


Хей Хабр.
Наскоро аз за това какви параметри ние като екип най-често използваме за Kafka Producer и Consumer, за да се доближим до гарантирана доставка. В тази статия искам да ви разкажа как организирахме повторната обработка на събитие, получено от Kafka в резултат на временна недостъпност на външната система.
Съвременните приложения работят в много сложна среда. Бизнес логика, обвита в модерен технологичен стек, работеща в Docker изображение, управлявано от оркестратор като Kubernetes или OpenShift, и комуникираща с други приложения или корпоративни решения чрез верига от физически и виртуални рутери. В такава среда винаги нещо може да се повреди, така че повторната обработка на събития, ако една от външните системи е недостъпна, е важна част от нашите бизнес процеси.
Как беше преди Кафка
По-рано в проекта използвахме IBM MQ за асинхронна доставка на съобщения. Ако възникне грешка по време на работата на услугата, полученото съобщение може да бъде поставено в опашка за мъртви писма (DLQ) за по-нататъшно ръчно анализиране. DLQ е създаден до входящата опашка, съобщението е прехвърлено вътре в IBM MQ.
Ако грешката е временна и можем да я определим (например ResourceAccessException при HTTP повикване или MongoTimeoutException при MongoDb заявка), тогава стратегията за повторен опит ще влезе в сила. Независимо от логиката на разклоняване на приложението, оригиналното съобщение беше преместено или в системната опашка за отложено изпращане, или в отделно приложение, създадено отдавна за повторно изпращане на съобщения. Това включва номер за повторно изпращане в заглавката на съобщението, който е свързан с интервала на забавяне или края на стратегията на ниво приложение. Ако сме стигнали до края на стратегията, но външната система все още не е достъпна, тогава съобщението ще бъде поставено в DLQ за ръчно анализиране.
Търсене в разтвор
, можете да намерите следното . Накратко, предлага се да се създаде тема за всеки интервал на забавяне и да се внедрят потребителски приложения отстрани, които ще четат съобщения с необходимото забавяне.
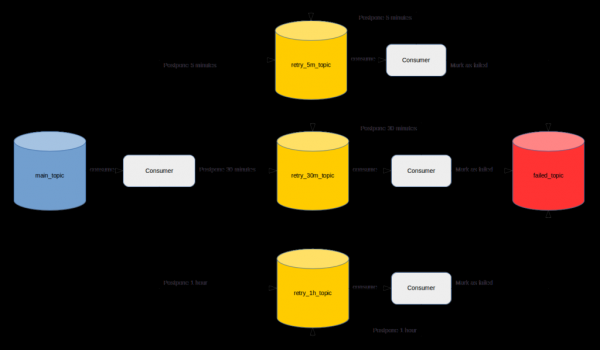
Въпреки големия брой положителни отзиви, не ми се струва съвсем успешен. На първо място, защото разработчикът, в допълнение към изпълнението на бизнес изискванията, ще трябва да отдели много време за прилагане на описания механизъм.
Освен това, ако контролът на достъпа е активиран в клъстера Kafka, ще трябва да отделите известно време за създаване на теми и предоставяне на необходимия достъп до тях. В допълнение към това ще трябва да изберете правилния параметър retention.ms за всяка от темите за повторен опит, така че съобщенията да имат време за повторно изпращане и да не изчезват от него. Внедряването и искането за достъп ще трябва да се повтарят за всяка съществуваща или нова услуга.
Нека сега да видим какви механизми spring като цяло и spring-kafka в частност ни предоставят за повторна обработка на съобщения. Spring-kafka има транзитивна зависимост от spring-retry, която предоставя абстракции за управление на различни BackOffPolicies. Това е доста гъвкав инструмент, но значителният му недостатък е съхраняването на съобщения за повторно изпращане в паметта на приложението. Това означава, че рестартирането на приложението поради актуализация или оперативна грешка ще доведе до загуба на всички чакащи повторна обработка съобщения. Тъй като тази точка е критична за нашата система, не я разглеждаме допълнително.
Самата spring-kafka предоставя няколко реализации на ContainerAwareErrorHandler, например , с който можете да обработите съобщението по-късно, без да измествате отместването в случай на грешка. Започвайки с версия на spring-kafka 2.3, стана възможно да се зададе BackOffPolicy.
Този подход позволява на повторно обработените съобщения да оцелеят при рестартиране на приложението, но все още няма DLQ механизъм. Избрахме тази опция в началото на 2019 г., оптимистично вярвайки, че DLQ няма да е необходим (имахме късмет и всъщност не ни трябваше след няколко месеца работа на приложението с такава система за преработка). Временни грешки доведоха до задействане на SeekToCurrentErrorHandler. Останалите грешки бяха отпечатани в дневника, което доведе до отместване и обработката продължи със следващото съобщение.
Окончателно решение
Реализацията, базирана на SeekToCurrentErrorHandler, ни подтикна да разработим собствен механизъм за повторно изпращане на съобщения.
На първо място, искахме да използваме съществуващия опит и да го разширим в зависимост от логиката на приложението. За приложение с линейна логика би било оптимално да спрете четенето на нови съобщения за кратък период от време, определен от стратегията за повторен опит. За други приложения исках да имам една точка, която да наложи стратегията за повторен опит. В допълнение, тази единична точка трябва да има DLQ функционалност и за двата подхода.
Самата стратегия за повторен опит трябва да се съхранява в приложението, което отговаря за извличането на следващия интервал, когато възникне временна грешка.
Спиране на потребителя за приложение с линейна логика
Когато работите с spring-kafka, кодът за спиране на потребителя може да изглежда така:
public void pauseListenerContainer(MessageListenerContainer listenerContainer,
Instant retryAt) {
if (nonNull(retryAt) && listenerContainer.isRunning()) {
listenerContainer.stop();
taskScheduler.schedule(() -> listenerContainer.start(), retryAt);
return;
}
// to DLQ
}В примера retryAt е времето за рестартиране на MessageListenerContainer, ако все още работи. Повторното стартиране ще се извърши в отделна нишка, стартирана в TaskScheduler, чието внедряване също е осигурено от пролетта.
Намираме стойността retryAt по следния начин:
- Търси се стойността на брояча на повторно повикване.
- Въз основа на стойността на брояча се търси текущият интервал на забавяне в стратегията за повторен опит. Стратегията се декларира в самото приложение, ние избрахме JSON формата, за да я съхраняваме.
- Интервалът, намерен в масива JSON, съдържа броя секунди, след които обработката ще трябва да се повтори. Този брой секунди се добавя към текущото време, за да се формира стойността за retryAt.
- Ако интервалът не бъде намерен, тогава стойността на retryAt е нула и съобщението ще бъде изпратено до DLQ за ръчно анализиране.
При този подход остава само да се запази броят на повтарящите се повиквания за всяко съобщение, което се обработва в момента, например в паметта на приложението. Поддържането на броя на повторните опити в паметта не е критично за този подход, тъй като приложението с линейна логика не може да се справи с обработката като цяло. За разлика от spring-retry, рестартирането на приложението няма да доведе до загуба на всички съобщения, за да бъдат преработени, а просто ще рестартира стратегията.
Този подход помага да се премахне натоварването от външната система, която може да е недостъпна поради много голямо натоварване. С други думи, в допълнение към повторната обработка, ние постигнахме внедряването на шаблона .
В нашия случай прагът за грешка е само 1 и за да минимизираме прекъсването на системата поради временни прекъсвания на мрежата, използваме много подробна стратегия за повторен опит с малки интервали на забавяне. Това може да не е подходящо за всички групови приложения, така че връзката между прага на грешката и стойността на интервала трябва да бъде избрана въз основа на характеристиките на системата.
Отделно приложение за обработка на съобщения от приложения с недетерминирана логика
Ето пример за код, който изпраща съобщение до такова приложение (Retryer), което ще изпрати отново до темата DESTINATION, когато бъде достигнато времето RETRY_AT:
public <K, V> void retry(ConsumerRecord<K, V> record, String retryToTopic,
Instant retryAt, String counter, String groupId, Exception e) {
Headers headers = ofNullable(record.headers()).orElse(new RecordHeaders());
List<Header> arrayOfHeaders =
new ArrayList<>(Arrays.asList(headers.toArray()));
updateHeader(arrayOfHeaders, GROUP_ID, groupId::getBytes);
updateHeader(arrayOfHeaders, DESTINATION, retryToTopic::getBytes);
updateHeader(arrayOfHeaders, ORIGINAL_PARTITION,
() -> Integer.toString(record.partition()).getBytes());
if (nonNull(retryAt)) {
updateHeader(arrayOfHeaders, COUNTER, counter::getBytes);
updateHeader(arrayOfHeaders, SEND_TO, "retry"::getBytes);
updateHeader(arrayOfHeaders, RETRY_AT, retryAt.toString()::getBytes);
} else {
updateHeader(arrayOfHeaders, REASON,
ExceptionUtils.getStackTrace(e)::getBytes);
updateHeader(arrayOfHeaders, SEND_TO, "backout"::getBytes);
}
ProducerRecord<K, V> messageToSend =
new ProducerRecord<>(retryTopic, null, null, record.key(), record.value(), arrayOfHeaders);
kafkaTemplate.send(messageToSend);
}Примерът показва, че много информация се предава в заглавки. Стойността на RETRY_AT се намира по същия начин, както при механизма за повторен опит чрез спирането на потребителя. В допълнение към DESTINATION и RETRY_AT преминаваме:
- GROUP_ID, по който групираме съобщения за ръчен анализ и опростено търсене.
- ORIGINAL_PARTITION, за да се опитате да запазите същия потребител за повторна обработка. Този параметър може да бъде нула, в който случай новият дял ще бъде получен с помощта на ключа record.key() на оригиналното съобщение.
- Актуализирана стойност COUNTER, за да следва стратегията за повторен опит.
- SEND_TO е константа, показваща дали съобщението се изпраща за повторна обработка при достигане на RETRY_AT или се поставя в DLQ.
- REASON - причината, поради която обработката на съобщението е прекъсната.
Retryer съхранява съобщения за повторно изпращане и ръчно анализиране в PostgreSQL. Таймер стартира задача, която намира съобщения с RETRY_AT и ги изпраща обратно към дяла ORIGINAL_PARTITION на темата DESTINATION с ключа record.key().
Веднъж изпратени, съобщенията се изтриват от PostgreSQL. Ръчното анализиране на съобщения се извършва в прост потребителски интерфейс, който взаимодейства с Retryer чрез REST API. Основните му функции са повторно изпращане или изтриване на съобщения от DLQ, преглед на информация за грешка и търсене на съобщения, например по име на грешка.
Тъй като контролът на достъпа е активиран на нашите клъстери, е необходимо допълнително да поискате достъп до темата, която Retryer слуша, и да позволите на Retryer да пише в темата DESTINATION. Това е неудобно, но за разлика от подхода с интервална тема, ние имаме пълноправен DLQ и потребителски интерфейс за управление.
Има случаи, когато входяща тема се чете от няколко различни потребителски групи, чиито приложения изпълняват различна логика. Повторната обработка на съобщение чрез Retryer за едно от тези приложения ще доведе до дубликат на другото. За да се предпазим от това, създаваме отделна тема за повторна обработка. Входящите и повторните теми могат да се четат от един и същ потребител без никакви ограничения.
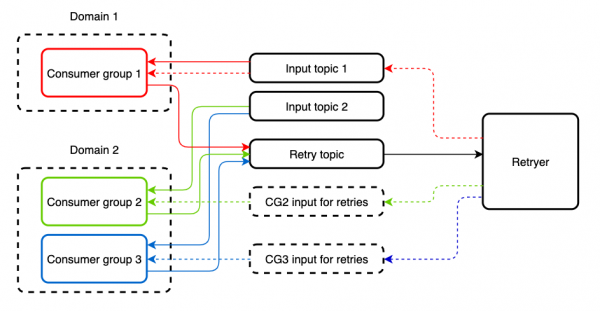
По подразбиране този подход не осигурява функционалност на прекъсвача, но може да бъде добавен към приложението чрез или нов , обвивайки местата, където се извикват външни услуги, в подходящи абстракции. Освен това става възможно да изберете стратегия за модел, който също може да бъде полезен. Например в spring-cloud-netflix това може да бъде пул от нишки или семафор.
Продукция
В резултат на това имаме отделно приложение, което ни позволява да повторим обработката на съобщения, ако някоя външна система е временно недостъпна.
Едно от основните предимства на приложението е, че може да се използва от външни системи, работещи на същия Kafka клъстер, без значителни модификации от тяхна страна! Такова приложение ще трябва само да получи достъп до темата за повторен опит, да попълни няколко заглавки на Kafka и да изпрати съобщение до Retryer. Не е необходимо изграждането на допълнителна инфраструктура. И за да намалим броя на съобщенията, прехвърлени от приложението към Retryer и обратно, ние идентифицирахме приложения с линейна логика и ги обработихме повторно чрез спиране на потребителите.
Източник: www.habr.com
