


Привет, я Сергей Еланцев, разрабатываю в Яндекс.Облаке. Раньше я руководил разработкой L7-балансировщика портала Яндекса — коллеги шутят, что чем бы я ни занимался, получается балансировщик. Я расскажу читателям Хабра, как нужно управлять нагрузкой в облачной платформе, каким мы видим идеальный инструмент достижения этой цели и как движемся к построению этого инструмента.
Для начала введём некоторые термины:
- VIP (Virtual IP) — IP-адрес балансировщика
- Сервер, бэкенд, инстанс — виртуальная машина с запущенным приложением
- RIP (Real IP) — IP-адрес сервера
- Healthcheck — проверка готовности сервера
- Зона доступности, Availability Zone, AZ — изолированная инфраструктура в дата-центре
- Регион — объединение разных AZ
Балансировщики нагрузки решают три основные задачи: выполняют саму балансировку, улучшают отказоустойчивость сервиса и упрощают его масштабирование. Отказоустойчивость обеспечивается за счёт автоматического управления трафиком: балансировщик следит за состоянием приложения и исключает из балансировки инстансы, не прошедшие проверку живости. Масштабирование обеспечивается равномерным распределением нагрузки по инстансам, а также обновлением списка инстансов на лету. Если балансировка будет недостаточно равномерной, то некоторые из инстансов получат нагрузку, превышающую их предел работоспособности, и сервис станет менее надёжным.
Балансировщик нагрузки часто классифицируют по уровню протокола из модели OSI, на котором он работает. Балансирощик Облака работает на уровне TCP, что соответствует четвёртому уровню, L4.
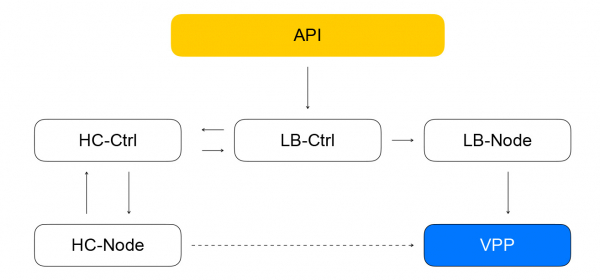
Перейдём к обзору архитектуры балансировщика Облака. Будем постепенно повышать уровень детализации. Мы делим компоненты балансировщика на три класса. Класс config plane отвечает за взаимодействие с пользователем и хранит в себе целевое состояние системы. Control plane хранит в себе актуальное состояние системы и управляет системами из класса data plane, которые отвечают непосредственно за доставку трафика от клиентов до ваших инстансов.
Data plane
Трафик попадает на дорогостоящие устройства под названием border routers. Для повышения отказоустойчивости в одном дата-центре одновременно работает несколько таких устройств. Далее трафик попадает на балансировщики, которые для клиентов анонсируют anycast IP-адрес на все AZ по BGP.
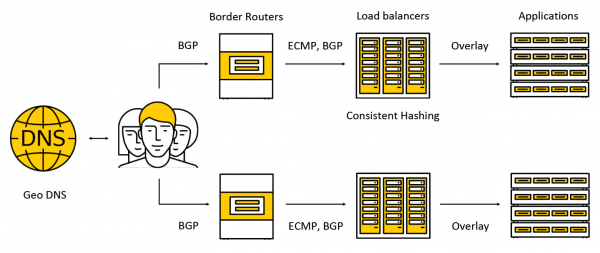
Трафик передаётся по ECMP — это стратегия маршрутизации, согласно которой может существовать несколько одинаково хороших маршрутов до цели (в нашем случае целью будет destination IP-адрес) и пакеты можно отправлять по любому из них. Также мы поддерживаем работу в нескольких зонах доступности по следующей схеме: анонсируем адрес в каждой из зон, трафик попадает в ближайшую и уже за её пределы не выходит. Дальше в посте мы рассмотрим подробнее, что происходит с трафиком.
Config plane
Ключевым компонентом config plane является API, через который выполняются основные операции с балансировщиками: создание, удаление, изменение состава инстансов, получение результатов healthchecks и т. д. C одной стороны, это REST API, а с другой, мы в Облаке очень часто используем фреймворк gRPC, поэтому мы «переводим» REST в gRPC и дальше используем только gRPC. Любой запрос приводит к созданию серии асинхронных идемпотентных задач, которые выполняются на общем пуле воркеров Яндекс.Облака. Задачи пишутся таким образом, что они могут быть в любое время приостановлены, а потом запущены заново. Это обеспечивает масштабируемость, повторяемость и логируемость операций.
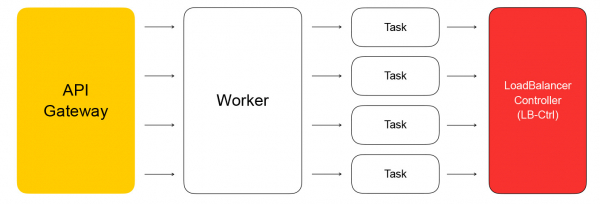
В итоге задача из API совершит запрос в сервис-контроллер балансировщиков, который написан на Go. Он может добавлять и удалять балансировщики, менять состав бэкендов и настройки.
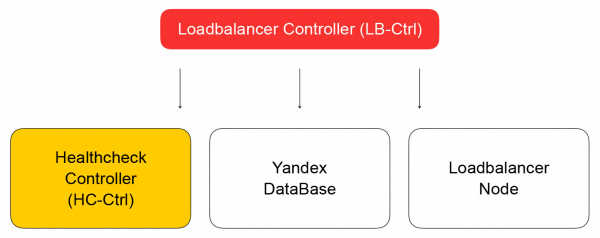
Сервис хранит своё состояние в Yandex Database — распределённой управляемой БД, которой вскоре сможете пользоваться и вы. В Яндекс.Облаке, как мы уже , действует концепция dog food: если мы сами пользуемся своими сервисами, то и наши клиенты тоже будут с удовольствием ими пользоваться. Yandex Database — пример воплощения такой концепции. Мы храним в YDB все свои данные, и нам не приходится думать об обслуживании и масштабировании базы: эти проблемы решены за нас, мы пользуемся базой как сервисом.
Возвращаемся к контроллеру балансировщика. Его задача — сохранить информацию о балансировщике, отправить задачу проверки готовности виртуальной машины в healthcheck controller.
Healthcheck controller
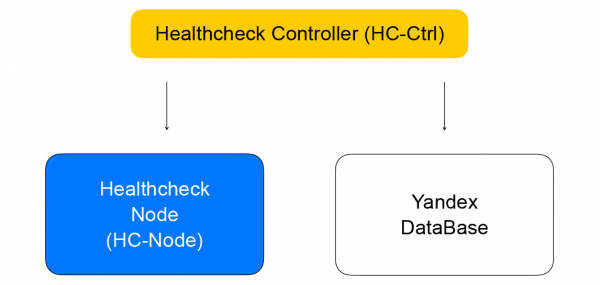
Он получает запросы на изменение правил проверок, сохраняет их в YDB, распределяет задачи по healtcheck nodes и агрегирует результаты, которые затем сохраняются в базу и отправляются в loadbalancer controller. Он, в свою очередь, отправляет запрос на изменение состава кластера в data plane на loadbalancer-node, о котором я расскажу ниже.
Поговорим подробнее про healthchecks. Их можно разделить на несколько классов. У проверок бывают разные критерии успеха. TCP-проверкам нужно успешно установить соединение за фиксированное время. HTTP-проверки требуют и успешного соединения, и получения ответа со статус-кодом 200.
Также проверки отличаются по классу действия — они бывают активные и пассивные. Пассивные проверки просто следят за тем, что происходит с трафиком, не предпринимая никаких специальных действий. Это не очень хорошо работает на L4, так как зависит от логики протоколов более высокого уровня: на L4 нет информации о том, сколько времени заняла операция, и было ли завершение соединения хорошим или плохим. Активные проверки требуют, чтобы балансировщик посылал запросы к каждому инстансу сервера.
Бо́льшая часть балансировщиков нагрузки выполняет проверки «живости» самостоятельно. Мы в Облаке решили разделить эти части системы для повышения масштабируемости. Такой подход позволит нам увеличивать количество балансировщиков, сохраняя количество healthcheck-запросов к сервису. Проверки выполняются отдельными healthcheck nodes, по которым шардированы и реплицированы цели проверок. Нельзя делать проверки с одного хоста, так как он может отказать. Тогда мы не получим состояние проверенных им инстансов. Мы выполняем проверки любого из инстансов минимум с трёх healthcheck nodes. Цели проверок мы шардируем между нодами с помощью алгоритмов консистентного хэширования.
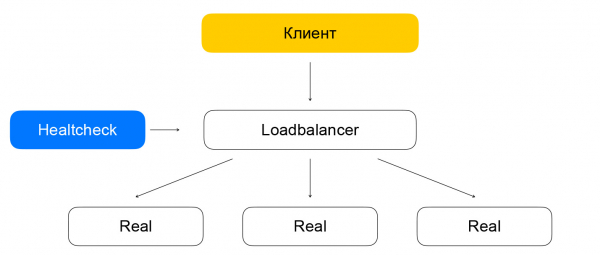
Разделение балансировки и healthcheck может приводить к проблемам. Если healthcheck node совершает запросы к инстансу, минуя балансировщик (который в данный момент не обслуживает трафик), то возникает странная ситуация: ресурс вроде бы жив, но трафик до него не дойдёт. Эту проблему мы решаем так: гарантированно заводим healthcheck-трафик через балансеровщики. Другими словами, схема перемещения пакетов с трафиком от клиентов и от healthchecks отличается минимально: в обоих случаях пакеты попадут на балансировщики, которые доставят их до целевых ресурсов.
Отличие в том, что клиенты делают запросы на VIP, а healthchecks обращаются к каждому отдельному RIP. Тут возникает интересная проблема: нашим пользователям мы даём возможность создавать ресурсы в серых IP-сетях. Представим, что есть два разных владельца облаков, которые спрятали свои сервисы за балансировщики. У каждого их них есть ресурсы в подсети 10.0.0.1/24, причём с одинаковыми адресами. Нужно уметь каким-то образом их отличать, и тут надо погрузиться в устройство виртуальной сети Яндекс.Облака. Подробности лучше узнать в , нам сейчас важно, что сеть многослойная и имеет в себе туннели, которые можно различать по id подсети.
Healthcheck nodes обращаются к балансировщикам с помощью так называемых квази-IPv6-адресов. Квазиадрес — это IPv6-адрес, внутри которого зашит IPv4-адрес и id подсети пользователя. Трафик попадает на балансировщик, тот извлекает из него IPv4-адрес ресурса, заменяет IPv6 на IPv4 и отправляет пакет в сеть пользователя.
Обратный трафик идёт так же: балансировщик видит, что назначение — серая сеть из healthcheckers, и преобразует IPv4 в IPv6.
VPP — сердце data plane
Балансировщик реализован на технологии Vector Packet Processing (VPP) — фреймворке от Cisco для пакетной обработки сетевого трафика. В нашем случае фреймворк работает поверх библиотеки user-space-управления сетевыми устройствами — Data Plane Development Kit (DPDK). Это обеспечивает высокую производительность обработки пакетов: в ядре происходит намного меньше прерываний, нет переключений контекста между kernel space и user space.
VPP идёт ещё дальше и выжимает из системы ещё больше производительности за счёт объединения пакетов в батчи. Повышение производительности происходит благодаря агрессивному использованию кэшей современных процессоров. Используются как кэши данных (пакеты обрабатываются «векторами», данные лежат близко друг к другу), так и кэши инструкций: в VPP обработка пакетов следует по графу, в узлах которого находятся функции, выполняющие одну задачу.
Например, обработка IP-пакетов в VPP проходит в таком порядке: сначала в узле разбора происходит парсинг заголовков пакетов, а потом они отправляются в узел, который пересылает пакеты дальше согласно таблицам маршрутизации.
Немного хардкора. Авторы VPP не терпят компромиссов в использовании кэшей процессора, поэтому типичный код обработки вектора пакетов содержит в себе ручную векторизацию: есть цикл обработки, в котором обрабатывается ситуация вида «у нас четыре пакета в очереди», затем — то же самое для двух, затем — для одного. Часто используются prefetch-инструкции, загружающие данные в кэши для ускорения доступа к ним на следующих итерациях.
n_left_from = frame->n_vectors;
while (n_left_from > 0)
{
vlib_get_next_frame (vm, node, next_index, to_next, n_left_to_next);
// ...
while (n_left_from >= 4 && n_left_to_next >= 2)
{
// processing multiple packets at once
u32 next0 = SAMPLE_NEXT_INTERFACE_OUTPUT;
u32 next1 = SAMPLE_NEXT_INTERFACE_OUTPUT;
// ...
/* Prefetch next iteration. */
{
vlib_buffer_t *p2, *p3;
p2 = vlib_get_buffer (vm, from[2]);
p3 = vlib_get_buffer (vm, from[3]);
vlib_prefetch_buffer_header (p2, LOAD);
vlib_prefetch_buffer_header (p3, LOAD);
CLIB_PREFETCH (p2->data, CLIB_CACHE_LINE_BYTES, STORE);
CLIB_PREFETCH (p3->data, CLIB_CACHE_LINE_BYTES, STORE);
}
// actually process data
/* verify speculative enqueues, maybe switch current next frame */
vlib_validate_buffer_enqueue_x2 (vm, node, next_index,
to_next, n_left_to_next,
bi0, bi1, next0, next1);
}
while (n_left_from > 0 && n_left_to_next > 0)
{
// processing packets by one
}
// processed batch
vlib_put_next_frame (vm, node, next_index, n_left_to_next);
}Итак, Healthchecks обращаются по IPv6 к VPP, который превращает их в IPv4. Этим занимается узел графа, который мы называем алгоритмическим NAT. Для обратного трафика (и преобразования из IPv6 в IPv4) есть такой же узел алгоритмического NAT.
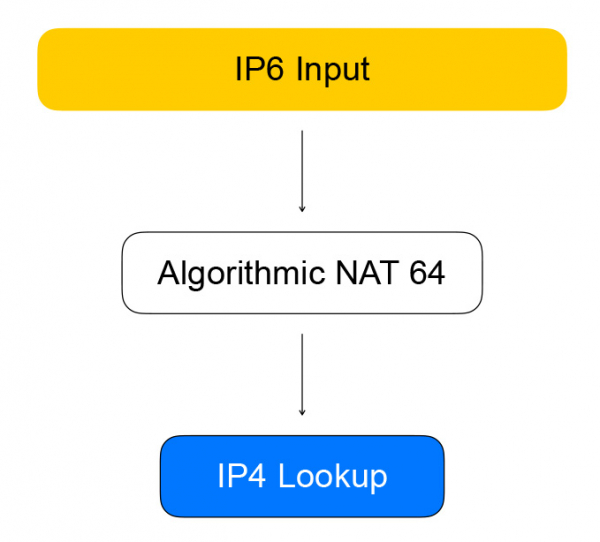
Прямой трафик от клиентов балансировщика идёт через узлы графа, которые выполняют саму балансировку.
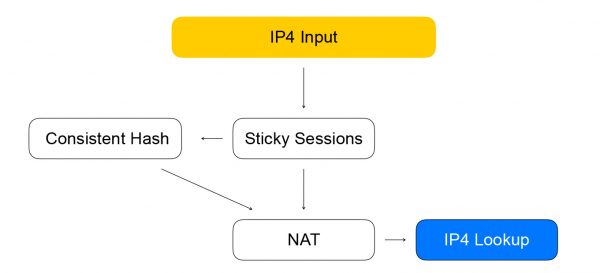
Первый узел — sticky sessions. В нём хранится хэш от для установленных сессий. 5-tuple включает в себя адрес и порт клиента, с которого передаётся информация, адрес и портов ресурсов, доступных для приёма трафика, а также сетевой протокол.
Хэш от 5-tuple помогает нам выполнять меньше вычислений в последующем узле консистентного хэширования, а также лучше обрабатывать изменение списка ресурсов за балансировщиком. Когда на балансровщик приходит пакет, для которого нет сессии, он отправляется в узел consistent hashing. Тут и происходит балансировка с помощью консистентного хэширования: мы выбираем ресурс из списка доступных «живых» ресурсов. Далее пакеты отправляются в узел NAT, который проводит фактическую замену адреса назначения и перерасчёт контрольных сумм. Как видите, мы следуем правилам VPP — подобное к подобному, группируем схожие вычисления для увеличения эффективности кэшей процессора.
Консистентное хэширование
Почему мы выбрали именно его и что это вообще такое? Для начала рассмотрим прежнюю задачу — выбора ресурса из списка.
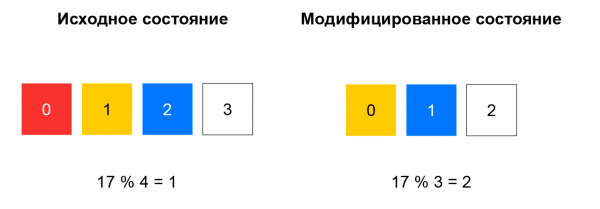
При неконсистентном хэшировании вычисляют хэш от входящего пакета, а ресурс выбирают из списка по остатку от деления этого хэша на количество ресурсов. Пока список остаётся неизменнным, такая схема работает хорошо: мы всегда отправляем пакеты с одинаковым 5-tuple на один и тот же инстанс. Если же, например, какой-то ресурс перестал отвечать на healthchecks, то для значительной части хэшей выбор изменится. У клиента разорвутся TCP-соединения: пакет, ранее попадавший на инстанс А, может начать попадать на инстанс Б, который с сессией для этого пакета не знаком.
Консистетное хэширование решает описанную проблему. Проще всего объяснить эту концепцию так: представьте, что у вас есть кольцо, на которое вы распределяете ресурсы по хэшу (например, по IP:port). Выбор ресурса — это поворот колеса на угол, который определяется по хэшу от пакета.
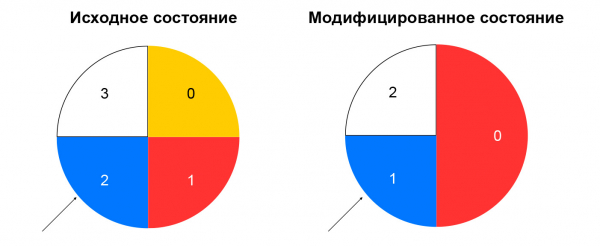
Тем самым минимизируется перераспределение трафика при изменении состава ресурсов. Удаление ресурса повлияет только на ту часть кольца консистентного хэширования, на которой находился данный ресурс. Добавление ресурса тоже меняет распределение, но у нас есть узел sticky sessions, который позволяет не переключать уже установленные сессии на новые ресурсы.
Мы рассмотрели, что происходит с прямым трафиком между балансировщиком и ресурсами. Теперь давайте разберёмся с обратным трафиком. Он следует по такой же схеме, как и трафик проверок — через алгоритмический NAT, то есть через обратный NAT 44 для клиентского трафика и через NAT 46 для трафика healthchecks. Мы придерживаемся своей же схемы: унифицируем трафик healthchecks и реальный трафик пользователей.
Loadbalancer-node и компоненты в сборе
О составе балансировщиков и ресурсов в VPP сообщает локальный сервис — loadbalancer-node. Он подписывается на поток событий от loadbalancer-controller, умеет строить разницу текущего состояния VPP и целевого состояния, полученного от контроллера. Мы получаем замкнутую систему: события из API приходят на контроллер балансировщика, который ставит healthcheck-контроллеру задачи на проверку «живости» ресурсов. Тот, в свою очередь, ставит задачи в healthcheck-node и агрегирует результаты, после чего отдаёт их обратно контроллеру балансировщиков. Loadbalancer-node подписывается на события от контроллера и меняет состояние VPP. В такой системе каждый сервис знает только необходимое о соседних сервисах. Количество связей ограничено, и у нас есть возможность независимо эксплуатировать и масштабировать различные сегменты.
Каких вопросов удалось избежать
Все наши сервисы в control plane написаны на Go и отличаются хорошими характеристиками по масштабированию и надёжности. В Go есть много опенсорсных библиотек для построения распределённых систем. Мы активно используем GRPC, все компоненты содержат в себе опенсорсную реализацию service discovery — наши сервисы следят за работоспособностью друг друга, могут менять свой состав динамически, и мы провязали это с GRPC-балансировкой. Для метрик мы тоже используем опенсорсное решение. В data plane мы получили достойную производительность и большой запас по ресурсам: оказалось очень непросто собрать стенд, на котором можно было бы упереться в производительность VPP, а не железной сетевой карты.
Проблемы и решения
Что сработало не очень хорошо? В Go управление памятью автоматическое, но утечки памяти всё же бывают. Самый простой способ справиться с ними — запускать горутины и не забывать их завершать. Вывод: следите за потреблением памяти Go-программ. Часто хорошим индикатором является количество горутин. В этой истории есть и плюс: в Go легко получить данные по runtime — по потреблению памяти, по количеству запущенных горутин и по многим другим параметрам.
Кроме того, Go — возможно, не лучший выбор для функциональных тестов. Они довольно многословные, и стандартный подход «запустить всё в CI пачкой» для них не очень подходит. Дело в том, что функциональные тесты более требовательны к ресурсам, с ними возникают настоящие таймауты. Из-за этого тесты могут завершаться неуспешно, так как CPU занят юнит-тестами. Вывод: по возможности выполняйте «тяжёлые» тесты отдельно от юнит-тестов.
Микросервисная событийная архитектура сложнее монолита: грепать логи на десятках разных машин не очень удобно. Вывод: если делаете микросервисы, сразу думайте про трейсинг.
Наши планы
Мы запустим внутренний балансировщик, IPv6-балансировщик, добавим поддержку сценариев Kubernetes, будем и дальше шардировать наши сервисы (сейчас шардированы только healthcheck-node и healthcheck-ctrl), добавим новые healthchecks, а также реализуем умную агрегацию проверок. Мы рассматриваем возможность сделать наши сервисы ещё более независимыми — чтобы они общались не напрямую между собой, а с помощью очереди сообщений. В Облаке недавно появился SQS-совместимый сервис .
Недавно состоялся публичный релиз Yandex Load Balancer. Изучайте к сервису, управляйте балансировщиками удобным вам способом и повышайте отказоустойчивость своих проектов!
Источник: habr.com
