

Поздрави хабр.
Ако някой управлява системата и се натъкна на проблем с производителността на хранилището (IO, изразходвано дисково пространство), тогава шансът ClickHouse да бъде разглеждан като заместител трябва да бъде близо до единица. Това твърдение предполага, че внедряване на трета страна вече се използва като приемащ демон, например или .
ClickHouse решава добре описаните проблеми. Например, след изливане на 2TiB данни от whisper, те се побират в 300GiB. Няма да се спирам подробно на сравнението, има достатъчно статии по тази тема. Освен това доскоро не всичко беше перфектно с нашето хранилище в ClickHouse.
Проблеми с консумираното пространство
На пръв поглед всичко трябва да работи добре. Следване , създайте конфигурация за схемата за съхранение на показатели (по-нататък retention), след това създайте таблица според препоръката на избрания graphite-web бекенд: + или , в зависимост от това кой стек се използва. И… се задейства бомба със закъснител.
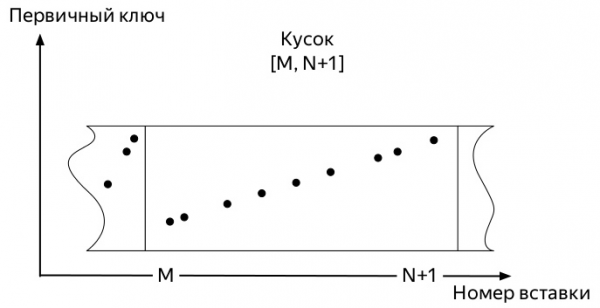
За да разберете кой, трябва да знаете как работят вложките и по-нататъшния жизнен път на данните в таблиците на семейните двигатели *MergeTree ClickHouse (диаграми, взети от Алексей Зателепин):
- Вмъкнато
блокданни. В нашия случай това са показатели.

- Всеки такъв блок се сортира според ключа, преди да бъде записан на диска.
ORDER BYПосоченото кога е създадена таблицата. - След сортиране,
кусок(part) данните се записват на диск.
- Сървърът следи във фонов режим, за да няма много такива парчета и пуска фон
слияния(merge, след това обединете).
- Сървърът спира самостоятелно да стартира сливания веднага щом данните спрат да се вливат активно
партицию(partition), но можете да стартирате процеса ръчно с командатаOPTIMIZE. - Ако в дяла е останало само едно парче, тогава няма да можете да започнете сливането с обичайната команда, трябва да използвате
OPTIMIZE ... FINAL
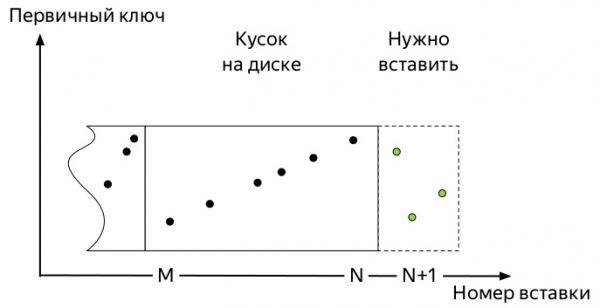
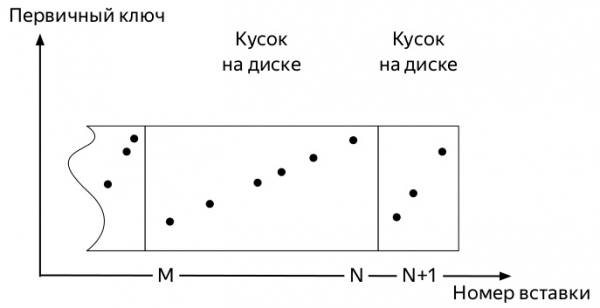
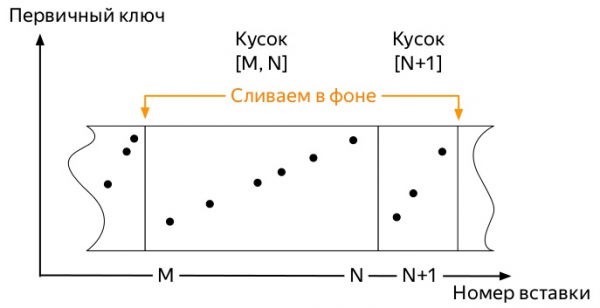
И така, пристигат първите показатели. И те заемат малко място. Последващите събития могат да варират донякъде в зависимост от много фактори:
- Ключът на дяла може да бъде много малък (един ден) или много голям (няколко месеца).
- Конфигурацията за задържане може да побере няколко значими прага за агрегиране на данни в активния дял (където се записват показателите) или може би не.
- Ако има много данни, тогава най-ранните парчета, които вече може да са огромни поради фоново сливане (при избор на неоптимален ключ за разделяне), няма да се слеят с нови малки парчета.
И винаги завършва едно и също. Мястото, заемано от показателите в ClickHouse, нараства само ако:
- не се прилагат
OPTIMIZE ... FINALръчно или - не вмъквайте данни във всички дялове на текуща база, за да започнете фоново сливане рано или късно
Вторият метод изглежда най-лесен за изпълнение и следователно е грешен и е тестван на първо място.
Написах доста прост скрипт на Python, който изпраща фиктивни показатели за всеки ден през последните 4 години и се изпълнява всеки час с cron.
Тъй като цялата работа на ClickHouse DBMS се основава на факта, че тази система рано или късно ще свърши цялата фонова работа, но не се знае кога, не успях да изчакам момента, в който старите огромни парчета благоволят да започнат да се сливат с нови малки. Стана ясно, че трябва да намерим начин да автоматизираме принудителните оптимизации.

Информация в системните таблици на ClickHouse
Нека да разгледаме структурата на таблицата . Това е изчерпателна информация за всяка част от всички маси на сървъра на ClickHouse. Съдържа, наред с други неща, следните колони:
- име на база данни (
database); - име на таблица (
table); - име на дял и ID (
partition&partition_id); - когато парчето е създадено (
modification_time); - минимална и максимална дата в парчето (разделянето е по дни) (
min_date&max_date);
Има и маса , със следните интересни полета:
- име на база данни (
Tables.database); - име на таблица (
Tables.table); - възрастта на показателя, когато трябва да се приложи следващото обобщаване (
age);
И така:
- Имаме таблица с блокове и таблица с правила за агрегиране.
- Обединяваме тяхното пресичане и получаваме всички *GraphiteMergeTree таблици.
- Търсим всички дялове, в които:
- повече от една бройка
- или е дошло времето за прилагане на следващото правило за агрегиране и
modification_timeпо-стари от този момент.
Изпълнение
Това искане
SELECT
concat(p.database, '.', p.table) AS table,
p.partition_id AS partition_id,
p.partition AS partition,
-- Самое "старое" правило, которое может быть применено для
-- партиции, но не в будущем, см (*)
max(g.age) AS age,
-- Количество кусков в партиции
countDistinct(p.name) AS parts,
-- За самую старшую метрику в партиции принимается 00:00:00 следующего дня
toDateTime(max(p.max_date + 1)) AS max_time,
-- Когда партиция должна быть оптимизированна
max_time + age AS rollup_time,
-- Когда самый старый кусок в партиции был обновлён
min(p.modification_time) AS modified_at
FROM system.parts AS p
INNER JOIN
(
-- Все правила для всех таблиц *GraphiteMergeTree
SELECT
Tables.database AS database,
Tables.table AS table,
age
FROM system.graphite_retentions
ARRAY JOIN Tables
GROUP BY
database,
table,
age
) AS g ON
(p.table = g.table)
AND (p.database = g.database)
WHERE
-- Только активные куски
p.active
-- (*) И только строки, где правила аггрегации уже должны быть применены
AND ((toDateTime(p.max_date + 1) + g.age) < now())
GROUP BY
table,
partition
HAVING
-- Только партиции, которые младше момента оптимизации
(modified_at < rollup_time)
-- Или с несколькими кусками
OR (parts > 1)
ORDER BY
table ASC,
partition ASC,
age ASCвръща всеки от дяловете на таблицата *GraphiteMergeTree, които трябва да бъдат обединени, за да се освободи дисково пространство. Остава само случаят с малките неща: прегледайте всички с молба OPTIMIZE ... FINAL. Окончателното изпълнение също взе предвид факта, че няма нужда да докосвате дялове с активен запис.
Това прави проектът. . Бивши колеги от Yandex.Market го тестваха в производство, резултатът от работата може да се види по-долу.
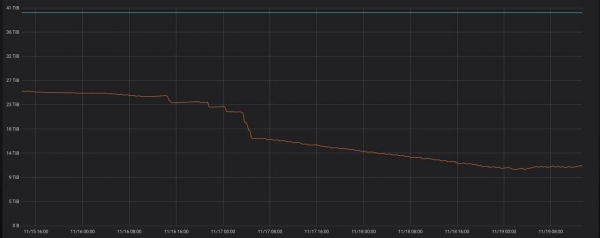
Ако стартирате програмата на сървър с ClickHouse, тя просто ще започне да работи в режим на демон. Веднъж на час ще се изпълнява заявка, като се проверява дали има нови дялове, по-стари от три дни, които могат да бъдат оптимизирани.
В близко бъдеще - да се осигурят поне deb пакети, а ако може - и rpm.
Вместо заключение
През последните 9+ месеца бях в моята компания прекара много време в готвене на кръстопътя на ClickHouse и graphite-web. Беше добро изживяване, което доведе до бърз преход от whisper към ClickHouse като хранилище на показатели. Надявам се, че тази статия е нещо като начало на цикъл за това какви подобрения сме направили в различни части на този стек и какво ще бъде направено в бъдеще.
Няколко литра бира и админ дни бяха изразходвани за разработването на заявката, заедно с за което искам да му изкажа своята благодарност. А също и за преглед на тази статия.
Източник: www.habr.com
