


Так как ClickHouse является специализированной системой, при его использовании важно учитывать особенности его архитектуры. В этом докладе Алексей расскажет о примерах типичных ошибок при использовании ClickHouse, которые могут привести к неэффективной работе. На примерах из практики будет показано, как выбор той или иной схемы обработки данных может изменить производительность на порядки.
Всем привет! Меня зовут Алексей, я делаю ClickHouse.

Во-первых, сразу спешу вас обрадовать, я не буду сегодня вам рассказывать, что такое ClickHouse. Если честно, мне это надоело. Я каждый раз рассказываю, что это. И, наверное, все уже знают.

Вместо этого я буду рассказывать, какие есть возможные грабли, т. е. как можно неправильно использовать ClickHouse. На самом деле бояться не стоит, потому что мы разрабатываем ClickHouse как систему, которая простая, удобная, работает из коробки. Поставил и все, никаких проблем.
Но все-таки надо учитывать, что система эта специализированная и можно легко натолкнуться на необычный сценарий использования, который выведет эту систему из зоны комфорта.
Итак, какие есть грабли? В основном я буду говорить про очевидные вещи. Всем всё очевидно, все всё понимают и могут порадоваться, что они такие умные, а кто не понимают, те узнают что-то новое.

Первый самый простой пример, который, к сожалению, часто встречается, это большое количество inserts с маленькими batches, т. е. большое количество маленьких inserts.
Если рассматривать, как ClickHouse выполняет insert, то вы можете за один запрос отправить хоть поток данных на терабайт. Это не проблема.
И давайте посмотрим, какая типичная будет производительность. Например, таблица у нас с данных Яндекс.Метрики. Хиты. 105 каких-то столбцов. 700 байт в несжатом виде. И будем вставлять по-хорошему батчами по одному миллиону строк.
Вставляем в таблицу MergeTree, получается полмиллиона строк в секунду. Отлично. В реплицированную таблицу – чуть поменьше будет, примерно 400 000 строк в секунду.
И если включить кворумную вставку, то получается чуть меньше, но все равно приличная производительность, 250 000 срок в секунду. Кворумная вставка – это недокументированная возможность в ClickHouse*.
* по состоянию на 2020 год, .

Что будет, если делать плохо? Вставляем по одной строке в таблицу MergeTree и получается 59 строк в секунду. Это в 10 000 раз медленно. В ReplicatedMergeTree – 6 строк в секунду. А если еще кворум включится, то получается 2 строки в секунду. По-моему, это какой-то кромешный отстой. Как можно так тормозить? У меня даже на футболке написано, что ClickHouse не должен тормозить. Но тем не менее бывает иногда.

На самом деле – это наш недостаток. Мы могли бы вполне сделать так, чтобы все работало нормально, но не сделали. И мы это не сделали, потому что для нашего сценария – это не требовалось. У нас и так были батчи. Просто к нам на вход поступали батчи, и никаких проблем. Вставляем и все нормально работает. Но, конечно, возможны всякие сценарии. Например, когда у вас куча серверов, на которых данные генерируются. И они вставляют данные не так часто, но все равно получаются частые вставки. И нужно этого как-то избежать.
С технической точки зрения суть в том, что когда вы делаете insert в ClickHouse, то данные не попадают ни в какой memtable. У нас даже не настоящий log structure MergeTree, а просто MergeTree, потому что нет ни log’а, ни memTable. Мы просто сразу записываем данные в файловую систему, уже разложенные по столбцам. И если у вас 100 столбцов, то больше 200 файлов надо будет записать в отдельную директорию. Все это весьма громоздко.

И возникает вопрос: «Как делать правильно?», если такая ситуация, что нужно все-таки как-то записывать данные в ClickHouse.
Способ 1. Это самый простой способ. Использовать какую-нибудь распределенную очередь. Например, Kafka. Просто вынимаете данные из Kafka, батчим раз в секунду. И все будет нормально, вы записываете, все нормально работает.
Недостатки в том, что Kafka – это еще одна громоздкая распределенная система. Я еще понимаю, если у вас в компании уже есть Kafka. Это хорошо, это удобно. Но если ее нет, то стоит трижды подумать перед тем, как тащить еще одну распределенную систему себе в проект. И поэтому стоит рассмотреть альтернативы.

Способ 2. Вот такая олдскульная альтернатива и при этом очень простая. Есть у вас какой-то сервер, который генерируют ваши логи. И он просто записывает ваши логи в файл. И раз в секунду, например, этот файл переименовываем, отрываем новый. И отдельный скрипт либо по cron, либо какой-то daemon берет самый старый файл и записывает в ClickHouse. Если записывать логи раз в секунду, то все будет прекрасно.
Но недостаток этого способа в том, что если у вас сервер, на котором генерируются логи куда-то исчез, то и данные тоже исчезнут.

Способ 3. Есть еще один интересный способ, который вообще без временных файлов. Например, у вас какая-нибудь рекламная крутилка или еще какой-нибудь интересный daemon, который генерирует данные. И вы можете накапливать пачку данных прямо в оперативке, в буфере. И когда проходит достаточное количество времени, вы этот буфер откладываете в сторонку, создаете новый, а в отдельном потоке то, что уже накопилось, вставляете в ClickHouse.
С другой стороны данные тоже при kill -9 исчезают. Если ваш сервер упадет, то вы эти данные потеряете. И еще проблема в том, что если вы не смогли записать в базу, то у вас данные будут накапливаться в оперативке. И либо закончится оперативка, либо просто потеряете данные.

Способ 4. Еще один интересный способ. Есть у вас какой-то серверный процесс. И он может отправлять данные в ClickHouse сразу, но делать это в одном соединении. Например, отправил http-запрос с transfer-encoding: chunked с insert’ом. И генерирует чанки уже не слишком редко, можно каждую строчку отправлять, хотя будет overhead на фрейминг этих данных.
Но тем не мене в этом случае данные будут отправлены в ClickHouse сразу. И ClickHouse сам их будет буферизовать.
Но тоже возникают проблемы. Теперь вы потеряете данные, в том числе, когда ваш процесс убьется и, если процесс ClickHouse убьется, потому что это будет незавершенный insert. А в ClickHouse inserts атомарные до некоторого указанного порога в размере строк. В принципе, это интересный способ. Тоже можно использовать.

Способ 5. Вот еще один интересный способ. Это какой-то разработанный community – сервер для батчинга данных. Я на него сам не смотрел, поэтому ничего гарантировать не могу. Впрочем, и для самого ClickHouse никаких гарантий не предоставляется. Это тоже open source, но с другой стороны, вы могли привыкнуть к некоторому стандарту качества, который мы стараемся обеспечивать. А вот для этой штуки – я не знаю, зайдите на GitHub, посмотрите код. Может быть, что-то нормальное написали.
* по состоянию на 2020 год, следует также добавить в рассмотрение .

Способ 6. Еще один способ – это использование Buffer таблиц. Достоинства этого способа в том, что это очень просто начать использовать. Создаете Buffer таблицу и вставляете в нее.
А недостаток в том, что проблема решается не полностью. Если при в ставке типа MergeTree вы должны группировать данные по одному батчу в секунду, то при в ставке в buffer таблицу, вам нужно группировать хотя бы до несколько тысяч в секунду. Если будет больше 10 000 в секунду, то все равно будет плохо. А если вставлять батчами, то вы видели, что там получается сотня тысяч строк в секунду. И это уже на достаточно тяжелых данных.
И тоже buffer таблицы не имеют лога. И если с вашим сервером что-то не так, то данные будут потеряны.

И в качестве бонуса недавно у нас в ClickHouse появилась возможность забирать данные из Kafka. Существует движок таблиц – Kafka. Вы просто создаете. И на него можно навесить материализованные представления. В этом случае он будет сам вынимать данные из Kafka и вставлять в нужные вам таблицы.
И особенно радует в этой возможности то, что ее делали не мы. Это community фича. И когда я говорю «community фича», я говорю без всякого презрения. Код мы читали, ревью делали, должно работать нормально.
* по состоянию на 2020 год, появилась аналогичная поддержка для .

Что еще может быть неудобного или неожиданного при вставке данных? Если вы делаете запрос insert values и в values пишите какие-то вычисляемые выражения. Например, now() – это тоже вычисляемое выражение. И в этом случае ClickHouse вынужден на каждую строчку запускать интерпретатор этих выражений, и производительность просядет на порядки. Лучше этого избегать.
* на данный момент, проблема полностью решена, регрессии производительности при использовании выражений в VALUES больше нет.
Другой пример, когда могут быть некоторые проблемы, когда у вас на одном батче данные относятся к куче партиций. По умолчанию в ClickHouse партиции по месяцам. И если вы вставляете батч из миллиона строк, а там данные за несколько лет, то у вас там будет несколько десятков партиций. И это эквивалентно тому, что будут батчи в несколько десятков раз меньшего размера, потому что внутри они всегда сначала разбиваются по партициям.
* недавно в ClickHouse в экспериментальном режиме добавлена поддержка компактного формата кусков и кусков в оперативной памяти с write-ahead log, что почти полностью решает проблему.

Теперь рассмотрим второй вид проблемы – это типизация данных.
Типизация данных бывает строгая, а бывает строковая. Строковая – это, когда вы просто взяли и объявили, что у вас все поля типа string. Это отстой. Так делать не надо.
Давайте разберемся, как делать правильно в тех случаях, когда хочется сказать, что какое-то поле у нас, строка, и пусть ClickHouse сам разберется, а я париться не буду. Но все-таки стоит предпринимать некоторые усилия.

Например, у нас есть IP-адрес. В одном случае мы его сохранили как строку. Например, 192.168.1.1. А в другом случае – это будет число типа UInt32*. 32 бит достаточно для IPv4 адреса.
Во-первых, как не странно, данные сожмутся примерно одинаково. Там будет разница, конечно, но не такая большая. Так что по дисковому вводу-выводу особых проблем нет.
Но есть серьезная разница по процессорному времени и по времени выполнения запроса.
Посчитаем количество уникальных IP-адресов, если они хранятся в виде чисел. Получается 137 миллионов строк в секунду. Если тоже самое в виде строк, то 37 миллионов строк в секунду. Я не знаю, почему такое совпадение получилось. Я сам выполнял эти запросы. Но тем не менее примерно в 4 раза медленнее.
А если посчитать разницу в месте на диске, то разница тоже есть. И разница где-то на одну четверть, потому что уникальных IP-адресов достаточно много. И если бы здесь были строчки с маленьким количеством разных значений, то они бы спокойно сжались по словарю примерно в одинаковый объем.
И четырехкратная разница во времени на дороге не валяется. Может быть, вам, конечно, по фиг, но когда я вижу такую разницу, мне становится грустно.

Рассмотрим разные случаи.
1. Один случай, когда у вас разных уникальных значений немного. В этом случае используем простую практику, которую вы, наверное, знаете и можете использовать для любых СУБД. Это все имеет смысл не только для ClickHouse. Просто записываете в базу числовые идентификаторы. А конвертировать в строки и обратно можно уже на стороне вашего приложения.
Вот, например, есть у вас регион. И вы его пытаетесь сохранить в виде строки. И там написано будет: Москва и МО. И когда я вижу, что там написано «Москва», то это еще ничего, а когда и МО, то как-то совсем грустно становится. Это же сколько байт.
Вместо этого мы просто записываем число Ulnt32 и 250. У нас 250 в Яндексе, а у вас, может быть, по-другому. На всякий случай скажу, что в ClickHouse есть встроенная возможность работы с геобазой. Вы просто записываете справочник с регионами, в том числе и иерархический, т. е. там будет и Москва, и МО, и все, что вам надо. И можно конвертировать на уровне запроса.

Второй вариант примерно такой же, но уже с поддержкой внутри ClickHouse. Это тип данных Enum. Вы просто внутри Enum прописываете все нужные вам значения. Например, тип устройства и там пишите: десктоп, мобильный, планшет, телевизор. Всего 4 варианта.
Недостаток в том, что нужно периодически алтерить. Добавили всего лишь один вариант. Делаем alter table. На самом деле alter table в ClickHouse бесплатен. Особенно бесплатен для Enum, потому что данные на диске не меняются. Но тем не менее alter захватывает блокировку* на таблицу и должен подождать, пока выполнятся все selects. И только после этого alter выполнится, т. е. все-таки некоторые неудобства присутствуют.
* в свежих версиях ClickHouse, ALTER сделан полностью неблокирующим.

Еще один вариант достаточно уникальный для ClickHouse – это подключение внешних словарей. Вы можете писать в ClickHouse числа, а ваши справочники держать в любой удобной вам системе. Например, можно использовать: MySQL, Mongo, Postgres. Можно даже свой микросервис запилить, который будет по http отдавать эти данные. И на уровне ClickHouse вы пишите функцию, которая будет эти данные преобразовывать из чисел в строчки.
Это специализированный, но очень эффективный способ выполнить join с внешней таблицей. Причем есть два варианта. В одном варианте эти данные будут полностью закэшированные, полностью присутствовать в оперативке и обновляться с некоторой периодичностью. А в другом варианте, если эти данные в оперативку не помещаются, то можно их частично кэшировать.
Вот пример. Есть Яндекс.Директ. И там есть рекламная компания и баннеры. Рекламных компаний, наверное, порядка десяток миллионов. И примерно помещаются в оперативку. А баннеров – миллиарды, они не помещаются. И мы используем кэшируемый словарь из MySQL.
Единственная проблема в том, что кэшируемый словарь будет работать нормально, если hit rate близок к 100 %. Если поменьше, то при обработке запросов на каждую пачку данных надо будет реально брать недостающие ключи и ходить забирать данные из MySQL. Про ClickHouse я еще могу заручиться, что – да, не тормозит, про другие системы говорить не буду.
А в качестве бонуса то, что словари – это очень простой способ обновлять данные в ClickHouse задним числом. Т. е. был у вас отчет по рекламной компаниям, пользователь просто поменял рекламную компанию и во всех старых данных, во всех отчетах эти данные тоже поменялись. Если писать строки непосредственно в таблицу, то обновлять их будет невозможно.

Еще один способ, когда вы не знаете, откуда вам взять идентификаторы для ваших строк. можно просто захэшировать. Причем самый простой вариант – это брать 64 битный хэш.
Единственная проблема в том, что если хэш 64-х битный, то коллизии у вас обязательно будут почти наверняка. Потому что если там миллиард строк, то вероятность уже становится ощутимой.
И не очень хорошо было бы так хэшировать имена рекламных компаний. Если рекламные компании у разных компаний перепутаются, то будет что-то непонятное.
И есть простой трюк. Правда, для серьезных данных тоже не очень подходит, но если что-то не очень серьезное, то просто добавьте в ключ словаря еще идентификатор клиента. И тогда коллизии у вас будут, но только в пределах одного клиента. И такой способ у нас используется для карты ссылок в Яндекс.Метрике. Есть у нас там урлы, мы храним хэши. И мы знаем, что коллизии, конечно, есть. Но когда отображается страница, то вероятность того, что именно на одной странице у одного пользователя какие-то урлы слиплись и это еще заметят, то этим можно пренебречь.
В качестве бонуса – для многих операций достаточно одних хэшей и сами строки можно нигде не хранить.

Другой пример, если строки короткие, например, домены сайтов. Их можно хранить как есть. Или, например, язык браузера ru – 2 байта. Мне конечно, очень жалко байтики, но не беспокойтесь, 2 байта не жалко. Пожалуйста, храните как есть, не парьтесь.

Другой случай, когда, наоборот, строк очень много и в них при этом очень много уникальных, да еще и множество потенциально не ограничено. Типичный пример – это поисковые фразы или урлы. Поисковые фразы, в том числе из-за опечаток. Посмотрим, сколько уникальных поисковых фраз за сутки. И получается, что их чуть ли не половина от всех событий. И в этом случае вы могли бы подумать, что нужно данные нормализовать, считать идентификаторы, складывать в отдельную таблицу. Но делать так не надо. Просто храните эти строки как есть.
Лучше – ничего не придумывайте, потому что если отдельно хранить, то потребуется делать join. А этот join – это в лучшем случае случайный доступ в память, если еще в память поместится. Если не поместится, то вообще будут проблемы.
А если данные хранятся в in place, то они просто вычитываются в нужном порядке из файловой системы и все нормально.

Если у вас есть урлы или еще какая-то сложная длинная строка, то стоит задуматься о том, что можно посчитать какую-то выжимку заранее и записать в отдельный столбец.
Для урлов, например, можно отдельно хранить домен. И если вам на самом деле нужен домен, то просто используйте этот столбец, а урлы будут лежать, и вы к ним даже прикасаться не будете.
Давайте посмотрим, какая получается разница. В ClickHouse есть специализированная функция, которая вычисляет домен. Она очень быстрая, мы ее оптимизировали. И, честно скажу, она даже не соответствует RFC, но тем не менее считает, все, что нам надо.
И в одном случае мы будем просто доставать урлы и вычислять домен. Получается 166 миллисекунд. А если взять готовенький домен, то получается всего лишь 67 миллисекунд, т. е. почти в три раза быстрее. Причем быстрее не из-за того, что нам нужно делать какие-то вычисления, а из-за того, что мы читаем меньше данных.
Вот почему-то у одного запроса, который медленней, получается больше скорость гигабайтов в секунду. Потому что он читает больше гигабайт. Это совершенно лишние данные. Запрос как бы работает быстрее, но выполняется за более длительное время.
А если посмотреть объем данных на диске, то получается, что урл 126 мегабайтов, а домен всего лишь 5 мегабайтов. Получается в 25 раз меньше. Но тем не менее запрос выполняется всего лишь в 4 раза быстрее. Но это потому что данные горячие. А если было бы холодные, то наверняка было в 25 раз быстрее из-за дискового ввода-вывода.
Кстати, если оценить, насколько домен меньше чем урл, то получается где-то раза в 4. Но почему-то на диске данные занимают в 25 раз меньше. Почему? Из-за сжатия. И урл сжимается, и домен сжимается. Но часто урл содержит кучу мусора.

И, конечно, стоит использовать правильные типы данных, которые предназначены специально для нужных значений или, которые подходят. Если вы в IPv4, то храните UInt32*. Если IPv6, то FixedString(16), потому что IPv6 адрес – это 128 бит, т. е. храните прямо в бинарном формате.
А что делать, если у вас иногда IPv4 адреса, а иногда IPv6? Да, можно хранить оба. Один столбец для IPv4, другой для IPv6. Конечно, есть вариант IPv4 отображать в IPv6. Это тоже будет работать, но если вам в запросах часто нужен именно IPv4 адрес, то неплохо бы засунуть в отдельный столбец.
* теперь в ClickHouse есть отдельные типы данных IPv4, IPv6, которые хранят данные так же эффективно, как числа, но представляют их так же удобно, как строки.

Еще важно заметь, что стоит данные предобработать заранее. Например, поступают к вам какие-то сырые логи. И, может быть, стоит не сразу их засовывать в ClickHouse, хотя очень заманчиво ничего не делать и все будет работать. Но стоит все-таки провести те вычисления, которые можно.
Например, версия браузера. В некотором соседнем отделе, на который мне не хочется показывать пальцем, там версия браузера хранится вот так, т. е. как строка: 12.3. А потом, чтобы сделать отчет, они берут эту строку и делят на массив, а потом на первый элемент массива. Естественно, все тормозит. Я спрашивал, почему они так делают. Они мне ответили, что не любят преждевременную оптимизацию. А я не люблю преждевременную пессимизацию.
Так что в этом случае правильнее будет разделить на 4 столбца. Тут не бойтесь, потому что это ClickHouse. ClickHouse – это столбцовая база данных. И чем больше аккуратных маленьких столбцов, тем лучше. Будет 5 BrowserVersion, делайте 5 столбцов. Это нормально.

Теперь рассмотрим, что делать, если у вас много очень длинных строк, очень длинных массивов. Их не нужно хранить в ClickHouse вообще. Вместо этого вы можете сохранить в ClickHouse только какой-то идентификатор. А эти длинные строки засуньте их в какую-нибудь другую систему.
Например, в одном из наших аналитических сервисов есть некоторые параметры событий. И если на события приходят много параметров, мы просто сохраняем первые попавшиеся 512. Потому что 512 – не жалко.

А если вы не можете определиться с вашими типами данных, то вы можете тоже записать данные в ClickHouse, но во временную таблицу типа Log, специальную для временных данных. После этого вы можете проанализировать, какое у вас там распределение значений, что вообще есть и составить правильные типы.
* сейчас в ClickHouse есть тип данных который позволяет эффективно хранить строки с меньшими трудозатратами.

Теперь рассмотрим еще один интересный случай. Иногда у людей все как-то странно работает. Я захожу и вижу такое. И сразу представляется, что это делал какой-то очень опытный, умный админ, у которого большой опыт настройки MySQL версии 3.23.
Здесь мы видим тысячу таблиц, в каждой из которой записан остаток от деления непонятно чего на тысячу.
В принципе, я уважаю чужой опыт, в том числе понимаю, какими страданиями этот опыт может быть наработан.

И причины более-менее понятны. Это старые стереотипы, которые могли накопиться при работе с другими системами. Например, в MyISAM таблицах нет кластерного первичного ключа. И такой способ разделения данных может быть отчаянной попыткой получить ту же функциональность.
Другая причина – это то, что всякие операции типа alter над большими таблицами делать трудно. Все будет блокироваться. Хотя в современных версиях MySQL эта проблема уже не столь серьезная.
Или, например, микрошардирование, но об этом чуть позже.

В ClickHouse так делать не надо, потому что, во-первых, первичный ключ кластерный, данные упорядочены по первичному ключу.
И иногда меня спрашивают: «Как меняется производительность диапазонных запросов в ClickHouse от размера таблицы?». Я говорю, что она никак не меняется. Например, у вас таблица в миллиард строк и читаете диапазон один миллион строк. Все нормально. Если в таблице триллион строк и вы читаете один миллион строк, то будет почти тоже самое.
И, во-вторых, всяких штук типа ручных партиций не требуется. Если вы зайдете и посмотрите, что там на файловой системе, вы увидите, что таблица – это достаточно серьезная вещь. И там внутри есть что-то типа партиций. Т. е. ClickHouse все делает за вас и вам не нужно страдать.

Alter в ClickHouse бесплатный, если alter add/drop column.
И маленькие таблицы делать не стоит, потому что если у вас в таблице 10 строк или 10 000 строк, то это совершено неважно. ClickHouse – это система, которая оптимизирует throughput, а не latency, так что 10 строк обрабатывать не иметь смысла.

Правильно использовать одну большую таблицу. Избавьтесь от старых стереотипов, все будет хорошо.
А в качестве бонуса у нас в последней версии появилась возможность делать произвольный ключ партиционирования для того, что чтобы выполнять всякие maintenance операции над отдельными партициями.
Например, вам нужно много маленьких таблиц, например, когда бывает потребность в обработке каких-то промежуточных данных, вам поступают чанки и вам нужно выполнять преобразование над ними перед записью в финальную таблицу. Для этого случая есть замечательный движок таблицы – StripeLog. Это примерно как TinyLog, только лучше.
* сейчас в ClickHouse есть ещё и .

Еще один антипаттерн – это микрошардинг. Например, вам данные нужно шардировать и у вас есть 5 серверов, а завтра будет 6 серверов. И вы думаете, как эти данные перебалансировать. И вместо этого вы разбиваете не на 5 шардов, а на 1 000 шардов. И дальше отображаете каждый из этих микрошардов на отдельный сервер. И у вас получится на одном сервере, например, 200 ClickHouse, например. Отдельные instance на отдельных портах или отдельные базы данных.

Но в ClickHouse это не очень хорошо. Потому что даже один instance ClickHouse старается использовать все доступные ресурсы сервера для обработки одного запроса. Т. е. есть у вас сервер какой-нибудь и там, например, 56 процессорных ядер. Вы выполняете запрос, который выполняется одну секунду, и он будет использовать 56 ядер. А если вы разместили там 200 ClickHouse на одном сервере, то получается, что запустится 10 000 потоков. В общем, все будет очень плохо.
Другая причина в том, что распределение работы по этим instances будет неравномерное. Какой-то закончит раньше, какой-то закончит позже. Если бы все это происходило в одном instance, то ClickHouse сам бы разобрался как распределить правильно данные по потокам.
И еще одна причина в том, что будет у вас межпроцессорное взаимодействие по TCP. Данные придется сериализовывать, десериализовывать и это огромное количество микрошардов. Просто неэффективно будет работать.

Еще один антипаттерн, хотя его трудно назвать антипаттерном. Это большое количество предагрегации.
Вообще, предагрегация – это хорошо. Было у вас миллиард строк, вы его сагрегировали и стало 1 000 строк, и теперь запрос выполняется мгновенно. Все замечательно. Так можно делать. И для этого даже в ClickHouse есть специальный тип таблицы AggregatingMergeTree, который делает инкрементальную агрегацию по мере вставке данных.
Но бывают случаи, когда вы думаете, что мы будем вот так агрегировать данные и еще так агрегировать данные. И в некотором соседнем отделе, тоже не хочется говорить в каком, используют таблицы SummingMergeTree для суммирования по первичному ключу, а в качестве первичного ключа используют штук 20 каких-то столбцов. Я на всякий случай изменил имена некоторых столбцов для конспирации, но примерно так и есть.

И возникают такие проблемы. Во-первых, объем данных у вас уменьшается не слишком сильно. Например, уменьшается в три раза. Три раза – это было бы хорошей ценой, чтобы позволить себе неограниченные возможности по аналитике, которые возникают, если данные у вас неагрегированные. Если данные агрегированные, то вы вместо аналитики получаете всего лишь жалкую статистику.
И что особенно достает? То, что эти люди из соседнего отдела, ходят и просят иногда добавить еще один столбец в первичный ключ. Т. е. мы вот так вот агрегировали данные, а теперь хотим чуть больше. Но в ClickHouse нет alter первичного ключа. Поэтому приходятся писать какие-то скрипты на C++. А я не люблю скрипты, даже если они на C++.
И если посмотреть для чего создавался ClickHouse, то неагрегированные данные – это прямо тот сценарий, для которого он рожден. Если вы используете ClickHouse для неагрегированных данных, то вы все делаете правильно. Если вы агрегируете, то это иногда простительно.
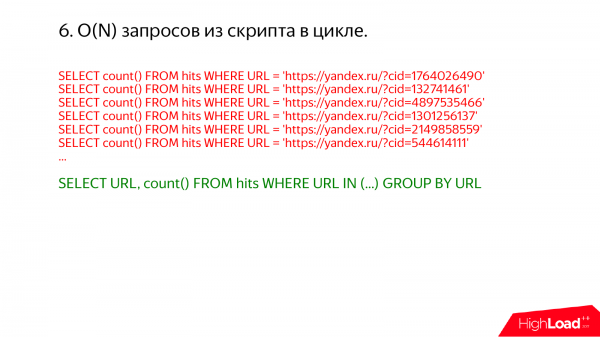
Еще один интересный случай – это запросы в бесконечном цикле. Я иногда захожу на какой-нибудь production сервер и смотрю там show processlist. И каждый раз обнаруживаю, что происходит что-то ужасное.
Например, вот такое. Тут сразу ясно, что можно было все выполнить в одном запросе. Просто пишите там url in и список.

Почему много таких запросов в бесконечном цикле – это плохо? Если индекс не используется, то у вас будет много проходов по одним и тем же данным. Но если индекс используется, например, у вас есть первичный ключ по ru и вы пишете url = чему-то там. И вы думаете, что будет точечно читаться из таблицы один url, будет все нормально. Но на самом деле нет. Потому что ClickHouse все делает по пачкам.
Когда ему нужно прочитать какой-то диапазон данных, он читает чуть больше, потому что индекс в ClickHouse разреженный. Этот индекс не позволяет найти в таблице одну индивидуальную строчку, только диапазон какой-то. И данные сжимаются блоками. Для того чтобы прочитать одну строчку, нужно взять целый блок и разжать его. И если вы выполняете кучу запросов, у вас будет много пересечений таких, и куча работы у вас будет выполняться снова и снова.

И в качестве бонуса можно заметить, что в ClickHouse не стоит бояться передавать даже мегабайты и даже сотни мегабайт в секцию IN. Я помню из нашей практики, что если в MySQL передаем кучу значений в секцию IN, например, передаем туда 100 мегабайт каких-то чисел, то MySQL съедает 10 гигабайт памяти и больше с этим ничего не происходит, все работает плохо.
А второе – это то, что в ClickHouse, если у вас запросы используют индекс, то это всегда не медленнее, чем full scan, т. е. если прочитать нужно почти всю таблицу, он будет идти последовательно и читать всю таблицу. В общем, сам разберется.
Но тем не менее есть некоторые сложности. Например, то, что IN с подзапросом индекс не использует. Но это наша проблема и нам надо это исправлять. Ничего фундаментального тут нет. Будем чинить*.
И еще одна интересная вещь – это то, что если у вас очень длинный запрос и распределенная обработка запросов идет, то этот очень длинный запрос будет отправлен на каждый сервер без сжатия. Например, 100 мегабайтов и 500 серверов. И, соответственно, у вас по сети будет передано 50 гигабайт. Будет передано и потом все успешно выполнится.
* уже использует; всё починили, как обещано.

И довольно частый случай, если запросы приходят из API. Например, вы сделали какой-то свой сервис. И если ваш сервис кому-то нужен, то вы открыли API и уже буквально через два дня видите, что происходит что-то непонятное. Все перегружено и какие-то ужасные запросы приходят, которые никогда не должны были быть.
И решение тут одно. Если вы открыли API, то вам его придется резать. Например, вводить квоты какие-нибудь. Других нормальных вариантов нет. Иначе сразу напишут скрипт и будут проблемы.
И в ClickHouse есть специальная возможность – это подсчет квот. Причем можно передавать свой ключ квоты. Это, например, внутренний идентификатор пользователя. И квоты будут считать независимо для каждого из них.

Теперь еще одна интересная вещь. Это репликация на ручном приводе.
Я знаю много случаев, когда, несмотря на то, что в ClickHouse есть встроенная поддержка репликации, люди реплицируют ClickHouse вручную.
Принцип какой? У вас есть pipeline обработки данных. И он работает независимо, например, в разных дата-центрах. Вы одинаковые данные одинаковом образом записываете в ClickHouse как бы. Правда, практика показывает, что данные все равно будут расходиться из-за каких-то особенностей в вашем коде. Надеюсь, что в вашем.
И периодически вам все равно придется вручную синхронизировать. Например, раз в месяц админы делают rsync.
На самом деле гораздо проще использовать встроенную в ClickHouse репликацию. Но тут могут быть некоторые противопоказания, потому что для этого нужно использовать ZooKeeper. Я ничего плохого про ZooKeeper говорить не буду, в принципе, система рабочая, но бывает, что люди не используют его из-за java-фобии, потому что ClickHouse – это такая хорошая система, написанная на C++, которой можно пользоваться и будет все отлично. А ZooKeeper на java. И как-то даже не хочется смотреть, но тогда можете репликацию на ручном приводе использовать.

ClickHouse – это практичная система. Она учитывает ваши нужны. Если у вас репликация на ручном приводе, то вы можете создать Distributed таблицу, которая смотрит на ваши ручные реплики и сама делает между ними failover. И есть даже специальная опция, которая позволяет избежать флапов, даже если ваши реплики систематически расходятся.

Далее могут быть проблемы, если вы используете примитивные table engines. ClickHouse – это такой конструктор, в котором есть куча разных движков таблиц. Для всех серьезных случаев, как написано в документации, используйте таблицы семейства MergeTree. А все остальные – это так, для отдельных случаев или для тестов.
В таблице MergeTree не обязательно, чтобы у вас были какая-то дата и время. Все равно можете использовать. Если нет даты и времени, пишите, что default – 2000 год. Это будет работать и ресурсов не будет требовать.
И в новой версии сервера можно даже указать, чтобы у вас было кастомное партиционирование без ключа партиции. Это будет то же самое.

С другой стороны, можно использовать примитивные движки таблиц. Например, залить данные один раз и посмотреть, покрутить и удалить. Можете использовать Log.
Или хранение маленьких объемов для промежуточной обработки – это StripeLog или TinyLog.
Memory можно использовать, если маленький объем данных и просто покрутить что-нибудь в оперативке.

ClickHouse не очень любит перенормализованные данные.
Вот типичный пример. Это огромное количество урлов. Вы их засунули в соседнюю таблицу. А потом решили с ними делать JOIN, но это работать не будет, как правило, потому что ClickHouse поддерживает только Hash JOIN. Если оперативки не хватает для множества данных, с которыми надо соединять, то JOIN выполнить не получится*.
Если данные большой кардинальности, то не парьтесь, храните их в денормализованном виде, урлы прямо inplace в основной таблице.
* а сейчас в ClickHouse есть и merge join тоже, и он работает в условиях, когда промежуточные данные не помещаются в оперативку. Но это неэффективно и рекомендация остаётся в силе.

Еще парочка примеров, но я уже сомневаюсь антипаттерные они или нет.
В ClickHouse есть один известный недостаток. Он не умеет апдейты*. В некотором смысле это даже хорошо. Если у вас какие-то важные данные, например, бухгалтерия, то никто их отправить не сможет, потому что апдейтов нет.
* уже давно добавлена поддержка update и delete в batch режиме.
Но есть некоторые особенные способы, которые позволяют апдейты как бы в фоне. Например, таблицы типа ReplaceMergeTree. Они делают апдейты во время фоновых merges. Вы можете это форсировать с помощью optimize table. Но не делайте это слишком часто, потому что это будет полной перезаписью партиции.
Распределенные JOIN в ClickHouse – это тоже плохо обрабатывается планировщиком запросов.
Плохо, но иногда Ок.
Использование ClickHouse только для того, чтобы прочитать данные обратно с помощью select*.
Я бы не рекомендовал использовать ClickHouse для громоздких вычислений. Но это не совсем так, потому что мы уже отходим от этой рекомендации. И у нас недавно добавилась возможность применять модели машинного обучения в ClickHouse – Catboost. И это меня беспокоит, потому что я думаю: «Какой ужас. Это сколько же тактов на байт получается!». Мне очень жалко такты на байты пускать.

Но не бойтесь, ставьте ClickHouse, все будет хорошо. Если что, у нас есть сообщество. Кстати, сообщество – это вы. И если у вас какие-то проблемы, вы можете хотя бы зайти в наш чат, и, надеюсь, что вам помогут.
Вопросы
Спасибо за доклад! Куда жаловаться на падение ClickHouse?
Можно жаловаться мне лично прямо сейчас.
Я недавно стал использовать ClickHouse. Сразу уронил cli интерфейс.
Вам повезло.
Чуть позже я уронил сервер маленьким select’ом.
У вас талант.
Я открыл баг GitHub, но его проигнорировали.
Посмотрим.
Алексей обманом затащил меня на доклад, пообещав рассказать, как вы данные внутри жмете.
Очень просто.
Это я еще вчера понял. Больше конкретики.
Там нет никаких хитростей ужасных. Там просто сжатие по блокам. По умолчанию используется LZ4, можно включить ZSTD*. Блоки от 64 килобайт до 1 мегабайта.
* также есть поддержка специализированных кодеков сжатия, которые можно использовать в цепочке с другими алгоритмами.
В блоках просто сырые данные?
Не совсем сырые. Там массивы. Если у вас столбец числовой, то там числа подряд уложены в массив.
Понятно.
Алексей, пример, который был с uniqExact над айпишниками, т. е. то, что uniqExact по строкам дольше считается, чем по числам и так далее. А если мы применим финт ушами и будем кастить в момент вычитки? Т. е. вы, вроде бы сказали, что на диске оно у нас не сильно различается. Если мы будем читать с диска строки, кастить, то тогда быстрее у нас агрегаты будут или нет? Или мы все-таки незначительно здесь выиграем? Мне кажется, что вы это тестировали, но почему-то не указали в бенчмарке.
Я думаю, что оно будет медленнее, чем без каста. В этом случае IP-адрес надо из строки распарсить. У нас, конечно, в ClickHouse парсинг IP-адресов тоже оптимизированный. Мы очень постарались, но там же у вас числа записаны в десятитысячной форме. Очень неудобно. С другой стороны функция uniqExact будет на строках работать медленнее не только потому что это строки, но еще и потому что выбирается другая специализация алгоритма. Строки просто обрабатываются по-другому.
А если взять более примитивный тип данных? Например, записали user id, который у нас in, записали его строчкой, а потом скастили, будет веселее или нет?
Я сомневаюсь. Я думаю, что будет даже грустнее, потому что все-таки парсить числа – это серьезная проблема. Мне кажется, что вот у этого коллеги был даже доклад на тему того, как сложно парсить числа в десятитысячной форме, а, может, и нет.
Алексей, большое спасибо за доклад! И еще большое спасибо за ClickHouse! У меня вопрос на счет планов. Есть ли в планах фича для апдейта словарей не полностью?
Т. е. частичная перезагрузка?
Да-да. Типа возможность задать там поле MySQL, т. е. апдейтить after, чтобы загружались только эти данные, если словарь очень большой.
Очень интересная фича. И, мне кажется, какой-то человек предлагал ее в нашем чате. Может быть, это даже были вы.
Не думаю, что я.
Отлично, теперь получается, что два запроса. И можно не спеша начинать делать. Но сразу вас хочу предупредить, что эта фича довольно простая для реализации. Т. е. по идее нужно просто в таблицу написать номер версии и дальше писать: версия меньше такой-то. А это значит, что, скорее всего, мы предложим это сделать энтузиастам. Вы энтузиаст?
Да, но, к сожалению, не в C++.
Коллеги ваши на C++ умеют писать?
Найду кого-нибудь.
Отлично*.
* возможность была добавлена через два месяца после доклада – её разработал автор вопроса и отправил свой .
Спасибо!
Здравствуйте! Спасибо за доклад! Вы упоминали, что ClickHouse очень хорошо потребляет все ресурсы, доступные ему. И докладчик соседний с Люксофт рассказывал про свое решение для Почты России. Он сказал, что им очень понравился ClickHouse, но они не использовали его вместо своего основного конкурента именно потому, что он сжирал весь процессор. И они не смогли воткнуть его в свою архитектуру, в свой ZooKeeper с докерами. Есть ли возможность как-то ограничить ClickHouse, чтобы он не потреблял все-все, что ему становится доступным?
Да, можно и очень легко. Если хотите, чтобы меньше ядер потреблял, то просто пишите set max_threads = 1. И все, будет в одно ядро выполнять запрос. Причем можно разным пользователям указать разную эту настройку. Так что никаких проблем. И коллегам из Люксофт передайте, что не хорошо, что они не нашли эту настройку в документации.
Алексей, здравствуйте! Хотел бы поинтересоваться таким вопросом. Уже не в первый раз слышу, что многие начинают использовать ClickHouse как хранилище для логов. На докладе вы говорили, чтобы так не делать, т. е. не нужно хранить длинные строки. Как вы к этому относитесь?
Во-первых, логи – это, как правило, не длинные строки. Бывает, конечно, исключения. Например, какой-нибудь сервис, написанный на java, кидают exception, он логируется. И так в бесконечном цикле, и заканчивается место на жестком диске. Решение очень простое. Если строки очень длинные, то режьте их. А что значит длинные? Десятки килобайт – это плохо*.
* в свежих версиях ClickHouse, включена "адаптивная гранулированность индекса", что снимает проблему хранения длинных строк по большей части.
А килобайт – это нормально?
Нормально.
Здравствуйте! Спасибо за доклад! Я уже об этом в чате спрашивал, но не помню, получил ли ответ. Планируется ли как-то расширять секцию WITH на манер CTE?
Пока нет. Секция WITH у нас несколько несерьезная. Она у нас как маленькая фича.
Я понял. Спасибо!
Спасибо за доклад! Очень интересно! Глобальный вопрос. Планируется ли делать, может быть, в виде каких-то заглушек модификацию удаления данных?
Обязательно. Это наша первая задача в нашей очереди. Мы сейчас активно продумали, как все делать правильно. И стоит начинать нажимать на клавиатуру*.
* понажимали кнопки на клавиатуре и всё сделали.
Повлияет ли это как-то на производительность системы или нет? Вставка будет такая же быстрая, как и сейчас?
Возможно, сами deletes, сами updates будут очень тяжелыми, но зато это никак не повлияет на производительность selects и производительность inserts.
И еще маленький вопрос. На презентации вы говорили про primary key. Соответственно, у нас есть партиционирование, которое по умолчанию месячное, правильное? И когда мы задаем диапазон дат, который укладывается в месяц, то у нас считывается только эта партиция, верно?
Да.
Такой вопрос. Если мы не можем выделить какой-нибудь primary key, то правильно ли его делать именно по поле «Дата» для того, чтобы в фоновом режиме была меньшая перестройка этих данных, чтобы они уложились более упорядоченно? Если у вас нет диапазонных запросов и вы даже не можете выбрать никакой первичный ключ, то стоит ли засунуть в первичный ключ дату?
Да.
Может быть, есть смысл положить в первичный ключ такое поле, по которому данные будут лучше сжиматься, если они будут отсортированы по этому полю. Например, идентификатор user’а. User, например, ходит на один и тот же сайт. В этом случае кладете user id и время. И тогда у вас данные будут лучше сжиматься. Насчет даты, если у вас действительно нет и никогда не бывает диапазонных запросов по датам, то можно не класть дату в первичный ключ.
Хорошо, спасибо большое!
Источник: habr.com
