

27 апреля на конференции , в рамках секции «DevOps», прозвучал доклад «Автомасштабирование и управление ресурсами в Kubernetes». В нём рассказывается о том, как с помощью K8s обеспечить высокую доступность приложений и гарантировать их максимальную производительность.

По традиции рады представить (44 минуты, гораздо информативнее статьи) и основную выжимку в текстовом виде. Поехали!
Разберём тему доклада по словам и начнём с конца.
Kubernetes
Пусть у нас на хосте есть Docker-контейнеры. Зачем? Для обеспечения повторяемости и изоляции, которые в свою очередь позволяют сделать просто и хорошо деплой, CI/CD. Таких машин с контейнерами у нас много.
Что в этом случае даёт Kubernetes?
- Мы перестаём думать про эти машины и начинаем работать с «облаком», кластером из контейнеров или pod’ов (групп из контейнеров).
- Более того, мы не думаем даже про отдельные pod’ы, а управляем ещё большими группами. Такие высокоуровневые примитивы позволяют нам сказать, что есть шаблон для запуска некой рабочей нагрузки, а вот нужное количество экземпляров для её запуска. Если мы впоследствии поменяем шаблон — поменяются и все экземпляры.
- С помощью декларативного API мы вместо выполнения последовательности конкретных команд описываем «устройство мира» (в YAML), который создаётся Kubernetes’ом. И снова: при изменениях описания будет меняться и его реально отображение.
Управление ресурсами
CPU
Пусть мы запускаем на сервере nginx, php-fpm и mysql. У этих служб в действительности будет ещё больше работающих процессов, каждый из которых требует вычислительных ресурсов:
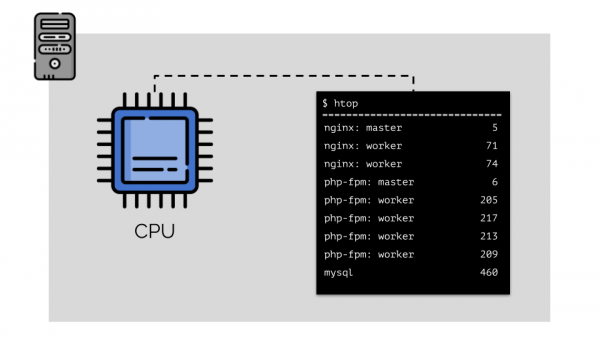
(числа на слайде — «попугаи», абстрактная потребность каждого процесса в вычислительных мощностях)
Чтобы с этим можно было удобно работать, логично объединить процессы по группам (например, все процессы nginx в одну группу «nginx»). Простой и очевидный способ сделать это — поместить каждую группу в контейнер:
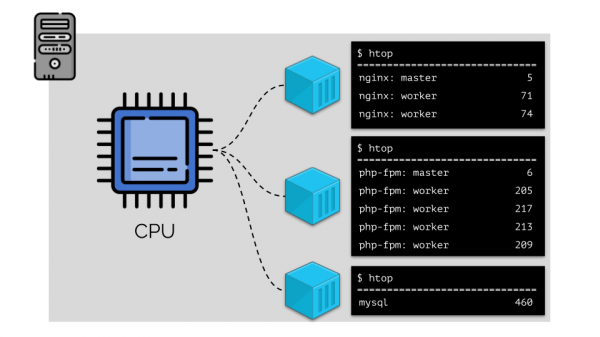
Чтобы продолжить, необходимо вспомнить, что же такое контейнер (в Linux). Их появление стало возможным благодаря трём ключевым возможностям в ядре, реализованным уже достаточно давно: , и . А дальнейшему развитию способствовали другие технологии (включая удобные «оболочки» типа Docker):
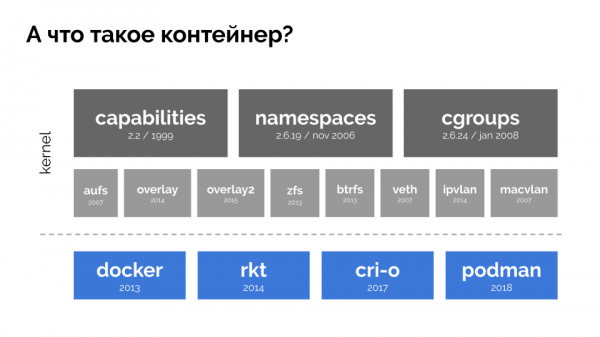
В контексте доклада нас интересует только cgroups, потому что именно контрольные группы — та часть функциональных возможностей контейнеров (Docker’а и т.п.), что реализует управление ресурсами. Процессы, объединённые в группы, как мы того хотели, — это и есть контрольные группы.
Вернёмся к потребностям в CPU у этих процессов, а теперь уже — у групп процессов:
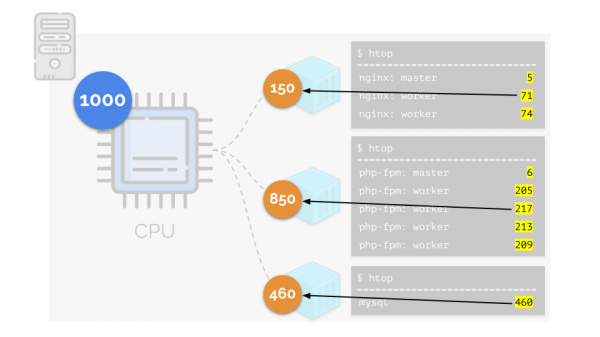
(повторюсь, что все числа — абстрактное выражение потребности в ресурсах)
При этом у самого CPU есть некий конечный ресурс (в примере это 1000), которого всем может не хватать (сумма потребностей всех групп — 150+850+460=1460). Что будет происходить в таком случае?
Ядро начинает раздавать ресурсы и делает это «честно», выдавая одинаковое количество ресурсов каждой группе. Но в первом случае их больше нужного (333>150), поэтому излишек (333-150=183) остаётся в резерве, который тоже равно распределяется между двумя другими контейнерами:
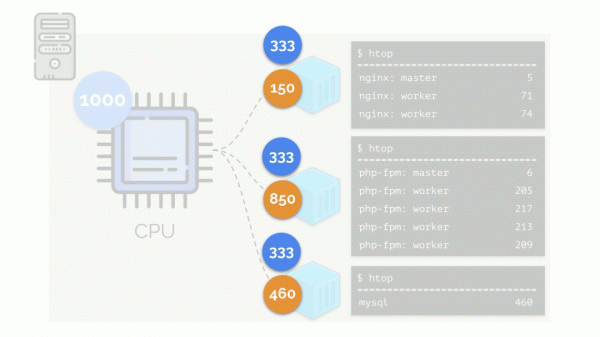
В итоге: первому контейнеру хватило ресурсов, второму — сильно не хватило, третьему — немного не хватило. Таков результат действий «честного» планировщика в Linux — . Его работу можно регулировать с помощью назначения веса каждому из контейнеров. Например, так:
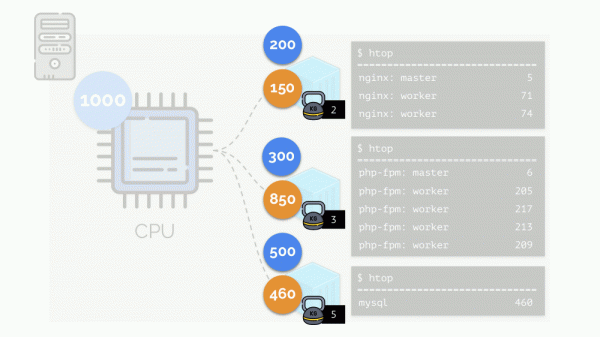
Посмотрим на случай нехватки ресурсов у второго контейнера (php-fpm). Все ресурсы контейнера распределяются между процессами поровну. В результате, master-процесс работает хорошо, а все worker’ы тормозят, получив менее половины от нужного:
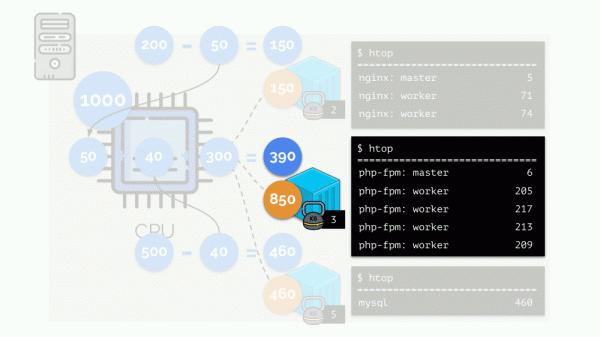
Так работает планировщик CFS. Веса, которые мы назначаем контейнерам, в дальнейшем будем назвать request’ами. Почему именно так — см. дальше.
Взглянем на всю ситуацию с другой стороны. Как известно, все дороги ведут в Рим, а в случае компьютера — в CPU. CPU один, задач много — нужен светофор. Самый простой способ управления ресурсами — «светофорный»: выдали одному процессу фиксированное время доступа к CPU, затем — следующему и т.п.
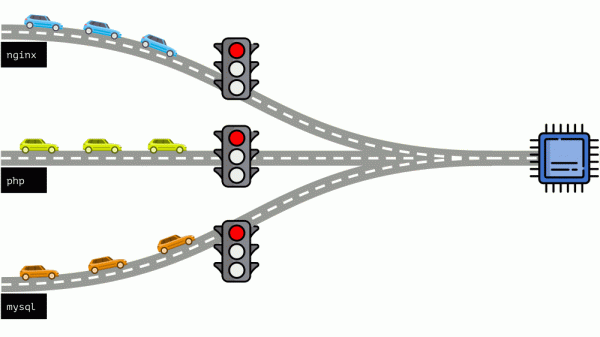
Этот подход называется жёстким квотированием (hard limiting). Запомним его просто как лимиты. Однако, если раздать всем контейнерами лимиты, возникает проблема: mysql ехал по дороге и в какой-то момент его потребность в CPU закончилась, но все остальные процессы вынуждены ждать, пока CPU простаивает.
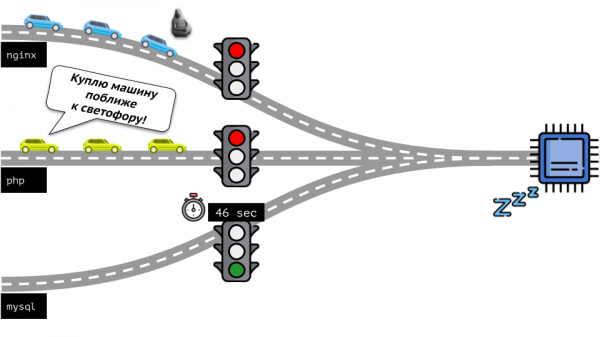
Вернёмся к ядру Linux и его взаимодействию с CPU — общая картина получается следующей:
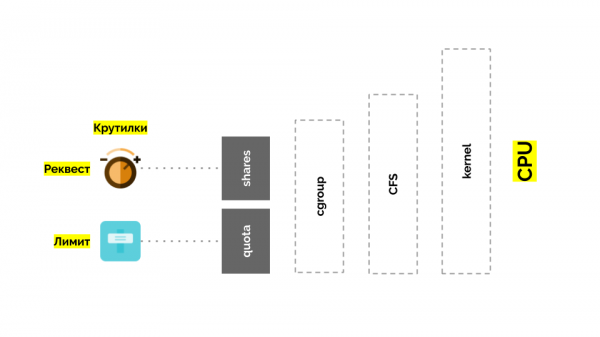
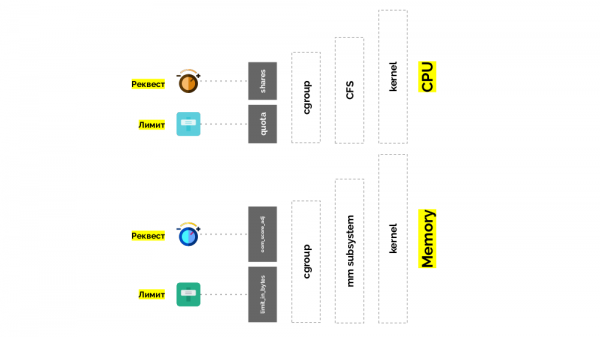
У cgroup есть две настройки — по сути это две простые «крутилки», позволяющие определять:
- вес для контейнера (request’ы) — это shares;
- процент от общего времени CPU для работы над задачами контейнера (лимиты) — это quota.
В чём мерить CPU?
Есть разные пути:
- Что такое попугаи, никто не знает — нужно каждый раз договариваться.
- Проценты понятнее, но относительны: 50% от сервера с 4 ядрами и с 20 ядрами — совершенно разные вещи.
- Можно использовать уже упомянутые веса, которые знает Linux, но они тоже относительны.
- Самый адекватный вариант — мерить вычислительные ресурсы в секундах. Т.е. в секундах процессорного времени по отношению к секундам реального времени: выдали 1 секунду процессорного времени в 1 реальную секунду — это одно ядро CPU целиком.
Чтобы стало говорить еще проще, измерять стали прямо в ядрах, подразумевая под ними то самое время CPU относительно реального. Поскольку Linux понимает веса, а не такое процессорное время/ядра, понадобился механизм перевода из одного в другое.
Рассмотрим простой пример с сервером с 3 ядрами CPU, где трём pod’ам будут выбраны такие веса (500, 1000 и 1500), которые легко конвертируются в соответствующие части выделенных им ядер (0,5, 1 и 1,5).
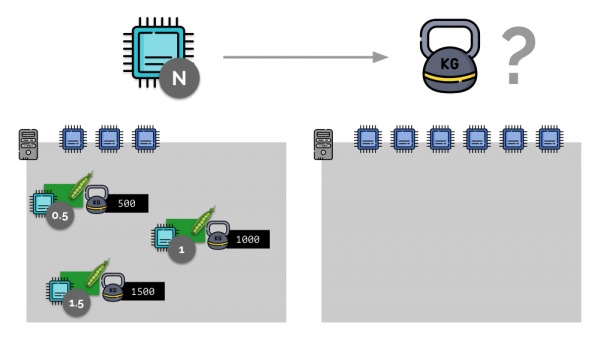
Если взять второй сервер, где ядер будет вдвое больше (6), и разместить там те же pod’ы, распределение ядер легко посчитать простым умножением на 2 (1, 2 и 3 соответственно). Но важный момент происходит тогда, когда на этом сервере появится четвёртый pod, вес у которого пусть для удобства будет 3000. Он забирает себе часть ресурсов CPU (половину ядер), а у остальных pod’ов они пересчитываются (уменьшатся вдвое):
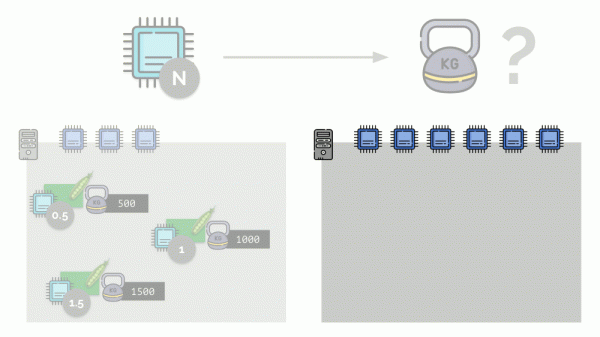
Kubernetes и ресурсы CPU
В Kubernetes ресурсы CPU принято измерять в миллиядрах, т.е. в качестве базового веса берётся 0,001 ядра. (То же самое в терминологии Linux/cgroups называют CPU share, хотя, если говорить точнее, то 1000 миллиядер = 1024 CPU shares.) K8s следит за тем, чтобы не размещать на сервере больше pod’ов, чем есть ресурсов CPU для суммы весов всех pod’ов.
Как это происходит? При добавлении сервера в кластер Kubernetes сообщается, сколько у него доступно ядер CPU. А при создании нового pod’а планировщик Kubernetes знает, сколько ядер потребуется этому pod’у. Таким образом, pod будет определён на сервер, где ядер достаточно.
Что же произойдёт, если не указан request (т.е. у pod’а не определено количество нужных ему ядер)? Давайте разберёмся, как Kubernetes вообще считает ресурсы.
У pod’а можно указать и request’ы (планировщик CFS), и лимиты (помните светофор?):
- Если они указаны равные, то pod’у назначается QoS-класс guaranteed. Такое количество всегда доступных для него ядер гарантируется.
- Если request меньше лимита — QoS-класс burstable. Т.е. мы ожидаем, что pod, например, всегда использует 1 ядро, однако это значение не является для него ограничением: иногда pod может использовать и больше (когда на сервере есть свободные ресурсы для этого).
- Есть ещё QoS-класс best effort — к нему относятся те самые pod’ы, для которых не указан request. Ресурсы им выдаются в последнюю очередь.
Память
С памятью ситуация подобная, но немного иная — всё-таки природа у этих ресурсов разная. В целом же аналогия такова:
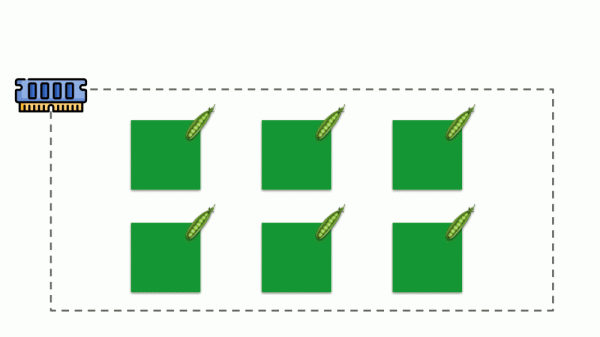
Давайте посмотрим, как в памяти реализуются request’ы. Пусть pod’ы живут на сервере, изменяя потребляемую память, пока один из них не станет таким большим, что память закончится. В этом случае появляется OOM killer и убивает самый большой процесс:
Нас это не всегда устраивает, поэтому есть возможность регулировать, какие процессы для нас важны и не должны убиваться. Для этого используется параметр oom_score_adj.
Вернёмся к QoS-классам CPU и проведём аналогию со значениями oom_score_adj, определяющими для pod’ов приоритеты по потреблению памяти:
- Самое низкое значение oom_score_adj у pod’а — -998 — означает, что такой pod должен убиваться в самую последнюю очередь, это guaranteed.
- Самое высокое — 1000 — это best effort, такие pod’ы убиваются раньше всех.
- Для расчёта остальных значений (burstable) есть формула, суть которой сводится к тому, что чем больше pod запросил ресурсов, тем меньше шансов, что его убьют.

Вторая «крутилка» — limit_in_bytes — для лимитов. С ней всё проще: мы просто назначаем максимальное количество выдаваемой памяти, и здесь (в отличие от CPU) нет вопроса, в чём её (память) измерять.
Итого
Каждому pod’у в Kubernetes задаются requests и limits — оба параметра для CPU и для памяти:
- на основании requests работает планировщик Kubernetes, который распределяет pod’ы по серверам;
- на основании всех параметров определяется QoS-класс pod’а;
- на основании CPU requests расчитываются относительные веса;
- на основании CPU requests настраивается CFS-планировщик;
- на основании memory requests настраивается OOM killer;
- на основании CPU limits настраивается «светофор»;
- на основании memory limits настраивается лимит на cgroup’у.
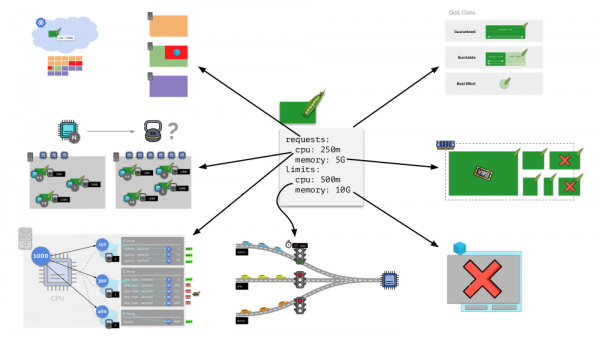
В целом эта картинка отвечает на все вопросы, как происходит основная часть управления ресурсами в Kubernetes.
Автомасштабирование
K8s cluster-autoscaler
Представим себе, что весь кластер уже занят и должен быть создан новый pod. Пока pod не может появиться, он висит в статусе Pending. Чтобы он всё-таки появился, мы можем подключить новый сервер к кластеру или же… поставить cluster-autoscaler, который сделает это за нас: закажет виртуальную машину у облачного провайдера (запросом по API) и подключит её к кластеру, после чего pod будет добавлен.
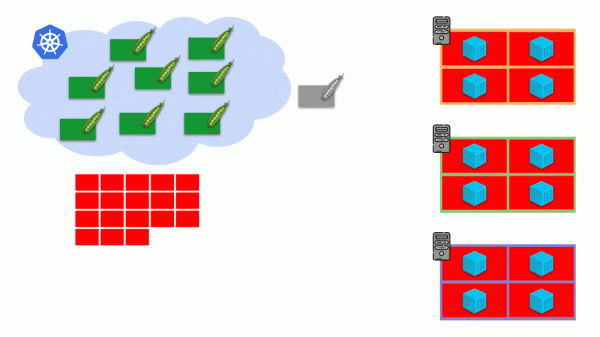
Это и есть автомасштабирование кластера Kubernetes, которое замечательно (по нашему опыту) работает. Однако, как и везде, здесь не без нюансов…
Пока мы увеличивали размеры кластера, всё было хорошо, но что происходит, когда кластер стал освобождаться? Проблема в том, что мигрировать pod’ы (для освобождения хостов) очень технически сложно и дорого по ресурсам. В Kubernetes работает совсем другой подход.
Рассмотрим кластер из 3 серверов, в котором есть Deployment. У него 6 pod’ов: сейчас это по 2 на каждый сервер. Мы по какой-то причине захотели выключить один из серверов. Для этого воспользуемся командой kubectl drain, которая:
- запретит отправлять новые pod’ы на этот сервер;
- удалит существующие pod’ы на сервере.
Поскольку Kubernetes следит за поддержанием числа pod’ов (6), он просто пересоздаст их на других узлах, но не на отключаемом, поскольку он уже помечен как недоступный для размещения новых pod’ов. Это основополагающая механика для Kubernetes.
Однако и здесь есть нюанс. В аналогичной ситуации для StatefulSet (вместо Deployment) действия будут иными. Теперь у нас уже stateful-приложение — например, три pod’а с MongoDB, у одного из которых возникла какая-то проблема (данные испортились или иная ошибка, не позволяющая корректно запуститься pod’у). И мы снова решаем отключить один сервер. Что произойдёт?
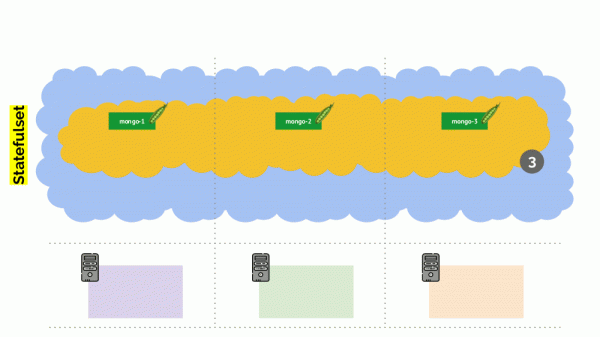
MongoDB мог бы умереть, поскольку ему необходим кворум: для кластера из трёх инсталляций хотя бы две должны функционировать. Однако этого не происходит — благодаря PodDisruptionBudget. Этот параметр определить минимально необходимое количество работающих pod’ов. Зная, что один из pod’ов с MongoDB уже не работает, и увидев, что для MongoDB в PodDisruptionBudget установлен minAvailable: 2, Kubernetes не даст удалить pod.
Итог: для того, чтобы корректно работало перемещение (а на самом деле — пересоздание) pod’ов при освобождении кластера, необходимо настраивать PodDisruptionBudget.
Горизонтальное масштабирование
Рассмотрим другую ситуацию. Есть приложение, запущенное как Deployment в Kubernetes. На его pod’ы (например, их три) приходит пользовательский трафик, а мы в них замеряем некий показатель (скажем, нагрузку на CPU). Когда нагрузка возрастает, мы это фиксируем по графику и увеличиваем количество pod’ов для распределения запросов.
Сегодня в Kubernetes это не нужно делать вручную: настраивается автоматическое увеличение/уменьшение количества pod’ов в зависимости от значений замеряемых показателей нагрузки.
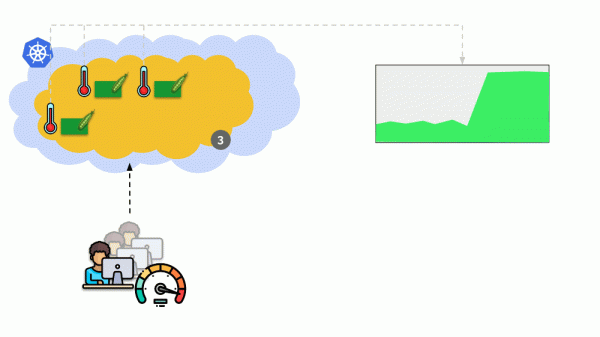
Главные вопросы здесь в том, что именно измерять и как интерпретировать полученные значения (для принятия решения об изменении числа pod’ов). Измерять можно очень многое:

Как делать это технически — собирать метрики и т.п. — я подробно рассказывал в докладе про . А основной совет для выбора оптимальных параметров — экспериментируйте!
Есть (Utilization Saturation and Errors), смысл которого в следующем. На основании чего имеет смысл масштабировать, например, php-fpm? На основании того, что worker’ы заканчиваются, — это utilization. А если worker’ы закончились и новые подключения не принимаются — это уже saturation. Оба этих параметра необходимо измерять, а в зависимости от значений и проводить масштабирование.
Вместо заключения
У доклада есть продолжение: про вертикальное масштабирование и про то, как правильно подбирать ресурсы. Об этом я расскажу в будущих роликах на — подписывайтесь, чтобы не пропустить!
Видео и слайды
Видео с выступления (44 минуты):

Презентация доклада:
P.S.
Другие доклады про Kubernetes в нашем блоге:
- «» (Андрей Половов; 8 апреля 2019 на Saint HighLoad++);
- «» (Дмитрий Столяров; 8 ноября 2018 на HighLoad++);
- «» (Дмитрий Столяров; 28 мая 2018 на RootConf);
- «» (Дмитрий Столяров; 7 ноября 2017 на HighLoad++);
- «» (Дмитрий Столяров; 6 июня 2017 на RootConf).
Источник: habr.com
