

Забележка. превод: В тази статия Banzai Cloud споделя пример за това как неговите персонализирани инструменти могат да се използват, за да направят Kafka по-лесен за използване в Kubernetes. Следните инструкции илюстрират как можете да определите оптималния размер на вашата инфраструктура и да конфигурирате самата Kafka, за да постигне необходимата пропускателна способност.

Apache Kafka е разпределена стрийминг платформа за създаване на надеждни, мащабируеми и високопроизводителни стрийминг системи в реално време. Неговите впечатляващи възможности могат да бъдат разширени с помощта на Kubernetes. За това сме разработили и инструмент, наречен . Те ви позволяват да стартирате Kafka на Kubernetes и да използвате различните му функции, като фина настройка на конфигурацията на брокера, базирано на метрика мащабиране с ребалансиране, информираност за стелажа, „меки“ (грациозен) пускане на актуализации и др.
Опитайте Supertubes във вашия клъстер:
curl https://getsupertubes.sh | sh и supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>Или контакт . Можете да прочетете и за някои от възможностите на Kafka, работата с която е автоматизирана с помощта на Supertubes и Kafka оператор. Вече сме писали за тях в блога:
- ;
- ;
- ;
- ;
- ;
- ;
- .
Когато решите да разположите Kafka клъстер на Kubernetes, вероятно ще се изправите пред предизвикателството да определите оптималния размер на основната инфраструктура и необходимостта да прецизирате вашата Kafka конфигурация, за да отговаря на изискванията за пропускателна способност. Максималната производителност на всеки брокер се определя от производителността на основните компоненти на инфраструктурата, като памет, процесор, скорост на диска, честотна лента на мрежата и т.н.
В идеалния случай конфигурацията на брокера трябва да е такава, че всички инфраструктурни елементи да се използват максимално. В реалния живот обаче тази настройка е доста сложна. По-вероятно е потребителите да конфигурират брокери, за да увеличат максимално използването на един или два компонента (диск, памет или процесор). Най-общо казано, брокерът показва максимална производителност, когато неговата конфигурация позволява най-бавният компонент да се използва в максимална степен. По този начин можем да добием груба представа за натоварването, което един брокер може да понесе.
Теоретично можем също да оценим броя на брокерите, необходими за справяне с даден товар. На практика обаче има толкова много опции за конфигурация на различни нива, че е много трудно (ако не и невъзможно) да се оцени потенциалната производителност на конкретна конфигурация. С други думи, много е трудно да се планира конфигурация въз основа на дадена производителност.
За потребителите на Supertubes обикновено използваме следния подход: започваме с някаква конфигурация (инфраструктура + настройки), след това измерваме ефективността й, коригираме настройките на брокера и повтаряме процеса отново. Това се случва, докато най-бавният компонент на инфраструктурата не се използва напълно.
По този начин получаваме по-ясна представа колко брокери са необходими на клъстера, за да се справи с определено натоварване (броят на брокерите зависи и от други фактори, като минималния брой реплики на съобщения, за да се осигури устойчивост, броя на дяловете лидери и др.). Освен това получаваме представа кои инфраструктурни компоненти изискват вертикално мащабиране.
Тази статия ще говори за стъпките, които предприемаме, за да извлечем максимума от най-бавните компоненти в първоначалните конфигурации и да измерим пропускателната способност на Kafka клъстер. Една изключително устойчива конфигурация изисква поне трима работещи брокера (min.insync.replicas=3), разпределени в три различни зони за достъпност. За да конфигурираме, мащабираме и наблюдаваме инфраструктурата на Kubernetes, ние използваме нашата собствена платформа за управление на контейнери за хибридни облаци - . Той поддържа локални (голи метал, VMware) и пет типа облаци (Alibaba, AWS, Azure, Google, Oracle), както и всяка комбинация от тях.
Мисли за инфраструктурата и конфигурацията на клъстер Kafka
За примерите по-долу избрахме AWS като облачен доставчик и EKS като дистрибуция на Kubernetes. Подобна конфигурация може да се реализира с помощта на - Дистрибуция на Kubernetes от Banzai Cloud, сертифицирана от CNCF.
диск
Amazon предлага различни . В основата gp2 и io1 има обаче SSD устройства, за да се осигури висока производителност gp2 изразходва натрупани кредити (I/O кредити), затова предпочетохме типа io1, който предлага постоянна висока производителност.
Типове инстанции
Производителността на Kafka силно зависи от кеша на страниците на операционната система, така че имаме нужда от екземпляри с достатъчно памет за брокерите (JVM) и кеша на страниците. Инстанция c5.2xголям - добро начало, тъй като има 16 GB памет и . Недостатъкът му е, че е в състояние да осигури максимална производителност само за не повече от 30 минути на всеки 24 часа. Ако вашето работно натоварване изисква максимална производителност за по-дълъг период от време, може да помислите за други типове инстанции. Точно това направихме, като се спряхме c5.4xголям. Осигурява максимална производителност 593,75 Mb/s. Максимална производителност на EBS обем io1 по-висока от инстанцията c5.4xголям, така че най-бавният елемент от инфраструктурата вероятно ще бъде I/O пропускателната способност на този тип инстанция (което нашите тестове за натоварване също трябва да потвърдят).
Сеть
Пропускателната способност на мрежата трябва да бъде достатъчно голяма в сравнение с производителността на VM екземпляра и диска, в противен случай мрежата се превръща в тясно място. В нашия случай мрежовият интерфейс c5.4xголям поддържа скорости до 10 Gb/s, което е значително по-високо от I/O пропускателната способност на VM инстанция.
Внедряване на брокер
Брокерите трябва да бъдат разгърнати (планирани в Kubernetes) в специализирани възли, за да се избегне конкуриране с други процеси за CPU, памет, мрежа и дискови ресурси.
Java версия
Логичният избор е Java 11, защото е съвместим с Docker в смисъл, че JVM правилно определя процесорите и паметта, налични за контейнера, в който работи брокерът. Знаейки, че ограниченията на процесора са важни, JVM вътрешно и прозрачно задава броя на GC нишките и JIT нишките. Използвахме образа на Кафка banzaicloud/kafka:2.13-2.4.0, който включва Kafka версия 2.4.0 (Scala 2.13) на Java 11.
Ако искате да научите повече за Java/JVM в Kubernetes, вижте нашите следните публикации:
- ;
- .
Настройки на паметта на брокера
Има два ключови аспекта при конфигурирането на паметта на брокера: настройки за JVM и за Kubernetes pod. Ограничението на паметта, зададено за pod, трябва да бъде по-голямо от максималния размер на купчината, така че JVM да има място за метапространството на Java, което се намира в нейната собствена памет, и за кеша на страницата на операционната система, който Kafka използва активно. В нашите тестове стартирахме Kafka брокери с параметри -Xmx4G -Xms2G, а ограничението на паметта за групата беше 10 Gi. Моля, обърнете внимание, че настройките на паметта за JVM могат да бъдат получени автоматично чрез -XX:MaxRAMPercentage и -X:MinRAMPercentage, въз основа на ограничението на паметта за под.
Настройки на процесора на брокера
Най-общо казано, можете да подобрите производителността чрез увеличаване на паралелизма чрез увеличаване на броя на нишките, използвани от Kafka. Колкото повече процесори са налични за Kafka, толкова по-добре. В нашия тест започнахме с ограничение от 6 процесора и постепенно (чрез итерации) повишихме техния брой до 15. Освен това зададохме num.network.threads=12 в настройките на брокера, за да увеличите броя на нишките, които получават данни от мрежата и ги изпращат. Веднага откривайки, че последователните брокери не могат да получат реплики достатъчно бързо, те повдигнаха num.replica.fetchers до 4, за да се увеличи скоростта, с която брокерите на последователи репликират съобщения от лидери.
Инструмент за генериране на натоварване
Трябва да се уверите, че избраният генератор на натоварване няма да изчерпи капацитета си, преди клъстерът Kafka (който се тества за сравнение) да достигне максималното си натоварване. С други думи, необходимо е да се извърши предварителна оценка на възможностите на инструмента за генериране на натоварване, както и да се изберат типове екземпляри за него с достатъчен брой процесори и памет. В този случай нашият инструмент ще генерира повече натоварване, отколкото клъстерът Kafka може да поеме. След много експерименти се спряхме на три екземпляра c5.4xголям, всеки от които имаше работещ генератор.
Сравнителен анализ
Измерването на ефективността е итеративен процес, който включва следните етапи:
- създаване на инфраструктура (EKS клъстер, Kafka клъстер, инструмент за генериране на натоварване, както и Prometheus и Grafana);
- генериране на натоварване за определен период за филтриране на случайни отклонения в събраните показатели за ефективност;
- коригиране на инфраструктурата и конфигурацията на брокера въз основа на наблюдаваните показатели за ефективност;
- повтаряне на процеса, докато се постигне необходимото ниво на пропускателна способност на клъстер Kafka. В същото време той трябва да бъде постоянно възпроизводим и да демонстрира минимални вариации в пропускателната способност.
Следващият раздел описва стъпките, които са извършени по време на процеса на сравнителен анализ на тестови клъстери.
Инструменти
Следните инструменти бяха използвани за бързо внедряване на базова конфигурация, генериране на натоварвания и измерване на производителността:
- за организиране на EKS клъстер от Amazon c (за събиране на Kafka и инфраструктурни показатели) и (за визуализиране на тези показатели). Ние се възползвахме интегриран в услуги, които осигуряват обединено наблюдение, централизирано събиране на регистрационни файлове, сканиране за уязвимости, възстановяване след бедствие, сигурност от корпоративно ниво и много други.
- — инструмент за тестване на натоварване на клъстер Kafka.
- Табла за управление на Grafana за визуализиране на Kafka показатели и инфраструктура: , .
- Supertubes CLI за най-лесния начин да настроите Kafka клъстер на Kubernetes. Zookeeper, Kafka operator, Envoy и много други компоненти са инсталирани и правилно конфигурирани за стартиране на готов за производство Kafka клъстер на Kubernetes.
- За монтаж supertubes CLI използвайте предоставените инструкции .
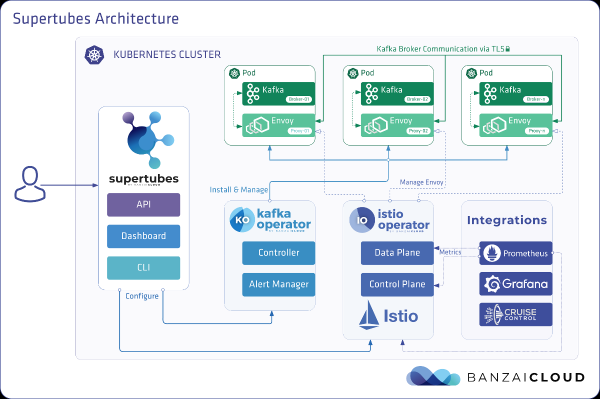
EKS клъстер
Подгответе EKS клъстер със специални работни възли c5.4xголям в различни зони за наличност за подове с брокери на Kafka, както и специални възли за генератор на натоварване и инфраструктура за наблюдение.
banzai cluster create -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/cluster_eks_202001.jsonСлед като EKS клъстерът е готов и работи, активирайте неговата интеграция — тя ще разположи Прометей и Графана в клъстер.
Компоненти на системата Kafka
Инсталирайте системните компоненти на Kafka (Zookeeper, kafka-operator) в EKS с помощта на supertubes CLI:
supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>Кафка клъстер
По подразбиране EKS използва EBS томове от тип gp2, така че трябва да създадете отделен клас за съхранение въз основа на томове io1 за клъстер Kafka:
kubectl create -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: "50"
fsType: ext4
volumeBindingMode: WaitForFirstConsumer
EOF Задайте параметъра за брокери min.insync.replicas=3 и разположете брокерски модули на възли в три различни зони на достъпност:
supertubes cluster create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/kafka_202001_3brokers.yaml --wait --timeout 600Теми
Изпълнихме паралелно три екземпляра на генератор на натоварване. Всеки от тях пише в своя тема, тоест имаме нужда от общо три теми:
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest1
spec:
name: perftest1
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest2
spec:
name: perftest2
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest3
spec:
name: perftest3
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOFЗа всяка тема коефициентът на репликация е 3 — минималната препоръчителна стойност за високо достъпни производствени системи.
Инструмент за генериране на натоварване
Пуснахме три копия на генератора на натоварване (всяко е написано в отделна тема). За модули за генериране на натоварване трябва да зададете афинитет на възел, така че да бъдат планирани само на възлите, разпределени за тях:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: loadtest
name: perf-load1
namespace: kafka
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: loadtest
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: loadtest
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nodepool.banzaicloud.io/name
operator: In
values:
- loadgen
containers:
- args:
- -brokers=kafka-0:29092,kafka-1:29092,kafka-2:29092,kafka-3:29092
- -topic=perftest1
- -required-acks=all
- -message-size=512
- -workers=20
image: banzaicloud/perfload:0.1.0-blog
imagePullPolicy: Always
name: sangrenel
resources:
limits:
cpu: 2
memory: 1Gi
requests:
cpu: 2
memory: 1Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30Няколко точки за отбелязване:
- Генераторът на натоварване генерира съобщения с дължина 512 байта и ги публикува в Kafka на партиди от 500 съобщения.
- Използване на аргумент
-required-acks=allПубликуването се счита за успешно, когато всички синхронизирани реплики на съобщението са получени и потвърдени от брокерите на Kafka. Това означава, че в бенчмарка измервахме не само скоростта на лидерите, получаващи съобщения, но и техните последователи, които репликират съобщения. Целта на този тест не е да се оцени скоростта на четене на потребителите (потребители) наскоро получени съобщения, които все още остават в кеша на страницата на ОС, и сравнението му със скоростта на четене на съобщенията, съхранени на диска. - Генераторът на натоварване управлява 20 работници паралелно (
-workers=20). Всеки работник съдържа 5 производителя, които споделят връзката на работника с клъстера Kafka. В резултат на това всеки генератор има 100 производители и всички те изпращат съобщения до клъстера Kafka.
Мониторинг на здравето на клъстера
По време на тестването на натоварването на клъстера Kafka ние също така наблюдавахме неговото здраве, за да гарантираме, че няма рестартиране на под, няма несинхронизирани реплики и максимална производителност с минимални колебания:
- Генераторът на натоварване записва стандартна статистика за броя на публикуваните съобщения и процента на грешки. Процентът грешки трябва да остане същият
0,00%. - , разгърнат от kafka-operator, предоставя табло за управление, където можем също да наблюдаваме състоянието на клъстера. За да видите този панел, направете:
supertubes cluster cruisecontrol show -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> - Ниво на ISR (брой „в синхрон“ реплики) свиването и разширяването са равни на 0.
Резултати от измерването
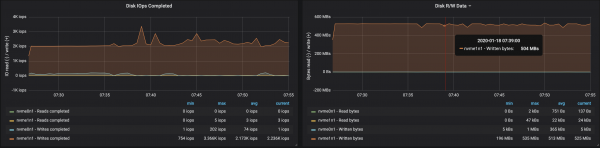
3 брокера, размер на съобщението - 512 байта
С дялове, равномерно разпределени между трима брокера, успяхме да постигнем производителност ~500 Mb/s (приблизително 990 хиляди съобщения в секунда):



Консумацията на памет на JVM виртуалната машина не надвишава 2 GB:



Пропускателната способност на диска достигна максималната пропускателна способност на I/O възел и на трите екземпляра, на които работеха брокерите:
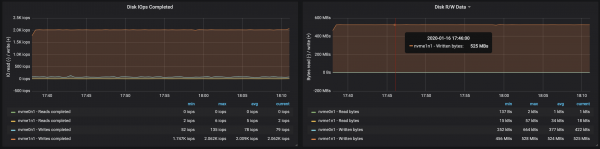
От данните за използването на паметта от възлите следва, че системното буфериране и кеширане са отнели ~10-15 GB:



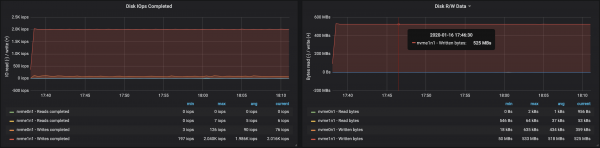
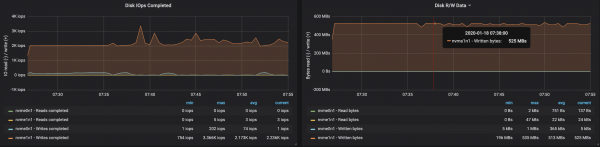
3 брокера, размер на съобщението - 100 байта
Тъй като размерът на съобщението намалява, пропускателната способност пада с приблизително 15-20%: времето, прекарано в обработка на всяко съобщение, се отразява на това. Освен това натоварването на процесора се е увеличило почти двойно.



Тъй като брокерските възли все още имат неизползвани ядра, производителността може да бъде подобрена чрез промяна на конфигурацията на Kafka. Това не е лесна задача, така че за да увеличите пропускателната способност е по-добре да работите с по-големи съобщения.
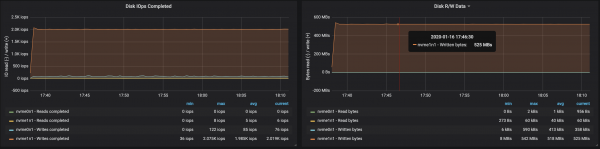
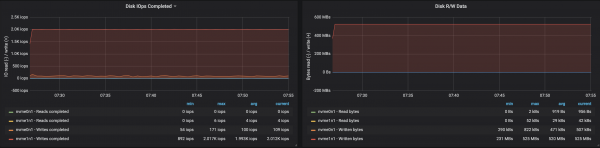
4 брокера, размер на съобщението - 512 байта
Можете лесно да увеличите производителността на клъстер Kafka, като просто добавите нови брокери и поддържате баланс на дяловете (това гарантира, че натоварването е равномерно разпределено между брокерите). В нашия случай, след добавяне на брокер, пропускателната способност на клъстера се увеличи до ~580 Mb/s (~1,1 милиона съобщения в секунда). Ръстът се оказа по-малък от очакваното: това се обяснява главно с дисбаланса на дяловете (не всички брокери работят на върха на своите възможности).




Консумацията на памет на JVM машината остава под 2 GB:




Работата на брокерите с дискове беше засегната от дисбаланса на дяловете:
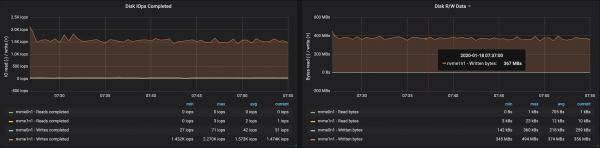
Данни
Итеративният подход, представен по-горе, може да бъде разширен, за да обхване по-сложни сценарии, включващи стотици потребители, повторно разпределение, непрекъснати актуализации, рестартиране на под и т.н. Всичко това ни позволява да оценим границите на възможностите на клъстера Kafka в различни условия, да идентифицираме тесните места в работата му и да намерим начини за борба с тях.
Проектирахме Supertubes за бързо и лесно внедряване на клъстер, конфигуриране, добавяне/премахване на брокери и теми, отговаряне на сигнали и гарантиране, че Kafka като цяло работи правилно на Kubernetes. Нашата цел е да ви помогнем да се концентрирате върху основната задача („генериране“ и „консумиране“ на Kafka съобщения) и да оставим цялата тежка работа на Supertubes и оператора на Kafka.
Ако се интересувате от Banzai Cloud технологии и проекти с отворен код, абонирайте се за компанията на адрес , или .
PS от преводача
Прочетете също в нашия блог:
- «»;
- «»;
- «".
Източник: www.habr.com
