

Сегодня большинство программных продуктов разрабатываются в командах. Условия успеха командной разработки можно представить в виде простой схемы.
Написав код, вы должны убедиться, что он:
- Работает.
- Ничего не ломает, в том числе код, который написали ваши коллеги.
Если оба условия выполняются, то вы на пути к успеху. Чтобы легко проверять эти условия и не сворачивать с выгодного пути, придумали Continuous Integration.
CI — это рабочий процесс, при котором вы как можно чаще интегрируете свой код в общий код продукта. И не просто интегрируете, а еще и постоянно проверяете, что все работает. Так как проверять нужно много и часто, стоит задуматься об автоматизации. Можно все проверять на ручной тяге, но не стоит, и вот почему.
- Люди дорогие. Час работы любого программиста стоит дороже, чем час работы любого сервера.
- Люди ошибаются. Поэтому могут возникнуть ситуации, когда запустили тесты не на той ветке или собрали не тот коммит для тестировщиков.
- Люди ленятся. Периодически, когда я заканчиваю какую-нибудь задачу, у меня возникает мысль: «Да что тут проверять? Я написал две строчки — стопудово все работает!» Думаю, некоторым из вас такие мысли тоже иногда приходят в голову. Но проверять нужно всегда.
Как внедряли и развивали Continuous Integration в команде мобильной разработки Авито, как дошли от 0 до 450 сборок в день, и что билд-машины собирают 200 часов в день, рассказывает Николай Нестеров () — участник всех эволюционных изменений CI/CD Android-приложения.
Рассказ построен на примере Android-команды, но большинство подходов применимы и на iOS тоже.

Когда-то давно в Android-команде Авито работал один человек. Ему по определению ничего из Continuous Integration было не нужно: интегрироваться не с кем.
Но приложение росло, появлялось все больше и больше новых задач, соответственно, росла команда. В какой-то момент пришло время более формально наладить процесс интеграции кода. Было решено использовать Git flow.
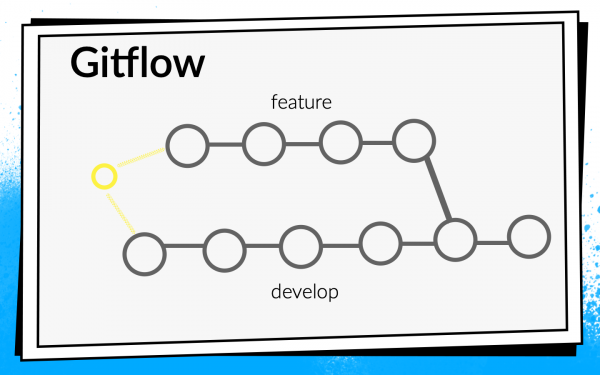
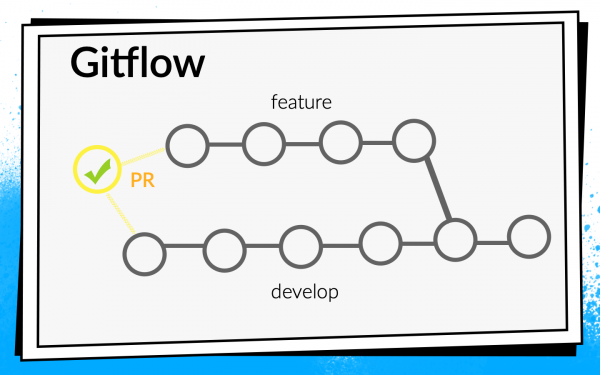
Концепция Git flow известна: в проекте есть одна общая ветка develop, а для каждой новой фичи разработчики срезают отдельную ветку, коммитят в нее, пушат, и, когда хотят влить свой код в ветку develop, открывают pull request. Для обмена знаниями и обсуждения подходов мы ввели code review, то есть коллеги должны проверить и подтвердить код друг друга.
Проверки
Смотреть код глазами — это круто, но недостаточно. Поэтому вводятся автоматические проверки.
- Первым делом проверяем сборку АРК.
- Много Junit-тестов.
- Считаем code coverage, раз уж запускаем тесты.
Чтобы понять, как следует запускать эти проверки, посмотрим на процесс разработки в Авито.
Схематично его можно представить так:
- Разработчик пишет код на своем ноутбуке. Можно запустить проверки интеграции прямо здесь — либо коммит-хуком, либо просто гонять проверки в фоне.
- После того, как разработчик запушил код, он открывает pull request. Чтобы его код попал в ветку develop, необходимо пройти code review и собрать нужное количество подтверждений. Можно включить проверки и билды здесь: пока не все билды успешные, pull request слить нельзя.
- После того, как pull request слит и код попал в develop, можно выбрать удобное время: например, ночью, когда все серверы свободны, и гонять проверки сколько влезет.
Запускать проверки на своем ноутбуке никому не понравилось. Когда разработчик закончил фичу, он хочет побыстрее ее запушить и открыть pull request. Если в этот момент запускаются какие-то долгие проверки, это не только не очень приятно, но и замедляет разработку: пока ноутбук что-то проверяет, на нем невозможно нормально работать.
Запускать проверки ночью нам очень понравилось, потому что времени и серверов много, можно разгуляться. Но, к сожалению, когда код фичи попал в develop, у разработчика уже гораздо меньше мотивации чинить ошибки, которые нашел CI. Я периодически ловил себя на мысли, когда смотрел в утреннем отчете на все найденные ошибки, что починю их когда-нибудь попозже, потому что сейчас в Jira лежит крутая новая задача, которую так и хочется начать делать.
Если проверки блокируют pull request, то мотивации достаточно, потому что пока билды не позеленеют, код не попадет в develop, а, значит, задача не будет завершена.
В итоге мы выбрали такую стратегию: ночью гоняем максимально возможный набор проверок, а самые критичные из них и, самое главное быстрые, запускаем на pull request. Но на этом не останавливаемся — параллельно оптимизируем скорость прохождения проверок так, чтобы перевести их из ночного режима в проверки на pull request.
На тот момент все наши сборки проходили достаточно быстро, поэтому мы просто включили блокером к pull request сборку АРК, Junit-тесты и расчет code coverage. Включили, подумали — и отказались от code coverage, потому что посчитали, что он нам не нужен.
На всю настройку базового CI у нас ушло два дня (здесь и далее временная оценка примерная, нужна для масштаба).
После этого стали думать дальше — а правильно ли мы вообще проверяем? Правильно ли мы запускаем билды на pull request?
Мы запускали сборку на последнем коммите ветки, с которой открыт pull request. Но проверки этого коммита могут показать только то, что тот код, который написал разработчик, работает. Но они не доказывают, что он ничего не сломал. На самом деле нужно проверять состояние ветки develop после того, как в нее будет влита фича.
Для этого мы написали простой bash-скрипт premerge.sh:
#!/usr/bin/env bash
set -e
git fetch origin develop
git merge origin/developЗдесь просто подтягиваются все самые свежие изменения из develop и вливаются в текущую ветку. Мы добавили скрипт premerge.sh первым шагом всех билдов и стали проверять именно то, что мы хотим, то есть интеграцию.
На локализацию проблемы, поиск решения и написание этого скрипта ушло три дня.
Приложение развивалось, задач появлялось все больше, росла команда, и premerge.sh иногда начал нас подводить. В develop проникали конфликтующие изменения, которые ломали сборку.
Пример того, как это происходит:
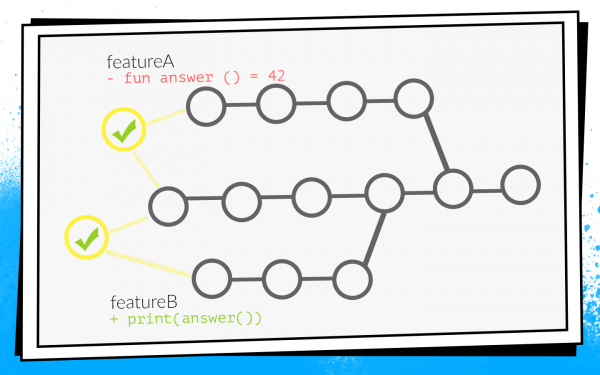
Два разработчика одновременно начинают пилить фичи A и B. Разработчик фичи A обнаруживает в проекте неиспользуемую функцию answer() и, как хороший бойскаут, удаляет ее. При этом разработчик фичи B в своей ветке добавляет новый вызов этой функции.
Разработчики заканчивают работу и в одно и то же время открывают pull request. Запускаются билды, premerge.sh проверяет оба pull request относительно свежего состояния develop — все проверки зеленые. После этого мержится pull request фичи A, мержится pull request фичи B… Бум! Develop ломается, потому что в коде develop есть вызов несуществующей функции.
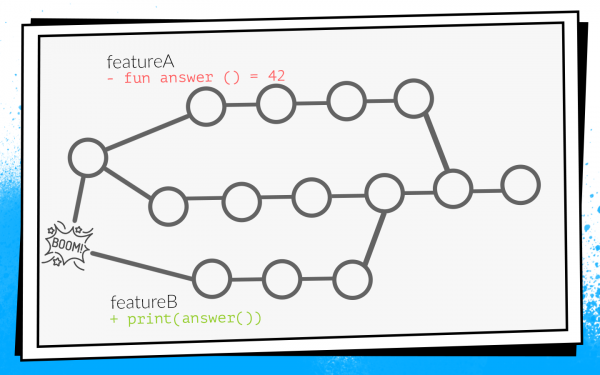
Когда не собирается develop, это локальная катастрофа. Вся команда ничего не может собрать и отдать на тестирование.
Так получилось, что я чаще всего занимался инфраструктурными задачами: аналитика, сеть, базы данных. То есть именно я писал те функции и классы, которые используют другие разработчики. Из-за этого я очень часто попадал в подобные ситуации. У меня даже одно время висела такая картинка.

Поскольку это нас не устраивало, мы начали прорабатывать варианты, как это предотвратить.
Как не ломать develop
Первый вариант: пересобирать все pull request при обновлении develop. Если в нашем примере pull request с фичей A первый попадет в develop, pull request фичи B пересоберется, и, соответственно, проверки не пройдут из-за ошибки компиляции.
Чтобы понять, сколько времени на это уйдет, рассмотрим пример с двумя PR. Открываем два PR: два билда, два запуска проверок. После того, как первый PR влит в develop, второй надо пересобрать. Итого, на два PR уходит три запуска проверок: 2 + 1 = 3.
В принципе, нормально. Но мы посмотрели статистику, и типичной ситуацией в нашей команде было 10 открытых PR, а тогда число проверок — это сумма прогрессии: 10 + 9 +… + 1 = 55. То есть чтобы принять 10 PR, надо пересобрать 55 раз. И это в идеальной ситуации, когда все проверки проходят с первого раза, когда никто не открывает дополнительный pull request, пока обрабатывается этот десяток.
Представьте себя разработчиком, которому нужно успеть нажать на кнопку «merge» первым, потому что если это сделает сосед, то придется ждать, пока все сборки пройдут заново… Нет, так не пойдет, это всерьез замедлит разработку.
Второй возможный способ: собирать pull request после code review. То есть открываете pull request, собираете нужное количество апрувов от коллег, исправляете что нужно, после этого запускаете билды. Если они успешны, pull request сливается с develop. В этом случае дополнительных перезапусков нет, но сильно замедляется обратная связь. Я, как разработчик, открывая pull request, сразу хочу видеть, собирается ли он. Например, если упал какой-то тест, нужно его быстро починить. В случае отложенной сборки замедляется обратная связь, а значит и вся разработка. Нас это тоже не устраивало.
В итоге остался только третий вариант — велосипедить. Весь наш код, все наши исходники хранятся в репозитории в Bitbucket-сервере. Соответственно, нам пришлось разработать плагин для Bitbucket.
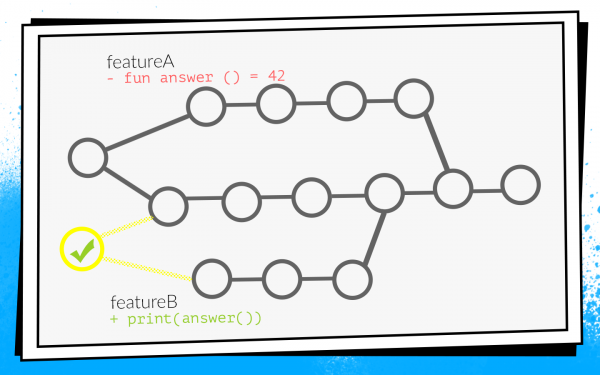
Этот плагин переопределяет механизм слияния pull request’ов. Начало стандартное: открывается PR, запускаются все сборки, проходит code review. Но после того, как code review пройден, и разработчик решает нажать на «merge», плагин проверяет, относительно какого состояния develop запускались проверки. Если после билдов develop успел обновиться, плагин не позволит влить такой pull request в основную ветку. Он просто перезапустит билды относительно свежего develop.
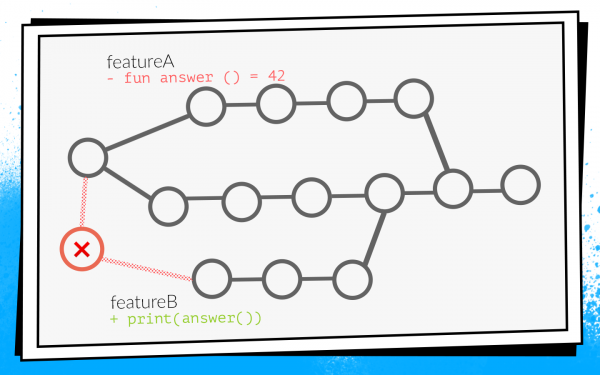
В нашем примере с конфликтующими изменениями такие билды не пройдут из-за ошибки компиляции. Соответственно, разработчику фичи B придется поправить код, перезапустить проверки, тогда плагин автоматически применит pull request.
До внедрения этого плагина у нас в среднем было 2,7 запуска проверки на один pull request. С плагином стало 3,6 запуска. Нас это устроило.
Стоит отметить, что у этого плагина есть недостаток: он перезапускает билд только один раз. То есть все равно остается маленькое окошко, через которое в develop могут попасть конфликтующие изменения. Но вероятность этого невысока, и мы пошли на этот компромисс между количеством запусков и вероятностью поломки. За два года выстрелило только один раз, поэтому, наверное, не зря.
На написание первой версии плагина для Bitbucket у нас ушло две недели.
Новые проверки
Тем временем, наша команда продолжала расти. Добавлялись новые проверки.
Мы подумали: зачем чинить ошибки, если их можно предотвращать? И поэтому внедрили статический анализ кода. Начали с lint, который входит в Android SDK. Но он в то время совсем не умел работать с Kotlin-кодом, а у нас уже 75% приложения было написано на Kotlin. Поэтому к lint добавились встроенные Android Studio checks.
Для этого пришлось сильно извратиться: взять Android Studio, запаковать ее в Docker и запускать на CI с виртуальным монитором, чтобы она думала, что запущена на реальном ноутбуке. Но это работало.
Также в это время мы начали писать много instrumentation тестов и внедрили скриншотное тестирование. Это когда генерируется эталонный скриншот для отдельной маленькой вьюшки, а тест заключается в том, что с вьюшки снимается скриншот и сравнивается с эталоном прямо попиксельно. Если есть расхождение, значит, где-то поехала верстка или что-то не так в стилях.
Но instrumentation тесты и скриншотные тесты нужно запускать на устройствах: на эмуляторах или на реальных девайсах. Учитывая, что тестов много и они гоняются часто, нужна целая ферма. Заводить свою ферму слишком трудозатратно, поэтому мы нашли готовый вариант — Firebase Test Lab.
Firebase Test Lab
Был выбран, потому что Firebase — продукт Google, то есть должен быть надежным и вряд ли когда-нибудь умрет. Цены демократичные: 5$ за час работы реального устройства, 1$ за час работы эмулятора.
На внедрение Firebase Test Lab в наш CI ушло примерно три недели.
Но команда продолжала расти, и Firebase нас, к сожалению, начал подводить. На тот момент у него не было никакого SLA. Иногда Firebase заставлял ждать, пока освободится нужное количество девайсов для тестов, а не начинал их выполнять тут же, как мы этого хотели. Ожидание в очереди занимало до получаса, а это очень долго. Instrumentation тесты гонялись на каждом PR, задержки очень замедляли разработку, а потом еще пришел счет за месяц с круглой суммой. В общем, решено было отказаться от Firebase и пилить in-house, раз уж команда достаточно выросла.
Docker + Python + bash
Взяли docker, запихнули в него эмуляторы, написали простую программку на Python, которая в нужный момент поднимает нужное количество эмуляторов в нужной версии а когда надо их останавливает. И, конечно, пару bash-скриптов — куда же без них?
На создание собственной тестовой среды ушло пять недель.
В результате на каждый pull request приходился обширный, блокирующий слияние, список проверок:
- Сборка АРК;
- Junit-тесты;
- Lint;
- Android Studio checks;
- Instrumentation тесты;
- Screenshot тесты.
Это предотвращало много возможных поломок. Технически все работало, но разработчики жаловались, что ждать результатов слишком долго.
Слишком долго — это сколько? Мы выгрузили данные из Bitbucket и TeamCity в систему анализа и поняли, что среднее время ожидания 45 минут. То есть разработчик, открывая pull request в среднем ждет результаты билдов 45 минут. На мой взгляд, это очень много, и так работать нельзя.
Конечно, мы решили ускорить все наши билды.
Ускоряемся
Увидев, что часто билды стоят в очереди, мы первым делом докупили железа — экстенсивное развитие самое простое. Билды перестали стоять в очереди, но время ожидания снизилось только чуть-чуть, потому что некоторые проверки сами по себе гонялись очень долго.
Убираем слишком долгие проверки
Наш Continuous Integration мог отловить такие типы ошибок и проблем.
- Не собирается. CI может поймать ошибку компиляции, когда из-за конфликтующих изменений что-то не собирается. Как я уже говорил, тогда никто ничего не может собрать, разработка встает, и все нервничают.
- Баг в поведении. Например, когда приложение собирается, но при нажатии на кнопку падает, или кнопка вообще не нажимается. Это плохо, потому что такой баг может добраться до пользователя.
- Баг в верстке. Например, кнопка нажимается, но съехала на 10 пикселей влево.
- Увеличение техдолга.
Посмотрев на этот список, мы поняли, что критичными являются только первые два пункта. Такие проблемы мы хотим отлавливать в первую очередь. Баги в верстке обнаруживаются на этапе design-review и тогда же легко исправляются. Работа с техдолгом требует отдельного процесса и планирования, поэтому мы решили не проверять его на pull request.
Исходя из этой классификации, мы перетряхнули весь список проверок. Вычеркнули Lint и перенесли его запуск на ночь: просто чтобы он выдавал отчет, сколько проблем в проекте. С техдолгом мы условились работать отдельно, а от Android Studio checks отказались совсем. Android Studio в Docker для запуска инспекций звучит интересно, но доставляет много неприятностей в поддержке. Любое обновление версий Android Studio — это борьба с непонятными багами. Так же сложно было поддерживать скриншотные тесты, потому что библиотека работала не очень стабильно, бывали ложные срабатывания. Скриншотные тесты убрали из списка проверок.
В итоге у нас остались:
- Сборка АРК;
- Junit-тесты;
- Instrumentation tests.
Gradle remote cache
Без тяжёлых проверок всё стало лучше. Но нет предела совершенству!
Наше приложение уже было разбито на примерно 150 gradle модулей. Обычно в таком случае хорошо работает Gradle remote cache, и мы решили его попробовать.
Gradle remote cache — это сервис, который может кэшировать артефакты сборки для отдельных задач в отдельных модулях. Gradle, вместо того чтобы реально компилировать код, по HTTP стучится в remote cache и спрашивает, выполнял ли кто-то уже эту таску. Если да, просто скачивает результат.
Запустить Gradle remote cache легко, потому что Gradle предоставляет Docker-образ. Нам удалось это сделать за три часа.
Всего-то надо было запустить Docker и прописать одну строчку в проекте. Но хотя запустить его можно быстро, чтобы все работало хорошо, потребуется достаточно много времени.
Ниже график cache misses.
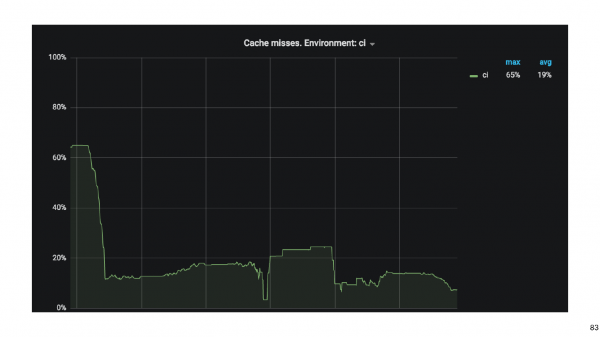
В самом начале процент промахов мимо кеша был около 65. Через три недели удалось довести это значение до 20%. Оказалось, что таски, которые собирает Android приложение, имеют странные транзитивные зависимости, из-за которых Gradle промахивался мимо кэша.
Подключив кэш, мы сильно ускорили сборку. Но кроме сборки еще гоняются instrumentation тесты, а гоняются они долго. Возможно, не все тесты надо гонять на каждый pull request. Чтобы это выяснить, используем импакт анализ.
Импакт анализ
На pull request мы собираем git diff и находим измененные Gradle модули.
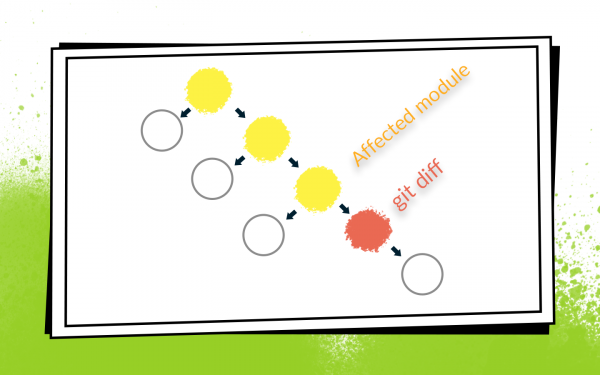
Имеет смысл запускать только те instrumentation тесты, которые проверяют измененные модули и все модули, которые от них зависят. Тесты для соседних модулей запускать смысла нет: там не изменился код, и ничего не может сломаться.
С instrumentation тестами не всё так просто, потому что они должны находиться в самом верхнеуровневом модуле Application. Мы применили эвристику с анализом байт-кода, чтобы понять, к какому модулю относится каждый тест.
Модернизация работы instrumentation тестов, чтобы они проверяли только задействованные модули, заняла около восьми недель.
Меры по ускорению проверок успешно сработали. С 45 минут мы дошли примерно до 15. Четверть часа ждать билд уже нормально.
Но теперь разработчики начали жаловаться, что им непонятно, какие билды запускаются, где лог посмотреть, почему билд красный, какой тест упал и т.д.
Проблемы с обратной связью замедляют разработку, поэтому мы постарались обеспечить максимально понятную и подробную информацию о каждом PR и билде. Начали с комментариев в Bitbucket к PR с указанием, какой билд упал и почему, писали адресные сообщения в Slack. В конце концов сделали для страницы PR dashboard со списком всех билдов, которые сейчас запускаются и их состоянием: в очереди, запускается, упал или завершился. Можно кликнуть на билд и попасть на его лог.
На подробную обратную связь было затрачено шесть недель.
Планы
Переходим к новейшей истории. Решив вопрос обратной связи, мы вышли на новый уровень — решили построить свою ферму эмуляторов. Когда тестов и эмуляторов много, ими сложно управлять. В итоге все наши эмуляторы переехали в k8s-кластер с гибким управлением ресурсов.
Кроме того, есть и другие планы.
- Вернуть Lint (и другой статический анализ). Мы уже работаем в этом направлении.
- Запускать на PR блокером все end-to-end тесты на всех версиях SDK.
Итак, мы проследили историю развития Continuous Integration в Авито. Теперь хочу дать несколько советов с точки зрения бывалого.
Советы
Если бы я мог дать только один совет, это был бы этот:
Пожалуйста, будьте осторожнее с shell-скриптами!
Bash — очень гибкий и мощный инструмент, на нем очень удобно и быстро писать скрипты. Но с ним можно попасть в ловушку, и мы, к сожалению, в нее попали.
Начиналось все с простых скриптов, которые запускались на наших билд-машинах:
#!/usr/bin/env bash
./gradlew assembleDebugНо, как известно, все со временем развивается и усложняется — давайте запустим один скрипт из другого, давайте передадим туда какие-то параметры — в итоге пришлось написать функцию, которая определяет, на каком уровне вложенности bash мы сейчас находимся, чтобы подставить нужные кавычки, чтобы это все запустилось.

Можете представить себе трудозатраты на развитие таких скриптов. Советую не попадать в эту ловушку.
Чем можно заменить?
- Любым скриптовым языком. Писать на Python или Kotlin Script удобнее, потому что это программирование, а не скрипты.
- Или описать всю логику билдов в виде Custom gradle tasks для вашего проекта.
Мы решили выбрать второй вариант, и сейчас планомерно удаляем все bash-скрипты и пишем много кастомных gradle-тасок.
Совет №2: хранить инфраструктуру в коде.
Удобно, когда настройка Continuous Integration хранится не в UI-интерфейсе Jenkins или TeamCity и т.п., а в виде текстовых файлов прямо в репозитории проекта. Это дает версионируемость. Будет не трудно откатиться или собрать код на другой ветке.
Скрипты можно хранить в проекте. А что делать с окружением?
Совет №3: с окружением может помочь Docker.
Android-разработчикам он точно поможет, iOS пока нет, к сожалению.
Это пример простого docker-файла, который содержит в себе jdk и android-sdk:
FROM openjdk:8
ENV SDK_URL="https://dl.google.com/android/repository/sdk-tools-linux-3859397.zip"
ANDROID_HOME="/usr/local/android-sdk"
ANDROID_VERSION=26
ANDROID_BUILD_TOOLS_VERSION=26.0.2
# Download Android SDK
RUN mkdir "$ANDROID_HOME" .android
&& cd "$ANDROID_HOME"
&& curl -o sdk.zip $SDK_URL
&& unzip sdk.zip
&& rm sdk.zip
&& yes | $ANDROID_HOME/tools/bin/sdkmanager --licenses
# Install Android Build Tool and Libraries
RUN $ANDROID_HOME/tools/bin/sdkmanager --update
RUN $ANDROID_HOME/tools/bin/sdkmanager "build-tools;${ANDROID_BUILD_TOOLS_VERSION}"
"platforms;android-${ANDROID_VERSION}"
"platform-tools"
RUN mkdir /application
WORKDIR /application
Написав этот docker-файл (скажу по секрету, его можно не писать, а стянуть готовый с GitHub) и собрав образ, вы получаете виртуальную машину, на которой cможете собирать приложение и запускать Junit-тесты.
Два главных аргумента, почему это имеет смысл: масштабируемость и повторяемость. С использованием docker можно быстро поднять десяток билд-агентов, которые будут иметь точно такое же окружение, как и прежний. Это очень облегчает жизнь CI-инженеров. Запихнуть android-sdk в docker совсем просто, с эмуляторами чуть-чуть сложнее: придется немного поднапрячься (ну, или опять с GitHub скачать готовое).
Совет №4: не забывать, что проверки делаются не ради проверок, а для людей.
Разработчикам очень важна быстрая и, самое главное, понятная обратная связь: что у них сломалось, какой тест упал, где билдлог посмотреть.
Совет №5: будьте прагматичны при развитии Continuous Integration.
Четко понимайте, какие типы ошибок хотите предотвратить, сколько готовы потратить ресурсов, времени, машинного времени. Слишком долгие проверки можно, например, перенести на ночь. А от тех из них, которые ловят не очень важные ошибки, совсем отказаться.
Совет №6: пользуйтесь готовыми инструментами.
Сейчас есть много компаний, которые предоставляют облачный CI.

Для маленьких команд это хороший выход. Не нужно ничего поддерживать, просто платите немного денег, собираете свое приложение и даже гоняете instrumentation tests.
Совет №7: в большой команде выгоднее in-house решения.
Но рано или поздно, с ростом команды станут выгоднее in-house решения. C этими решениями есть один момент. В экономике есть закон убывающей отдачи: в любом проекте каждое следующее улучшение дается все труднее, требует все больше и больше инвестиций.
Экономика описывает всю нашу жизнь, в том числе Continuous Integration. Я построил график трудозатрат на каждый этап развития нашего Continuous Integration.
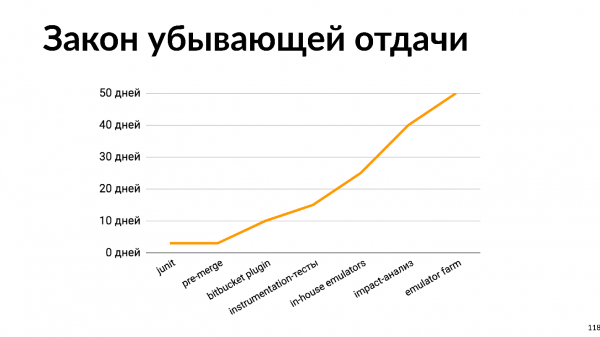
Видно, что любое улучшение дается все труднее и труднее. Глядя на этот график, можно понять, что развивать Continuous Integration нужно согласованно с ростом размера команды. Для команды из двух человек тратить 50 дней на разработку внутренней фермы эмуляторов — так себе идея. Но при этом для большой команды совсем не заниматься Continuous Integration — тоже плохая идея, потому что на проблемы интеграции, починку коммуникации и т.п. уйдет еще больше времени.
Мы начали с того, что автоматизация нужна, потому что люди дорогие, они ошибаются и ленятся. Но автоматизируют тоже люди. Поэтому все эти же проблемы относятся и к автоматизации.
- Автоматизировать дорого. Вспомните график трудозатрат.
- При автоматизации люди ошибаются.
- Автоматизировать иногда очень лень, потому что и так все работает. Зачем еще что-то улучшать, зачем весь этот Continuous Integration?
Но у меня есть статистика: в 20% сборок ловятся ошибки. И это происходит не потому, что наши разработчики плохо пишут код. Это потому, что разработчики уверены, что, если они допустят какую-то ошибку, она не попадет в develop, ее поймают автоматизированные проверки. Соответственно, разработчики могут тратить больше времени на написание кода и интересные штуки, а не локально что-то гонять и проверять.
Занимайтесь Continuous Integration. Но в меру.
Кстати, Николай Нестеров не только сам делает классные доклады, а еще входит в программный комитет и помогает другим готовить для вас содержательные выступления. Полноту и полезность программы ближайшей конференции можно оценить по темам в . А за подробностями приходите 22-23 апреля в Инфопространство.
Источник: habr.com
