

Рынок распределенных вычислений и больших данных, если верить , растет на 18-19% в год. Значит, вопрос выбора софта для этих целей остается актуальным. В этом посте мы начнем с того, зачем нужны распределенные вычисления, подробней остановимся на выборе ПО, расскажем о применении Hadoop с помощью Cloudera, а напоследок поговорим о выборе железа и о том, как оно разными способами влияет на производительность.

Зачем нужны распределенные вычисления в обычном бизнесе? Тут все просто и сложно одновременно. Просто — потому что в большинстве случаев мы выполняем относительно несложные расчеты на единицу информации. Сложно — потому что такой информации много. Очень много. Как следствие, приходится . Таким образом сценарии использования довольно универсальны: расчеты могут применяться везде, где требуется учесть большое количество метрик на еще большем массиве данных.
Один из недавних примеров: сеть пиццерий Додо Пицца на основании анализа базы заказов клиентов, что при выборе пиццы с произвольной начинкой пользователи обычно оперируют лишь шестью базовыми наборами ингредиентов плюс парой случайных. В соответствии с этим пиццерия подстроила закупки. Кроме того, у нее получилось лучше рекомендовать пользователям дополнительные товары, предлагаемые на этапе заказа, что позволило повысить прибыль.
Еще один пример: товарных позиций позволил магазину H&M сократить ассортимент в отдельных магазинах на 40%, сохранив при этом уровень продаж. Этого удалось достичь, исключив плохо продающиеся позиции, причем в расчетах учитывалась сезонность.
Выбор инструмента
Отраслевым стандартом вычислений такого рода является Hadoop. Почему? Потому что Hadoop — это отличный, хорошо документированный фреймворк (тот же Хабр выдает множество подробных статей на эту тему), который сопровождается целым набором утилит и библиотек. Вы можете подавать на вход огромные наборы как структурированных, так и неструктурированных данных, а система сама будет их распределять между вычислительными мощностями. Причем эти самые мощности можно в любой момент нарастить или отключить — та самая горизонтальная масштабируемость в действиии.
В 2017 году влиятельная консалтинговая компания Gartner , что Hadoop скоро изживет себя. Причина довольно банальна: аналитики считают, что компании станут массово мигрировать в облако, так как там они смогут платить по факту использования вычислительных мощностей. Второй важный фактор, якобы способный «похоронить» Hadoop — это скорость работы. Потому что варианты вроде Apache Spark или Google Cloud DataFlow работают быстрее, чем MapReduce, лежащий в основе Hadoop.
Hadoop покоится на нескольких китах, самыми заметными из которых являются технологии MapReduce (система распределения данных для расчетов между серверами) и файловая система HDFS. Последняя специально предназначена для хранения распределенной между узлами кластера информации: каждый блок фиксированной величины может быть размещен на нескольких узлах, а благодаря репликации обеспечивается устойчивость системы к отказам отдельных узлов. Вместо таблицы файлов используется специальный сервер, именуемый NameNode.
На иллюстрации ниже приведена схема работы MapReduce. На первом этапе данные разделяются по определенному признаку, на втором — распределяются по вычислительным мощностям, на третьем — происходит расчет.
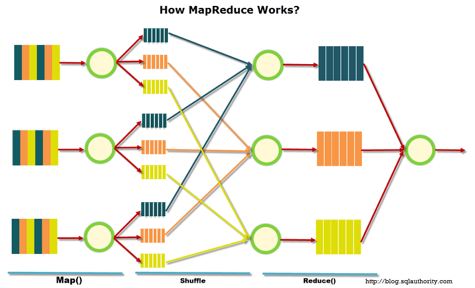
Изначально MapReduce создавалась Google для нужд своего поиска. Затем MapReduce ушла в свободный код, и проектом занялся Apache. Ну а Google постепенно мигрировал на другие решения. Интересный нюанс: в настоящий момент у Google есть проект, называемый Google Cloud Dataflow, позиционируемый как следующий шаг после Hadoop, как быстрая его замена.
При ближайшем рассмотрении видно, что Google Cloud Dataflow базируется на разновидности Apache Beam, при этом в Apache Beam входит хорошо документированный фреймворк Apache Spark, что позволяет говорить о практически одинаковой скорости выполнения решений. Ну а Apache Spark отлично работает на файловой системе HDFS, что позволяет разворачивать его на серверах Hadoop.
Добавим сюда объем документации и готовых решений по Hadoop и Spark против Google Cloud Dataflow, и выбор инструмента становится очевидным. Более того, инженеры могут сами решать, какой код — под Hadoop или Spark — им выполнять, ориентируясь на задачу, опыт и квалификацию.
Облако или локальный сервер
Тенденция к всеобщему переходу в облако породила даже такой интересный термин как Hadoop-as-a-service. В таком сценарии очень важным стало администрирование подключаемых серверов. Потому что, увы, несмотря на свою популярность, чистый Hadoop является довольно сложным для настройки инструментом, так как очень многое приходится делать руками. К примеру, по отдельности конфигурировать серверы, следить за их показателями, аккуратно настраивать множество параметров. В общем, работа на любителя и есть большой шанс где-то напортачить или что-то проворонить.
Поэтому большую популярность получили различные дистрибутивы, которые изначально комплектуются удобными средствами развертывания и администрирования. Один из наиболее популярных дистрибутивов, которые поддерживают Spark и все упрощают, — это Cloudera. У него есть и платная, и бесплатная версии — и в последней доступна вся основная функциональность, причем без ограничения числа нод.

Во время настройки Cloudera Manager будет подключаться по SSH к вашим серверам. Интересный момент: при установке лучше указать, чтобы она велась так называемыми парселами: специальными пакетами, в каждом из которых содержатся все нужные компоненты, настроенные на работу друг с другом. По сути это такая улучшенная версия пакетного менеджера.
После инсталляции мы получаем консоль управления кластером, на которой можно увидеть телеметрию по кластерам, установленные сервисы, плюс вы сможете добавлять/удалять ресурсы и редактировать конфигурацию кластера.
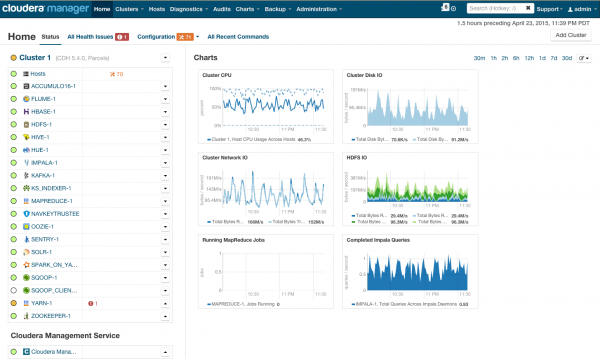
В результате перед вами появляется рубка той ракеты, которая унесет вас в светлое будущее BigData. Но прежде чем сказать «поехали», давайте перенесемся под капот.
Требования к железу
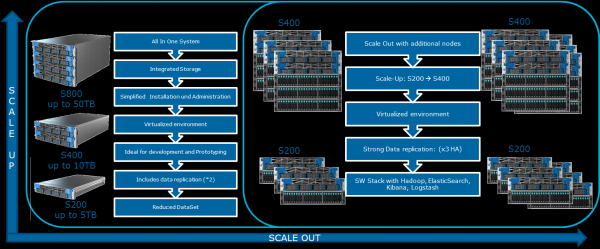
На своем сайте Cloudera упоминает разные возможные конфигурации. Общие принципы, по которым они строятся, приведены на иллюстрации:
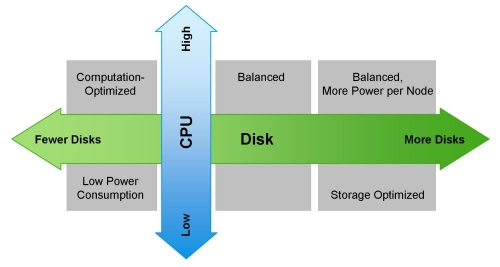
Смазать эту оптимистичную картину может MapReduce. Если еще раз посмотреть на схему из предыдущего раздела, становится очевидно, что почти во всех случаях задание MapReduce может столкнуться с «бутылочным горлышком» при чтении данных с диска или из сети. Это также отмечается в блоге Сloudera. В результате для любых быстрых вычислений, в том числе и через Spark, который часто используется для расчетов в реальном времени, очень важна скорость ввода/вывода. Поэтому при использовании Hadoop очень важно, чтобы в кластер попадали сбалансированные и быстрые машины, что, мягко говоря, не всегда обеспечивается в облачной инфраструктуре.
Сбалансированность в распределении нагрузок достигается за счет использования виртуализации Openstack на серверах с мощными многоядерными ЦПУ. Дата-нодам выделены свои процессорные ресурсы и определенные диски. В нашем решении Atos Codex Data Lake Engine достигается широкая виртуализация, отчего мы выигрываем как по производительности (минимизируется влияние сетевой инфраструктуры), так и по TCO (исключаются лишние физические сервера).
В случае использования серверов BullSequana S200 мы получаем весьма равномерную загрузку, лишенную части узких мест. В минимальную конфигурацию включается 3 сервера BullSequana S200, каждый с двумя JBOD, плюс опционально подключаются дополнительные S200, содержащие по четыре дата-ноды. Вот пример нагрузки в тесте TeraGen:
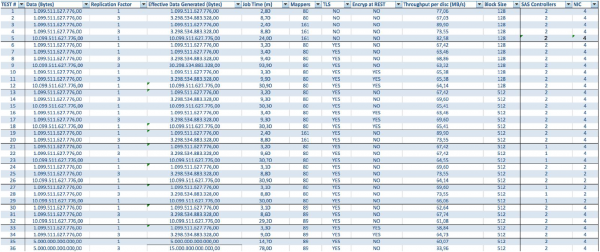
Тесты с различными объемами данных и значениями репликации показывают одинаковые результаты с точки зрения распределения нагрузки между узлами кластера. Ниже приведен график распределения доступа к диску по тестам производительности.
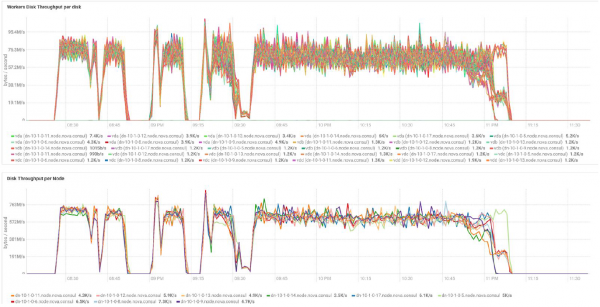
Расчеты выполнены на базе минимальной конфигурации из 3 серверов BullSequana S200. Она включает в себя 9 узлов данных и 3 главных узла, а также зарезервированные виртуальные машины на случай развертывания защиты на базе OpenStack Virtualization. Результат теста TeraSort: размер блока 512 МБ коэффициента реплицирования равном трем с шифрованием составляет 23,1 мин.
Как можно расширить систему? Для Data Lake Engine доступны различные виды расширений:
- Узлы передачи данных: для каждых 40 ТБ полезного пространства
- Аналитические узлы с возможностью установки графического процессора
- Другие варианты в зависимости от потребностей бизнеса (например, если нужна Kafka и тому подобное)
В состав комплекса Atos Codex Data Lake Engine входят как сами сервера, так и предварительно установленное программное обеспечение, включающее комплект Cloudera с лицензией; сам Hadoop, OpenStack с виртуальными машинами на основе ядра RedHat Enterprise Linux, системы репликации данных и бэкапа (в том числе с помощью ноды резервного копирования и Cloudera BDR — Backup and Disaster Recovery). Atos Codex Data Lake Engine стал первым решением с применением виртуализации, которое было сертифицировано .
Если вам интересны подробности, мы будем рады ответить на наши вопросы в комментариях.
Источник: habr.com
