

Определение DevOps очень сложное, поэтому приходится каждый раз запускать дискуссию об этом заново. Только на Хабре тысяча публикаций на эту тему. Но если вы это читаете, то наверняка знаете, что такое DevOps. Потому что я — нет. Привет, меня зовут Александр Титов (@), и мы мы просто поговорим о DevOps и я поделюсь своим опытом.

Долго думал, как сделать мой рассказ полезным, поэтому здесь будет много вопросов — тех, которые я сам себе задаю, и тех, которые я задаю клиентам нашей компании. Отвечая на эти вопросы, понимание становится лучше. Я расскажу зачем нужен DevOps с моей точки зрения, что это такое, опять же, с моей позиции, и как понять, что вы движетесь к DevOps снова с моей точки зрения. Последний пункт будет через вопросы. Отвечая на них самому себе, вы сможете понять, движется ли ваша компания к DevOps или в чем-то есть проблемы.

Одно время я гулял по волнам слияний и поглощений. Сначала я поработал в маленьком стартапе Qik, потом его купила чуть большая компания Skype, которую потом купила еще чуть большая компания Microsoft. В этот момент мне стало доступно видение, как трансформируется представление о DevOps в разных по величине компаниях. После этого мне стало интересно уже с точки зрения рынка смотреть на DevOps, и мы с коллегами организовали компанию Экспресс 42. Уже 6 лет мы движемся на ней по волнам рынка.
Кроме всего прочего я один из организаторов сообщества DevOps Moscow и организатор DevOps -Days 2017, но 2018 я не организовывал. Экспресс 42 работает со многими компаниями. Мы проращиваем там DevOps, смотрим, как это происходит, делаем выводы, анализируем, рассказываем свои выводы всем, обучаем людей DevOps-практикам. В общем, всячески растим в этом смысле опыт и экспертизу.
Зачем DevOps
Первый вопрос, который преследует всех и всегда — зачем? Многие считают, что DevOps — это просто автоматизация или похожая штука, которая уже была в каждой компании.
— У нас был Continuous Integration — это значит, уже был DevOps, и зачем вся эта ботва нужна? Там за границей развлекаются, а нам работать мешают!
За 9 лет развития сообщества и методологии уже стало понятно, что это все-таки не маркетинговые блестки, но все равно не до конца понятно зачем он нужен. Как у любого инструмента и процесса, у DevOps есть конкретные цели, которые он в итоге решает.
Все это связано с тем, что мир меняется. Он уходит от подхода enterprise, когда компании движутся сразу к мечте, как пел наш питерский классик, из точки А в точку В по определенной стратегии, с построенной для этого определенной структурой.
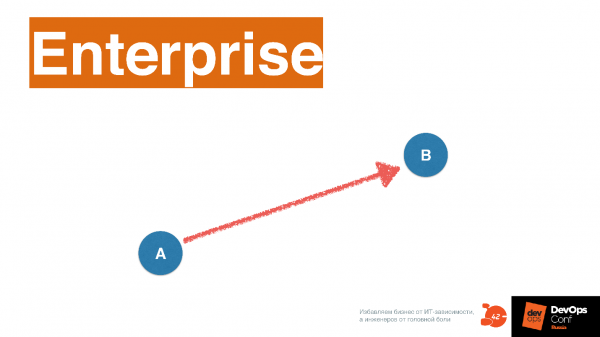
В принципе в IT все и должно быть построено под этот подход. Здесь IT используется исключительно для автоматизации процессов.
Автоматизация не часто меняется, потому что когда компания катится по наезженной колее — что там менять? Работает — не трогай. Сейчас в мире подходы меняются, и тот, что называется словом Agile, говорит о том, что конечной точки В сразу не видно.
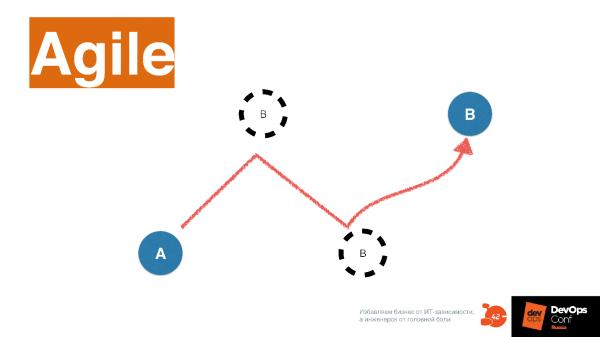
Когда компания идет по рынку, работает с клиентом — она постоянно исследует рынок и меняет конечную точку В. Причем чем чаще компания меняет свое направление, тем больше она в итоге успешна, потому что выбирает больше рыночных ниш.
Стратегию демонстрирует интересная компания, про которую я узнал недавно. One Box Shave — сервис по доставке бритв и бритвенных принадлежностей по подписке в коробке. Они умеют кастомизировать свою «коробочку» под разных клиентов. Этим занимается определенный софт, который потом отправляет заказ на корейскую фабрику, выпускающую товар.
Этот продукт купила компания Unilever за 1 млрд. долларов. Сейчас он конкурирует с Gillette и отъел у него значительную долю потребителей на американском рынке. One Box Shave говорят:
— 4 лезвия? Вы серьезно? Зачем вам это надо — это никак не улучшает качество бритья. Специально подобранный крем, отдушка и качественная бритва с двумя лезвиями решают гораздо больше вопросов, чем эти дурацкие 4 лезвия Gillette! Так скоро до 10 дойдем?
Так мир меняется. Unilever заявляют о том, что у них есть крутая IT-система, которая позволяет это делать. В итоге это выглядит как концепция Time-to-market, о которой уже кто только не говорил.
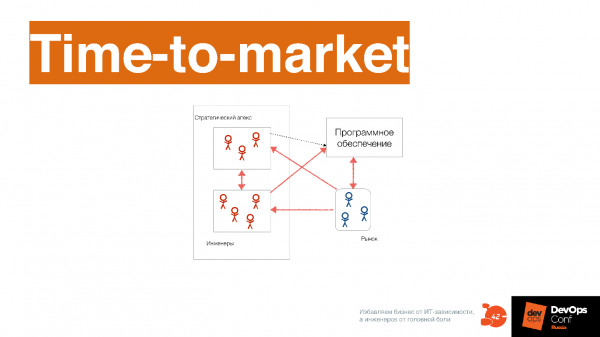
Смысл Time-to-market не в том, как часто мы деплоимся. Часто можно деплоить, но при этом релизные циклы будут длинными. Если трехмесячные релизные циклы накладывать друг на друга, сдвигая на недельку, получается, что компания как будто бы деплоится раз в неделю. А от идеи до конечной реализации проходит 3 месяца.
Time-to-market — это про минимизацию времени от идеи до конечной реализации.
В этом случае с рынком взаимодействует ПО. Так у One Box Shave с клиентом взаимодействует сайт. У них нет продавцов — просто сайт, где посетитель кликает и оставляет пожелания. Соответственно, на сайте надо постоянно размещать что-то новое, обновлять его в соответствии с пожеланиями. Например, в Южной Корее бреются не так, как в России, и им нравится в отдушке не запах сосны, а, например, морковки ванили.
Поскольку требуется быстро менять наполнение сайта, разработка ПО сильно меняется. Через ПО мы должны узнавать, что хочет клиент. Раньше мы это узнавали какими-то обходными путями, например, через бизнес-менеджмент. Потом проектировали, закладывали требования в IT-систему, и все было круто. Сейчас по-другому — ПО проектируется всеми, кто включен в процесс, в том числе и инженерами, потому что они узнают через технические характеристики, как работает рынок, и тоже делятся с бизнесом своими инсайтами.
Например, в компании Qik мы внезапно узнали, что людям очень нравится загружать контакт-листы на сервер, и они положили нам приложение. Изначально мы об этом не задумывались. В классической компании все бы решили, что это бага, так как в спеке не написано, что это должно классно работать и вообще было реализовано на коленке, выключили бы фичу и сказали: «Это никому не нужно, самое главное, что основная функциональность работает». А технологическая компания в этом видит возможность и начинает менять софт в согласии с этим.

В 1968 году прозорливый парень Мелвин Конвей сформулировал следующую идею.
Организация, которая создает систему, ограничена дизайном, который копирует структуру коммуникации в этой организации.
Если подробнее, — чтобы производить системы другого типа, надо еще вдобавок иметь коммуникационную структуру внутри компании другого типа. Если у вас коммуникационная структура верхне иерархическая, то это не позволит вам делать системы, которые могут обеспечивать очень высокий показатель Time-to-market.
Почитать можно . Он важен для понимания культуры или философии DevOps, так как единственное, что базово меняется в DevOps — это именно структура коммуникации между командами.
С точки зрения процесса, до DevOps все стадии: аналитика, разработка, тестирование, эксплуатация, проходили линейно.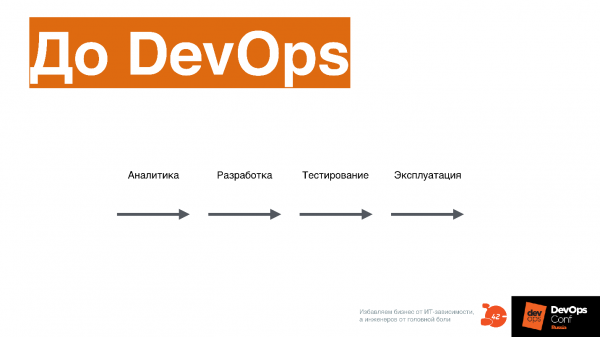
В случае DevOps все эти процессы идут одновременно.
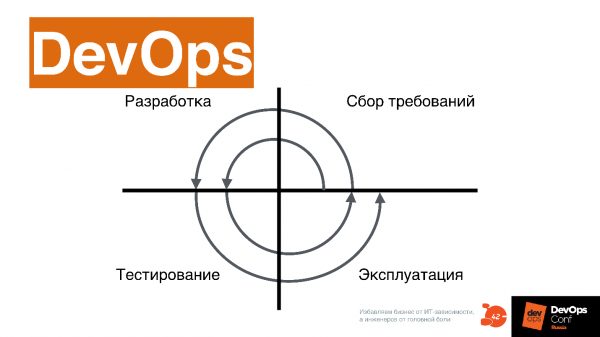
Time-to-market только так и может выполняться. Для людей, которые работали в старом процессе, это выглядит несколько космически, и вообще так себе.
Так зачем нужен DevOps?
Для разработки цифровых продуктов. Если у вас в компании нет цифрового продукта, DevOps не нужен — это очень важно.
DevOps преодолевает скоростные ограничения последовательной схемы производства ПО. В нем все процессы происходят одновременно.
Увеличивается сложность. Когда DevOps-евангелисты рассказывают, что с ним вам станет проще выпускать ПО — это бредятина.
С DevOps все будет только сложнее.
На конференции на стенде Авито можно было посмотреть, что такое задеплоить Docker-контейнер — нереальная задача. Сложность становится запредельной, надо жонглировать многими шариками одновременно.
DevOps меняет полностью процесс и организацию в компании — точнее, меняет не DevOps, а цифровой продукт. Чтобы прийти к DevOps, надо все-таки этот процесс полностью поменять.
Вопросы для специалиста
А что у вас? Вопросы, которые вы можете себе задать, работая в компании и развиваясь, как специалист.
Есть ли у вас стратегия по созданию цифрового продукта? Если есть — уже хорошо. Это значит, что ваша компания движется в сторону DevOps.
Ваша компания уже создает цифровой продукт? Это значит, что вы можете подняться еще на ступень выше, заниматься делами интереснее — с точки зрения DevOps опять-таки. Я только с этой точки зрения говорю.
Ваша компания один из лидеров рынка в нише с цифровым продуктом? Spotify, Яндекс, Uber — компании, которые находятся на пике технологического прогресса сейчас.
Задайте себе эти вопросы, и если все ответы отрицательные, то, возможно, вам и не стоит заниматься DevOps в этой компании. Если же вам тема DevOps реально интересна, может быть,… вам стоит перейти в другую компанию? Если ваша компания хочет пойти в DevOps, но на все вопросы вы ответили «Нет», то она напоминает этого прекрасного носорожика, который никогда не изменится.

Организация
Как я уже сказал, по закону Конвея в компании меняется организация. Начну с того, что мешает DevOps проникать внутрь компании именно с точки зрения организации.
Проблема «колодцев»
Английское слово «Silo» переведено здесь на русский как «колодец». Смысл этой проблемы в том, что между командами нет обмена информацией. Каждая команда копает свою экспертизу вглубь, при этом не строя общую карту, в которой можно ориентироваться.
Чем-то это напоминает человека, который только приехал в Москву и еще не умеет ориентироваться по карте метро. Москвичи обычно прекрасно знают свой район, а по всей Москве ориентируются по карте метро. Когда ты приезжаешь в Москву в первый раз, нет этого навыка, и ты просто дезориентирован.
DevOps предлагает пройти этот момент дезориентации и всем подразделениям вместе построить общую карту взаимодействия.
Этому мешают два фактора.
Следствие корпоративной системы управления. Она построена отдельными иерархическими «колодцами». Например, есть определенные KPI в компаниях, которые эту систему поддерживают. С другой стороны, мешают мозги человека, которому сложно выйти за пределы своей экспертизы и ориентироваться во всей системе. Это просто некомфортно. Представьте себе, что вы попали в аэропорт Бангкока — там быстро не сориентируешься. В DevOps тоже сложно ориентироваться, и поэтому люди говорят, что надо найти проводника найти, чтобы туда попасть.
Но самое главное, что проблема «колодцев» для инженера, который проникся духом DevOps, начитался Фаулера и кучу других книжек, выражается в том, что «колодцы» не позволяют делать «очевидные» вещи. Мы часто собираемся после DevOps Moscow, разговариваем друг с другом, и люди жалуются:
— Мы хотели просто CI запустить, а получилось, что менеджменту это не надо.
Это происходит именно из-за того, что CI и Continuous Delivery process находятся на границе многих экспертиз. Просто не преодолев проблему «колодцев» на организационном уровне, не получится продвинуться дальше, что бы вы не делали и как бы это грустно не было.
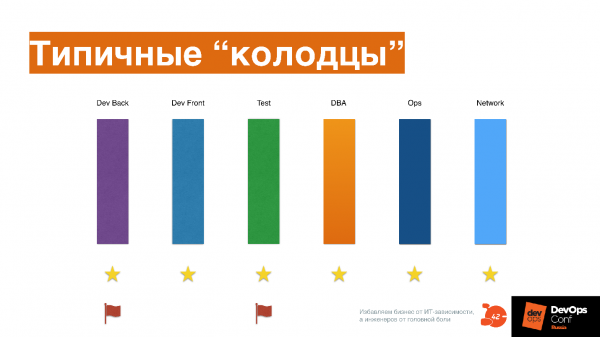
Каждый участник процесса в компании: разработчики бэкенда и фронтенда, тестирование, DBA, эксплуатация, сеть, копает в свою сторону, а общей карты не имеет никто, кроме управленца, который как-то их обозревает и управляет методом «разделяй и властвуй».
Люди борются за какие-то звездочки или флажки, каждый копает свою экспертизу.
В итоге, когда появляется задача все это соединить вместе и построить общий пайплайн, и за звездочки и флажки уже бороться не надо, появляется вопрос — а что делать-то вообще? Надо как-то договариваться, а как это делать, нас в школе никто не учил. Мы еще со школы научены: восьмой класс — ого! — по сравнению с седьмым классом! Здесь то же самое.
В вашей компании так же?
Чтобы это проверить, можно задать себе следующие вопросы.
Пользуются ли команды общими инструментами, вносят ли вклад в изменения этих общих инструментов?
Насколько часто команды переформируются — одни специалисты из одной команды переходят в другую команду? Именно в DevOps-среде это становится нормальным, потому что иногда человек просто не может понять, чем занимается другая зона экспертизы. Он переходит в другой отдел, две недельки там работает, чтобы создать для себя карту ориентации и взаимодействия с этим отделом.
Можно ли создать комитет по изменению и что-то изменить? Или для этого нужна сильная рука самого высшего руководства и распоряжение? Недавно я написал в Facebook, как один малоизвестный банк через распоряжения внедряет инструменты: написали распоряжение, год внедряем, смотрим, что происходит. Это, конечно, долго и печально.
Насколько важно для менеджеров получать личные достижения без учета достижений компании?
Если вы для себя ответите на эти вопросы, станет понятнее, есть ли у вас такая проблема в компании.
Инфраструктура как код
После того, как эта проблема пройдена, первая важная практика, без которой сложно продвинуться в DevOps дальше — это инфраструктура как код.
Чаще всего инфраструктуру как код воспринимают так:
— Давайте все автоматизируем на bash, обмажемся скриптами, чтобы у админок было меньше ручной работы!
Но это не так.
Инфраструктура как код подразумевает, что IT-систему, с которой работаете, вы описываете в виде кода, чтобы постоянно понимать ее состояние.
Совместно с другими командами вы создаете карту в виде кода, которая всем понятна, по которой можно ориентироваться, навигировать. Без разницы, на чем это сделано — Chef, Ansible, Salt, или используются YAML-файлы в Kubernetes — нет разницы.
На конференции коллега из 2ГИС рассказывал, как они сделали свою внутреннюю штуку для Kubernetes, которая описывает устройство отдельных систем. Чтобы описать 500 систем, им потребовался отдельный инструмент, который это описание генерирует. Когда есть это описание, каждый может сверяться друг с другом, мониторить изменения, как его поменять и улучшить, чего не хватает.
Согласитесь, отдельные bash-скрипты обычно не дают этого понимания. В одной из компаний, где я работал, было даже название «write only»-скрипт — когда скрипт написан, а прочитать его уже невозможно. Думаю, что это вам тоже знакомо.
Инфраструктура как код — это код, который описывает актуальное состояние инфраструктуры. Над этим кодом совместно работает множество продуктовых, инфраструктурных и сервисных команд, и, самое главное, все они должны понимать, как этот код вообще работает.
Код сопровождается согласно лучшим практикам работы с кодом: совместная разработка, код-ревью, XP-programming, тестирование, пулреквесты, CI для инфраструктур кода — это все годно и можно использовать.
Код становится общим языком для всех инженеров.
Изменение инфраструктуры в коде не занимает много времени. Да, в инфраструктурном коде тоже может быть технический долг. Обычно команды сталкиваются с ним года через полтора после того, как начали внедрять «инфраструктуру как код» в виде кучи скриптов или даже Ansible, который они пишут как спагетти-код, и еще bash-скрипты туда подкидывают в топочку!
Важно: если вы еще не попробовали эту дрянь, запомните, что Ansible — не bash! Внимательно читайте документацию, изучайте, что вообще про это пишут.
Инфраструктура как код — это разделение инфраструктурного кода на отдельные слои.
Мы у себя в компании выделяем 3 базовых слоя, которые очень понятны и просты, но их может быть больше. Вы можете посмотреть на ваш инфраструктурный код и сказать, есть ли у вас это условие или нет. Если никакие слои не выделяются, то надо выделить время и порефакторить немножко.
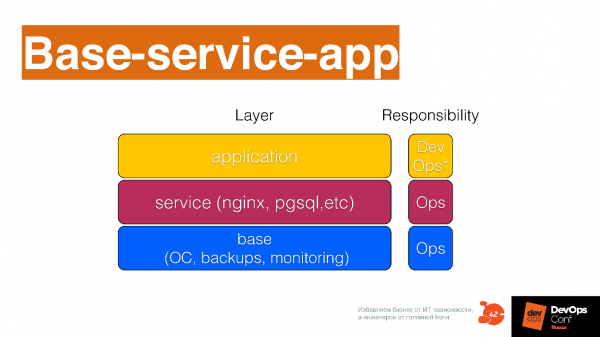
Базовый слой — это как настраивается ОС, бэкапы и другие низкоуровневые штуки, например, как разворачивается Kubernetes на базовом уровне.
Уровень сервисов — это те сервисы, которые вы даете разработчику: логирование как сервис, мониторинг как сервис, база данных как сервис, балансировщик как сервис, очередь как сервис, Continuous Delivery как сервис — куча сервисов, которые отдельные команды могут предоставлять разработке. Это все необходимо описывать отдельными модулями в вашей системе управления конфигурацией.
Слой, где делаются приложения и описывается, как они будут разворачиваться поверх двух предыдущих слоев.
Контрольные вопросы
Есть ли у вас в компании общий инфраструктурный репозиторий? Контролируете ли вы технический долг в инфраструктуре? Используете ли вы практики разработки в инфраструктурном репозитории? Нарезана ли ваша инфраструктура на слои? Можно свериться со схемой Base-service-APP. Насколько сложно внести изменение?
Если вы сталкивались с тем, что внесение изменений занимало полтора дня, это значит, что у вас появился технический долг и с ним надо поработать. Вы как раз наткнулись на грабли технического долга в инфраструктурном коде. Я помню много таких историй, когда чтобы поменять какой-нибудь CCTL, надо переписать половину инфраструктурного кода, потому что творчество и желание все автоматизировать привело к тому, что везде все закоркожено, все ручки убраны, и нужно рефакторить.
Непрерывная поставка
Подобьем дебит с кредитом. Сначала появляется описание инфраструктуры, которое может быть довольно базовым. Необязательно все описывать детально, но какое-то базовое описание требуется, чтобы вы могли с этим работать. Иначе непонятно, поверх чего дальше вообще делать непрерывную поставку. Все эти практики разворачиваются одновременно, когда вы приходите к DevOps, но начинать нужно с понимания того, что у вас есть, и как этим управлять. Это как раз практика инфраструктура как код.
После того, как стало понято, что у вас есть, как этим управлять, вы начинаете придумывать, как код разработчика максимально быстро отправить на продакшн. Я имею в виду вместе с разработчиком — помним про проблему «колодцев», то есть не отдельные люди это придумывают, а командой.
Когда мы с Ваней Евтуховичем увидели первую книжку Джеза Хамбла и группы авторов «Continuous Delivery», которая вышла в 2009 году, то долго думали, как перевести ее название на русский язык. Хотели перевести как «Постоянно доставлять», но, к сожалению, перевели как «Непрерывная поставка». Мне кажется, что в нашем названии есть что-то такое русское, с напором.
Постоянно доставлять — это значит
Код, который лежит в продуктовом репозитории, всегда может быть выкачен в продакшн. Он может быть и не выкачан, но всегда готов к этому. Соответственно, вы всегда пишите код с трудно объяснимым чувством некоторого беспокойства под копчиком. Оно часто появляется, когда выкатываешь инфраструктурный код. Это чувство некоторого беспокойства и должно присутствовать — оно вызывает мозговые процессы, которые позволяют писать код немного по-другому. Это должно быть зафиксировано в правилах внутри разработки.
Чтобы постоянно доставлять, нужен формат артефакта, который проходит по инфраструктурной платформе. Если вы кидаете по инфраструктурной платформе разного формата «отходы жизнедеятельности», то она у вас становится не унифицированной, ее сложно сопровождать, возникает проблема технического долга. Формат артефакта необходимо выровнять — это тоже коллективная задачка: надо всем вместе собраться, пошуршать мозгами и придумать этот формат.
Артефакт непрерывно улучшается и меняется под продакшн-среду во время прохождения по пайплайну поставки. Когда артефакт двигается по пайплайну, он все время сталкивается с какими-то неудобными для него вещами, которые похожи на то, с чем сталкивается артефакт, который вы выкладываете в продакшн. Если в классической разработке этим занимается сисадмин, который делает выкатку, то в DevOps-процессе это происходит постоянно: тут его какими-то тестами покрутили, тут — в Kubernetes-кластер закинули, который более-менее похож на продакшн, тут внезапно запустили нагрузочное тестирование.
Это чем-то напоминает игру Пакман — артефакт проходит какую-то историю. При этом важно контролировать, реально ли код проходит историю и она как-то связана с вашим продакшн. Истории с продакшен можно затаскивать внутрь Continuous Delivery процесса: было так, когда что-то упало, теперь давайте этот сценарий просто запрограммируем внутрь системы. Каждый раз код будет проходить этот сценарий тоже, и вы не столкнетесь следующий раз с этой проблемой. Вы узнаете о ней сильно раньше, чем она выйдет к вашему клиенту.
Разные стратегии деплоев. Например, вы используете AB-тестирование либо канареечные деплойменты, чтобы по-разному «щупать» код на разных клиентах, получать информацию о том, как код работает, и сильно раньше, чем когда он выкатится на 100 млн пользователей.
«Постоянно доставлять» выглядит так.
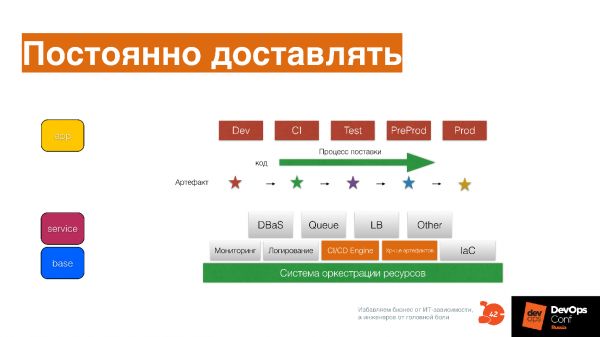
Процесс поставки Dev, CI, Test, PreProd, Prod — это не отдельное окружение, это стейджи или станции с несгораемыми суммами, по которым проходит ваш артефакт.
Если у вас есть инфраструктурный код, который описан как Base Service APP, то он помогает не забыть все сценарии, и записать их тоже в виде кода для этого артефакта, продвигать артефакт и менять его по ходу движения.
Вопросы для самопроверки
Время от описания фичи до выкатки в продакшен в 95 % случаев меньше недели? Повышается ли качество артефакта на каждом этапе пайплайна? Есть ли история, по которой он проходит? Используете ли вы различные стратегии деплоя?
Если все ответы да, то вы нереально круты! Напишите ответы в комментарии — я буду рад).
Обратная связь
Эта самая сложная практика из всех. На конференции DevOpsConf коллега из Infobip, рассказывая о ней, немного путался в словах, потому что это действительно очень сложная практика про то, что надо мониторить вообще все!
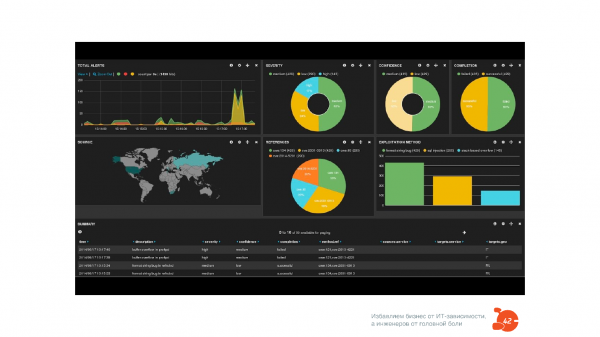
Например, давным-давно, когда я работал в Qik и мы поняли, что надо мониторить вообще все. Мы это сделали, и у нас в Zabbix появилось 150 000 items, которые мониторятся постоянно. Это было страшно, технический директор крутил пальцем у виска:
— Ребята, вы зачем сервак насилуете непонятно чем?
Но потом произошел случай, который показал, что это реально очень крутая стратегия.
Постоянно начал падать один из сервисов. Изначально он не падал, что интересно, туда код не дописывался, потому что это был базовый брокер, в котором практически не было бизнес-функциональности — он просто гонял сообщения между отдельными сервисами. Сервис не менялся 4 месяца, и вдруг стал падать с ошибкой «Segmentation fault».
Мы были в шоке, открыли наши графики в Zabbix, и выяснилось, что, оказывается, полторы недели назад сильно изменилось поведение запросов в API-сервисе, который использует этот брокер. Дальше мы посмотрели, что изменилась частота посылки определенного типа сообщений. После выяснили, что это android-клиенты. Мы спросили:
— Ребята, а что у вас случилось полторы недели назад?
В ответ услышали интересную историю о том, что они переделали UI. Вряд ли кто сразу скажет, что поменял HTTP-библиотеку. Для android-клиентов это как мыло сменить в ванной — они просто это не помнят. В итоге, после 40 минут разговора, мы выяснили, что они все-таки сменили HTTP-библиотеку, и у нее изменились дефолтные тайминги. Это привело к тому, что изменилось поведение трафика на API сервере, что и привело к ситуации, которая вызвала гонку внутри брокера, и он начал падать.
Без глубокого мониторинга это вскрыть вообще невозможно. Если же в организации есть еще проблема «колодцев», когда каждый перекидывает друг на друга, это может жить годами. Вы просто рестартуете сервер, потому что невозможно решить проблему. Когда вы мониторите, отслеживаете, трекаете все события, которые у вас есть, и используете мониторинг как тестирование — пишете код и сразу же указываете, как его промониторить, тоже в виде кода (у нас уже инфраструктура как код есть), все становится ясно как на ладони. Даже такие сложные проблемы легко отслеживаются.
Собирайте всю информацию о том, что происходит с артефактом на каждой стадии процесса поставки — не в продакшн.
Мониторинг грузите на CI, и там уже будут видны какие-то базовые вещи. Дальше вы их увидите и в Test, и в PredProd, и в нагрузочном тестировании. Собирайте информацию на всех стадиях, причем не только метрики, статистику, но и логи: как выкатилось приложение, аномалии — собирайте все.
В противном случае будет сложно разобраться. Я уже говорил, что DevOps — это бОльшая сложность. Чтобы справиться с этой сложностью, нужно иметь нормальную аналитику.
Вопросы для самоконтроля
Ваш мониторинг и логирование — это средство разработки для вас? Ваши разработчики, и вы в том числе, когда пишут код, думают о том, как его замониторить?
Узнаете ли вы о проблемах от клиентов? Понимаете ли вы клиента лучше из мониторинга и логирования? Понимаете ли вы систему лучше из мониторинга и логирования? Меняете ли вы систему просто потому, что увидели, что тренд в системе растет и понимаете, что еще 3 недели и все загнется?
Когда у вас есть эти три компонента, вы можете подумать о том, какая у вас в компании инфраструктурная платформа.
Инфраструктурная платформа
Смысл не в том, что это набор разрозненных инструментов, который есть в каждой компании.
Смысл инфраструктурной платформы в том, что все команды пользуются этими инструментами и развивают их совместно.
Понятно, что есть отдельные команды, которые несут ответственность за развитие отдельных кусков инфраструктурной платформы. Но при этом ответственность за развитие, работоспособность, продвижение инфраструктурной платформы несет каждый инженер. На внутреннем уровне это становится общим инструментом.
Все команды развивают инфраструктурную платформу, относятся бережно к ней как к собственному IDE. В своем IDE вы ставите разные плагины, чтобы все было красиво и быстро, настраиваете горячие клавиши. Когда вы открываете Sublime, Atom или Visual Studio Code, у вас там сыпятся ошибки кода и вы понимаете, что вообще невозможно работать, вам сразу становится грустно и вы бежите чинить свой IDE.
Точно также относитесь к вашей инфраструктурной платформе. Если вы понимаете, что с ней что-то не то, оставляйте заявку, если не можете починить сами. Если же там что-то простое — правьте самостоятельно, отправляйте pull request — ребята рассматривают, добавляют. Это несколько другой подход к инженерному инструментарию в голове разработчика.
Инфраструктурная платформа обеспечивает перенос артефакта от разработки клиенту с постоянным повышением качества. В ИП запрограммирован набор историй, которые случаются с кодом в продакшн. За годы разработки этих историй становится очень много, часть из них уникальны и относятся только к вам — их невозможно нагуглить.
В этот момент инфраструктурная платформа становится вашим конкурентным преимуществом, потому что в нее зашито то, чего нет в инструменте конкурента. Чем глубже ваша ИП, тем больше ваше конкурентное преимущество в смысле Time-to-market. Здесь появляется проблема vendor lock: вы можете взять себе чужую платформу, но используя чужой опыт, вы не будете понимать, насколько он релевантен к вам. Да, не всякая компания может построить платформу типа Амазона. Это сложная грань, где опыт компании релевантен ее положению на рынке, и спускать туда vendor lock нельзя. Об этом тоже важно подумать.
Схема
Это базовая схема инфраструктурной платформы, которая поможет вам наладить все практики и процессы в DevOps-компании.
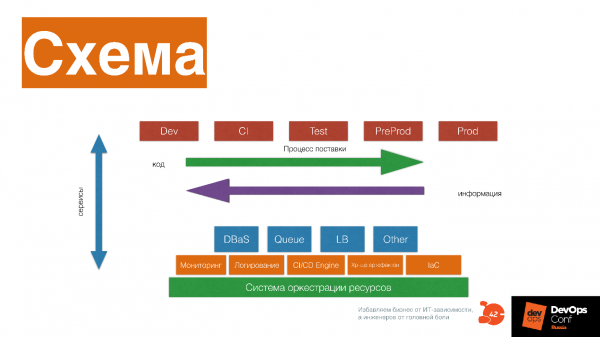
Рассмотрим, из чего она состоит.
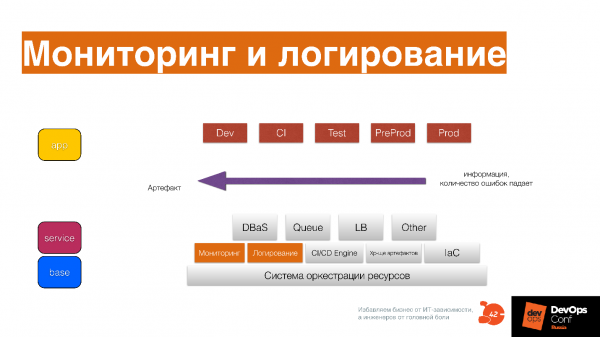
Система оркестрации ресурсов, которая предоставляет CPU, память, диск приложениям и другим сервисам. Поверх этого — сервисы низкого уровня: мониторинг, логирование, CI/CD Engine, хранилище артефактов, инфраструктура как код системы.
Сервисы более высокого уровня: база данных, как сервис, очереди как сервис, Load Balance как сервис, resizing картинок как сервис, Big Data фабрика как сервис. Поверх этого — пайплайн, который поставляет постоянно модифицированный код вашему клиенту.
Вы получаете информацию о том, как ваше ПО работает у клиента, меняете, опять поставляете этот код, получаете информацию — и так постоянно развиваете и инфраструктурную платформу, и ваше ПО.
На схеме delivery pipeline состоит из множества стейджей. Но это принципиальная схема, которая приведена для примера — не надо повторять ее один в один. Стейджы взаимодействуют с сервисами, как с сервисами — каждый кирпичик платформы несет свою историю: как выделяются ресурсы, как приложение запускается, работает с ресурсами, мониторится, меняется.
Важно понимать, что каждая часть платформы несет историю, и спрашивать себя — какую историю несет этот кирпичик, может быть, его стоит выбросить и заменить сторонним сервисом. Например, можно ли вместо кирпичика поставить Okmeter? Возможно, парни уже прокачали эту экспертизу гораздо больше, чем мы. Но может и нет — возможно, у нас есть уникальная экспертиза, нам надо поставить Prometheus и развивать это дальше.
Создание платформы
Это сложный коммуникационный процесс. Когда у вас есть базовые практики, вы запускаете общение между разными инженерами и специалистами, которые вырабатывают требования и стандарты, и постоянно их изменяют к разным инструментам и подходам. Здесь важна культура, которая есть в DevOps.
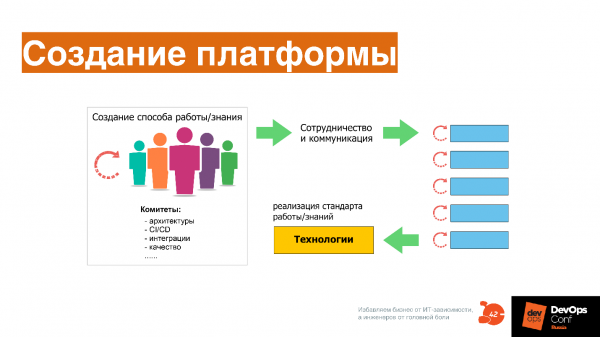
С культурой все очень просто — это сотрудничество и коммуникация, то есть желание работать в общем поле друг с другом, желание владеть одним инструментом вместе. Тут нет никакого rocket science — все очень просто, банально. Например, мы все живем в подъезде и поддерживаем его чистоту — такой уровень культуры.
А что у вас?
Снова вопросы, которые вы можете себе задать.
Выделена ли инфраструктурная платформа? Кто отвечает за ее развитие? Понимаете ли вы конкурентные преимущества своей инфраструктурной платформы?
Эти вопросы надо постоянно себе задавать. Если что-то можно вынести на сторонние сервисы — нужно выносить, если сторонний сервис начинает блокировать ваше движение, то надо строить систему внутри себя.
Итак, DevOps…
… это сложная система, в нем должны быть:
- Цифровой продукт.
- Бизнес модули, которые этот цифровой продукт развивают.
- Продуктовые команды, которые пишут код.
- Практики Continuous Delivery.
- Платформы как сервис.
- Инфраструктура как сервис.
- Инфраструктура как код.
- Отдельные практики поддержания надежности, зашитые внутри DevOps.
- Практика обратной связи, которая описывает все это.
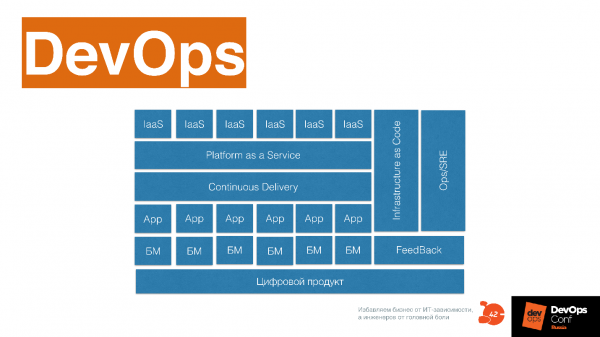
Можно использовать эту схему, подкрасив в ней то, что уже у вас в компании есть в каком-то виде: это развилось или еще надо развить.
Уже через пару недель пройдет . в составе РИТ++. Приходите на конференцию, где вас ждет много крутых докладов про непрерывную поставку, инфраструктуру как код и DevOps-трансформацию. , последний дедлайн цен 20 мая
Источник: habr.com
