

Приветствую, habr.
Если кто-то эксплуатирует систему и столкнулся с проблемой производительности хранилища (IO, потребляемое дисковое пространство), то шанс того, что был брошен взгляд на ClickHouse в качестве замены, должен стремиться к единице. Данное утверждение подразумевает то, что в качестве принимающего метрики демона уже используется сторонняя реализация, например или .
ClickHouse хорошо решает описанные проблемы. К примеру, после переливки 2TiB данных из whisper, они уместились в 300GiB. Подробно на сравнении я останавливаться не буду, статей на эту тему хватает. К тому же, до недавнего времени с нашим ClickHouse хранилищем было не всё идеально.
Проблемы с потребляемым местом
На первый взгляд, всё должно работать хорошо. Следуя , создаём конфиг для схемы хранения метрик (далее retention), затем создаём таблицу согласно рекомендации выбранного бекенда для graphite-web: + или , в зависимости от того, какой стек используется. И… включается бомба замедленного действия.
Для того, чтобы понять, какая, надо знать, как работают вставки и дальнейший жизненный путь данных в таблицах движков семейства *MergeTree ClickHouse (диаграммы взяты из Алексея Зателепина):
- Вставляется
блокданных. В нашем случае это прилетели метрики.

- Каждый такой блок перед записью на диск сортируется согласно ключу
ORDER BY, указанному при создании таблицы. - После сортировки,
кусок(part) данных записывается на диск.
- Сервер следит в фоне, чтобы таких кусков было не много, и запускает фоновые
слияния(merge, далее мержи).
- Сервер перестаёт запускать мержи самостоятельно, как только данные перестают активно поступать в
партицию(partition), но можно запустить процесс вручную командойOPTIMIZE. - Если в партиции остался только один кусок, то запустить мерж обычной командой не получится, необходимо использовать
OPTIMIZE ... FINAL
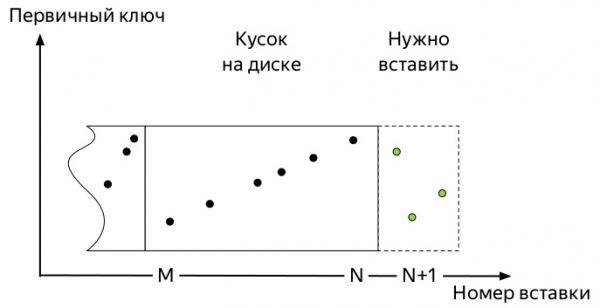
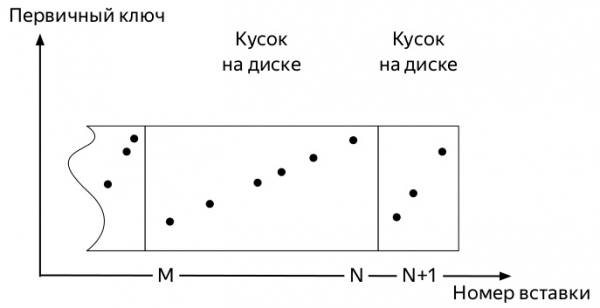
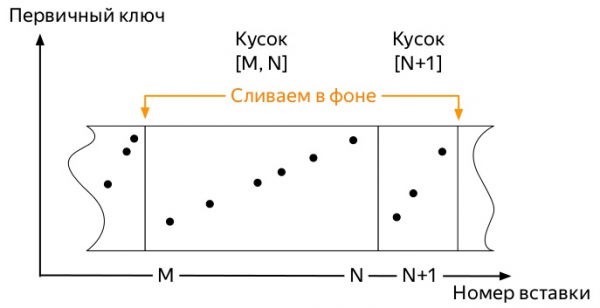
Итак, поступают первые метрики. И они занимают некое пространство. Последующие события могут несколько варьироваться в зависимости от многих факторов:
- Ключ партиционирования может быть как очень маленьким (день), так и очень большим (несколько месяцев).
- Конфиг retention может умещать несколько значительных порогов агрегации данных внутри активной партиции (куда идёт запись метрик), а может и нет.
- Если данных очень много, то самые ранние куски, которые из-за фоновых мержей могут уже быть огромными (при выборе неоптимального ключа партиционирования), не будут мержиться сами со свежими маленькими кусками.
И заканчивается всегда всё одинаково. Место, занимаемое метриками в ClickHouse только растёт, если:
- не применять
OPTIMIZE ... FINALвручную или - не вставлять данные во все партиции на постоянной основе, чтобы рано или поздно запустить фоновый мерж
Второй способ кажется наиболее простым в реализации и, значит, он неправильный и был опробован в первую очередь.
Я написал достаточно простой скрипт на python, который отправлял фиктивные метрики для каждого дня за прошлые 4 года и запускался каждый час кроном.
Так как вся работа ClickHouse DBMS построена на том, что эта система рано или поздно сделает всю фоновую работу, но неизвестно когда, то дождаться момента, когда старые огромные куски соизволят начать мерж с новыми маленькими, мне не удалось. Стало ясно, что надо искать способ автоматизировать принудительные оптимизации.

Информация в системных таблицах ClickHouse
Взглянем на структуру таблицы . Это исчерпывающая информация о каждом куске всех таблиц на сервере ClickHouse. Содержит, в том числе, следующие столбцы:
- имя БД (
database); - имя таблицы (
table); - имя и ИД партиции (
partition&partition_id); - когда кусок был создан (
modification_time); - минимальная и максимальная дата в куске (партиционирование идёт по дням) (
min_date&max_date);
Также есть таблица , со следующими интересными полями:
- имя БД (
Tables.database); - имя таблицы (
Tables.table); - возраст метрики, когда должна быть применена следующая агрегация (
age);
Итак:
- У нас имеется таблица кусков и таблица правил агрегации.
- Объединяем их пересечение и получаем все таблицы *GraphiteMergeTree.
- Ищем все партиции, в которых:
- больше одного куска
- или настал момент применить следующее правило агрегации, и
modification_timeстарше этого момента.
Реализация
Данный запрос
SELECT
concat(p.database, '.', p.table) AS table,
p.partition_id AS partition_id,
p.partition AS partition,
-- Самое "старое" правило, которое может быть применено для
-- партиции, но не в будущем, см (*)
max(g.age) AS age,
-- Количество кусков в партиции
countDistinct(p.name) AS parts,
-- За самую старшую метрику в партиции принимается 00:00:00 следующего дня
toDateTime(max(p.max_date + 1)) AS max_time,
-- Когда партиция должна быть оптимизированна
max_time + age AS rollup_time,
-- Когда самый старый кусок в партиции был обновлён
min(p.modification_time) AS modified_at
FROM system.parts AS p
INNER JOIN
(
-- Все правила для всех таблиц *GraphiteMergeTree
SELECT
Tables.database AS database,
Tables.table AS table,
age
FROM system.graphite_retentions
ARRAY JOIN Tables
GROUP BY
database,
table,
age
) AS g ON
(p.table = g.table)
AND (p.database = g.database)
WHERE
-- Только активные куски
p.active
-- (*) И только строки, где правила аггрегации уже должны быть применены
AND ((toDateTime(p.max_date + 1) + g.age) < now())
GROUP BY
table,
partition
HAVING
-- Только партиции, которые младше момента оптимизации
(modified_at < rollup_time)
-- Или с несколькими кусками
OR (parts > 1)
ORDER BY
table ASC,
partition ASC,
age ASCвозвращает каждую из партиций таблиц *GraphiteMergeTree, мерж которых должен привести к освобождению дискового пространства. Осталось только дело за малым: пройтись по ним всем с запросом OPTIMIZE ... FINAL. В финальной реализации также учтён тот момент, что партиции с активной записью трогать нет необходимости.
Именно это и делает проект . Бывшие коллеги из Яндекс.Маркет опробовали его в проде, результат работы можно видеть ниже.
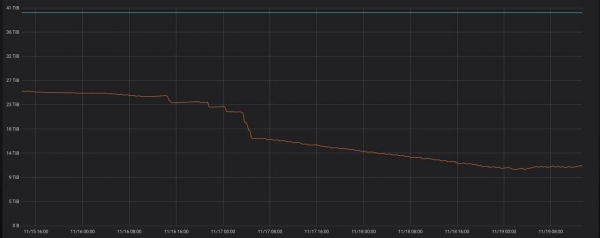
Если запустить программу на сервере с ClickHouse, то она просто начнёт работать в режиме демона. Раз в час будет выполняться запрос, проверяя, не появились ли новые партиции старше трёх суток, которые можно оптимизировать.
В ближайших планах — предоставить, по крайней мере, deb пакеты, а по возможности — ещё и rpm.
Вместо заключения
За прошедшие 9 с лишним месяцев я внутри своей компании провёл много времени, варясь на стыке ClickHouse и graphite-web. Это был хороший опыт, результатом которого стал возможен скорый переход с whisper на ClickHouse в качестве хранилища метрик. Надеюсь, что эта статья — что-то вроде начала цикла о том, какие улучшения были внесены нами в различные части этого стека, и что будет сделано в будущем.
На разработку запроса было потрачено несколько литров пива и админо-дней совместно с , за что я хочу выразить ему свою благодарность. А также за рецензирование этой статьи.
Источник: habr.com
