

Всем привет!
Наша компания занимается разработкой программного обеспечения и последующей технической поддержкой. В рамках технической поддержки требуется не просто исправлять ошибки, а следить за работоспособностью наших приложений.
Например, если «упал» один из сервисов, то нужно автоматически зафиксировать данную проблему и приступить к её решению, а не ждать обращений в техническую поддержку недовольных пользователей.
У нас небольшая компания, нет ресурсов изучать и содержать какие-то сложные решения для мониторинга приложений, нужно было найти простое и эффективное решение.

Стратегия мониторинга
Выполнить проверку работоспособности приложения не просто, эта задача нетривиальная, можно даже сказать творческая. Особенно сложно выполнить проверку сложной многозвенной системы.
Как можно съесть слона? Только по частям! Используем данный подход для мониторинга приложений.
Суть нашей стратегии мониторинга:
Разбейте приложение на компоненты.
Для каждого компонента придумайте контрольные проверки.
Компонент считается исправным, если все его контрольные проверки выполняются без ошибок. Приложение считается исправным, если исправны все его компоненты.
Таким образом любую систему можно представить в виде дерева компонентов. Сложные компоненты разбиваются на более простые. Простые компоненты имеют проверки.
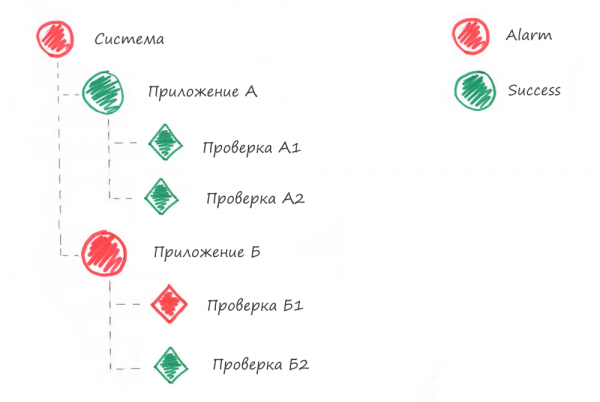
Контрольные проверки не должны выполнять функциональное тестирование, это не юнит-тесты. Контрольные проверки должны проверять как чувствует себя компонент в текущий момент времени, есть ли все необходимые для его функционирования ресурсы, есть ли какие проблемы.
Чудес не бывает, большинство проверок нужно будет разработать самостоятельно. Но не стоит пугаться, потому что в большинстве случаев одна проверка занимает 5-10 строк кода, но зато вы сможете реализовать любую логику и вам будет четко понятно, как отрабатывает проверка.
Система мониторинга
Допустим мы разбили приложение на компоненты, придумали и реализовали для каждого компонента проверки, но что делать с результатами этих проверок? Как мы узнаем о том, что какая-то проверка выполнилась с ошибкой?
Нам потребуется система мониторинга. Она будет выполнять следующие задачи:
- Получать результаты проверок и по ним определять статус компонентов.
Визуально это выглядит как подсвечивание дерева компонентов. Исправные компоненты становятся зелеными, проблемные – красными. - Выполнять общие проверки «из коробки».
Некоторые проверки система мониторинга умеет выполнять сама. Зачем изобретать велосипед, будем их использовать. Например, можно проверить что страница сайта открывает или сервер пингуется. - Отправка уведомлений о проблемах заинтересованным лицам.
- Визуализация данных мониторинга, предоставление отчетов, графиков и статистики.
Краткое описание системы АСМО
Лучше всего объяснять на примере. Давайте посмотрим, как организован мониторинг работоспособности системы АСМО.
АСМО – это автоматизированная система метеорологического обеспечения. Система помогает специалистам дорожных служб понять, где и когда необходимо обрабатывать дорогу противогололедными материалами. Система собирает данные с пунктов дорожного контроля. Пункт дорожного контроля – это место на дороге, где установлено оборудование: метеостанция, видеокамера и другое. Для прогнозирования опасных ситуаций система получает прогнозы погоды из внешних источников.
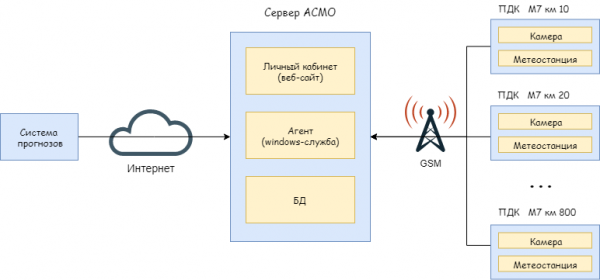
Итак, состав системы достаточно типовой: веб-сайт, агент, оборудование. Приступим к мониторингу.
Разбиваем систему на компоненты
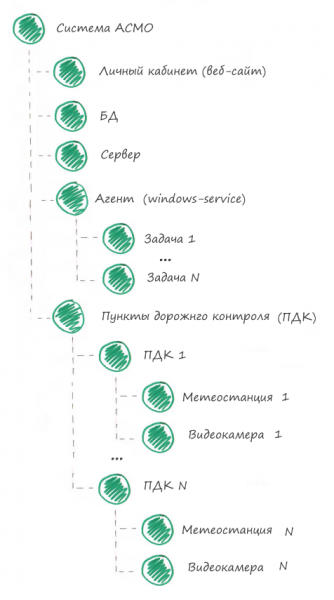
В системе АСМО можно выделить следующие компоненты:
1. Личный кабинет
Это веб-приложение. Как минимум нужно проверять, что приложение доступно в Интернете.
2. База данных
В базе данных хранятся важные для отчетности данные, необходимо проверять, что резервные копи базы данных успешно создаются.
3. Сервер
Под сервером имеется ввиду железо, на котором работают приложения. Необходимо проверять состояние HDD, RAM, CPU.
4. Агент
Это windows-служба, которая выполняет много разных задач по расписанию. Как минимум необходимо проверять, что служба работает.
5. Задача агента
Просто знать, что агент работает — недостаточно. Агент может работать, но не выполнять возложенные на него задачи. Разобьем компонент агента на задачи и будем проверять успешно ли работает каждая задача агента.
6. Пункты дорожного контроля (контейнер всех ПДК)
Пунктов дорожного контроля много, поэтому объединим все ПДК в одном компоненте. Это позволит более удобно читать данные мониторинга. При просмотре состояния компонента «система АСМО» сразу будет понятно где проблемы: в приложениях, железе или в ПДК.
7. Пункт дорожного контроля (один ПДК)
Данный компонент будем считать исправным, если исправны все устройства на данном ПДК.
8. Устройство
Это видеокамера или метеостанция, которые установлены на ПДК. Необходимо проверять, что устройство исправно работает.
В системе мониторинга дерево компонентов будет выглядеть так:
Мониторинг веб-приложения
Итак, мы разбили систему на компоненты, теперь нужно придумать для каждого компонента проверки.
Для мониторинга веб-приложения мы используем следующие проверки:
1. Проверка открытия главной страницы
Эту проверку выполняет система мониторинга. Для её выполнения указываем адрес страницы, ожидаемый фрагмент ответа и максимальное время выполнения запроса.
2. Проверка срока оплаты домена
Очень важная проверка. Когда домен остается без оплаты, пользователи не могут открыть сайт. Решение проблемы может занять несколько дней, т.к. изменения ДНС применяются не сразу.
3. Проверка SSL сертификата
Сейчас почти все сайты используют для доступа протокол https. Для корректной работы протокола нужен валидный SSL сертификат.
Ниже представлен компонент «Личный кабинет» в системе мониторинга:

Все проверки выше подойдут для большинства приложений и не требуют написания кода. Это очень здорово, потому что можно начать мониторинг любого веб-приложения за 5 минут. Ниже приведены дополнительные проверки, которые можно выполнить для веб-приложения, но их реализация более сложная и специфична для разных приложений, поэтому мы не будем разбирать их в этой статье.
Что еще можно проверить?
Для более полного мониторинга веб-приложения можно выполнить следующие проверки:
- Количество ошибок JavaScript за период
- Количество ошибок на стороне веб-приложения (back-end) за период
- Количество не успешных ответов веб-приложения (код ответа 404, 500 и т.д.)
- Среднее время выполнения запроса
Мониторинг windows-службы (агента)
В системе АСМО агент выполняет роль планировщика задач, который в фоновом режиме выполняет задачи по расписанию.
Если все задачи агента выполняются успешно, значит агент работает исправно. Получается, чтобы выполнить мониторинг агента, нужно выполнить мониторинг его задач. Поэтому разбиваем компонент «Агент» на задачи. Создадим для каждой задачи отдельный компонент в системе мониторинга, где компонент «Агент» будет «родителем».
Разбиваем компонент «Агент» на дочерние компоненты (задачи):
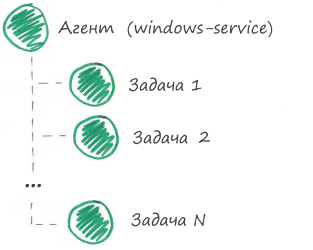
Итак, мы разбили сложный компонент на несколько простых. Теперь нужно для каждого простого компонента придумать проверки. Обратите внимание, что родительский компонент «Агент» не будет иметь ни одной проверки, потому что его состояние система мониторинга вычислит самостоятельно по статусу его дочерних компонентов. Другими словами, если все задачи выполняются успешно, значит и агент работает успешно.
В системе АСМО более ста задач, неужели для каждой задачи нужно придумывать уникальные проверки? Конечно, контроль будет лучше, если для каждой задачи агента мы придумаем и реализуем свои специальные проверки, но в большинстве случаев достаточно использовать универсальные проверки.
В системе АСМО используются только универсальные проверки для задач и этого достаточно, чтобы следить за работоспособностью системы.
Проверка выполнения
Самая простая и эффективная проверка – это проверка выполнения. Проверка проверяет, что задача выполняется, причем без ошибок. Данная проверка есть у всех задач.
Алгоритм проверки
После каждого выполнения задачи нужно отправить в систему мониторинга результат проверки SUCCESS, если выполнение задачи прошло успешно, или ERROR, если выполнение завершилось с ошибкой.
Данная проверка позволяет обнаружить следующие проблемы:
- Задача выполняется, но завершается ошибкой.
- Задача перестала выполняться, например, зависла.
Рассмотрим, как решаются данные проблемы более подробно.
Проблема 1 – Задача выполняется, но завершается ошибкой
Ниже изображен случай, когда задача выполняется, но с 14:00 до 16:00 завершается ошибкой.
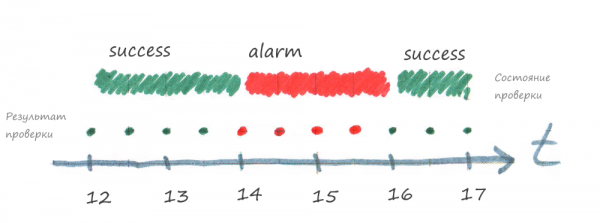
По рисунку видно, что когда задача завершается ошибкой, то сразу отправляется сигнал в систему мониторинга и статус соответствующей проверки в системе мониторинга становится alarm.
Обратите внимание, что в системе мониторинга от статуса проверки зависит и статус компонента. Статус alarm проверки переведет в alarm все вышестоящие компоненты, см. рисунок ниже.
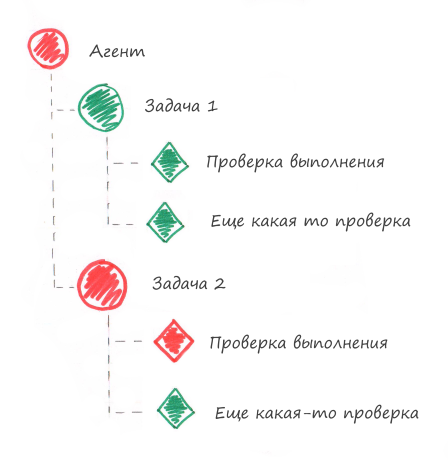
Проблема 2 — Задача перестала выполняться (зависла)
Как система мониторинга поймет, что задача зависла?
Результат проверки имеет время актуальности, например, 1 час. Если проходит час, а нового результат проверки нет, то система мониторинга установит проверке статус alarm.
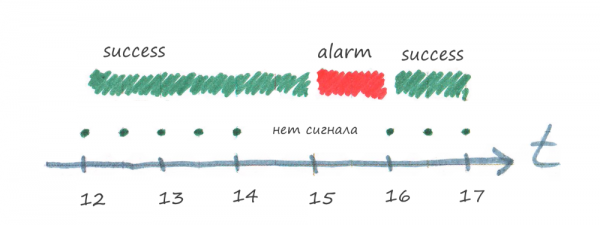
На рисунке выше в 14:00 выключили свет. В 15:00 система мониторинга обнаружит, что результат проверки (от 14:00) протух, т.к. закончилось время актуальности (один час), а нового результата нет, и переведет проверку в статус alarm.
В 16:00 свет опять включили, программа выполнит задачу и отправит результат выполнения в систему мониторинга, статус проверки опять станет success.
Какое время актуальности проверки использовать?
Время актуальности должно быть больше периода выполнения задачи. Рекомендую устанавливать время актуальности в 2-3 раза больше, чем период выполнения задачи. Это нужно, чтобы не получать ложные уведомления, когда, например, задача выполнялась дольше, чем обычно, или кто-то перезагружал программу.
Проверка прогресса
В системе АСМО есть задача «Загрузка прогноза», которая раз в час пытается загрузить новый прогноз из внешнего источника. Точное время, когда во внешней системе появляется новый прогноз не известно, но известно, что это происходит 2 раза в день. Получается, что если нового прогноза нет несколько часов, то это нормально, но если нового прогноза нет уже более суток, то значит где-то что-то сломалось. Например, во внешней системе прогнозов может измениться формат данных, из-за чего АСМО не увидит нового релиза прогноза.
Алгоритм проверки
Задача отправляет в систему мониторинга результат проверки SUCCESS, когда удаётся получить прогресс (загрузить новый прогноз погоды). Если прогресса нет или произошла ошибка, то ничего в систему мониторинга не отправляется.
Проверка должна иметь интервал актуальности такой, чтобы за это время гарантированно получить новый прогресс.
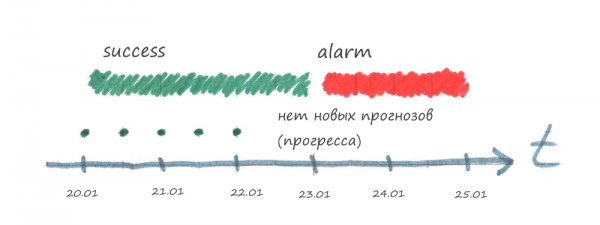
Обратите внимание, что о проблеме мы узнаем с задержкой, потому что система мониторинга ждет, когда закончится время актуальности последнего результата проверки. Поэтому время актуальности проверки не нужно делать слишком большим.
Мониторинг базы данных
Для контроля базы данных в системе АСМО мы выполняем следующие проверки:
- Проверка создания резервных копий
- Проверка свободного места на диске
Проверка создания резервных копий
В большинстве приложений важно иметь актуальные резервные копии базы данных, чтобы в случае поломки сервера можно было развернуть программу на новом сервере.
АСМО раз в неделю создаёт резервную копию и отправляет её в хранилище. Когда данная процедура успешно завершается в систему мониторинга отправляется результат проверки success. Результат проверки имеет время актуальности 9 дней. Т.е. для контроля за созданием резервных копий используется механизм «проверка прогресса», который мы разбирали выше.
Проверка свободного места на диске
Если на диске не будет достаточно свободного места, то база данных не сможет нормально работать, поэтому важно контролировать размер свободного места.
Для проверки числовых параметров удобно использовать метрики.
Метрика – это числовая переменная, значение которой передаётся в систему мониторинга. Система мониторинга проверяет пороговые значения и вычисляет статус метрики.
Ниже представлен рисунок как выглядит компонент «База данных» в системе мониторинга:

Мониторинг сервера
Для мониторинга сервера мы используем следующие проверки и метрики:
1. Свободное место на диске
Если место на диске закончится, то приложение не сможет работать. У нас используется 2 пороговых значения: первое уровня WARNING, второе уровня ALARM.
2. Среднее значение RAM в процентах за час
Мы используем среднее значение за час, т.к. нас не интересуют редкие скачки.
3. Среднее значение CPU в процентах за час
Мы используем среднее значение за час, т.к. нас не интересуют редкие скачки.
4. Проверка ping
Проверяет, что сервер в сети. Данную проверку умеет выполнять система мониторинга, не нужно писать код.
Ниже представлен рисунок как выглядит компонент «Сервер» в системе мониторинга:

Мониторинг оборудования
Расскажу, как происходит получение данных. Для каждого пункта дорожного контроля (ПДК) в планировщике задач есть задача, например, «Опрос ПДК М2 км 200». Задача раз в 30 минут получает данные со всех устройств ПДК.
Проблема канала связи
Большая часть оборудования стоит за городом, для передачи данных используется GSM сеть, которая работает не стабильно (сеть то есть, то её нет).
Из-за частых сбоев сети первое время проверка опроса ПДК в мониторинге выглядела так:
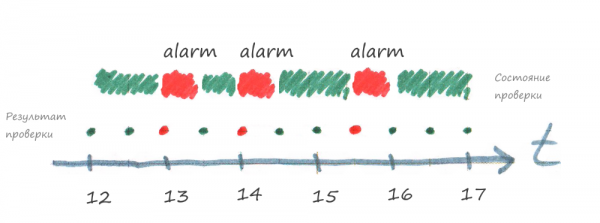
Стало понятно, что это не рабочий вариант, потому что получалось много ложный уведомлений о проблемах. Тогда было принято решение для каждого устройства использовать «проверку прогресса», т.е. в систему мониторинга отправляется только сигнал success, в случае, когда устройство опрашивается без ошибки. Время актуальности поставили 5 часов.
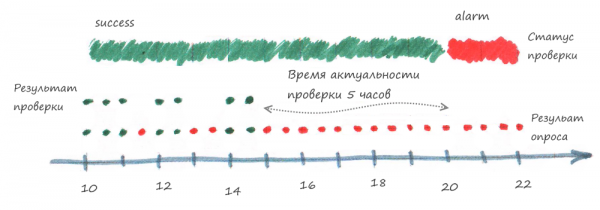
Теперь мониторинг присылает уведомление о проблемах, только когда устройство не удаётся опросить более 5 часов. С высокой долей вероятности это не ложные тревоги, а реальные проблемы.
Ниже представлен рисунок как выглядит оборудование в системе мониторинга:
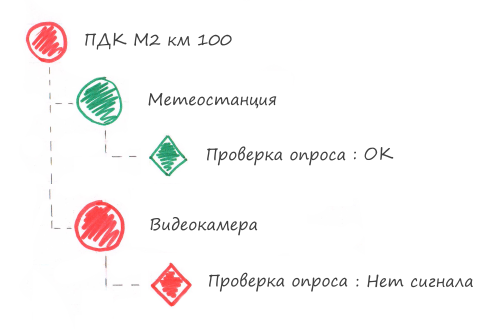
Важно!
Когда GSM сеть престает работать, то не опрашиваются все устройства ПДК. Чтобы уменьшить количество писем от системы мониторинга, наши инженеры подписываются на уведомления о проблемах компонентов с типом «ПДК», а не «Устройство». Это позволяет получить одно уведомление по каждому ПДК, а не получать отдельное уведомление по каждому устройству.
Итоговая схема мониторинга АСМО
Давайте соберем все вместе и посмотрим какая схема мониторинга у нас получилась.
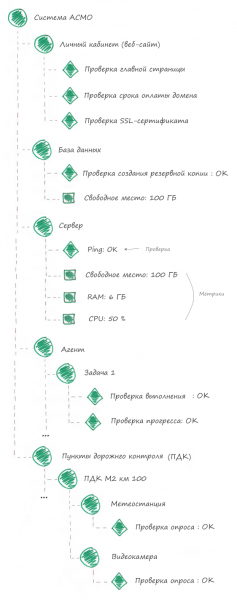
Заключение
Давайте подведем итоги.
Что нам дал мониторинг работоспособности АСМО?
1. Уменьшилось время устранения дефектов
Раньше мы узнавали о дефектах от пользователей, но не все пользователи сообщают о дефектах. Бывало так, что о неисправности какого-либо компонента системы мы узнавали через неделю после его появления. Теперь система мониторинга уведомляет нас о проблемах сразу, как только проблема обнаружена.
2. Увеличилась стабильность работы системы
Так как дефекты стали устраняться раньше, то и система в целом стала работать гораздо стабильнее.
3. Снижение количества обращений в техническую поддержку
Многие проблемы теперь устраняются до того, как о них узнают пользователи. Пользователи стали меньше обращаться в техническую поддержку. Все это хорошо сказывается на нашу репутацию.
4. Увеличение лояльности заказчика и пользователей
Заказчик заметил положительные изменения в стабильности работы системы. Пользователи меньше сталкиваются с проблемами в работе с системой.
5. Сокращения затрат на техническую поддержку
Мы перестали вручную выполнять какие-либо проверки. Теперь все проверки автоматизированы. Раньше мы узнавали о проблемах от пользователей, часто было сложно понять, о какой проблеме говорит пользователь. Теперь о большинстве проблем сообщает система мониторинга, уведомления содержат технические данные, по которым всегда понятно, что и где сломалось.
Важно!
Нельзя устанавливать систему мониторинга на тот же сервер, где работают ваши приложения. Если сервер выйдет из строя, то приложения перестанут работать, и некому будет отправить об этом уведомление.
Система мониторинга должна работать на отдельном сервере в другом ЦОД.
Если вы не хотите использовать выделенный сервер в новом ЦОД, можно воспользоваться облачной системой мониторинга. В нашей компании используется облачная система мониторинга Zidium, но вы можете использовать любую другую систему мониторинга. Стоимость облачной системы мониторинга ниже аренды нового сервера.
Рекомендации:
- Разбивайте приложения и системы в виде дерева компонентов как можно детальнее, так будет удобно понимать, где и что сломалось, а контроль будет более полный.
- Чтобы проверить работоспособность компонента используйте проверки. Лучше использовать много простых проверок, чем одну сложную.
- Пороговые значения метрик настраивайте на стороне системы мониторинга, а не прописывайте в коде. Это избавит вас от перекомпилирования, переконфигурирования или перезапуска приложения.
- Для пользовательских проверок используйте время актуальности с запасом, чтобы не получать ложные уведомления из-за того, что какая-то проверка выполнялась чуть дольше, чем обычно.
- Постарайтесь сделать так, чтобы компоненты в системе мониторинга становились красными только тогда, когда проблема точно есть. Если они будут становиться красными по пустякам, то вы перестанете обращать внимание на уведомления системы мониторинга, её смысл будет утрачен.
Если вы еще не используете систему мониторинга, начинайте! Это не так сложно, как кажется. Получите кайф, разглядывая зеленое дерево компонентов, которое вы вырастили сами.
Удачи.
Источник: habr.com
