

Разработката на сторидж е дълъг и сериозен бизнес.
Много в живота на един проект зависи от това колко добре са обмислени обектният модел и основната структура в началото.
Общоприетият подход е бил и остава различни комбинации от звездната схема с третата нормална форма. Като правило, според принципа: първоначални данни - 3NF, витрини - звезда. Този подход, изпитан във времето и подкрепен от много изследвания, е първото (и понякога единственото) нещо, което идва на ум на опитен DWH специалист, когато мисли как трябва да изглежда едно аналитично хранилище.
От друга страна, бизнесът като цяло и изискванията на клиентите в частност са склонни да се променят бързо, докато данните растат както „в дълбочина“, така и „в ширина“. И тук се проявява основният недостатък на звездата – ограничеността гъвкавост.
И ако във вашия тих и комфортен живот като DWH разработчик изведнъж:
- възникна задачата „да направим поне нещо бързо и тогава ще видим“;
- появи се бързо развиващ се проект с свързване на нови източници и промяна на бизнес модела поне веднъж седмично;
- появи се клиент, който няма представа как трябва да изглежда системата и какви функции трябва да изпълнява в крайна сметка, но е готов за експерименти и последователно усъвършенстване на желания резултат с последователен подход към него;
- ръководителят на проекта погледна с добрата новина: „И сега имаме agile!“.
Или ако просто се интересувате да научите как иначе можете да изградите хранилище - добре дошли в котката!
Какво означава "гъвкавост"?
Като начало нека дефинираме какви свойства трябва да има една система, за да се нарече „гъвкава“.
Отделно, заслужава да се спомене, че описаните свойства трябва да се отнасят конкретно за система, а не да процес неговото развитие. Ето защо, ако искате да прочетете за Agile като методология за разработка, по-добре е да прочетете други статии. Например, точно там, на Хабре, има много интересни материали (както и И ).
Това не означава, че процесът на разработка и структурата на хранилището за данни са напълно несвързани. Като цяло гъвкавото разработване на гъвкаво хранилище трябва да бъде много по-лесно. На практика обаче има повече възможности с Agile разработка на класически DWH според Kimbal и DataVault - според waterfall, отколкото щастливи съвпадения на гъвкавост в двете й форми в един проект.
И така, какви характеристики трябва да има гъвкавото съхранение? Тук има три точки:
- Ранна доставка и бързо изпълнение - това означава, че в идеалния случай първият бизнес резултат (например първите работни отчети) трябва да бъде получен възможно най-рано, тоест дори преди цялата система да бъде проектирана и внедрена. В същото време всяка следваща ревизия също трябва да отнема възможно най-малко време.
- Итеративно усъвършенстване - това означава, че всяка следваща ревизия в идеалния случай не трябва да засяга вече работещата функционалност. Именно този момент често се превръща в най-големия кошмар при големи проекти - рано или късно отделните обекти започват да придобиват толкова много връзки, че става по-лесно да се повтори напълно логиката в копие един до друг, отколкото да се добави поле към съществуваща таблица. И ако сте изненадани, че анализът на въздействието на подобренията върху съществуващи обекти може да отнеме повече време от самата ревизия, най-вероятно не сте работили с големи хранилища за данни в банкирането или телекомуникациите.
- Постоянна адаптация към променящите се бизнес изисквания - общата структура на обекта трябва да бъде проектирана не само като се вземе предвид възможното разширение, но и с очакването, че посоката на това следващо разширение не може дори да бъде мечтана на етапа на проектиране.
И да, спазването на всички тези изисквания в една система е възможно (разбира се, в определени случаи и с известни резерви).
По-долу ще прегледам две от най-популярните методологии за гъвкав дизайн за HD − котвен модел и Хранилище за данни. Извън скобите са такива отлични трикове като например EAV, 6NF (в чистата му форма) и всичко, свързано с NoSQL решения - не защото са по някакъв начин по-лоши и дори не защото в този случай статията би заплашила да придобие обем на средностатистически дисератор. Просто всичко това се отнася до решения от малко по-различен клас - или до техники, които можете да приложите в конкретни случаи, независимо от общата архитектура на вашия проект (като EAV), или до глобално различни парадигми за съхранение на информация (като графови бази данни и други опции).NoSQL).
Проблеми на “класическия” подход и техните решения в гъвкави методологии
Под „класически“ подход имам предвид добрата стара звезда (независимо от конкретното изпълнение на основните слоеве, да ме прощават привържениците на Kimball, Inmon и CDM).
1. Твърда кардиналност на връзките
Този модел се основава на ясно разделяне на данните на измервания (измерение) и факти (факт). И това, по дяволите, е логично - в края на краищата анализът на данните в преобладаващата част от случаите се свежда до анализ на определени цифрови показатели (факти) в определени раздели (измерения).
В същото време връзките между обектите се поставят под формата на връзки между таблици чрез външен ключ. Това изглежда съвсем естествено, но веднага води до първото ограничение на гъвкавостта − строго определение на кардиналността на връзките.
Това означава, че на етапа на проектиране на таблиците трябва да посочите за всяка двойка свързани обекти дали те могат да бъдат свързани като много към много или само 1 към много и „в каква посока“. Пряко зависи коя от таблиците ще има първичен ключ и коя ще има външен ключ. Промяната на това съотношение при получаване на нови изисквания най-вероятно ще доведе до преработка на основата.
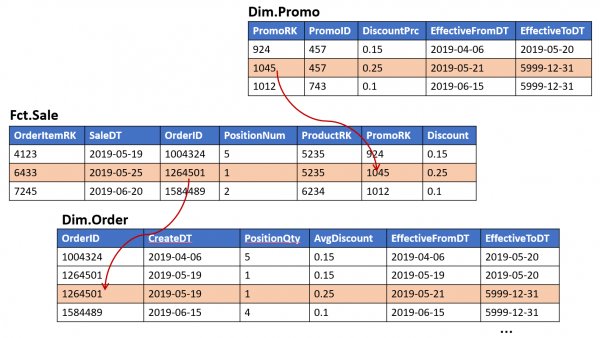
Например, когато проектирате обекта „касова бележка“, вие, разчитайки на клетвените уверения на отдела по продажбите, заложихте възможността за действие една промоция за няколко позиции за проверка (но не обратното):
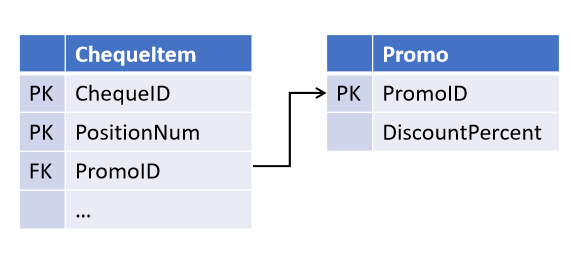
И след известно време колегите въведоха нова маркетингова стратегия, в която няколко промоции едновременно. И сега трябва да финализирате таблиците, като маркирате връзката в отделен обект.
(Всички производни обекти, в които се включва промоционалната проверка, сега също трябва да бъдат подобрени).
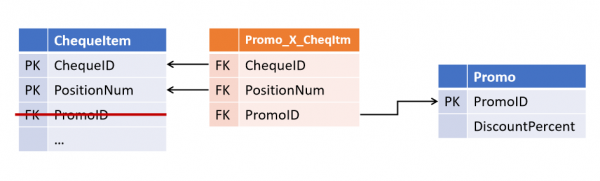
Връзки в Data Vault и Anchor Model
Оказа се доста лесно да се избегне такава ситуация: не е нужно да се доверявате на отдела по продажбите, достатъчно е всички релации първоначално се съхраняват в отделни таблици и обработвайте много към много.
Този подход е предложен Дан Линстед като част от парадигмата Хранилище за данни и се поддържа напълно Ларс Рьонбек в Модел на котвата.
В резултат на това получаваме първата отличителна черта на гъвкавите методологии:
Връзките между обектите не се съхраняват в атрибутите на родителските обекти, а са отделен тип обекти.
В Хранилище за данни такива таблици се наричат връзкаИ в Модел на котвата - Вратовръзка. На пръв поглед те са много сходни, въпреки че разликите им не се изчерпват с името (което ще бъде разгледано по-долу). И в двете архитектури свързващите таблици могат да се свързват произволен брой субекти (не е задължително 2).
Тази на пръв поглед излишък дава съществена гъвкавост при завършване. Такава структура става толерантна не само към промяна на кардиналностите на съществуващи връзки, но и към добавяне на нови - ако сега чековата позиция също има връзка към касиера, който я е прекъснал, появата на такава връзка ще бъде просто надстройка върху съществуващи таблици, без да засяга съществуващи обекти и процеси.
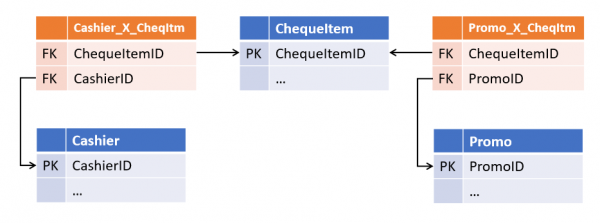
2. Дублиране на данни
Вторият проблем, решен от гъвкавите архитектури, е по-малко очевиден и присъщ на първо място. измервания тип SCD2 (бавно променящи се измервания от втория тип), макар и не само те.
В класическото хранилище измерението обикновено е таблица, която съдържа сурогатен ключ (като PK) и набор от бизнес ключове и атрибути в отделни колони.

Ако измерението поддържа управление на версиите, времевите ограничения на версията се добавят към стандартния набор от полета и множество версии се появяват в хранилището на ред в източника (по една за всяка промяна на атрибутите с версия).
Ако едно измерение съдържа поне един атрибут с версии, който се променя често, броят на версиите на такова измерение ще бъде впечатляващ (дори ако другите атрибути не са с версии или никога не се променят), а ако има няколко такива атрибута, броят на версиите може да нарасне експоненциално от броя им. Такова измерение може да заема значително количество дисково пространство, въпреки че повечето от данните, съхранявани в него, са просто дубликати на неизменни стойности на атрибути от други редове.
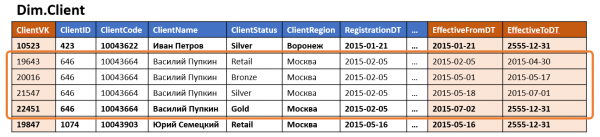
В същото време той също се използва често денормализиране - някои от атрибутите умишлено се съхраняват като стойност, а не като препратка към справочник или друго измерение. Този подход ускорява достъпа до данни чрез намаляване на броя на присъединяванията при достъп до измерение.
Обикновено това води до една и съща информация се съхранява едновременно на няколко места. Например, информацията за региона на пребиваване и членството в категорията на клиента може да се съхранява едновременно в измеренията „Клиент“ и фактите „Покупка“, „Доставка“ и „Контакти с кол център“, както и в „Клиент - Мениджър на клиенти” таблица с връзки.
По принцип горното се отнася за редовни (неверсирани) измервания, но при версионните те могат да имат различен мащаб: появата на нова версия на обект (особено в заден план) води не само до актуализиране на всички свързани таблици, но до каскадно появяване на нови версии на свързани обекти - когато таблица 1 се използва за изграждане на таблица 2, а таблица 2 се използва за изграждане на таблица 3 и т.н. Дори ако нито един атрибут на Таблица 1 не е включен в конструкцията на Таблица 3 (и са включени други атрибути на Таблица 2, получени от други източници), версията на тази конструкция ще доведе най-малко до допълнителни разходи и най-много до допълнителни версии в Таблица 3, което обикновено е „нищо общо с“ и по-надолу по веригата.
3. Нелинейна сложност на усъвършенстването
В същото време всеки нов магазин, който е изграден върху друг, увеличава броя на местата, където данните могат да се „разминават“, когато се правят промени в ETL. Това от своя страна води до увеличаване на сложността (и продължителността) на всяка следваща ревизия.
Ако горното се отнася за системи с рядко модифицирани ETL процеси, можете да живеете в такава парадигма - просто се уверете, че новите подобрения са правилно направени за всички свързани обекти. Ако ревизиите се случват често, вероятността от случайно „пропускане“ на няколко връзки се увеличава значително.
Ако в допълнение вземем предвид, че „версираният“ ETL е много по-сложен от „неверсирания“, става доста трудно да се избегнат грешки по време на честото усъвършенстване на цялата тази икономика.
Съхраняване на обекти и атрибути в Data Vault и Anchor Model
Подходът, предложен от авторите на гъвкави архитектури, може да се формулира по следния начин:
Необходимо е да се отдели това, което се променя от това, което остава непроменено. Това означава да съхранявате ключовете отделно от атрибутите.
Въпреки това, не бъркайте не е версия атрибут с непроменен: първият не съхранява историята на промените си, но може да се променя (например при коригиране на грешка при въвеждане или получаване на нови данни), вторият никога не се променя.
Гледните точки за това какво точно може да се счита за непроменено в Data Vault и модела Anchor се различават.
По отношение на архитектурата Хранилище за данни, може да се счита за непроменена целия комплект ключове — естествен (TIN на организацията, код на продукта в изходната система и др.) и сурогат. В същото време останалите атрибути могат да бъдат разделени на групи според източника и / или честотата на промените и поддържайте отделна таблица за всяка група с независим набор от версии.
В същата парадигма Котва модел се считат за непроменени само сурогатен ключ образувания. Всичко останало (включително естествените ключове) е само частен случай на неговите атрибути. При което всички атрибути са независими един от друг по подразбиране, така че за всеки атрибут трябва да се създаде отделна маса.
В Хранилище за данни извикват се таблици, съдържащи ключове на обекти Хубами (Хъб). Хъбовете винаги съдържат фиксиран набор от полета:
- Ключове за естествени обекти
- Сурогатен ключ
- Връзка към източника
- Време за запис
Записи в Хъбове никога не се променят и нямат версии. Външно хъбовете са много подобни на таблиците с ID-карти, използвани в някои системи за генериране на сурогати, но се препоръчва да се използва не целочислена последователност, а хеш от набор от бизнес ключове като сурогати в Data Vault. Този подход опростява зареждането на връзки и атрибути от източници (няма нужда да се присъединявате към центъра, за да получите сурогат, просто изчислете хеша от естествения ключ), но може да причини други проблеми (например със сблъсъци, регистър и не- отпечатване на знаци в ключове за низове и т.н. .p.), следователно не е общоприето.
Всички други атрибути на обекта се съхраняват в специални таблици, наречени Сателити (Satellit). Един хъб може да има няколко сателита, които съхраняват различни набори от атрибути.
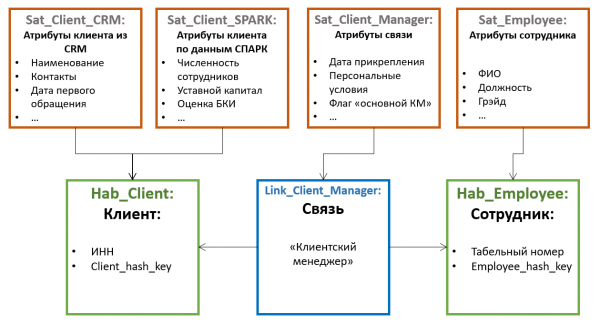
Разпределението на атрибутите между сателитите става според принципа ставна промяна - в един сателит могат да се съхраняват неверсирани атрибути (например дата на раждане и SNILS за физическо лице), в другия - рядко променящи се версии (например фамилно име и номер на паспорт), в третия - често променящи се (например адрес за доставка, категория, дата на последна поръчка и др.). Версионирането в този случай се извършва на ниво отделни сателити, а не на обекта като цяло, поради което е препоръчително да се разпределят атрибутите по такъв начин, че пресичането на версии в рамките на един сателит да е минимално (което намалява общия брой на съхранени версии).
Също така, за да се оптимизира процесът на зареждане на данни, атрибутите, получени от различни източници, често се поставят в отделни сателити.
Сателитите комуникират с Хъба чрез външен ключ (което съответства на кардиналност 1 към много). Това означава, че множество стойности на атрибути (например множество телефонни номера за контакт за един и същ клиент) се поддържат от тази архитектура „по подразбиране“.
В Модел на котвата се наричат таблици, които съхраняват ключове Котви. И те пазят:
- Само сурогатни ключове
- Връзка към източника
- Време за запис
Разгледани са естествените ключове от гледна точка на Anchor Model обикновени атрибути. Тази опция може да изглежда по-трудна за разбиране, но дава много повече възможности за идентифициране на обект.
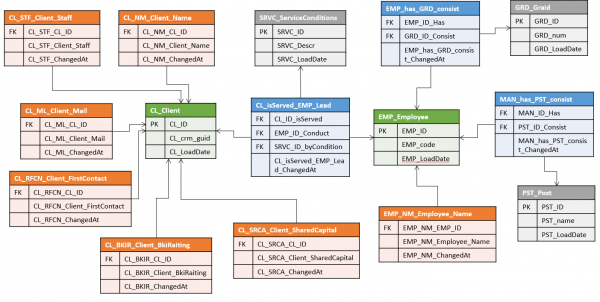
Например, ако данните за един и същи обект могат да идват от различни системи, всяка от които използва свой естествен ключ. В Data Vault това може да доведе до доста тромави конструкции от няколко хъба (по един на източник + обединяваща главна версия), докато в модела Anchor естественият ключ на всеки източник попада в негов собствен атрибут и може да се използва при зареждане независимо от всички останали.
Но тук се крие един коварен момент: ако атрибути от различни системи са комбинирани в едно цяло, най-вероятно има някои правила за лепило, чрез което системата трябва да разбере, че записи от различни източници съответстват на един екземпляр на обекта.
В Хранилище за данни тези правила вероятно ще определят формацията „сурогатен център“ на главния субект и по никакъв начин не засяга хъбовете, които съхраняват естествените ключове на източниците и техните оригинални атрибути. Ако в даден момент правилата за сливане се променят (или атрибутите, които се използват за сливане, се актуализират), ще бъде достатъчно да се формират отново сурогатните центрове.
В котвен модел такъв обект е вероятно да се съхранява в единична котва. Това означава, че всички атрибути, без значение от кой източник са получени, ще бъдат обвързани с един и същ сурогат. Разделянето на погрешно обединени записи и като цяло проследяването на уместността на обединяването в такава система може да бъде много по-трудно, особено ако правилата са доста сложни и се променят често и един и същ атрибут може да бъде получен от различни източници (въпреки че определено е възможно, защото всяка версия на атрибута запазва препратка към своя произход).
Във всеки случай, ако вашата система трябва да реализира функционалността дедупликация, сливане на записи и други MDM елементи, трябва особено внимателно да прочетете аспектите на съхраняването на естествени ключове в гъвкави методологии. Може би по-тромавият дизайн на Data Vault внезапно е по-безопасен по отношение на грешки при сливане.
котвен модел също предоставя допълнителен тип обект, наречен Възел всъщност е специален изроден тип котва, който може да съдържа само един атрибут. Предполага се, че възлите се използват за съхраняване на плоски директории (например пол, семейно положение, категория обслужване на клиенти и т.н.). За разлика от Anchor, Knot няма свързани таблици с атрибути, а единственият му атрибут (име) винаги се съхранява в същата таблица с ключа. Възлите са свързани към Anchors чрез Tie таблици по същия начин, по който анкерите са свързани помежду си.
Няма недвусмислено мнение относно използването на Nodes. Например, , който активно насърчава използването на Anchor Model в Русия, смята (не неоснователно), че е невъзможно да се каже за един справочник, че той винаги ще бъде статичен и на едно ниво, така че е по-добре да използвате пълноправен Anchor за всички обекти наведнъж.
Друга важна разлика между Data Vault и Anchor Model е наличието атрибути за връзки:
В Хранилище за данни Връзките са същите пълноценни обекти като хъбовете и могат да имат собствени атрибути. В котвен модел Връзките се използват само за свързване на котви и не могат да имат свои собствени атрибути. Тази разлика води до значително различни подходи за моделиране. факти, за което ще стане дума по-нататък.
Съхранение на факти
Досега говорихме основно за моделиране на измервания. Фактите са малко по-малко ясни.
В Хранилище за данни типичен обект за съхранение на факти − Връзка, в чиито сателити се добавят реални показатели.
Този подход изглежда интуитивен. Тя осигурява лесен достъп до анализираните индикатори и като цяло е подобна на традиционна таблица с факти (само че индикаторите не се съхраняват в самата таблица, а в „съседната таблица“). Но има и клопки: едно от типичните усъвършенствания на модела - разширяването на фактологичния ключ - го прави необходимо добавяне на нов външен ключ към връзката. А това от своя страна „разваля” модулността и потенциално предизвиква нуждата от подобрения на други обекти.
В котвен модел Връзката не може да има свои собствени атрибути, така че този подход няма да работи - абсолютно всички атрибути и индикатори трябва да бъдат свързани към една конкретна котва. Изводът от това е прост - всеки факт също се нуждае от собствена котва. За част от това, което сме свикнали да възприемаме като факти, това може да изглежда естествено - например фактът на покупка е перфектно сведен до обекта „поръчка“ или „получаване“, посещението на сайт е сведено до сесия и т.н. Но има и факти, за които не е толкова лесно да се намери такъв естествен „носещ обект“ - например балансът на стоките в складовете в началото на всеки ден.
Съответно, няма проблеми с модулността при разширяване на ключа на фактите в Anchor Model (достатъчно е просто да добавите нова връзка към съответния Anchor), но проектирането на модела за показване на факти е по-малко лесно, може да се появят „изкуствени“ Anchor които отразяват обектния модел на бизнеса, не е очевидно.
Как се постига гъвкавост
Получената конструкция и в двата случая съдържа значително повече масиотколкото традиционното измерване. Но може да отнеме значително по-малко дисково пространство със същия набор от версионирани атрибути като традиционното измерение. Естествено, тук няма магия - всичко е свързано с нормализиране. Чрез разпределяне на атрибути между сателити (в Data Vault) или отделни таблици (Anchor Model), ние намаляваме (или напълно премахваме) дублиране на стойностите на някои атрибути при промяна на други.
За Хранилище за данни печалбата ще зависи от разпределението на атрибутите между сателитите и за котвен модел — е почти право пропорционална на средния брой версии на обект на измерване.
Заемането на място обаче е важно, но не и основно предимство на разделното съхраняване на атрибути. Заедно с отделното съхранение на връзки, този подход прави съхранението модулен дизайн. Това означава, че добавянето както на отделни атрибути, така и на цели нови предметни области в такъв модел изглежда така надстройка върху съществуващ набор от обекти, без да ги променяте. И точно това прави описаните методологии гъвкави.
Той също така прилича на прехода от производство на парче към масово производство - ако в традиционния подход всяка моделна маса е уникална и изисква отделно внимание, то при гъвкавите методологии това вече е набор от типични „детайли“. От една страна, има повече таблици, процесите на зареждане и извличане на данни трябва да изглеждат по-сложни. От друга страна стават типичен. Това означава, че може да има автоматизирани и управлявани от метаданни. Въпросът „как ще го поставим?“, Отговорът на който може да заеме значителна част от работата по дизайна на подобренията, сега просто не си струва (както и въпросът за въздействието на промяната на модела върху работни процеси).
Това не означава, че анализаторите в такава система изобщо не са необходими - някой все още трябва да разработи набор от обекти с атрибути и да разбере къде и как да ги зареди. Но количеството работа, както и вероятността и цената на грешка, са значително намалени. Както на етапа на анализ, така и по време на разработването на ETL, което в значителна част може да се сведе до редактиране на метаданни.
Тъмната страна
Всичко по-горе прави и двата подхода наистина гъвкави, технологични и подходящи за итеративно усъвършенстване. Разбира се, има и „бъчва с катран“, за която мисля, че вече знаете.
Декомпозирането на данни, което е в основата на модулността на гъвкавите архитектури, води до увеличаване на броя на таблиците и, съответно, отгоре за обединения при извличане. За да получите просто всички атрибути на измерение, един избор е достатъчен в класическото хранилище, а гъвкавата архитектура ще изисква редица съединения. Освен това, ако за отчетите всички тези съединения могат да бъдат написани предварително, тогава анализаторите, които са свикнали да пишат SQL на ръка, ще пострадат двойно.
Има няколко факта, които улесняват тази ситуация:
Когато работите с големи размери, почти всички негови атрибути почти никога не се използват едновременно. Това означава, че може да има по-малко присъединявания, отколкото изглежда на пръв поглед към модела. В Data Vault можете също да вземете предвид очакваната честота на споделяне, когато разпределяте атрибути към сателитите. В същото време самите Hubs или Anchors са необходими предимно за генериране и картографиране на сурогати на етапа на зареждане и рядко се използват в заявки (това важи особено за Anchors).
Всички съединения са по ключ. В допълнение, по-„компресиран“ начин за съхраняване на данни намалява излишните разходи за сканиране на таблици, където е необходимо (например при филтриране по стойност на атрибут). Това може да доведе до факта, че извличането от нормализирана база данни с куп съединения ще бъде дори по-бързо от сканирането на едно тежко измерение с много версии на ред.
Например тук в статия има подробен сравнителен тест за ефективност на модела Anchor с избор от една таблица.
Много зависи от двигателя. Много съвременни платформи имат вътрешни механизми за оптимизиране на съединенията. Например, MS SQL и Oracle могат да „пропускат“ обединения към таблици, ако техните данни не се използват никъде освен за други обединявания и не засягат крайния избор (елиминиране на таблица/съединяване), докато MPP Vertica , се оказа отличен двигател за Anchor Model, с известна ръчна оптимизация на плана за заявка. От друга страна, съхраняването на Anchor Model, например, в Click House, който има ограничена поддръжка за присъединяване, все още не изглежда като добра идея.
Освен това и за двете архитектури има специални трикове, които улесняват достъпа до данни (както по отношение на производителността на заявките, така и за крайните потребители). Например, Таблици за точка във времето в Data Vault или специални функции на таблицата в модела на котвата.
Общо
Основната същност на разглежданите гъвкави архитектури е модулността на техния „дизайн“.
Този имот позволява:
- След известна първоначална подготовка, свързана с внедряване на метаданни и писане на основни ETL алгоритми, бързо предоставя на клиента първия резултат под формата на няколко отчета, съдържащи данни само от няколко изходни обекта. За това не е необходимо да обмисляте напълно (дори и на най-високо ниво) целия обектен модел.
- Един модел на данни може да започне да работи (и полезен) само с 2-3 обекта и след това растат постепенно (по отношение на модела на котвата Николай красиво сравнение с мицел).
- Повечето подобрения, включително разширяване на предметната област и добавяне на нови източници не засяга съществуващата функционалност и не създава опасност от счупване на нещо, което вече работи.
- Благодарение на разлагането на стандартни елементи, ETL процесите в такива системи изглеждат еднакви, тяхното писане се поддава на алгоритмизиране и в крайна сметка, автоматизация.
Цената на тази гъвкавост е продуктивност. Това не означава, че е невъзможно да се постигне приемлива производителност на такива модели. По-често просто може да се нуждаете от повече усилия и внимание към детайла, за да постигнете желаните показатели.
Apps
Типове обекти Хранилище за данни
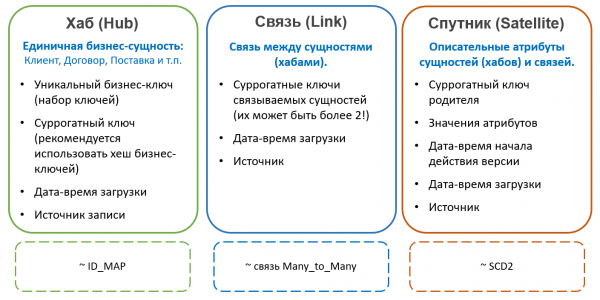
Повече за Data Vault:
Типове обекти Котва модел
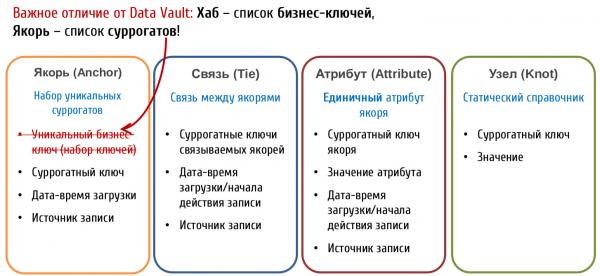
Повече за Anchor модел:
Обобщена таблица с общи черти и разлики между разглежданите подходи:

Източник: www.habr.com
