіне рухавічка ніяк не сінхранізуюцца, сувязь паміж імі адбываецца ўжо на ўзроўні PHP. Паглядзець на структуру дадзеных і магчымасці text-engine знутры можна .
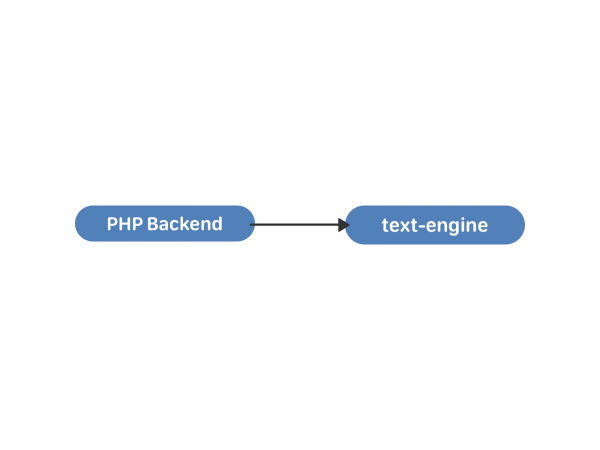
Гэтага было цалкам дастаткова для перапіскі двух карыстальнікаў. Адгадайце, што здарылася потым?
У маі 2011 года ВКонтакте з'явіліся гутаркі з некалькімі ўдзельнікамі - мульцічаты. Для працы з імі мы паднялі два новыя кластары - member-chats і chat-members. Першы захоўвае дадзеныя аб чатах па карыстальніках, другі - дадзеныя аб карыстальніках па чатах. Акрамя саміх спісаў гэта, напрыклад, які запрасіў карыстач і час дадання ў чат.
- PHP, давай адправім паведамленне ў чат, - кажа карыстач.
- Ну давай, {username}, - кажа PHP.
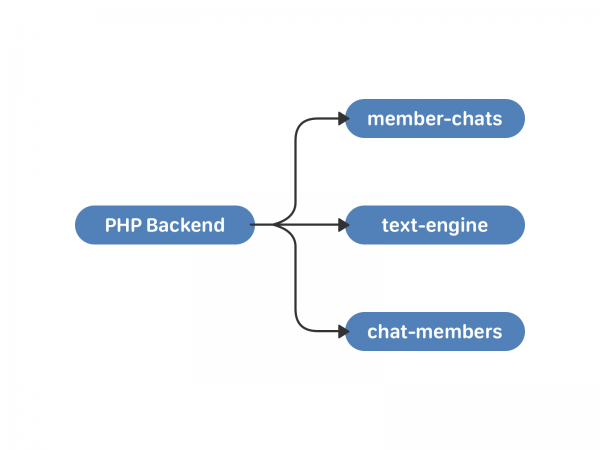
У гэтай схеме ёсць мінусы. Сінхранізацыя па-ранейшаму ўскладзена на PHP. Вялікія чаты і карыстальнікі, якія адначасова адпраўляюць паведамленні ў іх - небяспечная гісторыя. Паколькі асобнік text-engine залежыць ад uid, удзельнікі чата маглі атрымліваць адно і тое ж паведамленне з розніцай у часе. З гэтым можна было жыць, калі б прагрэс стаяў на месцы. Але не бываць такому.
У канцы 2015 года мы запусцілі паведамленні супольнасцяў, а ў пачатку 2016 - API для іх. Са з'яўленнем буйных чат-ботаў у супольнасцях аб раўнамернасці размеркавання нагрузкі можна было забыцца.
Прыдатны бот генеруе некалькі мільёнаў паведамленняў у суткі – нават самыя гаваркія карыстальнікі такім пахваліцца не могуць. А гэта значыць, што некаторым асобнікам text-engine, на якіх жылі такія вось робаты, стала даставацца па поўнай.
Рухавікі паведамленняў у 2016 годзе - гэта па 100 экзэмпляраў chat-members і member-chats, і 8000 text-engine. Яны размяшчаліся на тысячы сервераў, кожны з 64 Гб памяці. У якасці першай экстранай меры мы павялічылі памяць яшчэ на 32 Гб. Прыкінулі прагнозы. Без кардынальных зменаў гэтага хапіла б яшчэ прыкладна на год. Трэба альбо разжывацца жалезам, альбо аптымізаваць самі БД.
У сілу асаблівасцяў архітэктуры нарошчваць жалеза мае сэнс толькі кратна. Гэта значыць, як мінімум падвоіць колькасць машын - відавочна, гэта даволі дарагі шлях. Будзем аптымізаваць.
Новая канцэпцыя
Цэнтральная сутнасць новага падыходу - чат. У чата ёсць спіс паведамленняў, якія адносяцца да яго. У карыстальніка ёсць спіс чатаў.
Неабходны мінімум - гэта дзве новыя базы дадзеных:
- chat-engine. Гэта сховішча вектараў чатаў. У кожнага чата ёсць вектар паведамленняў, якія да яго адносяцца. У кожнага паведамлення ёсць тэкст і ўнікальны ідэнтыфікатар паведамлення ўнутры чата - chat_local_id.
- user-engine. Гэта сховішча вектараў users - спасылак на карыстачоў. У кожнага карыстальніка ёсць вектар peer_id (суразмоўцаў - іншых карыстальнікаў, мульцічат або супольнасцяў) і вектар паведамленняў. У кожнага peer_id ёсць вектар паведамленняў, якія да яго адносяцца. У кожнага паведамлення ёсць chat_local_id і ўнікальны ідэнтыфікатар паведамлення для гэтага карыстальніка - user_local_id.
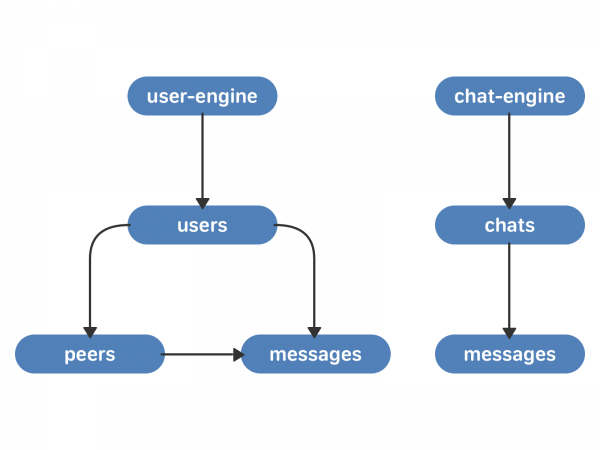
Новыя кластары маюць зносіны паміж сабой з дапамогай TCP - гэта гарантуе, што парадак запытаў не зменіцца. Самі запыты і пацверджанні для іх запісваюцца на цвёрдую кружэлку — таму мы можам аднавіць стан чаргі ў любы момант часу пасля збою або перазапуску рухавічка. Паколькі user-engine і chat-engine гэта 4 тысячы шардаў кожны, чарга запытаў паміж кластарамі будзе размяркоўвацца раўнамерна (а ў рэальнасці яе няма ўвогуле — і гэта працуе вельмі хутка).
Праца з дыскам у нашых базах у большасці выпадкаў заснавана на спалучэнні бінарнага лога змен (бінлога), статычных здымкаў і частковай выявы ў памяці. Змены на працягу дня пішуцца ў бінглог, перыядычна ствараецца здымак бягучага стану. Здымак уяўляе сабой набор структур дадзеных, аптымізаваных для нашых мэт. Ён складаецца з загалоўка (метаіндэкс здымка) і набору метафайлаў. Загаловак увесь час захоўваецца ў аператыўнай памяці і паказвае, дзе шукаць дадзеныя са здымка. Кожны метафайл уключае дадзеныя, якія з вялікай верагоднасцю запатрабуюцца ў блізкія моманты часу - напрыклад, ставяцца да аднаго карыстача. Пры запыце да базы з дапамогай загалоўка здымка чытаецца патрэбны метафайл, а затым улічваюцца змены ў бінлогу, якія адбыліся ўжо пасля стварэння здымка. Прачытаць падрабязней пра перавагі такога падыходу можна .
Пры гэтым дадзеныя на самай цвёрдай кружэлцы змяняюцца толькі раз у суткі – глыбокай ноччу па Маскве, калі нагрузка мінімальная. Дзякуючы гэтаму (ведаючы, што структура на дыску на працягу сутак сталая) мы можам дазволіць сабе замяніць вектары на масівы фіксаванага памеру – і за кошт гэтага выйграць у памяці.
Адпраўка паведамлення ў новай схеме выглядае так:
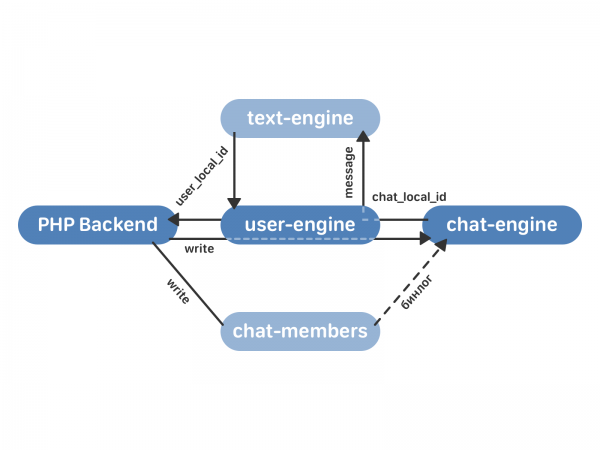
- PHP backend звяртаецца да user-engine з запытам на адпраўку паведамлення.
- user-engine праксіруе запыт у патрэбны экзэмпляр chat-engine, які вяртае ў user-engine chat_local_id - унікальны ідэнтыфікатар новага паведамлення ўнутры гэтага чата. Затым chat_engine рассылае паведамленне ўсім атрымальнікам у чаце.
- user-engine прымае ад chat-engine chat_local_id і вяртае ў PHP user_local_id - унікальны ідэнтыфікатар паведамлення для гэтага карыстальніка. Гэты ідэнтыфікатар затым выкарыстоўваецца, напрыклад, для працы з паведамленнямі праз API.
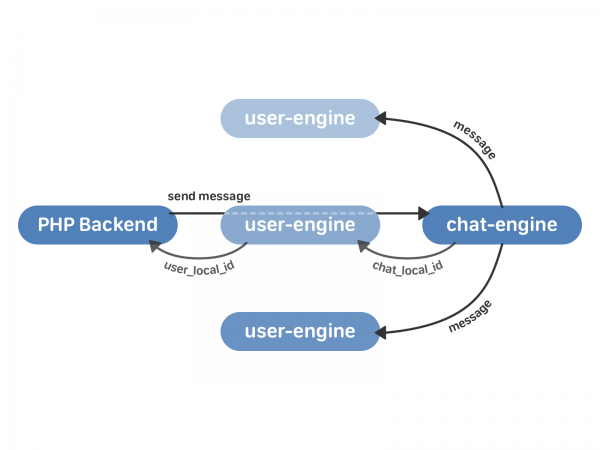
Але апроч уласна рассылання паведамленняў трэба рэалізаваць яшчэ некалькі важных рэчаў:
- Падпіскі - гэта напрыклад, самыя свежыя паведамленні, якія Вы бачыце, адкрываючы спіс дыялогаў. Непрачытаныя паведамленні, паведамленні з пазнакамі ("Важныя", "Спам" і г.д.).
- Сціск паведамленняў у chat-engine
- Кэшаванне паведамленняў у user-engine
- Пошук (па ўсіх дыялогах і ўнутры канкрэтнага).
- Абнаўленне ў рэальным часе (Longpolling).
- Захаванне гісторыі для рэалізацыі кэшавання на мабільных кліентах.
Усе падпіскі - гэта хутка зменлівыя структуры. Для працы з імі мы выкарыстоўваем . Такі выбар тлумачыцца тым, што ў вяршыні дрэва ў нас часам захоўваецца цэлы адрэзак паведамленняў са здымка - напрыклад, пасля начной пераіндэксацыі дрэва складаецца з адной вяршыні, у якой ляжаць усе паведамленні падспісу. Splay-дрэва дазваляе лёгка выконваць аперацыю ўстаўкі ў сярэдзіну такой вяршыні, не думаючы аб балансіроўцы. Акрамя таго, Splay не захоўвае лішніх дадзеных, і гэта эканоміць нам памяць.
Паведамленні маюць на ўвазе вялікі аб'ём інфармацыі, у асноўным тэкставай, якую карысна ўмець сціскаць. Пры гэтым важна, каб мы маглі дакладна разархіваваць нават адно асобнае паведамленьне. Для сціску паведамленняў выкарыстоўваецца з уласнымі эўрыстыкі - напрыклад, мы ведаем, што ў паведамленнях словы чаргуюцца з «не словамі» - прабеламі, знакамі пунктуацыі, - а таксама памятаем аб некаторых асаблівасцях выкарыстання знакаў для рускай мовы.
Паколькі карыстальнікаў значна менш, чым чатаў, для эканоміі random-access запытаў да дыска ў chat-engine мы кэшуем паведамленні ў user-engine.
Пошук па паведамленнях рэалізаваны як дыяганальны запыт з user-engine да ўсіх экзэмпляраў chat-engine, якія змяшчаюць чаты гэтага карыстальніка. Вынікі аб'ядноўваюцца ўжо ў самім user-engine.
Што ж, усе дэталі ўлічаны, засталося перайсці на новую схему і пажадана так, каб карыстачы гэтага не заўважылі.
Міграцыя дадзеных
Такім чынам, у нас ёсць text-engine, які захоўвае паведамленні па карыстальніках, і два кластары chat-members і member-chats, якія захоўваюць дадзеныя аб мультычат і карыстальнікаў у іх. Як ад гэтага перайсці да новых user-engine і chat-engine?
member-chats у старой схеме выкарыстоўваўся пераважна для аптымізацыі. Мы даволі хутка перанеслі патрэбныя дадзеныя з яго ў chat-members, і далей у працэсе міграцыі ён ужо не ўдзельнічаў.
Чарга за chat-members. Ён уключае 100 экзэмпляраў, у той час як chat-engine — 4 тысячы. Для пераліўкі дадзеных трэба прывесці іх у адпаведнасць - для гэтага chat-members разбілі на тыя ж 4 тысячы асобнікаў, а пасля ўключылі чытанне бінгла chat-members у chat-engine.
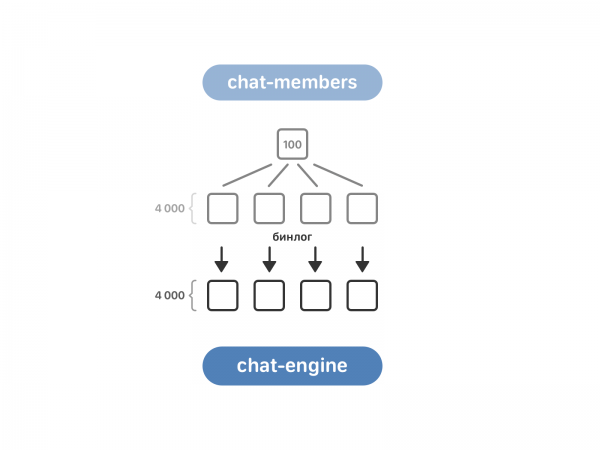
Цяпер chat-engine ведае пра мульцічат з chat-members, але яму пакуль нічога не вядома пра дыялогы з двума суразмоўцамі. Такія дыялогі ляжаць у text-engine з прывязкай да карыстальнікаў. Тут мы забіралі дадзеныя "ў лоб": кожны асобнік chat-engine запытваў ва ўсіх асобнікаў text-engine, ці ёсць у іх патрэбны яму дыялог.
Выдатна - chat-engine ведае, якія ёсць мультычаты, і ведае, якія ёсць дыялогі.
Трэба аб'яднаць паведамленні ў мультычатах - так, каб у выніку для кожнага чата атрымаць спіс паведамленняў у ім. Спачатку chat-engine забірае з text-engine усе паведамленні карыстальнікаў з гэтага чата. У некаторых выпадках іх даволі шмат (да сотні мільёнаў), але за вельмі рэдкім выключэннем чат поўнасцю змяшчаецца ў аператыўную памяць. Мы маем неўпарадкаваныя паведамленні, кожнае ў некалькіх копіях - бо выцягваюцца яны ўсе з розных асобнікаў text-engine, якія адпавядаюць карыстачам. Задача ў тым, каб адсартаваць паведамленні і пазбавіцца ад дзід, якія займаюць лішняе месца.
У кожнага паведамлення ёсць timestamp, які змяшчае час адпраўкі, і тэкст. Выкарыстоўваны час для сартавання - змяшчаем паказальнікі на самыя старыя паведамленні ўдзельнікаў мультычата і параўноўваем хэшы ад тэксту меркаваных копій, рухаючыся ў бок павелічэння timestamp. Лагічна, што ў дзід будуць супадаць і хэш, і timestamp, але на практыку гэта не заўсёды так. Як Вы памятаеце, сінхранізацыя ў старой схеме ажыццяўлялася сіламі PHP - і ў рэдкіх выпадках час адпраўкі аднаго і таго ж паведамлення адрознівалася ў розных карыстачоў. У гэтых выпадках мы дазвалялі сабе рэдагаваць timestamp, як правіла, у межах секунды. Другая праблема - розны парадак паведамленняў для розных атрымальнікаў. У такіх выпадках мы дапушчалі стварэнне лішняй копіі, з рознымі варыянтамі парадку для розных карыстачоў.
Пасля гэтага дадзеныя аб паведамленнях у мультычатах накіроўваюцца ў user-engine. І тут узнікае непрыемная асаблівасць імпартаваных паведамленняў. У нармальным рэжыме працы паведамлення, якія прыходзяць у рухавічок, спарадкаваны строга па ўзрастанні user_local_id. Імпартаваныя са старога рухавічка ў user-engine паведамлення гублялі гэтую карысную ўласцівасць. Пры гэтым для зручнасці тэсціравання трэба ўмець хутка да іх звяртацца, нешта ў іх шукаць і дадаваць новыя.
Для захоўвання імпартаваных паведамленняў мы выкарыстоўваем асаблівую структуру даных.
Яна ўяўляе сабой вектар памеру  , дзе ўсе
, дзе ўсе  - розныя і спарадкаваны па спаданні, з асаблівым парадкам элементаў. У кожным адрэзку з індэксамі
- розныя і спарадкаваны па спаданні, з асаблівым парадкам элементаў. У кожным адрэзку з індэксамі  элементы адсартаваны. Пошук элемента ў такой структуры выконваецца за час
элементы адсартаваны. Пошук элемента ў такой структуры выконваецца за час  праз
праз  бінарных пошукаў. Даданне элемента выконваецца амартызавана за
бінарных пошукаў. Даданне элемента выконваецца амартызавана за  .
.
Такім чынам, мы разабраліся з тым, як пераліваць дадзеныя са старых рухавікоў у новыя. Але гэты працэс займае некалькі дзён - і наўрад ці на гэтыя дні нашы карыстальнікі кінуць звычку пісаць адзін аднаму. Каб не страціць паведамлення за гэты час, мы пераключаемся на схему працы, якая задзейнічае і старыя, і новыя кластары.
Запіс дадзеных ідзе ў chat-members і user-engine (а не ў text-engine, як пры нармальнай працы па старой схеме). user-engine праксіруе запыт да chat-engine — і тут паводзіны залежаць ад таго, смярцены ўжо гэты чат ці яшчэ не. Калі чат яшчэ не смяротны, chat-engine не запісвае паведамленне да сябе, і яго апрацоўка адбываецца толькі ў text-engine. Калі чат ужо смярджаны ў chat-engine, ён вяртае ў user-engine chat_local_id і рассылае паведамленне ўсім атрымальнікам. user-engine праксуе ўсе дадзеныя ў text-engine - каб у выпадку чаго мы заўсёды маглі адкаціцца назад, маючы ўсе актуальныя дадзеныя ў старым рухавічку. text-engine вяртае user_local_id, які user-engine захоўвае ў сябе і вяртае ў бэкэнд.
У выніку працэс пераходу выглядае так: падлучаем пустыя кластары user-engine і chat-engine. chat-engine чытае ўвесь бінг chat-members, затым запускаецца праксіраванне па схеме, апісанай вышэй. Пераліваем старыя дадзеныя, атрымліваем два сінхранізаваныя кластары (стары і новы). Застаецца толькі пераключыць чытанне з text-engine на user-engine і адключыць праксіраванне.
Вынікі
Дзякуючы новаму падыходу палепшыліся ўсе метрыкі якасці працы рухавікоў, вырашаны праблемы з кансістэнтнасцю даных. Цяпер мы можам хутчэй укараняць новыя фічы ў паведамленнях (і ўжо пачалі гэта рабіць – павялічылі максімальную колькасць удзельнікаў чата, рэалізавалі пошук па перасланых паведамленнях, запусцілі замацаваныя паведамленні і паднялі ліміт на агульную колькасць паведамленняў у аднаго карыстальніка).
Змены ў логіцы сапраўды грандыёзныя. І жадаецца адзначыць, што гэта не заўсёды азначае цэлыя гады распрацоўкі велізарнай камандай і мірыяды радкоў кода. chat-engine і user-engine разам з усімі дадатковымі гісторыямі накшталт Хафмана для сціску паведамленняў, Splay-дрэваў і структуры для імпартаваных паведамленняў - гэта менш за 20 тысяч радкоў кода. І напісалі іх 3 распрацоўшчыкі ўсяго за 10 месяцаў (зрэшты, варта мець на ўвазе, што - чэмпіёны свету ).
Больш за тое, замест падваення колькасці сервераў мы прыйшлі да памяншэння іх ліку напалову – цяпер user-engine і chat-engine жывуць на 500 фізічных машынах, пры гэтым у новай схемы ёсць вялікі запас па нагрузцы. Мы зэканомілі кучу грошай на абсталяванні - гэта каля $ 5 млн + $ 750 тысяч у год за кошт аперацыйных выдаткаў.
Мы імкнемся знаходзіць найлепшыя рашэнні для самых складаных і маштабных задач. У нас іх дастаткова - і таму мы шукаем таленавітых распрацоўшчыкаў у аддзел баз дадзеных. Калі Вы любіце і ўмееце рашаць такія задачы, выдатна ведаеце алгарытмы і структуры дадзеных, запрашаем Вас далучыцца да каманды. Звяжыцеся з нашым , Каб даведацца падрабязнасці.
Нават калі гэтая гісторыя не пра Вас, звярніце ўвагу, што мы шануем рэкамендацыі. Раскажыце сябру пра , і, калі ён паспяхова пройдзе выпрабавальны тэрмін, Вы атрымаеце бонус у памеры 100 тысяч рублёў.
Крыніца: habr.com
