

Прим. перев.: авторы этой статьи — инженеры из небольшой чешской компании pipetail. Им удалось собрать замечательный список из [местами банальных, но всё ещё] столь актуальных проблем и заблуждений, связанных с эксплуатацией кластеров Kubernetes.

За годы использования Kubernetes нам довелось поработать с большим числом кластеров (как управляемых, так и неуправляемых — на GCP, AWS и Azure). Со временем мы стали замечать, что некоторые ошибки постоянно повторяются. Однако в этом нет ничего постыдного: мы сами совершили большинство из них!
В статье собраны наиболее распространенные ошибки, а также упомянуто о том, как их исправлять.
1. Ресурсы: запросы и лимиты
Этот пункт определенно заслуживает самого пристального внимания и первого места в списке.
CPU request обычно либо вообще не задан, либо имеет очень низкое значение (чтобы разместить как можно больше pod’ов на каждом узле). Таким образом, узлы оказываются перегружены. Во время высокой нагрузки процессорные мощности узла полностью задействованы и конкретная рабочая нагрузка получает только то, что «запросила» путем троттлинга CPU. Это приводит к повышению задержек в приложении, таймаутам и другим неприятным последствиям. (Подробнее об этом читайте в другом нашем недавнем переводе: «» — прим. перев.)
BestEffort (крайне не рекомендуется):
resources: {}Экстремально низкий запрос CPU (крайне не рекомендуется):
resources:
Requests:
cpu: "1m"С другой стороны, наличие лимита CPU может приводить к необоснованному пропуску тактов pod’ами, даже если процессор узла загружен не полностью. Опять же, это может привести к увеличению задержек. Продолжаются споры вокруг параметра CPU CFS quota в ядре Linux и троттлинга CPU в зависимости от установленных лимитов, а также отключении квоты CFS… Увы, лимиты CPU могут вызвать больше проблем, чем способны решить. Подробнее об этом можно узнать по ссылке ниже.
Чрезмерное выделение (overcommiting) памяти может привести к более масштабным проблемам. Достижение предела CPU влечет за собой пропуск тактов, в то время как достижение предела по памяти влечет за собой «убийство» pod’а. Наблюдали когда-нибудь OOMkill? Да, речь идет именно о нем.
Хотите свести к минимуму вероятность этого события? Не распределяйте чрезмерные объемы памяти и используйте Guaranteed QoS (Quality of Service), устанавливая memory request равным лимиту (как в примере ниже). Подробнее об этом читайте в (ведущий инженер Zalando).
Burstable (более высокая вероятность получить OOMkilled):
resources:
requests:
memory: "128Mi"
cpu: "500m"
limits:
memory: "256Mi"
cpu: 2Guaranteed:
resources:
requests:
memory: "128Mi"
cpu: 2
limits:
memory: "128Mi"
cpu: 2Что потенциально поможет при настройке ресурсов?
С помощью metrics-server можно посмотреть текущее потребление ресурсов CPU и использование памяти pod’ами (и контейнерами внутри их). Скорее всего, вы уже им пользуетесь. Просто выполните следующие команды:
kubectl top pods
kubectl top pods --containers
kubectl top nodesОднако они показывают только текущее использование. С ним можно получить приблизительное представление о порядке величин, но в конечном итоге понадобится история изменения метрик во времени (чтобы ответить на такие вопросы, как: «Какова была пиковая нагрузка на CPU?», «Какой была нагрузка вчера утром?» — и т.д.). Для этого можно использовать Prometheus, DataDog и другие инструменты. Они просто получают метрики с metrics-server и хранят их, а пользователь может запрашивать их и строить соответствующие графики.
позволяет автоматизировать этот процесс. Он отслеживает историю использования процессора и памяти и настраивает новые request’ы и limit’ы на основе этой информации.
Эффективное использование вычислительных мощностей — непростая задача. Это все равно что постоянно играть в тетрис. Если вы слишком много платите за вычислительные мощности при низком среднем потреблении (скажем, ~10 %), рекомендуем обратить внимание на продукты, основанные на AWS Fargate или Virtual Kubelet. Они построены на модели биллинга serverless/pay-per-usage, что в таких условиях может оказаться дешевле.
2. Liveness и readiness probes
По умолчанию проверки состояния liveness и readiness в Kubernetes не включены. И порой их забывают включить…
Но как еще можно инициировать перезапуск сервиса в случае неустранимой ошибки? И как балансировщик нагрузки узнает, что некий pod готов принимать трафик? Или что он способен обработать больше трафика?
Часто эти пробы путают между собой:
- Liveness — проверка «живучести», которая перезапускает pod при неудачном завершении;
- Readiness — проверка готовности, она при неудаче отключает pod от сервиса Kubernetes (это можно проверить с помощью
kubectl get endpoints) и трафик на него не поступает до тех пор, пока очередная проверка не завершится успешно.
Обе эти проверки ВЫПОЛНЯЮТСЯ В ТЕЧЕНИЕ ВСЕГО ЖИЗНЕННОГО ЦИКЛА POD’А. Это очень важно.
Распространено заблуждение, что readiness-пробы запускаются только на старте, чтобы балансировщик мог узнать, что pod готов (Ready) и может приступить к обработке трафика. Однако это лишь один из вариантов их применения.
Другой — возможность узнать, что трафик на pod чрезмерно велик и перегружает его (или pod проводит ресурсоемкие вычисления). В этом случае readiness-проверка помогает снизить нагрузку на pod и «остудить» его. Успешное завершение readiness-проверки в будущем позволяет опять повысить нагрузку на pod. В этом случае (при неудаче readiness-пробы) провал liveness-проверки был бы очень контрпродуктивным. Зачем перезапускать pod, который здоров и трудится изо всех сил?
Поэтому в некоторых случаях полное отсутствие проверок лучше, чем их включение с неправильно настроенными параметрами. Как было сказано выше, если liveness-проверка копирует readiness-проверку, то вы в большой беде. Возможный вариант — настроить , а оставить в стороне.
Оба типа проверок не должны завершаться неудачей при падении общих зависимостей, иначе это приведет к каскадному (лавинообразному) отказу всех pod’ов. Другими словами, .
3. LoadBalancer для каждого HTTP-сервиса
Скорее всего, у вас в кластере есть HTTP-сервисы, которые вы хотели бы пробросить во внешний мир.
Если открыть сервис как type: LoadBalancer, его контроллер (в зависимости от поставщика услуг) будет предоставлять и согласовывать внешний LoadBalancer (не обязательно работающий на L7, скорее даже на L4), и это может сказаться на стоимости (внешний статический адрес IPv4, вычислительные мощности, посекундная тарификация) из-за необходимости создания большого числа подобных ресурсов.
В данном случае гораздо логичнее использовать один внешний балансировщик нагрузки, открывая сервисы как type: NodePort. Или, что еще лучше, развернуть что-то вроде nginx-ingress-controller (или traefik), который выступит единственным NodePort endpoint’ом, связанным с внешним балансировщиком нагрузки, и будет маршрутизировать трафик в кластере с помощью ingress-ресурсов Kubernetes.
Другие внутрикластерные (микро)сервисы, взаимодействующие друг с другом, могут «общаться» с помощью сервисов типа ClusterIP и встроенного механизма обнаружения сервисов через DNS. Только не используйте их публичные DNS/IP, так как это может повлиять на задержку и привести к росту стоимости облачных услуг.
4. Автомасштабирование кластера без учета его особенностей
При добавлении узлов в кластер и их удалении из него не стоит полагаться на некоторые базовые метрики вроде использования CPU на этих узлах. Планирование pod’а должно производиться с учетом множества ограничений, таких как affinity pod’ов/узлов, taints и tolerations, запросы ресурсов, QoS и т.д. Использование внешнего autoscaler’а, не учитывающего эти нюансы, может привести к проблемам.
Представьте, что некий pod должен быть запланирован, но все доступные мощности CPU запрошены/разобраны и pod застревает в состоянии Pending. Внешний autoscaler видит среднюю текущую загрузку CPU (а не запрашиваемую) и не инициирует расширение (scale-out) — не добавляет еще один узел. В результате данный pod не будет запланирован.
При этом обратное масштабирование (scale-in) — удаление узла из кластера — всегда сложнее реализовать. Представьте, что у вас stateful pod (с подключенным постоянным хранилищем). Persistent-тома обычно принадлежат к определенной зоне доступности и не реплицируются в регионе. Таким образом, если внешний autoscaler удалит узел с этим pod’ом, то планировщик не сможет запланировать данный pod на другой узел, так как это можно сделать только в той зоне доступности, где находится постоянное хранилище. Pod зависнет в состоянии Pending.
В Kubernetes-сообществе большой популярностью пользуется . Он работает в кластере, поддерживает API от основных поставщиков облачных услуг, учитывает все ограничения и умеет масштабироваться в вышеперечисленных случаях. Он также способен выполнять scale-in при сохранении всех установленных ограничений, тем самым экономя деньги (которые иначе были бы потрачены на невостребованные мощности).
5. Пренебрежение возможностями IAM/RBAC
Остерегайтесь использовать IAM-пользователей с постоянными секретами для машин и приложений. Организуйте временный доступ, используя роли и учетные записи служб (service accounts).
Мы часто сталкиваемся с тем, что ключи доступа (и секреты) оказываются за’hardcode’ны в конфигурации приложения, а также с пренебрежением ротацией секретов несмотря на имеющийся доступ к Cloud IAM. Используйте роли IAM и учетные записи служб вместо пользователей, где это уместно.

Забудьте о kube2iam и переходите сразу к ролям IAM для service accounts (как это описывается в Štěpán Vraný):
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::123456789012:role/my-app-role
name: my-serviceaccount
namespace: defaultОдна аннотация. Не так уж сложно, правда?
Кроме того, не наделяйте service accounts и профили инстансов привилегиями admin и cluster-admin, если они в этом не нуждаются. Это реализовать чуть сложнее, особенно в RBAC K8s, но определенно стоит затрачиваемых усилий.
6. Не полагайтесь на автоматическое anti-affinity для pod’ов
Представьте, что у вас три реплики некоторого deployment’а на узле. Узел падает, а вместе с ним и все реплики. Неприятная ситуация, так? Но почему все реплики находились на одном узле? Разве Kubernetes не должен обеспечивать высокую доступность (HA)?!
Увы, планировщик Kubernetes по своей инициативе не соблюдает правила раздельного существования (anti-affinity) для pod’ов. Их необходимо явно прописать:
// опущено для краткости
labels:
app: zk
// опущено для краткости
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- zk
topologyKey: "kubernetes.io/hostname" Вот и все. Теперь pod’ы будут планироваться на различные узлы (это условие проверяется только во время планирования, но не их работы — отсюда и requiredDuringSchedulingIgnoredDuringExecution).
Здесь мы говорим о podAntiAffinity на разных узлах: topologyKey: "kubernetes.io/hostname", — а не о разных зонах доступности. Чтобы реализовать полноценную HA, придется копнуть поглубже в эту тему.
7. Игнорирование PodDisruptionBudget’ов
Представьте, что у вас production-нагрузка в кластере Kubernetes. Периодически узлы и сам кластер приходится обновлять (или выводить из эксплуатации). PodDisruptionBudget (PDB) — это нечто вроде гарантийного соглашения об обслуживании между администраторами кластера и пользователями.
PDB позволяет избежать перебоев в работе сервисов, вызванных недостатком узлов:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: zookeeperВ этом примере вы, как пользователь кластера, заявляете администраторам: «Эй, у меня есть сервис zookeeper, и независимо от того, что вы делаете, я бы хотел, чтобы по крайней мере 2 реплики этого сервиса всегда были доступны».
Подробнее об этом можно почитать .
8. Несколько пользователей или окружений в общем кластере
Пространства имен Kubernetes (namespaces) не обеспечивают сильную изоляцию.
Распространено заблуждение, что если развернуть не-prod-нагрузку в одно пространство имен, а prod-нагрузку в другое, то они никак не будут влиять друг на друга… Впрочем, некоторый уровень изоляции можно достичь с помощью запросов/ограничений ресурсов, установки квот, задания priorityClass’ов. Некую «физическую» изоляцию в data plane обеспечивают affinities, tolerations, taints (или nodeselectors), однако подобное разделение довольно сложно реализовать.
Тем, кому необходимо совмещать оба типа рабочих нагрузок в одном кластере, придется мириться со сложностью. Если же такой потребности нет, и вам по карману завести еще один кластер (скажем, в публичном облаке), то лучше так и сделать. Это позволит достичь гораздо более высокого уровня изоляции.
9. externalTrafficPolicy: Cluster
Очень часто мы наблюдаем, что весь трафик внутрь кластера поступает через сервис типа NodePort, для которого по умолчанию установлена политика externalTrafficPolicy: Cluster. Это означает, что NodePort открыт на каждом узле в кластере, и можно использовать любой из них для взаимодействия с нужным сервисом (набором pod’ов).
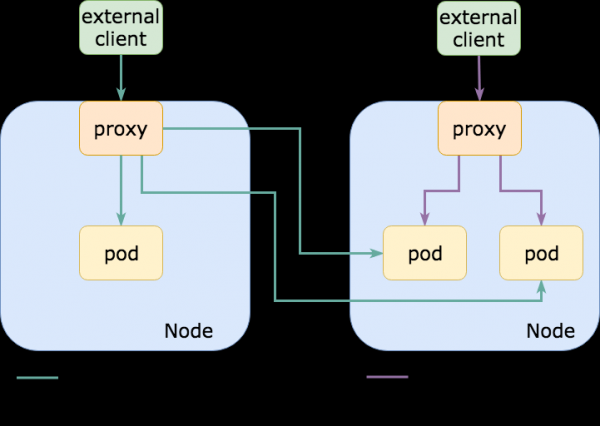
При этом реальные pod’ы, связанные с вышеупомянутым NodePort-сервисом, обычно имеются лишь на неком подмножестве этих узлов. Другими словами, если я подключусь к узлу, на котором нет нужного pod’а, он будет перенаправлять трафик на другой узел, добавляя транзитный участок (hop) и увеличивая задержку (если узлы находятся в разных зонах доступности/дата-центрах, задержка может оказаться довольно высокой; кроме того, вырастут расходы на egress-трафик).
С другой стороны, если для некоего сервиса Kubernetes задана политика externalTrafficPolicy: Local, то NodePort открывается только на тех узлах, где фактически запущены нужные pod’ы. При использовании внешнего балансировщика нагрузок, проверяющего состояния (healthchecking) endpoint’ов (как это делает AWS ELB), он будет отправлять трафик только на нужные узлы, что благоприятно скажется на задержках, вычислительных потребностях, счетах за egress (да и здравый смысл диктует то же самое).
Высока вероятность, что вы уже используете что-то вроде traefik или nginx-ingress-controller в качестве конечной NodePort-точки (или LoadBalancer, который тоже использует NodePort) для маршрутизации HTTP ingress-трафика, и установка этой опции может значительно снизить задержку при подобных запросах.
В можно более подробно узнать об externalTrafficPolicy, ее преимуществах и недостатках.
10. Не привязывайтесь к кластерам и не злоупотребляйте control plane
Раньше серверы было принято называть именами собственными: , HAL9000 и Colossus… Сегодня на смену им пришли случайно сгенерированные идентификаторы. Однако привычка осталась, и теперь собственные имена достаются кластерам.
Типичная история (основанная на реальных событиях): все начиналось с доказательства концепции, поэтому кластер носил гордое имя testing… Прошли годы, и он ДО СИХ пор используется в production, и все боятся к нему прикоснуться.
Нет ничего забавного в том, что кластеры превращаются в питомцев, поэтому рекомендуем периодически удалять их, попутно практикуясь в восстановлении после сбоев (в этом поможет — прим. перев.). Кроме того, не помешает заняться и управляющим слоем (control plane). Боязнь прикоснуться к нему — не очень хороший знак. Etcd мертв? Ребята, вы влипли по-настоящему!
С другой стороны, не стоит увлекаться манипуляциями с ним. Со временем управляющий слой может стать медленным. Скорее всего, это связано с большим количеством создаваемых объектов без их ротации (обычная ситуация при использовании Helm с настройками по умолчанию, из-за чего не обновляется его состояние в configmap’ах/секретах — как результат, в управляющем слое скапливаются тысячи объектов) или с постоянным редактированием объектов kube-api (для автоматического масштабирования, для CI/CD, для мониторинга, логи событий, контроллеры и т.д.).
Кроме того, рекомендуем проверить соглашения SLA/SLO с поставщиком managed Kubernetes и обратить внимание на гарантии. Вендор может гарантировать доступность управляющего слоя (или его субкомпонентов), но не p99-задержку запросов, которые вы ему посылаете. Другими словами, можно ввести kubectl get nodes, а ответ получить лишь через 10 минут, и это не будет являться нарушением условий соглашения об обслуживании.
11. Бонус: использование тега latest
А вот это уже классика. В последнее время мы встречаемся с подобной техникой не так часто, поскольку многие, наученные горьким опытом, перестали использовать тег :latest и начали закреплять (pin) версии. Ура!
ECR ; рекомендуем ознакомиться с этой примечательной особенностью.
Резюме
Не ждите, что все заработает по мановению руки: Kubernetes — это не панацея. Плохое приложение (и, возможно, станет еще хуже). Беспечность приведет к избыточной сложности, медленной и напряженной работе управляющего слоя. Кроме того, вы рискуете остаться без стратегии аварийного восстановления. Не рассчитывайте, что Kubernetes «из коробки» возьмет на себя обеспечение изоляции и высокой доступности. Потратьте некоторое время на то, чтобы сделать свое приложение по-настоящему cloud native.
Познакомиться с неудачным опытом различных команд можно в от Henning Jacobs.
Желающие дополнить список ошибок, приведенный в этой статье, могут связаться с нами в Twitter (, ).
P.S. от переводчика
Читайте также в нашем блоге:
- «»;
- «»;
- «» (обзор и видео доклада);
- «».
Источник: habr.com
