


Казвам се Юри и съм ръководител на екипа за системна администрация в Citymobil. Днес ще споделя опита си с технологията за тънко осигуряване на файлови системи. Linux Ще обясня как може да се приложи в CI/CD процесите на една компания. Ще разгледаме ситуация, в която, за да тестваме автоматично код при доставянето му в производствена среда, се нуждаем от копия за четене и запис на MySQL база данни, възможно най-близки до производствената версия.
Въведение: Защо да давате лоши съвети?
Логичен въпрос, защото има доказани механизми за мигриране на схеми на бази данни в тестови среди. Защо дори да разширявате основната неразделена СУБД до такива обеми? И не всички данни са необходими за тестване. Ще се опитам да обясня.
Преди около година, на фона на активния растеж на нашия таксиметров агрегатор (през 2018 г. извършените пътувания се увеличиха приблизително 15 пъти), обемът на данните, натоварването на сървърите и честотата на внедряване се увеличиха. Попаднахме в следната ситуация:
- Основната база данни MySQL нарасна до около 1000 таблици с общо 2,5 TB и продължи да расте.
- Нямаше начин бързо да бъде раздробен и да унищожи базата. Това не беше позволено от стария подход „Пиша в базата данни каквото искам и както искам“, куп JOIN и вътрешни зависимости на таблици.
- Нямаше механизъм за мигриране на схемата на базата данни в тестови среди.
- Нямаше автоматично тестване на кода по време на внедряването.
Исках да разреша последния проблем възможно най-бързо. Тестовете на Postman вече бяха написани за тестване на основния PHP монолит, но им липсваше актуална база данни. В същото време не можехме да създадем реплика през нощта, да я направим главна и да я оставим да бъде разкъсана на парчета през деня: много голям брой внедрявания и промени, включително в данните и схемата на базата данни, биха направили стойката не работи до средата на деня. И ограничаването на внедряването само до един работен ден би било неефективно.
Въпреки това задачата беше изпълнена: получихме първия работещ стенд в рамките на две седмици. Той претърпя много промени през последната година и продължава да се използва.
След това ще опиша подробно всички стъпки и етапи на разработване на нашето решение. Ще видите, че този метод заслужава правото си на съществуване.
Какво е „тънък излишък“?
Това е хардуерна или софтуерна технология (друго име е редки томове), която ви позволява да разпределите повече от необходимия ресурс, отколкото е наличен. В този случай разпределеният обем трябва да отговаря на критериите точно достатъчно (колкото е необходимо) и точно навреме (за необходимото време). По принцип тънкото резервиране се използва в различни системи за съхранение, за да се осигури дисково пространство в необходимите обеми, надхвърлящи действително наличните. Технологията се поддържа от различни файлови системи, например LVM2, ZFS, BTRFS. Той се използва широко в хипервайзори за виртуализация. Тънкото архивиране ни позволи бързо да създадем от моментни снимки на основната секция с данни толкова копия на тази секция, колкото са ни необходими (директория с данни на MySQL СУБД).
Първа стойка, Thin LVM технология
Тази глава може също да се нарече „Как да направите най-бързите моментни снимки на големи обеми данни, използвайки , намалявайки стабилността на файловата система и MySQL DBMS до неприлични нива.“
Тъй като вече използвахме LVM за изграждане на основните дялове на ОС, решихме да започнем с него. Като начало имахме нужда от отделна физическа машина - реплика на нашата основна MySQL база данни, на която бихме могли да създадем моментна снимка на репликата при поискване и да я повдигнем до отделен MySQL екземпляр. По време на тестването позволихме да се използват модифициращи операции в този екземпляр и след завършване на тестовете безопасно го изтрихме. Конфигурацията на сървъра беше следната:
- 2 x Intel Silver 4114 (10x2,2 GHz HT)
- 8 x 32 GB DDR4
- 8 x 1920 GB Intel SSD в Adaptec RAID контролер в RAID-10
Можете да напишете отделна статия по темата за избора между RAID контролер и софтуер RAID MD. Само да кажа, че изборът ни беше повлиян от два фактора:
- По времето, когато беше формулиран проблемът, ние инсталирахме всички СУБД на RAID контролери, така че можем да кажем, че това се е случило исторически.
- Разликата в производителността между тестовете на синтетичната файлова система и тестовете с различни MySQL операции беше минимална.
Разделихме получения RAID-10: направихме една група томове (VG) за целия том (с режийни разходи от приблизително 6,7 GB) и създадохме логически дял (Logical Volume, LV) за система от 50 GB. В нормална ситуация ние дефинираме останалата част от пространството като секцията MySQL. Но имахме нужда от тънко архивиране, така че първо създадохме така наречения пул, вътре в който създадохме раздел за /var/lib/mysql с 3,5 TB (въз основа на прогнозните обеми на базата данни):
lvcreate -l 100%FREE -T vga/thin
lvcreate -V 3.5T -T vga/thin -n mysqlФорматирахме дяла в ext4, монтирахме го, записахме реплика и получихме оригиналния стенд. След това направихме обвързване под формата на API, което трябва да създаде моментни снимки, да повдигне екземпляр на MySQL база данни на даден порт и да изтрие създадения екземпляр. Тъй като това използва изключително системни извиквания, ние избрахме обикновен bash като скриптов език и внедрихме решение с отворен код за свързване на HTTP → bash API , написано на Go.
Някой ден ще пуснем нашите bash скриптове в отворен код, но засега просто ще опиша основния алгоритъм:
Създаване на основната моментна снимка:
- Спиране на основната реплика.
- Поставяме блок върху операциите с моментната снимка на snapmain.
- Създайте нова моментна снимка.
- Стартирайте MySQL и премахнете заключването.
Създаване на база данни на произволен порт от snapmain:
- Поставяме заключване на конкретен екземпляр на базата данни (порт).
- Проверяваме дали създаването на основната моментна снимка е блокирано. Ако е там, изчакваме и проверяваме на всеки 5 секунди.
- Проверяваме дали има стара LV секция на инстанцията.
3.1 Ако има, използвайте kill -9, за да спрете екземпляра на MySQL и да изтриете LV дяла. - Създаваме нов екземпляр от snapmain.
- Подготвяме и монтираме директории за този екземпляр.
- Премахваме атрибутите на slave (файлове) и стартираме екземпляра на MySQL.
- Да го направим майстор.
- Премахваме блокировката.
Премахване на база данни на произволен порт:
- Поставяме заключване на конкретен екземпляр на базата данни (порт).
- Убийте екземпляра на MySQL, като използвате kill -9.
- Нека демонтираме директориите.
- Изтриваме LV дяла и премахваме ключалката.
Примерни команди за клониране на дялове на нов екземпляр на база данни:
lvcreate -n stage_3307 -s vga/snapmain
lvchange -ay -K vga/stage_3307
mount -o noatime,nodiratime,data=writeback /dev/mapper/vga-stage_3307 /mnt/stage_3307Сега ще ви разкажа за основния проблем, с който се сблъскахме при използването на тънко резервиране. Заседнали сме в производителността на SSD устройствата. Това се случи поради характеристиките на Thin LVM: той основно работи на ниво устройство с парчета от ниско ниво с размер по подразбиране от 4 MB. Как изглеждаше:
- Създайте моментна снимка от главния раздел /var/lib/mysql.
- Започваме репликация, за да настигнем капитана.
- Всяка промяна в таблиците на репликите принуждава стари, непроменени части от данни да бъдат съхранени в секцията за моментна снимка.
- Всяка промяна в повдигнат тестов екземпляр води до съхраняване на стари, немодифицирани части от данни в клонирана секция за моментна снимка за този екземпляр.
- Получаваме натоварване от 100% I/O операции на устройството, забавяне на всички операции и постепенно забавяне на репликата.
- До края на работния ден получаваме щанд с няколко часа изоставане.
Как се справихме с това, за да получим по-разумен резултат (основни точки):
RAID контролер:
- Всички видове кеширане са деактивирани по подразбиране.
- Задаване на обратно записване (когато данните влязат в буфера, записването приключва, преди да се извърши действителното записване на диска).
Файлова система:
- В точката на монтиране /var/lib/mysql написахме noatime,nodiratitime,data=writeback
- Деактивирано регистриране на ext4 с помощта на tune2fs.
MySQL:
- Предписано innodb_flush_method = O_DSYNC (повишена скорост на запис, като по този начин се намалява надеждността).
- Регистрацията е деактивирана, не се нуждаем от регистрационни файлове.
- Предписано innodb_buffer_pool_size = 4G (колкото по-малък е размерът на пула на InnoDB, толкова по-бързо MySQL ще се изключи при спиране и толкова по-бързо ще създадем моментна снимка).
Това не е пълен списък, особено за MySQL. Въпреки това, останалите промени са незначителни и често не са винаги или точно приложими. Например, в опит да разтоварим дисковете, дори отнехме innodb_parallel_doublewrite_path в /dev/shm, което в някои случаи ни спестява до 5 секунди при стартиране на неправилно прекратено копие.
Защо спираме MySQL преди да направим моментна снимка? В крайна сметка можем да го премахнем от работеща реплика. Така е, но новият екземпляр на базата данни на тази моментна снимка ще се счита за повреден по подразбиране и ще изисква пълно сканиране при стартиране. Спирането на реплика определено е по-бързо, въпреки че в крайна сметка е най-дългата операция в целия процес.
В резултат на това получихме по-приемливи времена и готова за употреба стойка. Въпреки че, както може да се види от най-красноречивата графика на забавянето на репликацията на основната реплика, ситуацията все още е далеч от идеалната:
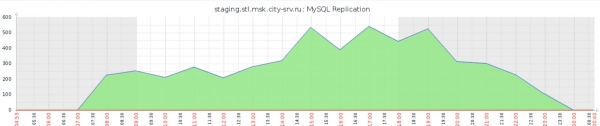
Сред другите недостатъци си струва да се отбележи практическата невъзможност за наблюдение на Thin LVM пула: в допълнение към системните стандартни функции на iostat е невъзможно да се разбере например кой елемент на пула в момента произвежда най-голямо натоварване на файловата система.
Отделно, заслужава да се отбележи един голям недостатък, свързан с описаната по-горе оптимизация: получихме стойка YOLO. Приблизително веднъж на всеки един или два месеца ext4 не можеше да издържи на такава злоупотреба и се разваляше непоправимо, което изискваше преформатиране и повторно качване на репликата. След като спечелихме в скоростта, ние безнадеждно разрушихме стабилността.
Какви показатели трябва да наблюдавате, докато използвате Thin LVM:
- Тънък пул данни %
- Thin pool метаданни %
Ако нашият щанд оцелее след изчерпване на пространството за данни (достатъчно е да почистите дисковете), тогава изчерпването на пространството за метаданни ще доведе до пълен колапс на пула и необходимостта да го възстановите от нулата.
Файловата система в пула става много фрагментирана с течение на времето. Препоръчвам да изпълнявате командата cron веднъж на ден fstrim -v /var/lib/mysql.
Междинни суми:
- Технологията е лесна за прилагане, също като самата LVM, и не изисква специални инженерни квалификации.
- Той е много подходящ за малки и не твърде натоварени бази данни. Колкото по-малка е базата данни, толкова по-малко парчета се движат около файловата система в пула и толкова по-малко е натоварването на дисковете.
- За нашата задача започнахме да търсим други решения, които ще бъдат обсъдени в следващия раздел.
Втора стойка, ZFS технология
Работех с файловата система ZFS отдавна, но тогава ZFS работеше надеждно и добре на родното си семейство операционни системи Solaris. Имаше порт към FreeBSD с доста добро ниво на имплементация. Имаше и недовършен порт към Linux, която малцина използваха. Поради структурата си за съхранение на данни B-дърво (между другото, InnoDB на MySQL има същата структура за съхранение), ZFS се представяше зле при инсталации с много голям брой файлове. Това, съчетано с необходимостта да се научат основните неща преди употреба, доведе до дългосрочно използване на тази файлова система от мен. Ext4 и xfs се появиха и станаха стандарт. Но като се има предвид, че ZFS е повече от подходящ за нашите нужди и Linux-версията, съдейки по отзивите, се е превърнала в напълно разумен продукт (макар и не напълно поддържан, поради което инсталирането на система на ZFS от нулата е възможно само с помощта на различни вуду техники), решихме да я пробваме.
По очевидни причини стойката беше избрана с подобна конфигурация (с изключение на RAID контролера). Инсталирахме осем 1920 GB SSD устройства. Нямаше желание да напишем собствено мрежово изображение, за да качим сървъра на гол ZFS, така че отхапахме 50 GB от всички дискове и направихме MD RAID-10 върху тях за системата. Останалите 1950 GB на всеки диск бяха комбинирани в ZFS аналог на RAID-10:
zpool create zpool mirror /dev/sda2 /dev/sdb2 mirror /dev/sdc2 /dev/sdd2 mirror /dev/sde2 /dev/sdf2 mirror /dev/sdg2 /dev/sdh2Създадохме секции за MySQL:
zfs create zpool/mysql
zfs set compression=gzip zpool/mysql
zfs set recordsize=128k zpool/mysql
zfs set atime=off zpool/mysql
zfs create zpool/mysql/data
zfs set recordsize=16k zpool/mysql/data
zfs set primarycache=metadata zpool/mysql/data
zfs set mountpoint=/var/lib/mysql zpool/mysql/dataМоля, имайте предвид, че сме активирали естественото компресиране на данни с gzip. Имаме много процесорни ресурси на сървъра и те не се използват напълно. В резултат на това 3 TB от нашата база данни се превърнаха в 1,6 TB и тъй като слабата връзка, както в предишния случай, е максималната производителност на диска, по-малко данни, толкова по-добре, ние Получаваме страхотен бонус от ZFS от самото начало! По време на час пик при пълно натоварване са необходими до 4 ядра, за да поддържа gzip работещ, но ние нямаме нищо против.
Тогава изпълнението вървеше по-бързо. Настройките на репликата на MySQL бяха прехвърлени от стойката на LVM като копие. Трябваше да прекарам известно време в пренаписване на скриптовете с помощта на ZFS команди, но като цяло алгоритмите останаха същите. Пример за създаване на моментна снимка:
zfs set snapdir=visible zpool/mysql/data
zfs create zpool/stage_3307
zfs clone zpool/mysql/data@snapmain zpool/stage_3307/data
zfs set mountpoint=/mnt/stage_3307 zpool/stage_3307/dataОт допълнителна настройка: преместихме ZFS дялове с метаданни и l2arc и zil регистрационни файлове в паметта. За нашата задача, както се оказа по-късно, това беше излишно, но засега оставихме тази оптимизация лесно да се промени, ако е необходимо. Един от негативните ефекти е, че след рестартиране на сървъра, трябва да създадете отново съответните области на паметта. Не се губят данни. Изрязване на състоянието на Zpool:
logs
/dev/shm/zil_slog.img ONLINE 0 0 0
cache
/dev/shm/l2arc.img ONLINE 0 0 0В тази конфигурация започнахме да тестваме стойката и получихме отлични резултати: с две едновременно работещи копия на база данни (и активна основна реплика) в моментни снимки, получихме 50-60% използване на диска.
Отървахме се от нашия основен проблем, както може да се види в графиката на забавяне на репликацията (сравнете с предишната графика в секцията Thin LVM):
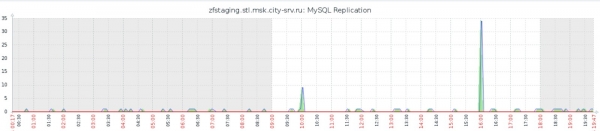
В допълнение и благодарение на това, ние значително ускорихме всички операции: пълното създаване на моментна снимка със спиране и стартиране на реплика отнема до 40 секунди, внедряването на нов MySQL екземпляр от моментна снимка отнема до 20 секунди. Което е повече от задоволително както за нас, така и за нашите тестове на програмния код.
Междинни суми:
- Резултатите напълно задоволиха нуждата ни да получим копие от производствената база данни за тестване на кода.
- Технологията изисква влизане: трябва да разберете какво е ZFS и как да работите с него.
- Не сме проверили текущото състояние на ZFS с голям брой (над 1 милион) малки файлове. Но предполагаме, че проблемът продължава, така че не бих препоръчал тази файлова система за никакво съхранение на файлове.
Каква е следващата?
Няма какво друго да правим в рамките на щанда, доволни сме от резултата. Може би в бъдеще ще добавим изключения на таблици, които не са необходими за тестване, към настройката за репликация на стойката; това допълнително ще намали размера на базата данни. Не сме тествали системата BTRFS и нейното внедряване на технология за тънко резервиране. Такава задача обаче вече не си струва, тъй като основната цел е постигната. Като цяло, разбира се, бих искал да се отдалеча от подхода, описан по-горе - да внедря миграции на работещи бази данни към тестова среда, да създам отделна верига за тестови бази данни и да започна да шардинг основната база данни. Вече прилагаме голяма част от това на практика, за което определено ще говорим в бъдещи статии.
Резултати от
Първоначалният проблем беше решен, макар и по необичаен начин. Междинните заключения описват предимствата и недостатъците на всяка от използваните технологии, така че нека решим коя технология може да се използва и кога:
- Thin LVM - за малки бази данни и когато не искате или нямате време да научите ZFS.
- ZFS - ако имате опит в работата с него или възможност да отделите време за изучаването му във всяка ситуация.
На по-високо ниво на представяне тази статия не е просто сравнение на технологията на двете файлови системи. Основната идея, която бих искал да предам и затвърдя е, че не трябва да се страхувате да мислите нестандартно в критични за бизнеса ситуации и да приемате само готови рецепти. Имало едно време можехме да поклатим главите си като цяло в техническия отдел и да кажем, че задачата за създаване на тритерабайтови копия на база данни за по-малко от минута е невъзможна и не се нуждаем от рискови технологии, нека направим правилно е. Беше възможно, но щяхме да загубим около шест месеца до една година и много пътувания на клиенти (пътуването е основният ни бизнес показател) без тестване и по време на внедряване. Действайки извън кутията, ние не загубихме много време за внедряване, натрупахме опит в нови и забравени стари технологии и предоставихме тестване в момент, когато наистина имахме нужда от него. Несъмнено това се отрази положително на всички наши показатели. Изборът винаги е ваш, а ние от своя страна ще продължим да говорим за интересни настоящи и бъдещи постижения в нашия блог.
Източник: www.habr.com
