

В крупных облачных системах особенно остро стоит вопрос автоматической балансировки или выравнивания нагрузки на вычислительные ресурсы. Озаботились данным вопросом и в Тиониксе (разработчик и оператор облачных услуг, входим в группу компаний Ростелекома).
И, поскольку нашей основной платформой разработки является Openstack, а мы, как и все люди, ленивы, то было решено подобрать какой-то готовый модуль, что уже есть в составе платформы. Наш выбор пал на Watcher, который мы и решили использовать для своих нужд.
Для начала разберемся с терминами и определениями.
Термины и определения
Цель — это человекочитаемый, наблюдаемый и поддающийся измерению конечный результат, который должен быть достигнут. Для достижения каждой цели имеются одна или более стратегии. Стратегия — это реализация алгоритма, который способен найти решение для данной цели.
Действие (Action) — это элементарная задача, которая изменяет текущее состояние целевого управляемого ресурса кластера OpenStack, такая как: миграция виртуальной машины (migration), изменение состояния питания узла (change_node_power_state), изменение состояния службы nova (change_nova_service_state), изменение флэвора (resize), регистрация NOP сообщения (nop), отсутствие действий в течении определенной продолжительности времени — пауза (sleep), перенос диска (volume_migrate).
План действий (Action Plan) — специфический поток действий, осуществленных в определенном порядке для достижения конкретной Цели. План действий также содержит оцениваемую глобальную эффективность с набором показателей эффективности. План действий генерируется Watcher при успешно проведенном аудите, в результате которого использованная стратегия находит решение для достижения цели. План действий состоит из списка последовательных действий.
Аудит (Audit) — это запрос на оптимизацию кластера. Оптимизация выполняется для того, чтобы достичь одну Цель в данном кластере. Для каждого успешного аудита Watcher генерирует План действий.
Область аудита (Audit Scope) — это набор ресурсов, в рамках которых производится аудит (зона(ы) доступности, агрегаторы узлов, отдельные вычислительные узлы или узлы хранения и т.д.). Область аудита определена в каждом шаблоне. Если область аудита не указана, производится аудит всего кластера.
Шаблон аудита (Audit Template) — сохраненный набор настроек для запуска аудита. Шаблоны необходимы для того, чтобы многократно запускать аудиты с одинаковыми настройками. Шаблон должен обязательно содержать цель аудита, если стратегии не указываются, то выбираются наиболее подходящие из существующих стратегий.
Кластер (Cluster) — это набор физических машин, которые предоставляют вычислительные ресурсы, ресурсы хранения и сетевые ресурсы и управляются одним и тем же управляющим узлом OpenStack.
Модель данных кластера (Cluster Data Model, CDM) — это логическое представление текущего состояния и топологии управляемых кластером ресурсов.
Показатель эффективности (Efficacy Indicator) — показатель, который указывает на то, как выполняется решение, созданное с помощью данной стратегии. Показатели эффективности специфичны для конкретной цели и обычно используются для расчета глобальной эффективности итогового плана действий.
Спецификация эффективности (Efficacy Specification) — это набор специфических особенностей, связанный с каждой Целью, который определяет различные показатели эффективности, которые стратегия, обеспечивающая достижение соответствующей цели, должна обеспечивать в своем решении. Действительно, каждое решение, предложенное стратегией, будет проверено на соответствие спецификации, прежде чем рассчитывать его глобальную эффективность.
“Подсчитывающий” движок (Scoring Engine) — это исполняемый файл, который имеет четко определенные входные данные, четко определенные выходные данные и выполняет чисто математическую задачу. Таким образом, расчет не зависит от среды, в которой он выполняется, — он даст одинаковый результат в любом месте.
Watcher планировщик (Watcher Planner) — часть механизма принятия решений Watcher. Этот модуль принимает набор действий, сгенерированных стратегией, и создает план рабочего процесса, который определяет, как планировать во времени эти различные действия и для каждого действия, каковы предварительные условия.
Цели и стратегии Watcher
Цель
Стратегии
Dummy goal
Dummy Strategy
Dummy Strategy using sample Scoring Engines
Dummy strategy with resize
Saving Energy
Saving Energy Strategy
Server Consolidation
Basic Offline Server Consolidation
VM Workload Consolidation Strategy
Workload Balancing
Workload Balance Migration Strategy
Storage Capacity Balance Strategy
Workload stabilization
Noisy Neighbor
Noisy Neighbor
Thermal Optimization
Outlet temperature based strategy
Airflow Optimization
Uniform airflow migration strategy
Hardware maintenance
Zone migration
Unclassified
Actuator
Dummy goal — резервная цель, которая используется для тестирования (reserved goal that is used for testing purposes).
Связанные стратегии: Dummy Strategy, Dummy Strategy using sample Scoring Engines и Dummy strategy with resize. Dummy strategy — фиктивная стратегия, используемая для интеграционного тестирования через Tempest. Эта стратегия не обеспечивает никакой полезной оптимизации, его единственная цель — использовать тесты Tempest.
Dummy strategy using sample Scoring Engines — стратегия аналогична предыдущей, отличается лишь использованием образца “оценивающего движка”, ведущего подсчет с использованием методов машинного обучения.
Dummy strategy with resize — стратегия аналогична предыдущей, отличается лишь использованием изменения флэвора (миграция и ресайз).
Не используется в продакшн.
Saving Energy — минимизировать потребление энергии. Стратегия данной цели Saving Energy Strategy совместно со стратегией VM Workload Consolidation Strategy (Server Consolidation) способна выполнять функции динамического управления питанием (DPM), которые экономить электроэнергию за счет динамической консолидации рабочих нагрузок даже в периоды низкой загрузки ресурсов: виртуальные машины переносятся на меньшее количество узлов, а ненужные узлы — отключаются. После консолидации стратегия предлагает решение о включении/выключении узлов в соответствии с заданными параметрами: “min_free_hosts_num” — количество свободных включенных узлов, которые ожидают нагрузки, и “free_used_percent” — процентное соотношение свободных включенных узлов к количеству узлов, которое занято машинами. Для работы стратегии должен быть включен и настроен Ironic для работы с включением/отключением питания на узлах.
Параметры стратегии
параметр
тип
по умолчанию
описание
free_used_percent
Number
10.0
соотношение количества свободных вычислительных узлов к количеству вычислительных узлов с виртуальными машинами
min_free_hosts_num
Int
1
минимальное количество свободных вычислительных узлов
В облаке должно быть минимум два узла. Используемый метод — изменение состояния питания узла (change_node_power_state). Сбора метрик стратегия не требует.
Server Consolidation — минимизировать количество вычислительных узлов (консолидация). Имеет две стратегии: Basic Offline Server Consolidation и VM Workload Consolidation Strategy.
Стратегия Basic Offline Server Consolidation минимизирует общее количество используемых серверов, а также минимизирует количество миграций.
Базовая стратегия требует следующие метрики:
метрика
служба
плагины
комментарий
compute.node.cpu.percent
none
cpu_util
none
Параметры стратегии: migration_attempts — количество комбинаций для поиска потенциальных кандидатов на выключение (по умолчанию, 0, нет ограничений), period — интервал времени в секундах для получения статической агрегации из источника данных метрики (по умолчанию, 700).
Используемые методы: миграция, изменение состояния службы nova (change_nova_service_state).
Стратегия VM Workload Consolidation Strategy основана на эвристической алгоритме первого подходящего (first-fit), который фокусируется на измеренной загрузке CPU и пытается минимизировать узлы, которые имеют слишком большую или слишком небольшую нагрузку с учетом ограничений емкости ресурсов. Эта стратегия предоставляет решение, которое приводит к более эффективному использованию ресурсов кластера, используя следующие четыре этапа:
- Фаза разгрузки — обработка перерасходованных ресурсов;
- Фаза консолидации — обработка недостаточно используемых ресурсов;
- Оптимизация решения — сокращение количества миграций;
- Отключение неиспользуемых вычислительных узлов.
Стратегия требует следующие метрики:
метрика
служба
плагины
комментарий
memory
none
disk.root.size
none
Следующие метрики не являются обязательными, но повышают точности стратегии, если доступны:
метрика
служба
плагины
комментарий
memory.resident
none
cpu_util
none
Параметры стратегии: period — интервал времени в секундах для получения статической агрегации из источника данных метрики (по умолчанию, 3600).
Использует те же методы, что и предыдущая стратегия. Подробнее .
Workload Balancing — сбалансировать рабочую нагрузку между вычислительными узлами. Цель обладает тремя стратегиями: Workload Balance Migration Strategy, Workload stabilization, Storage Capacity Balance Strategy.
Workload Balance Migration Strategy запускает миграции виртуальных машин на основе рабочей нагрузки виртуальных машин узлов. Решение о переносе принимается всякий раз, когда % использования CPU или ОЗУ узла превышает указанный порог. При этом перемещаемая виртуальная машина должна приблизить узел к средней рабочей нагрузке всех узлов.
Требования
- Использование физических процессоров;
- Минимум два физических вычислительных узла;
- Установленный и настроенный компонент Ceilometer — ceilometer-agent-compute, работающий на каждом вычислительном узле, и Ceilometer API, а также сбор следующих метрик:
метрика
служба
плагины
комментарий
cpu_util
none
memory.resident
none
Параметры стратегии:
параметр
тип
по умолчанию
описание
metrics
String
‘cpu_util’
Метрики, которые лежат в основе: ‘cpu_util’, ‘memory.resident’.
threshold
Number
25.0
Порог рабочей нагрузки для миграции.
period
Number
300
Совокупный период времени Ceilometer.
Используемый метод — миграция.
Workload stabilization — стратегия, направленная на стабилизацию рабочей нагрузки с использованием живой миграции. Стратегия основана на алгоритме стандартного отклонения и определяет, существует ли перегрузка в кластере, и реагирует на нее путем запуска миграции машин для стабилизации кластера.
Требования
- Использование физических процессоров;
- Минимум два физических вычислительных узла;
- Установленный и настроенный компонент Ceilometer — ceilometer-agent-compute, работающий на каждом вычислительном узле, и Ceilometer API, а также сбор следующих метрик:
метрика
служба
плагины
комментарий
cpu_util
none
memory.resident
none
Storage Capacity Balance Strategy (стратегия реализована начиная с Queens) — стратегия переносит диски в зависимости от загруженности пулов Cinder. Решение о переносе принимается всякий раз, когда коэффициент использования пула превышает указанный порог. Перемещаемый диск должен приблизить пул к средней нагрузке всех пулов Cinder.
Требования и ограничения
- Минимум два пула Cinder;
- Возможность миграции дисков.
- Модель данных кластера — Cinder cluster data model collector.
Параметры стратегии:
параметр
тип
по умолчанию
описание
volume_threshold
Number
80.0
Пороговое значение дисков для балансировки объемов.
Используемый метод — миграция диска (volume_migrate).
Noisy Neighbor — идентифицировать и перенести “шумного соседа” — виртуальной машины с низким приоритетом, которая негативно влияет на производительность виртуальной машины с высоким приоритетом с точки зрения IPC, чрезмерно используя Last Level Cache. Собственная стратегия: Noisy Neighbor (используемый параметр стратегии — cache_threshold (значение по умолчанию — 35), при падении производительности до указанного значения запускается миграция. Для работы стратегии необходимы включенные LLC (Last Level Cache) метрики, последний Intel сервер с поддержкой CMT, а также сбор следующих метрик:
метрика
служба
плагины
комментарий
cpu_l3_cache
none
Необходим Intel .
Модель данных кластера (по умолчанию): Nova cluster data model collector. Применяемый метод — миграция.
Работа с данной целью через Dashboard не реализована в полном объеме в Queens.
Thermal Optimization — оптимизировать температурный режим. Температура на выходе (вытяжной воздух) является одной из важных тепловых телеметрических систем для измерения состояния тепловой / рабочей нагрузки сервера. Для цели имеется одна стратегия — Outlet temperature based strategy, которая принимает решения о переносе рабочих нагрузок на узлы с благоприятным температурным режимом (самая низкая температура на выходе), когда температура на выходе исходных хостов достигает настраиваемого порога.
Для работы стратегии необходим сервер с установленным и настроенным Intel Power Node Manager , а также сбор следующих метрик:
метрика
служба
плагины
комментарий
hardware.ipmi.node.outlet_temperature
IPMI
Параметры стратегии:
параметр
тип
по умолчанию
описание
threshold
Number
35.0
Температурный порог для миграции.
period
Number
30
Интервал времени в секундах для получения статистической агрегации из источника данных метрики.
Используемый метод — миграция.
Airflow Optimization — оптимизировать режим вентилирования. Собственная стратегия — Uniform Airflow using live migration. Стратегия запускает миграцию виртуальной машины всякий раз, когда воздушный поток от вентилятора сервера превышает указанный порог.
Для работы стратегии необходимы:
- Аппаратное обеспечение: вычислительные узлы <с поддержкой NodeManager 3.0;
- Минимум два вычислительных узла;
- Установленный и настроенный на каждом вычислительном узле компонент ceilometer-agent-compute и Ceilometer API, который может успешно сообщать о таких метриках как поток воздуха, мощность системы, температура на входе:
метрика
служба
плагины
комментарий
hardware.ipmi.node.airflow
IPMI
hardware.ipmi.node.temperature
IPMI
hardware.ipmi.node.power
IPMI
Для работы стратегии необходим сервер с установленным и настроенным Intel Power Node Manager 3.0 или более поздней версии.
Ограничения: Концепция не предназначена для продакшна.
Предлагается использовать этот алгоритм с непрерывными аудитами, поскольку за одну итерацию планируется миграция только одной виртуальной машины.
Возможны живые миграции.
Параметры стратегии:
параметр
тип
по умолчанию
описание
threshold_airflow
Number
400.0
Airflow threshold for migration Unit is 0.1CFM
threshold_inlet_t
Number
28.0
Inlet temperature threshold for migration decision
threshold_power
Number
350.0
System power threshold for migration decision
period
Number
30
Интервал времени в секундах для получения статистической агрегации из источника данных метрики.
Используемый метод — миграция.
Hardware Maintenance — обслуживание аппаратных средств. Стратегия, относящаяся к данной целе, — Zone migration. Стратегия является инструментом для эффективной автоматической и минимальной миграции виртуальных машин и дисков в случае необходимости проведения технического обслуживания аппаратных средств. Стратегия выстраивает план действий в соответствии с весами: набор действий, который имеет больший вес, будут запланированы раньше других. Существует два параметра конфигурации: веса действий (action_weights) и распараллеливание (parallelization).
Ограничения: необходима настройка весов действий и распараллеливания.
Параметры стратегии:
параметр
тип
по умолчанию
описание
compute_nodes
array
None
Вычислительные узлы для миграции.
storage_pools
array
None
Узлы хранения для миграции.
parallel_total
integer
6
Общее количество действий, которые должны выполняться параллельно.
parallel_per_node
integer
2
Количество действий, выполняемых параллельно для каждого вычислительного узла.
parallel_per_pool
integer
2
Количество действий, выполняемых параллельно для каждого пула хранения.
priority
object
None
Список приоритетов для виртуальных машин и дисков.
with_attached_volume
boolean
False
False — виртуальные машины будут перенесены после переноса всех дисков. True — виртуальные машины будут перенесены после миграции всех подключенных дисков.
Элементы массива вычислительных узлов:
параметр
тип
по умолчанию
описание
src_node
string
None
Вычислительный узел, с которого переносятся виртуальные машины (обязательно).
dst_node
string
None
Вычислить узел, на который мигрируют виртуальные машины.
Элементы массива узлов хранения:
параметр
тип
по умолчанию
описание
src_pool
string
None
Пул хранения, из которого переносятся диски (обязательно).
dst_pool
string
None
Пул хранения, на который переносятся диски.
src_type
string
None
Исходный тип диска (обязательно).
dst_type
string
None
Итоговый тип диска (обязательно).
Элементы приоритетности объектов:
параметр
тип
по умолчанию
описание
project
array
None
Имена проектов.
compute_node
array
None
Имена вычислительных узлов.
storage_pool
array
None
Имена пулов хранения.
compute
enum
None
Параметры виртуальной машины [“vcpu_num”, “mem_size”, “disk_size”, “created_at”].
storage
enum
None
Параметры дисков [“size”, “created_at”].
Используемые методы — миграция виртуальных машин, миграция дисков.
Unclassified — вспомогательная цель, используемая для облегчения процесса разработки стратегии. Не содержит спецификаций и может использоваться всякий раз, когда стратегия еще не связана с существующей целью. Эта цель также может быть использована в качестве переходного этапа. Связанная с данной целью стратегия — Actuator.
Создание новой цели
Watcher Decision Engine имеет интерфейс плагина “внешней цели”, который дает возможность интегрировать внешнюю цель, которая может быть достигнута с помощью стратегии.
Прежде чем создавать новую цель, следует убедиться, что ни одна из существующих целей не соответствует вашим потребностям.
Создание нового плагина
Чтобы создать новую цель, вы должны: расширить класс цели, реализовать метод класса get_name () для возвращения уникального идентификатора новой цели, которую вы хотите создать. Этот уникальный идентификатор должен совпадать с именем точки входа, которую вы декларируете позже.
Далее необходимо реализовать метод класса get_display_name () для возвращения переведенного отображаемого имени цели, которую вы хотите создать (не используйте переменную для возврата переведенной строки, чтобы она могла автоматически собираться инструментом перевода.).
Реализуйте метод класса get_translatable_display_name (), чтобы вернуть ключ перевода (фактически английское отображаемое имя) вашей новой цели. Возвращаемое значение должно совпадать со строкой, переведенной в get_display_name ().
Реализуйте его метод get_efficacy_specification (), чтобы вернуть спецификацию эффективности для вашей цели. Метод get_efficacy_specification () возвращает экземпляр Unclassified (), предоставленный Watcher. Эта спецификация эффективности полезна в процессе разработки вашей цели, поскольку она соответствует пустой спецификации.
→
Архитектура Watcher (подробнее ).
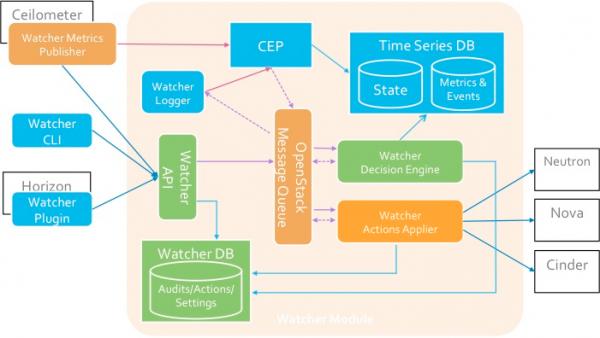
Компоненты
Watcher API — компонент, реализующий REST API, предоставляемый Watcher. Механизмы взаимодействия: CLI, плагин Horizon, Python SDK.
Watcher DB — база данных Watcher.
Watcher Applier — компонент, реализующий выполнение плана действий, созданного компонентом Watcher Decision Engine.
Watcher Decision Engine — компонент, отвечающий за вычисление набора потенциальных действий по оптимизации для выполнения цели аудита. Если стратегия не указана, компонент самостоятельно выбирает наиболее подходящую.
Watcher Metrics Publisher — компонент, который собирает и вычисляет некоторые метрики или события и публикует их в конечной точке CEP. Функционал компонента может предоставляться также Ceilometer publisher.
Complex Event Processing (CEP) Engine — движок комплексной обработки событий. По соображениям производительности может быть несколько экземпляров CEP Engine, работающих одновременно, каждый из которых обрабатывает определенный тип метрики / событий. В системе Watcher CEP запускает два типа действий: — записать соответствующие события / метрики в базу данных временных рядов; — отправлять соответствующие события в компонент Watcher Decision Engine, когда это событие может повлиять на результат текущей стратегии оптимизации, поскольку кластер Openstack не является статической системой.
Взаимодействие компонентов осуществляется по протоколу AMQP.
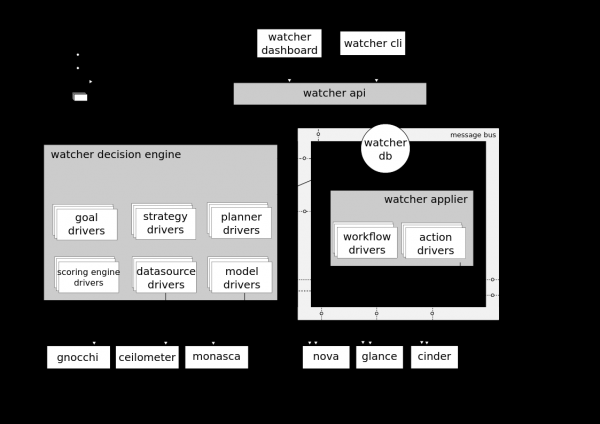
→
Схема взаимодействия с Watcher

Результаты тестирования Watcher
- На странице Optimization — Action plans 500 ошибка (как на чистом Queens, так и на стенде с модулями Тионикс), появляется только после того, как запускается аудит и генерируется план действий, пустая открывается нормально.
- На вкладке Action details ошибки, не удается получить цель и стратегию аудита (как на чистом Queens, так и на стенде с модулями Тионикс).
- Аудиты с целью Dummy (тестовые) создаются и запускаются нормально, генерируются планы действий.
- Аудиты с целью Unclassified не создаются, так как цель не является функциональной и предназначена для промежуточной настройки при создании новых стратегий.
- Аудиты с целью Workload Balancing (стратегия Storage Capacity balance) создаются успешно, однако план действий не генерируется. Не требуется оптимизация пулов хранения.
- Аудиты с целью Workload Balancing (стратегия Workload Balance Migration Strategy) создаются успешно, однако план действий не генерируется.
- Аудиты с целью Workload Balancing (стратегия Workload Stabilization Strategy) завершаются ошибкой.
- Аудиты с целью Noisy Neighbor создаются успешно, однако план действий не генерируется.
- Аудиты с целью Hardware maintenance создаются успешно, план действий генерируется не в полном объеме (генерируются показатели эффективности, но не генерируется сам список действий).
- Правки в конфигах nova.conf (в default секции compute_monitors = cpu.virt_driver) на вычислительных и управляющем узле не исправляют ошибки.
- Аудиты с целью Server Consolidation (стратегия Basic) также завершаются с ошибкой.
- Аудиты с целью Server Consolidation (стратегия VM workload consolidation) завершаются с ошибкой. В логах ошибка получения исходных данных. Обсуждение ошибки, в частности, .
Попробовали указать в конфиг-файле Watcher (не помогло — в результате ошибки на всех страницах Optimization, возвращение к исходному содержимому конфиг-файла не исправляет ситуацию):[watcher_strategies.basic]
datasource = ceilometer, gnocchi - Аудиты с целью Saving Energy завершаются с ошибкой. Судя по логам, проблема все-таки в отсутствии Ironic, не будет работать без baremetal service.
- Аудиты с целью Thermal Optimization завершаются с ошибкой. Трейсбек тот же, что и для Server Consolidation (стратегия VM workload consolidation) (ошибка исходных данных)
- Аудиты с целью Airflow Optimization завершаются с ошибкой.
Встречаются также следующие ошибки завершения аудита. Трейсбэк в логах decision-engine.log (не определено состояние кластера).
→ Обсуждение ошибки
Заключение
Результатом наших двухмесячных изысканий стал однозначный вывод о том, что для получения полноценной, работающей системы балансировки нагрузки нам придется, в этой части, вплотную заняться доработкой инструментария для платформы Openstack.
Watcher показал себя серьезным и быстро развивающимся продуктом с огромным потенциалом, для полноценного использования которого потребуется большая и серьезная работа.
Но об этом – в следующих статьях цикла.
Источник: habr.com
