


Будет рассмотрен вклад Яндекса в следующие базы данных.
- ClickHouse
- Odyssey
- Восстановление на точку во времени (WAL-G)
- PostgreSQL (включая logerrors, Amcheck, heapcheck)
- Greenplum
Видео:

Hello world! Меня зовут Андрей Бородин. И я в Яндекс.Облаке занимаюсь тем, что развиваю открытые реляционные базы данных в интересах Яндекс.Облака и клиентов Яндекс.Облака.

В этом докладе мы поговорим о том, какие проблемы возникают у открытых баз данных в масштабе. Почему это важно? Потому что маленькие-маленькие проблемки, которые, как комарики, потом становятся слонами. Они становятся большими, когда у вас много кластеров.
Но это не главное. Бывают невероятные вещи. Вещи, которые происходят в одном на миллион случае. И в облачном окружении вы должны быть к этому готовы, потому что невероятные вещи становятся весьма вероятными, когда что-то существует в масштабе.
Но! В чем плюс открытых баз данных? В том, что у вас есть теоретическая возможность с любой проблемой бороться. У вас есть исходный код, у вас есть знания программирования. Совмещаем и работает.

Какие подходы есть в работе над открытым программным обеспечением?
- Самый понятный подход – это использование программного обеспечения. Если вы используете протоколы, если вы используете стандарты, если вы используете форматы, если вы пишите запросы на программном обеспечении из open source, то вы уже его поддерживаете.
- Вы делаете его экосистему больше. Вы делаете вероятность раннего обнаружения бага больше. Вы повышаете надежность этой системы. Вы повышаете доступность разработчиков на рынке. Вы улучшаете это программное обеспечение. Вы уже контрибьютор, если вы просто сделали up getting style и что-нибудь там поковыряли.
- Другой понятный подход – это спонсирование открытого программного обеспечения. Например, всем известная программа Google Summer of Code, когда Google платит большому количеству студентов со всего мира понятные деньги за то, чтобы они развивали открытые программные проекты, которые удовлетворяют определенным требованиям по лицензии.
- Это очень интересный подход, потому что он позволяет развивать программное обеспечение, не смещая фокус с сообщества. Google, как технологический гигант, не говорит о том, что мы хотим вот эту фичи, хотим починить вот этот баг и вот там нужно копать. Google говорит: «Делайте то, что вы делаете. Просто продолжайте работать так, как работали и все будет хорошо».
- Следующий подход участия в open source – это соучастие. Когда у вас есть проблема в открытом программном обеспечении и есть разработчики, то ваши разработчики начинают проблемы решать. Они начинают делать вашу инфраструктуру более эффективной, ваши программы более быстрыми и надежными.

Один из наиболее известных яндексовых проектов в области СПО – это ClickHouse. Это база данных, которая родилась как ответ на вызовы, стоящие перед Яндекс.Метрикой.
И как база данных она была сделана в open source для того, чтобы создавать экосистему и совместно с другими разработчиками (не только внутри Яндекса) ее развивать. И сейчас это большой проект, в котором участвует множество различных компаний.

В Яндекс.Облаке мы сделали ClickHouse поверх Yandex Object Storage, т. е. поверх облачного хранилища.
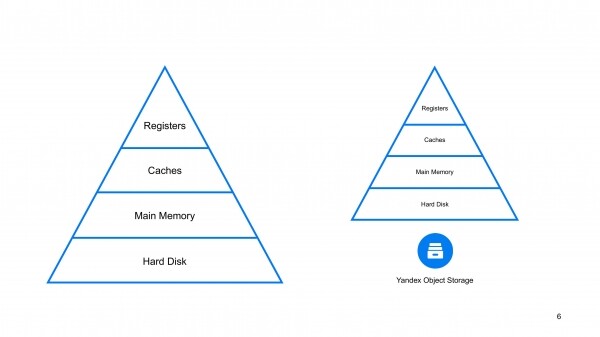
Почему это важно именно в облаке? Потому что любая база данных работает в этом треугольнике, в этой пирамиде, в этой иерархии типов памяти. У вас есть быстрые, но маленькие регистры и дешевые большие, но медленные SSD-диски, жесткие диски и какие-то еще блочные устройства. И если вы эффективны сверху пирамиды, то у вас быстрая база данных. если вы эффективны снизу этой пирамиды, то у вас масштабированная база данных. И в этом плане добавление еще одного слоя снизу – это логичный подход по увеличению масштабируемости база данных.

Как его можно было сделать? Это важный момент в этом докладе.
- Мы могли реализовать ClickHouse over MDS. MDS – это внутренний яндексовый интерфейс облачного хранилища. Он более сложный, чем распространенный протокол S3, но он больше подходит для блочного устройства. Он лучше подходит для записи данных. Он требует больше программирования. Программисты будут программировать, это даже хорошо, интересно.
- S3 – более распространенный подход, который делает более простой интерфейс ценой меньшей адаптации под некоторые типы нагрузок.
Естественно, желая предоставить функциональность всей экосистеме ClickHouse и сделать ту задачу, которая нужна внутри Яндекс.Облака, мы решили сделать так, чтобы эффект от нее получило все сообщество ClickHouse. Мы реализовали ClickHouse over S3, а не ClickHouse over MDS. А это большое количество работы.

Ссылки:
«Filesystem abstraction layer”
«AWS SDK S3 integration”
«Base implementation of IDisk interafce for S3”
«Integration of log storage engines with IDisk interface»
«Log engine support for S3 and SeekableReadBuffer»
«Storage Stripe Log S3 support»
«Storage MergeTree initial support for S3»
«MergeTree full support for S3»
«Support ReplicatedMergeTree over S3»
«Add default credentials and custom headers for s3 storage»
«S3 with dynamic proxy configuration»
«S3 with proxy resolver»
Это список pull request для реализации виртуальной файловой системы в ClickHouse. Это большое количество pull requests.

Ссылки:
«DiskS3 hardlinks optimal implementation»
«S3 HTTP client — Avoid copying response stream into memory»
«Avoid copying whole response stream into memory in S3 HTTP
client»
«Ability to cache mark and index files for S3 disk»
«Move parts from DiskLocal to DiskS3 in parallel»
Но на этом работа не закончилась. После того, как фича была сделана, потребовалось еще какое-то количество работы для того, чтобы оптимизировать эту функциональность.

Ссылки:
«Add SelectedRows and SelectedBytes events»
«Add profiling events from S3 request to system.events»
«Add QueryTimeMicroseconds, SelectQueryTimeMicroseconds and InsertQueryTimeMicroseconds»
И потом потребовалось сделать ее диагностируемой, наладить мониторинги и сделать ее управляемой.
И все это было сделано так, чтобы все сообщество, вся экосистема ClickHouse результат этой работы получила.

Давайте перейдем к транзакционным базам данным, к OLTP базам данным, которые лично мне ближе.

Вот это подразделение разработки СУБД с открытым кодом. Вот эти ребята делают уличную магию по улучшению транзакционных открытых баз данных.
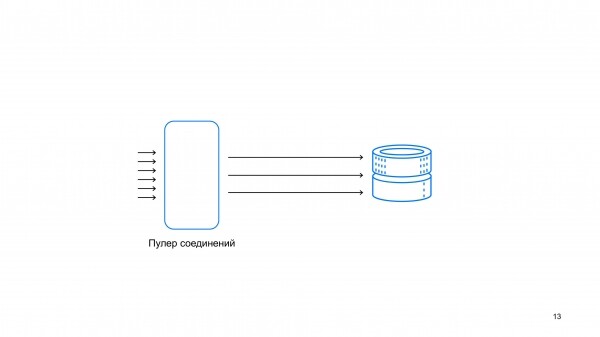
Один из проектов, на примере которого можно рассказать, о том, как и что мы делаем, это Пулер соединений в Postgres.
Postgres – это процессная база данных. Это означает, что в базу данных должно входить как можно меньше сетевых соединений, которые работают с транзакциями.
С другой стороны, в облачном окружении типичная ситуация, когда в один кластер пришло сразу тысяча соединений. И задача пулера соединения тысячу соединений упаковать в небольшое количество серверных соединений.

Можно сказать, что пулер соединения – это телефонист, который перекладывает байтики так, чтобы они эффективно доехали до базы данных.
К сожалению, нет хорошего русского слова для обозначения пулера соединений. Иногда его называют multiplexer соединений. Если вы знаете, как назвать connection pooler, то обязательно мне скажите, я буду очень рад говорить на правильном русском техническом языке.
Мы исследовали пулеры соединений, которые подходили для управляемого postgres’ного кластера. И лучше всего нам подходил PgBouncer. Но мы сталкивались с рядом проблем в PgBouncer. Много лет назад Володя Бородин делал доклады о том, что мы используем PgBouncer, нам все нравится, но есть нюансы, есть над чем работать.
И мы работали. Те проблемы, с которыми мы сталкивались, мы чинили, мы патчили Bouncer, старались относить pull request в upstream. Но с фундаментальной однопоточностью сложно было работать.
Нам пришлось собирать каскады с патченых Bouncers. Когда у нас множество однопоточных Bouncers, то на верхнем слое переводят соединения во внутренний слой Bouncers. Это плохо управляемая, сложная в построении и в масштабировании туда и обратно система.

Мы пришли к тому, что мы создали свой пулер соединений, который называется Odyssey. Мы написали его с нуля.

В 2019-ом году на конференции PgCon я представлял этот пулер сообществу разработчиков. Сейчас у нас чуть меньше 2 000 звездочек на GitHub, т. е. проект живет, проект популярен.
И если вы создаете кластер Postgres в Яндекс.Облаке, то это будет кластер со встроенным Odyssey, который перенастраивается при масштабировании кластера туда или обратно.

Чему мы научились в этом проекте? Запуск конкурирующего проекта – это всегда агрессивный шаг, это крайняя мера, когда мы говорим, что есть проблемы, которые не решаются достаточно быстро, не решаются в те промежутки времени, которые нас устроили бы. Но это эффективная мера.
PgBouncer начал развиваться быстрее.
И сейчас появились другие проекты. Например, pgagroal, которые развивается разработчиками Red Hat. Они преследуют похожие цели и реализуют похожие идеи, но, конечно, со своей спецификой, которая ближе разработчикам pgagroal.

Еще один случай работы с postgres’ным сообществом – это восстановление на точку во времени. Это восстановление после сбоя, это восстановление из бэкапа.

Бэкапилок много и они все разные. У почти каждого вендора Postgres есть свое бэкапное решение.
Если взять все системы резервного копирования, составить матрицу фич и в шутку посчитать определитель в этой матрице, то он будет нулевой. Что это означает? Что, если взять какую-то конкретную бэкапилку, то ее нельзя собрать из кусков всех остальных. Она уникальна в своей реализации, она уникальна в своем назначении, она уникальна в идеях, которые заложены в нее. И все они специфичны.
Когда мы занимались этим вопросом, компания CitusData запустила проект WAL-G. Это система резервного копирования, которая была сделана с прицелом на облачное окружение. Сейчас CitusData – это уже часть Microsoft. А в тот момент, идеи, которые были заложены на начальных релизах WAL-G, нам очень понравились. И мы начали контрибьютить в этот проект.
Сейчас в этом проекте много десятков разработчиков, но в топ-10 контрибьюторов WAL-G входят 6 яндексоидов. Мы много своих идей принесли в туда. И, конечно, сами их реализовали, сами их протестировали, сами их выкатили в production, сами их используем, сами придумываем, куда двигаться дальше, при этом взаимодействуем с большим сообществом WAL-G.

И с нашей точки зрения, сейчас эта система резервного копирования, в том числе учитывая наши усилия, стала оптимальной для облачного окружения. Это лучшее, чем стоит бэкапить Postgres в облаке.
Что это значит? Мы продвигали достаточно большую идею: резервное копирование должно быть безопасным, дешевым при эксплуатации и максимально быстрым при восстановлении.
Почему оно должно быть дешевым при эксплуатации? Когда ничего не сломалось, вы не должны знать, что у вас есть резервные копии. Все работаете нормально, вы тратите как можно меньше центрального процессора, вы используете как можно меньше ресурсов вашего диска и шлете как можно меньше байтиков в сеть, чтобы не мешать полезной нагрузке ваших ценных сервисов.
А когда все сломалось, например, админ дропнул данные, что-то пошло не так, и вам нужно срочно вернуться в прошлое, вы восстанавливаетесь на все деньги, потому что вы хотите ваши данные вернуть быстро и в целости.
И мы эту простую идею продвинули. И, как нам кажется, нам удалось ее реализовать.

Но это не все. Мы хотели еще одну маленькую вещь. Мы хотели много разных баз данных. Не все наши клиенты пользуются Postgres. Некоторые пользуются MySQL, MongoDB. В сообществе другие разработчики поддержали FoundationDB. И это список постоянно расширяется.
Идея того, что база данных эксплуатируется в управляемом окружении в облаке, сообществу нравится. И разработчики поддерживают свои базы данных, которые единообразно вместе с Postgres нашей системой резервного копирования можно копировать.

Чему мы научились в этой истории? Наш продукт, как подразделение развития, это не строчки коды, это не операторы, это не файлы. Наш продукт это не pull requests. Это идеи, которые мы транслируем сообществу. Это технологическая экспертиза и движение технологий в сторону облачного окружения.

Есть такая база данных, как Postgres. Мне ядро Postgres нравится больше всего. Я много времени трачу на то, чтобы развивать ядро Postgres совместно с сообществом.

Но тут надо сказать, что у Яндекс.Облака есть внутренняя инсталляция управляемых баз данных. И началась она давным-давно в Яндекс.Почте. Та экспертиза, которая привела сейчас к управляемому Postgres, она была накоплена тогда, когда почта захотела заехать в Postgres.
У почты очень похожие с облаком требования. Ей нужно, чтобы вы могли отмасштабироваться на неожиданный экспоненциальный рост в любой точке ваших данных. И у почты уже была нагрузка с какими-то сотнями миллионов ящиков огромного количества пользователей, которые постоянно делают много запросов.
И это был довольно серьезный вызов для команды, которая занималась развитием Postgres. Тогда все проблемы, с которыми мы сталкивались, сообщались сообществу. И эти проблемы исправлялись, причем исправлялись сообществом местами даже на уровне платной поддержки некоторых других баз данных и даже лучше. Т. е. отправить письмо в PgSQL hacker и получить ответ можно в течение 40 минут. Платный саппорт в каких-то базах данных может подумать, что есть более приоритетные вещи, чем ваш баг.
Сейчас внутренняя инсталляция Postgres – это какие-то петабайты данных. Это какие-то миллионы запросов в секунду. Это тысячи кластеров. Она очень масштабная.
Но есть нюанс. Она живет не на модных сетевых дисках, а на достаточно простом железе. И там есть тестовое окружение специально для интересных новых вещей.

И в определенный момент в тестовом окружении мы получили такое сообщение, которое свидетельствует о том, что нарушены внутренние инварианты индексов баз данных.
Инвариант – это какое-то соотношение, которое мы ожидаем, что будет выполняться всегда.
Очень критичная ситуация для нас. Она свидетельствует о том, что какие-то данные, возможно, потеряны. А потеря данных – это что-то прямо катастрофическое.
Общая идея, которой мы следуем в управляемых базах данных в том, что даже прилагая усилия, потерять данные будет сложно. Даже если вы их целенаправленно удалите, вам понадобится еще игнорировать их отсутствие в течение длительного промежутка времени. Сохранность данных – это религия, которой мы следуем довольно усердно.
А тут возникает ситуация, которая говорит о том, что может быть ситуация, к которой мы можем быть не готовы. И мы начали готовиться к этой ситуации.
Первое, что мы сделали, мы погрепали логи с этих тысяч кластеров. Нашли, какие из кластеров располагаются на дисках с проблемными прошивками, которые теряли обновление страниц данных. Разметили всю кодовую данных Postgres. И те сообщения, которые свидетельствуют о нарушениях внутренних инвариантов, мы разметили кодом, который предназначен для обнаружения коррупции данных.
Этот патч был практически принят сообществом без особого обсуждения, потому что в каждом конкретном случае было очевидно, что что-то плохое случилось, нужно сообщить в лог об этом.

После этого мы пришли к тому, что у нас есть мониторинг, который сканирует логи. И в случае подозрительных сообщений будит дежурного, и дежурный чинит.
Но! Сканирование логов – это дешевая операция на одном кластере и катастрофически дорогая для тысячи кластеров.
Мы написали расширение, которое называется . Оно создает представление о базе данных, в котором можно дешево и быстро поселектить статистику по прошедшим ошибкам. И если нужно будить дежурного, то мы узнаем об этом, не сканируя гигабайтные файлы, а извлекая несколько байт из хеш-таблицы.
Это расширение было принято, например, в репозитарии для . Если вы хотите его использовать, вы можете себе его поставить. Конечно, это open source.

Но это не все. Мы начали использовать Amcheck — расширение, которое создано сообществом, для поиска нарушений инвариантов в индексах.
И мы выяснили, что если эксплуатировать его в масштабе, то там есть баги. Мы начали их чинить. Наши исправления были приняты.
Мы обнаружили, что это расширение не умеет анализировать GiST & GIT индексы. Мы сделали их поддержку. Но это поддержка пока обсуждается сообществом, потому что это относительно новая функциональность и там есть много деталей.
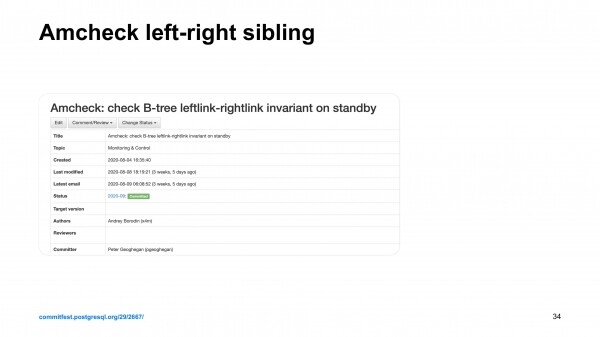
И еще мы обнаружили, что в случае проверок индексов на нарушение на лидере репликации, на мастере все работает хорошо, а на репликах, на follower поиск коррупций не такой эффективный. Не все инварианты проверяются. И один инвариант нас беспокоил очень сильно. И мы полтора года общались с сообществом для того, чтобы включить эту проверку на репликах.
Писали код, который должен следовать всем can… протоколам. Обсуждали довольно долго с Питером Гейганом из Crunchy Data этот патч. Ему пришлось немножко модифицировать существующее B-дерево в Postgres для того, чтобы этот патч принять. Он был принят. И сейчас проверка индексов на репликах тоже стала достаточно эффективной для того, чтобы обнаруживать те нарушения, с которыми мы сталкивались. Т. е. это те нарушения, которые могут быть вызваны ошибками в прошивке дисков, багами в Postgres, багами в ядре Linux, железными проблемами. Довольно обширный список источников проблем, к которым мы готовились.

Но кроме индексов есть такая часть, как heap, т. е. то место, где данные хранятся. И там не так много инвариантов, которые можно было бы проверять.
У нас есть расширение, которые называется Heapcheck. Мы начали его развивать. И параллельно вместе с нами компания EnterpriseDB тоже стала писать модуль, который они назвали точно так же Heapcheck. Только мы его назвали PgHeapcheck, а они просто Heapcheck. Он у них с аналогичными функциями, немножко с другой сигнатурой, но с теми же идеями. Они чуть-чуть местами получше их реализовали. И раньше выложили в open source.
И теперь мы занимаемся тем, что развиваем их расширение, потому что это уже не их расширение, а расширение сообщества. И в будущем – это часть ядра, которая будет поставляться всем для того, чтобы можно было о будущих проблемах знать заранее.
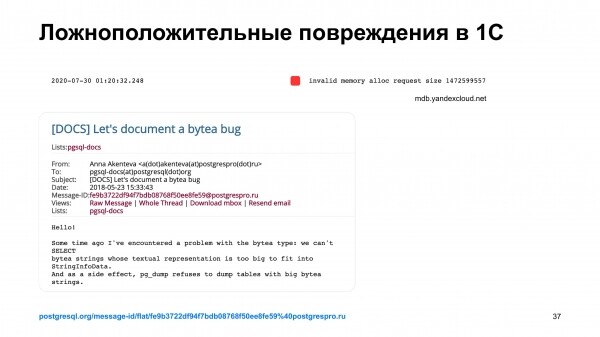
Местами мы даже пришли к тому, что у нас есть ложноположительные срабатывания у наших мониторингов. Например, система 1С. При использовании базы данных Postgres иногда записывает в нее такие данные, которые сама считать сможет, но pg_dump считать их не сможет.
Эта ситуация выглядела для нашей системы обнаружения проблем как коррупция. Дежурного разбудили. Дежурный посмотрел, что происходит. Через некоторое время пришел клиент и сказал, что у меня есть проблемы. Дежурный объяснил, в чем проблема. Но проблема в ядре Postgres.
Я нашел обсуждение этой особенности. И написал, что мы столкнулись с этой особенностью и было неприятно, человек ночью просыпался для того, чтобы разобраться с тем, что это такое.

Сообщество ответило: «О, действительно, надо чинить».
У меня есть простая аналогия. Если вы ходите в ботинке, в который попала песчинка, то, в принципе, можно идти дальше – ничего страшного. Если вы продаете ботинки тысячам человек, то давайте делать ботинки без песка совсем. А если кто-то из пользователей ваших ботинок собрался бежать марафон, то вы хотите сделать очень хорошие ботинки, а потом уже отмасштабировать на всех ваших пользователей. И такие неожиданные пользователи всегда в облачном окружении находятся. Всегда находятся пользователи, которые эксплуатируют кластер каким-то оригинальным способом. К этому надо всегда готовиться.

Чему мы здесь научились? Мы научились простой вещи: самое главное объяснить сообществу, что проблема есть. Если сообщество осознало проблему, то возникает естественная конкуренция за то, чтобы проблему решить. Потому что важную проблему все хотят решить. Все вендоры, все хакеры понимают, что сами могут на эти грабли наступить, поэтому хотят их устранить.
Если вы работаете над какой-то проблемой, но она кроме вас никого не беспокоит, но вы работаете над ней системно и ее в конечном итоге посчитали проблемой, то ваш pull request обязательно будет принят. Ваш патч будет принят, ваши доработки или даже запросы на доработки будут рассмотрены сообществом. В конце концов мы делаем базу данных лучше друг для друга.

Интересная база данных – Greenplum. Это сильно параллельная база данных, основанная на кодовой базе Postgres, которая мне хороша знакома.
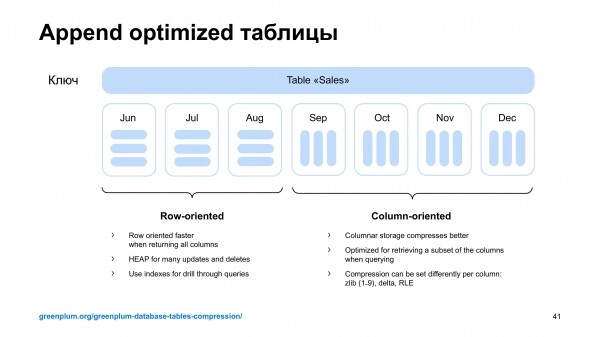
И в Greenplum есть интересная функциональность – это append optimized таблицы. Это такие таблицы, в которых можно быстро дописывать. Они могут быть либо столбцовыми, либо строчными.
Но там не было кластеризации, т. е. не было функциональности, когда можно упорядочить данные, расположенные в таблице, в соответствии с порядком, который есть в каком-то из индексов.
Ко мне пришли ребята из такси и говорят: «Андрей, ты же знаешь Postgres. И тут почти то же самое. Переключение на 20 минут. Берешь и делаешь». Я подумал, что да, я же знаю Postgres, переключение на 20 минут – надо этим заняться.
Но нет, это было не 20 минут, я писал это несколько месяцев. На конференции PgConf.Russia я подошел к Heikki Linakangas из Pivotal и спросил: «Есть какие-то проблемы с этим? Почему нет кластеризации append optimized таблицы?». Он говорит: «Берешь данные. Сортируешь, перекладываешь. Это просто работа». Я: «О, да, это надо просто взять и сделать». Он говорит: «Да, нужны свободные руки, которые это сделают». Я подумал, что точно надо этим заняться.
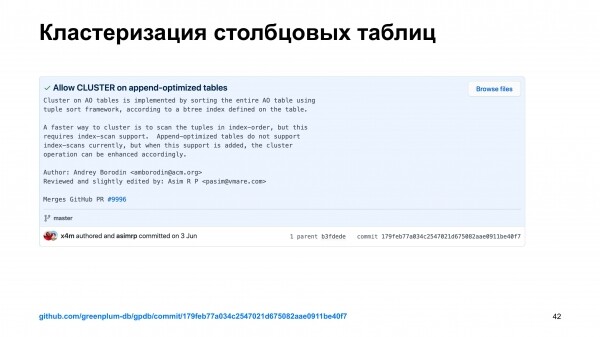
И через несколько месяцев я отправил pull request, который реализовывал эту функциональность. Этот pull request посмотрели в Pivotal совместно с сообществом. Конечно, там были баги.
Но самое интересное, что при мерже этого pull request в самом Greenplum нашли баги. Мы обнаружили, что heap-таблицы при кластеризации иногда нарушают транзакционность. И это вещь, которую надо чинить. И она в том месте, которое я только что трогал. И естественная реакция моя была – хорошо, давайте я этим тоже займусь.
Я починил этот баг. Отправил pull request фиксам. Его помержили.
После чего выяснилось, что эту функциональность нужно получить еще в версии Greenplum для PostgreSQL 12. Т. е. приключения на 20 минут продолжаются новыми интересными приключениями. Было интересно потрогать актуальное развитие, где сообщество пилит новые и самые важные фичи. Это помержили.
Но этим все не закончилось. После всего выяснилось, что нужно и документацию на это все написать.
Я начал писать документацию. К счастью, пришли документаторы из Pivotal. Для них английский язык родной. Они помогли мне с документацией. По сути, сами переписали то, что я предлагал на настоящий английский.
И на этом, казалось бы, приключение закончилось. И знаете, что произошло потом? Ко мне пришли ребята из такси и говорят: «Тут два приключения еще есть, каждое на 10 минут». И что мне надо было им сказать? Я сказал, что сейчас доклад на scale сделаю, потом посмотрим ваши приключения, потому что это интересная работа.

Чему мы научились в этом случае? Тому, что работа с open source – это всегда работа с конкретным человеком, это всегда работа с сообществом. Потому что в каждой отдельной стадии я работал с каким-то разработчиком, с каким-то тестировщиком, с каким-то хакером, с каким-то документаром, с каким-то архитектором. Я работал не с Greenplum, я работал с людьми вокруг Greenplum.
Но! Есть еще один важным момент – это просто работа. Т. е. приходишь, выпиваешь кофе, пишешь код. Работают всякие простые инварианты. Нормально делай – нормально будет! И это довольно интересная работа. На эту работу есть запрос со стороны клиентов Яндекс.Облака, пользователей наших кластеров как внутри Яндекса, так и снаружи. И, я думаю, что количество проектов, в которых мы участвуем, будет увеличиваться и глубина нашего вовлечения тоже будет увеличиваться.
На этом все. Давайте переходить к вопросам.

Сессия вопросов
Привет! У нас очередная сессия вопросов и ответов. И в студии Андрей Бородин. Это человек, который только что вам рассказывал про вклад Яндекс.Облака и Яндекса в open source. У нас сейчас доклад не совсем про Облако, но в то же самое время на таких технологиях мы и базируемся. Не будь того, что сделали вы внутри Яндекса, не было сервиса в Яндекс.Облаке, поэтому спасибо тебе от меня лично. И первый вопрос из трансляции: «На чем написан каждый из проектов, который ты упоминал?».
Система резервного копирования в WAL-G написана на Go. Это один из наиболее новых проектов, над которым мы работали. Ему буквально всего 3 года. А база данных зачастую – это про надежность. И это означает, что базы данных довольно старые и они написаны обычно на C. Проект Postgres начинался лет 30 назад. Тогда правильным выбором был C89. И на нем Postgres написан. Более современные базы такие, как ClickHouse уже пишут на C++ обычно. Вся системная разработка базируется вокруг C и C++.
Вопрос от нашего финансового менеджера, который отвечает в Облаке за расходы: «Зачем Облако тратит деньги на поддержку open source?».
Тут есть простой ответ для финансового менеджера. Мы это делаем для того чтобы делать наши сервисы лучше. В каком плане мы можем сделать лучше? Мы можем сделать эффективнее, быстрее, сделать что-то более масштабируемым. Но для нас эта история в первую очередь про надежность. Например, в системе резервного копирования мы ревьюним 100 % патчи, которые к нему применяются. Мы знаем, что это за код. И мы спокойнее выкатываем новые версии в production. Т. е. в первую очередь это про уверенность, про готовность к развитию и про надежность
Еще вопрос: «Отличается ли требования внешних пользователей, которые живут в Яндекс.Облаке, от внутренних пользователей, которые живут во внутреннем Облаке?».
Профиль нагрузок, конечно, разный. Но с точки зрения моего подразделения, все особенные и интересные случаи создаются на нестандартной нагрузке. Разработчики с фантазией, разработчики, делающие неожиданные вещи, они встречаются равно вероятно как внутри, так и снаружи. В этом плане у нас все примерно одинаково. И, наверное, единственная важная особенность внутри яндексовой эксплуатации баз данных будет то, что внутри Яндекса у нас есть учение. В какой-то момент какая-то зона доступности полностью уходит в тень, и все сервисы Яндекса должны как-то продолжить функционировать, несмотря на это. Вот это небольшое отличие. Но оно создает много исследовательской разработки на стыке базы данных и сетевого стека. В остальном внешние и внутренние инсталляции создают одинаковые запросы на фичи и схожие запросы по улучшению надежности и производительности.
Следующий вопрос: «Как лично ты относишься к тому, что многое из того, что ты делаешь, используется другими Облаками?». Мы не будем называть конкретные, но многие проекты, которые сделали в Яндекс.Облаке, используются в чужих облаках.
Это же классно. Во-первых, это признак того, что мы сделали что-то правильное. И это чешет эго. И мы больше уверены в том, что приняли правильное решение. С другой стороны, это надежда, что в будущем это будет нам приносить новые идеи, новые запросы со стороны сторонних пользователей. Большинство issues на GitHub создаются отдельными сисадминами, отдельными DBA, отдельными архитекторами, отдельными инженерами, но иногда приходят люди со систематизированным опытом и говорят, что в 30 % определенных случаях у нас есть вот такая-то проблема и давайте подумаем, как ее решить. Вот это то, чего мы ждем больше всего. Мы ждем, что у нас будет обмен опытом с другими облачными платформами.
Ты рассказывал много про марафон. Я знаю, что ты пробежал марафон в Москве. Как результат? Обогнал ребят из Postgres Pro?
Нет, Олег Бартунов бегает очень быстро. Он на час раньше меня финишировал. В целом я доволен тем, что я добежал. Для меня просто финиш был достижением. В целом это удивительно, что в postgres’овом сообществе столько бегунов. Мне кажется, что есть какая-то зависимость между аэробными видами спорта и стремлением к системному программированию.
Ты хочешь сказать, что в ClickHouse нет бегунов?
Я точно знаю, что они там есть. ClickHouse – это тоже база данных. Кстати, мне сейчас Олег пишет: «Идем бегать после доклада?». Это отличная идея.
Еще вопрос из трансляции от Никиты: «Почему ты баг в Greenplum правил сам, а не отдал junior’ам?». Правда, тут не очень пояснено, что за баг и в каком сервисе, но, наверное, имеется в виду тот, о котором ты рассказывал.
Да, в принципе, можно было отдать кому-то. Просто это был код, который я только что поменял. И было естественным продолжить тут же его сделать. В принципе, идея разделять экспертизу с командой – это хорошая идея. Мы обязательно будем разделять задачи по Greenplum между всеми участниками нашего подразделения.
Раз речь зашла про junior’ов, такой вопрос. Человек решил создать первый коммит в Postgres. Что ему надо сделать, чтобы сделать первый коммит?
Это интересный вопрос: «С чего начать?». Обычно начать с чего-то в ядре достаточно сложно. В Postgres, например, есть список to do list. Но на самом деле это лист того, что пытались сделать, но не получилось. Это сложные вещи. И обычно можно найти какие-то утилиты в экосистеме, какие-то расширения, которые можно улучшить, которые привлекают меньше внимания разработчиков ядра. И, соответственно, там есть больше точек для роста. На программе Google Summer of code каждый год postgres’ное сообщество выставляет много различных тем, которыми можно было бы заняться. В этом году у нас, кажется, было три студента. Один даже в WAL-G писал по темам, которые важны для Яндекса. В Greenplum все проще, чем в сообществе Postgres, потому что хакеры Greenplum очень хорошо относятся pull request’ам и начинают ревьювить прямо сразу. Отправить патч в Postgres – это какая-то история на месяцы, а в Greenplum придут через день и посмотрят, что ты сделал. Другое дело, что в Greenplum нужно решать актуальные проблемы. Greenplum эксплуатируется не так широко, поэтому найти свою проблему довольно сложно. А в первую очередь надо решать, конечно, проблемы.
Источник: habr.com
