

Нядаўна я расказаў, як з дапамогай тыпавых рэцэптаў з PostgreSQL-базы. Сёння ж гаворка пойдзе аб тым, як можна зрабіць больш эфектыўнай запіс у БД без выкарыстання якіх-небудзь «круцілак» у канфігу - проста правільна арганізаваўшы патокі дадзеных.

#1. Секцыянаванне
Артыкул пра тое, як і навошта варта арганізоўваць ужо была, тут жа гаворка пойдзе аб практыцы прымянення некаторых падыходаў у рамках нашага. .
«Справы даўно мінулых дзён…»
Першапачаткова, як і ўсякі MVP, наш праект стартаваў пад досыць невялікай нагрузкай – маніторынг ажыццяўляўся толькі для дзясятка найболей крытычных сервераў, усе табліцы былі адносна кампактныя… Але час ішоў, адсочваных хастоў станавілася ўсё больш, і паспрабаваўшы ў чарговы раз нешта зрабіць з адной з табліц памерам 1.5TB, мы зразумелі, што жыць так далей хоць і можна, але вельмі ўжо няёмка.
Часы былі амаль што былінныя, актуальнымі былі розныя варыянты PostgreSQL 9.x, таму ўсё секцыянаванне прыйшлося рабіць "уручную" - праз атрыманне ў спадчыну табліц і трыгеры роўтынгу з дынамічным EXECUTE.
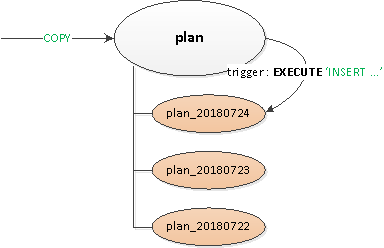
Атрыманае рашэнне апынулася досыць універсальным, каб можна было странсліраваць яго на ўсе табліцы:
- Была абвешчана пустая "загалоўкавая" бацькоўская табліца, на якой апісваліся ўсе патрэбныя індэксы і трыгеры.
- Запіс з пункту гледжання кліента праводзіўся ў "каранёвую" табліцу, а ўнутры з дапамогай трыгера роўтынгу
BEFORE INSERTзапіс "фізічна" устаўлялася ў патрэбную секцыю. Калі такой яшчэ не было - мы лавілі выключэнне і … - … з дапамогай па шаблоне бацькоўскай табліцы стваралася секцыя з абмежаваннем на патрэбную дату, Каб пры выманні дадзеных чытанне праводзілася толькі ў ёй.
PG10: першая спроба
Але секцыянаванне праз атрыманне ў спадчыну было гістарычна не вельмі прыстасавана для працы з актыўным струменем запісу або вялікай колькасцю секцый-нашчадкаў. Напрыклад, можна ўспомніць, што алгарытм выбару патрэбнай секцыі меў квадратычную складанасць, Што пры 100+ секцыях працуе, самі разумееце як…
У PG10 гэтую сітуацыю моцна аптымізавалі, рэалізаваўшы падтрымку . Таму мы адразу паспрабавалі яго ўжыць адразу пасля міграцыі сховішчы, але...
Як высветлілася пасля перакопвання мануала, натыўна секцыянаваная табліца ў гэтай версіі:
- не падтрымлівае апісанне індэксаў
- не падтрымлівае на ёй трыгераў
- не можа быць сама нічыёй «нашчадкай»
- не падтрымлівае
INSERT ... ON CONFLICT - не ўмее спараджаць секцыю аўтаматычна
Балюча атрымаўшы па лбе граблямі, мы зразумелі, што без мадыфікацыі дадатку абыйсціся не атрымаецца, і адклалі далейшыя даследаванні на паўгода.
PG10: другі шанец
Такім чынам, мы пачалі вырашаць узніклыя праблемы па чарзе:
- Паколькі трыгеры і
ON CONFLICTнам аказаліся дзе-нідзе ўсё ж патрэбныя, для іх адпрацоўкі зрабілі прамежкавую. проксі-табліцу. - Пазбавіліся «роўтынгу» у трыгерах - гэта значыць ад
EXECUTE. - Вынеслі асобна табліцу-шаблон з усімі індэксамі, Каб яны нават не прысутнічалі на проксі-табліцы.
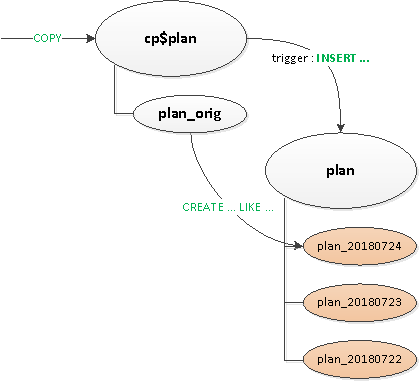
Нарэшце, пасля ўсяго гэтага, ужо натыўна адсекцыянавалі асноўную табліцу.
«Пілім» слоўнікі
Як і ў любой аналітычнай сістэме, у нас таксама былі "факты" і "разрэзы" (слоўнікі). У нашым выпадку, у гэтай якасці выступалі, напрыклад, аднатыпных павольных запытаў або тэкст самога запыту.
"Факты" ў нас былі адсекцыянаваць па днях ужо даўно, таму мы спакойна выдалялі састарэлыя секцыі, і яны нам не перашкаджалі (лагі ж!). А вось са слоўнікамі атрымалася бяда…
Не сказаць, што іх аказалася вельмі шмат, але прыкладна на 100TB "фактаў" атрымаўся слоўнік на 2.5TB. З такой табліцы зручна нічога не выдаляеш, не сціснеш за адэкватны час, ды і запіс у яе паступова станавілася ўсё павольней.
Накшталт слоўнік… у ім кожны запіс павінен быць прадстаўлены роўна адзін раз… і гэта правільна, але!.. Ніхто не мяшае нам мець па асобным слоўніку на кожны дзень! Так, гэта прыносіць пэўную надмернасць, затое дазваляе:
- пісаць/чытаць хутчэй за кошт меншага памеру секцыі
- спажываць менш памяці за кошт працы з больш кампактнымі індэксамі
- захоўваць менш дадзеных за кошт магчымасці хуткага выдалення састарэлых
У выніку ўсяго комплексу мерапрыемстваў нагрузка па CPU скарацілася на ~30%, па дыску - на ~50%:
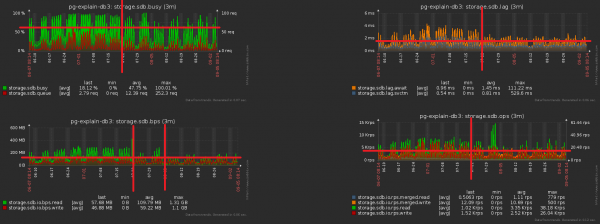
Пры гэтым мы працягнулі пісаць у базу роўна тое ж самае, проста з меншай нагрузкай.
#2. Эвалюцыя і рэфакторынг БД
Дык вось, мы спыніліся на тым, што ў нас на кожны дзень ёсць свая секцыя з дадзенымі. CHECK (dt = '2018-10-12'::date) - і ёсць ключ секцыянавання і ўмова траплення запісу ў канкрэтную секцыю.
Паколькі ўсе справаздачы ў нашым сэрвісе будуюцца ў разрэзе канкрэтнай даты, то і індэксы яшчэ з "несекцыянаваных часоў" для іх былі ўсе тыпу (Сервер, Дата, Шаблон плана), (Сервер, Дата, Вузел плана), (Дата, Клас памылкі, Сервер), ...
Але зараз на кожнай секцыі жывуць свае экзэмпляры кожнага такога індэкса... І ў межах кожнай секцыі дата - канстанта… Атрымліваецца, што зараз мы ў кожны такі індэкс банальна ўпісваем канстанту у якасці аднаго з палёў, што робіць больш і яго аб'ём, і час пошуку па ім, але не прыносіць ніякага выніку. Самі сабе пакінулі граблі, упс...

Кірунак аптымізацыі відавочна - проста прыбіраны поле з датай з усіх індэксаў на секцыянаваных табліцах. Пры нашых аб'ёмах выйгрыш - парадку 1TB/тыдзень!
А зараз давайце заўважым, што гэты тэрабайт яшчэ трэба было неяк запісаць. Гэта значыць, мы яшчэ і дыск павінны зараз грузіць менш! На гэтым малюнку добра бачны атрыманы эфект ад праведзенай чысткі, якой мы прысвяцілі тыдзень.
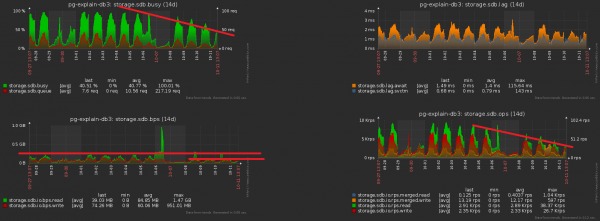
#3. «Размазваем» пікавую нагрузку
Адна з вялікіх бед нагружаных сістэм - гэта залішняя сінхранізацыя нейкіх аперацый таго, якія не патрабуюць. Часам "таму што не заўважылі", часам "так было прасцей", але рана ці позна даводзіцца ад яе пазбаўляцца.
Набліжаем папярэднюю карцінку — і бачым, што дыск у нас «кача» па нагрузцы з двухразовай амплітудай паміж суседнімі адлікамі, чаго відавочна "статыстычна" не павінна быць пры такой колькасці аперацый:
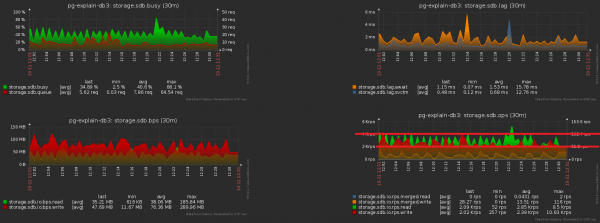
Дабіцца гэтага дастаткова проста. У нас на маніторынг было заведзена ўжо амаль 1000 сервераў, кожны апрацоўваецца асобным лагічным струменем, а кожны струмень скідае назапашаную інфармацыю для адпраўкі ў базу з вызначанай перыядычнасцю, прыкладна так:
setInterval(sendToDB, interval)Праблема тут крыецца роўна ў тым, што усе патокі стартуюць прыкладна ў адзін час, таму моманты адпраўкі ў іх амаль заўсёды супадаюць "да кропкі". Упс №2…
На шчасце, кіруецца гэта дастаткова лёгка, даданнем «выпадковай» разбежкі па часе:
setInterval(sendToDB, interval * (1 + 0.1 * (Math.random() - 0.5)))#4. Які кэшуецца, што трэба можна
Трэцяя традыцыйная праблема highload - адсутнасць кэша там, дзе ён мог бы быць.
Напрыклад, мы зрабілі магчымасць аналізу ў разрэзе вузлоў плана (усе гэтыя Seq Scan on users), але адразу падумаць, што яны, у масе, аднолькавыя - забыліся.
Не, вядома, у базу нічога паўторна не пішацца, гэта адсякае трыгер з INSERT ... ON CONFLICT DO NOTHING. Але да базы гэтыя дадзеныя далятаюць усё роўна, ды яшчэ і лішняе чытанне для праверкі канфлікту рабіць даводзіцца. Упс №3…
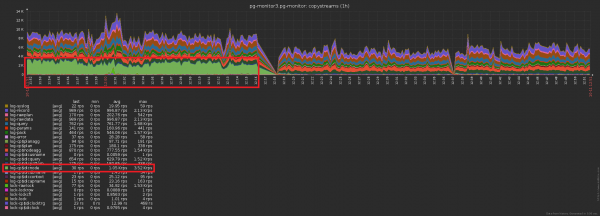
Розніца па колькасці якія адпраўляюцца ў базу запісаў да/пасля ўключэння кэшавання – відавочная:
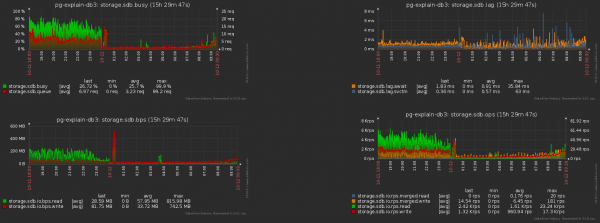
А гэта - спадарожнае падзенне нагрузкі на сховішча:
Разам
"Тэрабайт-у-суткі" толькі гучыць страшна. Калі вы ўсё робіце правільна, тое гэта ўсяго толькі 2^40 байт / 86400 секунд = ~12.5MB/s, Што трымалі нават настольныя IDE-шрубы. 🙂
А калі сур'ёзна, то нават пры дзесяціразовым "перакосе" нагрузкі на працягу сутак, вы спакойна можаце ўкласціся ў магчымасці сучасных SSD.

Крыніца: habr.com
