

Празниците свършиха и ние се завръщаме с втората ни публикация от поредицата Istio Service Mesh.

Днешната тема е „Прекъсвач“, което на руски означава „автоматичен превключвател“ или, по-разговорно, „предпазител“. В Istio обаче този предпазител изключва дефектни контейнери, а не късо съединени или претоварени вериги.
Как би трябвало да работи в идеалния случай
Когато микросървисите се управляват от Kubernetes, например, в рамките на платформата OpenShift, те автоматично се мащабират нагоре и надолу в зависимост от натоварването. Тъй като микросървисите се изпълняват в pod-ове, множество екземпляри на контейнеризирана микросървис могат да се изпълняват на една крайна точка и Kubernetes ще маршрутизира заявките и ще балансира натоварването между тях. И в идеалния случай всичко това трябва да работи перфектно.
Спомняме си, че микросървисите са малки и ефимерни. Ефимерността, която тук се отнася до лекотата на възникване и изчезване, често се подценява. Раждането и смъртта на поредния екземпляр на микросървис в под е напълно очаквано; OpenShift и Kubernetes се справят добре с това и всичко работи чудесно - но отново, това е само на теория.
Как всъщност работи
Сега си представете, че даден екземпляр на микросървис или контейнер е станал неизползваем: или не отговаря (грешка 503), или, още по-лошо, отговаря, но твърде бавно. С други думи, той се срива или не отговаря, но не се премахва автоматично от пула. Какво трябва да направите в този случай? Да опитате отново? Да го премахнете от маршрутизацията? И какво означава „твърде бавен“? Колко е това и кой го определя? Може би просто трябва да му дадете почивка и да опитате отново по-късно? Ако е така, за колко време?
Какво е изхвърляне на басейн в Istio?
Тук се намесва Istio със своите механизми за защита Circuit Breaker, които временно премахват дефектни контейнери от пула ресурси за маршрутизиране и балансиране на натоварването, като прилагат процедурата за изхвърляне на пула.
Използвайки стратегия за откриване на отклонения, Istio открива подове, които не са синхронизирани, и ги премахва от пула с ресурси за определено време, наречено прозорец за заспиване.
За да покажем как работи това в Kubernetes на платформата OpenShift, нека започнем със екранна снимка на нормално работещи микросървиси от примерното хранилище. Тук имаме два pod-а, v1 и v2, всеки от които изпълнява по един контейнер. Когато не се използват правилата за маршрутизиране на Istio, Kubernetes по подразбиране използва равномерно балансирано кръгово маршрутизиране:
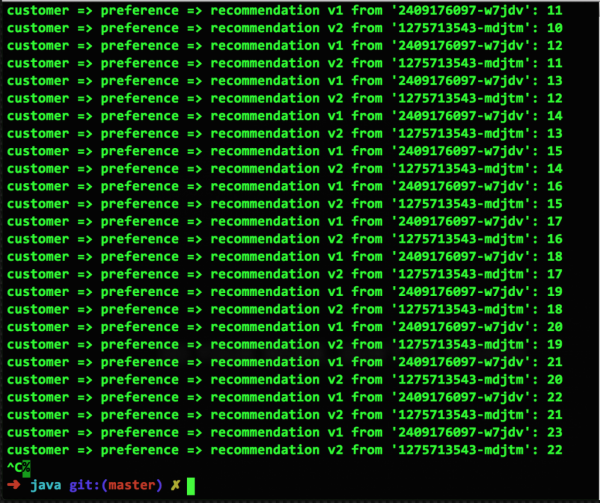
Подготовка за провал
Преди да извършим изхвърляне на Pool, трябва да създадем правило за маршрутизиране на Istio. Да кажем, че искаме да разпределим заявките между pod-овете 50/50. Ще увеличим и броя на v2 контейнерите от един на два, ето така:
oc scale deployment recommendation-v2 --replicas=2 -n tutorial
Сега настройваме правило за маршрутизиране, така че трафикът да се разпределя между подовете в съотношение 50/50.

И ето как изглежда резултатът от това правило:
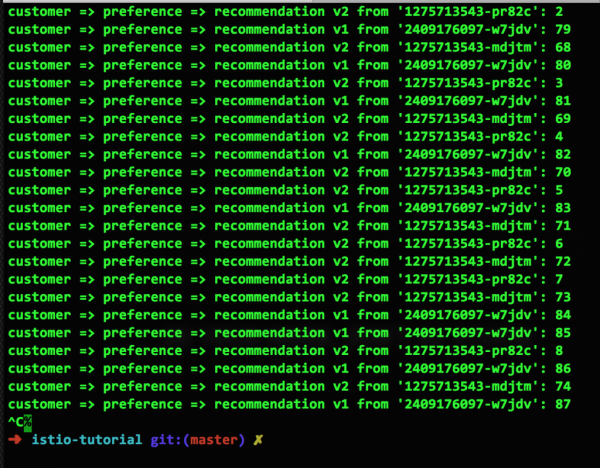
Някой може да се усъмни, че този екран не е 50/50, а 14:9, но ситуацията ще се подобри с времето.
Предизвикваме бъг
Сега нека деактивираме един от двата v2 контейнера, така че да имаме един здрав v1 контейнер, един здрав v2 контейнер и един повреден v2 контейнер:
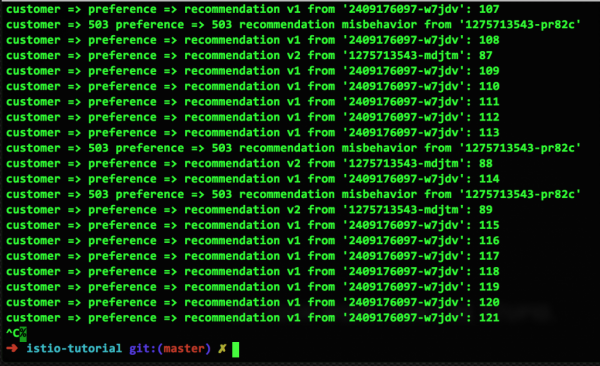
Ние решаваме проблема
И така, имаме повреден контейнер и е време за изхвърляне от пула (Pool Ejection). Използвайки много проста конфигурация, ще изключим този повреден контейнер от всички маршрути за 15 секунди, надявайки се, че ще се възстанови сам (чрез рестартиране или възстановяване на производителността). Ето как изглежда тази конфигурация и резултатите:

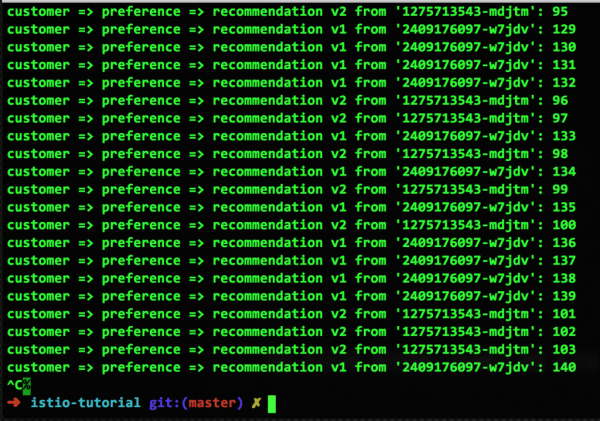
Както виждате, дефектният v2 контейнер вече не се използва за маршрутизиране на заявки, защото е премахнат от пула. След 15 секунди обаче той автоматично ще се върне в пула. Всъщност току-що демонстрирахме как работи изхвърлянето от пула.
Нека започнем да изграждаме архитектура
Изхвърлянето на пула, комбинирано с възможностите за мониторинг на Istio, ви позволява да започнете изграждането на рамка за автоматична подмяна на повредени контейнери, за да намалите, ако не и да елиминирате, времето на престой и повреди.
НАСА има едно силно мото - Провалът не е опция, авторът на което се смята за ръководител на полета Може да се преведе на руски като „Провалът не е опция“ и идеята е, че всичко може да се накара да работи с достатъчно воля. В реалния живот обаче провалите не се случват просто така; те са неизбежни, навсякъде и във всичко. И така, как да се справите с тях в случая с микросървисите? Според нас е по-добре да се разчита не на волята, а на възможностите на контейнерите. , И .
Както вече споменахме, Istio прилага добре установената концепция за прекъсвачи във физическия свят. Точно както електрическият прекъсвач прекъсва проблемна част от веригата, софтуерният прекъсвач на Istio прекъсва връзката между потока от заявки и проблемния контейнер, когато нещо се обърка с крайната точка, като например срив или бавна работа на сървър.
Освен това, във втория случай проблемите само се увеличават, тъй като забавянето на един контейнер не само причинява каскада от забавяния в услугите, които имат достъп до него, и в резултат на това намалява производителността на системата като цяло, но и генерира повтарящи се заявки към вече бавна услуга, което само влошава ситуацията.
Предпазител на теория
Прекъсвачът е прокси сървър, който контролира потока от заявки към крайна точка. Когато тази крайна точка спре да работи или, в зависимост от конфигурираните настройки, започне да се забавя, прокси сървърът прекъсва връзката с контейнера. След това трафикът се пренасочва към други контейнери, просто за целите на балансирането на натоварването. Връзката остава отворена за определен прозорец за заспиване, например две минути, и след това се счита за полуотворена. Опит за изпращане на следващата заявка определя последващото състояние на връзката. Ако услугата е наред, връзката се връща в работещо състояние и отново се затваря. Ако услугата все още не работи, връзката се прекъсва и прозорецът за заспиване се активира отново. Ето опростена диаграма на прехода на състоянието на прекъсвача:
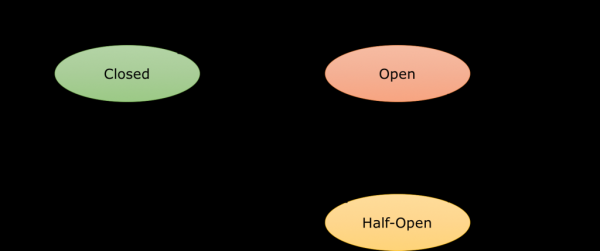
Важно е да се отбележи, че всичко това се случва на ниво системна архитектура, така да се каже. Следователно, в даден момент ще трябва да научите приложенията си да работят с Circuit Breaker, например, като предоставите стойност по подразбиране в отговор или, ако е възможно, като игнорирате съществуването на услугата. Това се постига с помощта на шаблона bulkhead, но е извън обхвата на тази статия.
Автоматичен прекъсвач на практика
За този пример ще изпълним две версии на нашата микроуслуга за препоръки на OpenShift. Версия 1 ще работи нормално, но във v2 ще добавим забавяне, за да симулираме лаг на сървъра. За да видите резултатите, използвайте инструмента :
siege -r 2 -c 20 -v customer-tutorial.$(minishift ip).nip.io
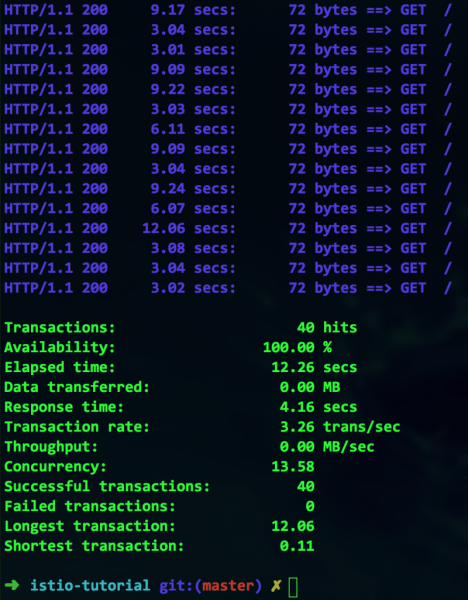
Всичко изглежда работи, но на каква цена? На пръв поглед имаме 100% наличност, но погледнете по-отблизо – максималната продължителност на транзакцията е колосалните 12 секунди. Това очевидно е пречка и трябва да се реши.
За да направим това, ще използваме Istio, за да предотвратим извиквания към забавящи контейнери. Ето как изглежда съответната конфигурация, използваща Circuit Breaker:

Последният ред с параметъра httpMaxRequestsPerConnection показва, че връзката трябва да бъде затворена при опит за създаване на втора връзка в допълнение към съществуващата. Тъй като нашият контейнер симулира бавна услуга, подобни ситуации ще се случват периодично и тогава Istio ще върне грешка 503, а ето какво ще покаже Siege:
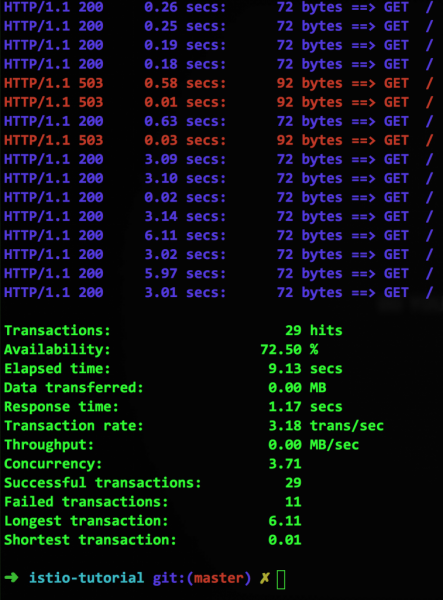
Добре, имаме прекъсвач, какво следва?
И така, имплементирахме автоматично изключване, без да докосваме изходния код на самите услуги. Използвайки Circuit Breaker и процедурата Pool Ejection, описана по-горе, можем да премахваме бавни контейнери от пула с ресурси, докато се върнат към нормалното си състояние, и да проверяваме състоянието им през определен интервал – в нашия пример, на всеки две минути (параметърът sleepWindow).
Моля, обърнете внимание, че способността на приложението да реагира на грешка 503 все още е дефинирана на ниво изходен код. Съществуват различни стратегии за справяне с Circuit Breaker, в зависимост от ситуацията.
В следващата публикация: Ще разгледаме проследяването и мониторинга, които са вградени в Istio или лесно се добавят, както и как умишлено да се въвеждат грешки в системата.
Източник: www.habr.com
