

Летом традиционно снижается и покупательская активность, и интенсивность изменения инфраструктуры веб-проектов, говорит нам Капитан Очевидность. Просто потому что даже айтишники, случается, ходят в отпуск. И CТО тоже. Тем тяжелее тем, кто остаётся на посту, но сейчас не об этом: возможно, именно поэтому лето — лучший период для того, чтобы не торопясь обдумать существующую схему резервирования и составить план по её улучшению. И в этом вам будет полезен опыт Егора Андреева из , о котором он рассказал на конференции .
При строительстве резервных площадок, при резервировании есть несколько ловушек, в которые можно попасть. А попадаться в них совершенно нельзя. И губит нас во всем этом, как и во многом другом, перфекционизм и… лень. Мы пытаемся сделать всё-всё-всё идеально, а идеально делать не нужно! Нужно делать только определённые вещи, но сделать их правильно, довести до конца, чтоб они нормально работали.
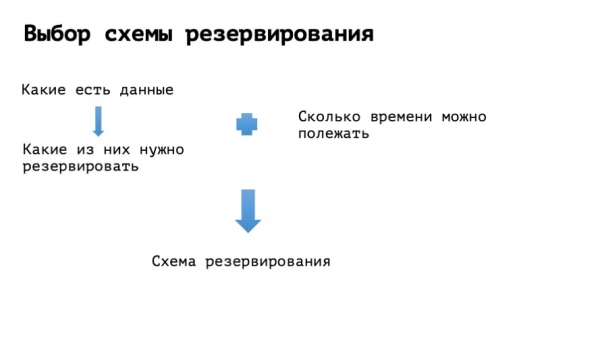
Failover — это не какая-то такая весёлая фановая штука «чтоб было»; это вещь, которая должна сделать ровно одно — уменьшить время простоя, чтобы сервис, компания, теряла меньше денег. И во всех методах резервирования я предлагаю думать в следующем контексте: где деньги?

Первая ловушка: когда мы строим большие надёжные системы и занимаемся резервированием — мы уменьшаем число аварий. Это страшное заблуждение. Когда мы занимаемся резервированием, число аварий мы, скорее всего, повышаем. И если мы сделаем всё правильно, то совокупно мы время простоя уменьшим. Аварий будет больше, но они будут происходить с меньшими издержками. Ведь что такое резервирование? — это усложнение системы. Любое усложнение — это плохо: у нас появляется больше винтиков, больше шестерёнок, словом, больше элементов — и, следовательно, выше шанс на поломку. И они действительно разломаются. И будут ломаться чаще. Простой пример: скажем, у нас есть некий сайт, с PHP, MySQL. И его срочно нужно зарезервировать.
Штош (с) Берём вторую площадку, строим идентичную систему… Сложность становится в два раза больше — у нас две сущности. А ещё мы сверху накатываем определённую логику переноса данных с одной площадки на другую — то есть репликация данных, копирование статики и так далее. Так вот, логика репликации — она обычно очень сложная, и стало быть, совокупная сложность системы может быть не в 2, а 3, 5, 10 раз больше.
Вторая ловушка: когда мы строим по-настоящему большие сложные системы, мы фантазируем, что же хотим получить в итоге. Вуаля: мы хотим получить супернадёжную систему, которая работает вообще без простоя, переключается за полсекунды (а лучше вообще мгновенно), и начинаем воплощать мечты в реальность. Но здесь тоже есть нюанс: чем меньше желаемое время переключения, тем более сложной получается логика системы. Чем сложнее нам придётся делать эту логику, тем чаще система будет ломаться. И можно попасть в очень неприятную ситуацию: мы всеми силами пытаемся время простоя уменьшить, а на самом деле мы всё усложняем, и когда что-то идёт не так, время простоя в итоге будет больше. Тут зачастую ловишь себя на мысли: вот… лучше б не резервировали. Лучше б оно одно работало и с понятным временем простоя.
Как можно с этим бороться? Надо перестать себе врать, перестать себе льстить, что мы тут сейчас будем строить космолёт, но адекватно понимать, сколько проект может полежать. И под это максимальное время мы будем выбирать, какими, собственно, методами будем повышать надёжность нашей системы.
Самое время для «историй из ж»… из жизни, конечно же.
Пример номер один
Представьте сайт-визитку трубопрокатного завода №1 города N. На ней написано огромными буквами — ТРУБОПРОКАТНЫЙ ЗАВОД №1. Чуть ниже — слоган: «Наши трубы — самые круглые трубы в N». И снизу номер телефона генерального директора и его имя. Понимаем, что нужно резервировать — это ж очень важная штука! Начинаем разбираться, из чего состоит. Html-статика — то есть пара картиночек, где генеральный, собственно, за столом в бане со своим партнером обсуждают какую-то очередную сделку. Начинаем думать про время простоя. В голову приходит: лежать там нужно пять минут, не больше. И тут вопрос: а сколько с этого нашего сайта было продаж вообще? Сколько-сколько? Что значит «ноль»? А то и значит: потому что все четыре сделки за прошлый год генеральный сделал за тем же столом, с теми же людьми, с которыми они ходят в баню сидят за столом. И понимаем, что даже если день полежит сайт — страшного не будет ничего.
Исходя из вводных, есть день на поднятие этой истории. Начинаем думать про схему резервирования. И выбираем самую идеальную схему для резервирования для данного примера: мы резервирование не используем. Вот эта вся штука поднимается любым админом за полчаса с перекурами. Поставить веб-сервер, положить файлы — всё. Оно заработает. Ни за чем не нужно следить, ничему не нужно уделять особого внимания. То есть вывод из примера номер один довольно очевидный: сервисы, которые резервировать не нужно — резервировать не нужно.

Пример номер два
Блог компании: специально обученные пишут туда новости, вот мы поучаствовали в такой-то выставке, а вот мы выпустили еще новый продукт и так далее. Допустим, это стандартный PHP с WordPress, небольшая база данных и чуть-чуть статики. В голову, конечно, опять приходит, что лежать ни в коем случае нельзя — «не больше пяти минут!», вот это всё. Но давайте подумаем дальше. Что этот блог делает? Туда приходят из Яндекса, из Гугла по каким-то запросам, по органике. Здорово. А продажи как-то вообще с ним связаны? Прозрение: не особо. Рекламный трафик идёт на основной сайт, который на другой машине. Начинаем думать про схему резервирования бложека. По-хорошему, за пару часов его нужно поднять, и к этому было бы неплохо подготовиться. Разумным будет взять в другом дата-центре машину, на нее вкатить окружение, то есть веб-сервер, PHP, WordPress, MySQL, и оставить это лежать притушенным. В момент, когда мы понимаем, что всё сломалось, нужно сделать две вещи — раскатать дамп mysql на 50 метров, он пролетит там за минуту, и раскатать там какое-то количество картинок из бэкапа. Это тоже там не бог весть сколько. Таким образом, за полчаса вся эта штука поднимается. Никаких репликаций, или прости господи, автоматического failover’a. Вывод: то, что мы можем быстро раскатать из бэкапа — резервировать не нужно.

Пример номер три, посложнее
Интернет-магазин. PhP с open heart немножко подпиленный, mysql с солидной базой. Довольно много статики (ведь в интернет-магазине есть красивые HD-картиночки и всё такое прочее), Redis для сессии и Elasticsearch для поиска. Начинаем думать про время простоя. И тут, конечно, очевидно, что день безболезненно интернет-магазин валяться не может. Ведь чем дольше он лежит, тем больше денег мы теряем. Стоит ускориться. А насколько? Полагаю, если мы час полежим, то никто с ума не сойдет. Да, мы что-то потеряем, но начнём усердствовать — будет только хуже. Определяем схему простоя, допустимого в час.
Как это все можно зарезервировать? Машина нужна в любом случае: час времени — это довольно мало. Mysql: тут уже нужна репликация, живая репликация, потому что за час 100 гб в дамп, скорее всего, не вольётся. Статика, картиночки: опять же, за час 500 гб может не успеть влиться. Стало быть, лучше сразу картиночки копировать. Redis: вот тут интереснее. В Redis сессии лежат — просто взять и похоронить мы его не можем. Потому что это будет не очень хорошо: все пользователи окажутся разлогиненными, корзины очищенными и так далее. Люди будут вынуждены заново вводить свой логин и пароль, и много народу может отколоться и покупку не завершить. Опять же, конверсия упадет. С другой стороны, Redis прям один в один актуальный, с последними залогинившимися пользователями, наверное, тоже не нужен. И хороший компромисс — взять Redis и восстановить его из бэкапа, вчерашнего, либо, если он у вас каждый час делается, — часовой давности. Благо восстановление его из бэкапа — это копирование одного файла. А самая интересная история — это Elasticsearch. Кто когда-либо поднимал репликацию MySQL? Кто когда-нибудь поднимал репликацию Elasticsearch? И у кого она после работала нормально? Я к чему: видим в нашей системе некую сущность. Она вроде как полезная — но она сложная.
Сложная в том смысле, что у наших коллег-инженеров нет опыта работы с ней. Либо есть негативный опыт. Либо мы понимаем, что пока это довольно новая технология с нюансами или сыростью. Думаем… Блин, elastic тоже здоровый, его из бэкапа тоже долго восстанавливать, что делать? Понимаем, что elastic в нашем этом случае используется для поиска. А как продаёт наш интернет-магазин? Идём к маркетологам, спрашиваем, вообще откуда люди приходят. Они отвечают: «90% из Яндекс-маркета приходят прямо в карточку товара». И либо покупают, либо нет. Следовательно, поиск нужен 10% пользователей. А держать репликацию elastic’a, особенно между разными дата-центрами в разных зонах, — там, действительно, много нюансов. Какой выход? Мы берем elastic на резервированной площадке и ничего с ним не делаем. Если дело затянется, то мы его когда-нибудь потом, возможно, поднимем, но это не точно. Собственно, вывод плюс-минус прежний: сервисы, которые на деньги не влияют, мы, опять же, не резервируем. Чтобы схема оставалась проще.

Пример номер четыре, ещё сложнее
Интегратор: продажи цветов, вызова такси, продажи товаров, в общем, чего угодно. Серьёзная штука, которая работает 24/7 на большое число пользователей. С полноценным интересным стеком, где есть интересные базы, решения, высокая нагрузка, и самое главное, лежать ему больше 5 минут больно. Не только и не столько потому, что люди не купят, а потому что люди увидят, что эта штука не работает, расстроятся и могут вообще второй раз не прийти.
Окей. Пять минут. Что с этим будем делать? В этом случае мы по-взрослому, на все деньги строим настоящую резервную площадку, с репликацией всего и вся, и возможно, даже автоматизируем по максимуму переключение на эту площадку. И в дополнение к этому нужно не забыть сделать одну важную вещь: собственно, написать регламент переключения. Регламент, даже если у вас автоматизировано всё и вся, может быть очень простой. Из серии «запустить вот такой-то сценарий ansible», «в route 53 нажать такую-то галку» и так далее — но это должен быть какой-то точный список из действий.
И вроде все понятно. Репликацию переключить — тривиальная задача, либо она сама переключится. Переписать доменное имя в dns — из той же серии. Беда в том, что когда падает подобный проект, начинается паника, и даже самые сильные, бородатые админы могут быть ей подвержены. Без чёткой инструкции «открой терминал, зайди сюда, адрес у нашего сервера по-прежнему вот такой» срок в 5 минут, отведённых на реанимацию, выдержать сложно. Ну и плюс, когда мы этим регламентом пользуемся, легко отфиксировать какие-то изменения в инфраструктуре, например, — и соответствующим образом изменить регламент.
Ну, а если если система резервирования очень сложная и в какой-то момент мы допустили ошибку, то мы можем уложить и нашу резервную площадку, а вдобавок данные превратить в тыкву на обеих площадках — это будет совсем грустно.

Пример номер пять, полный хардкор
Международный сервис с сотней миллионов пользователей по всему миру. Все таймзоны, какие только есть, highload на максималках, лежать вообще никак нельзя. Минута — и будет грустно. Что делать? Резервировать, опять же, по полной программе. Сделали всё, о чём говорил в предыдущем примере, и ещё чуточку больше. Идеальный мир, и наша инфраструктура — она по всем понятиям девопса IaaC. То есть всё вообще в git, и только кнопку нажимай.
Чего не хватает? Одного — учений. Без них нельзя. Кажется, у нас все идеально, у нас вообще все под контролем. Кнопку нажимаем, всё происходит. Даже если это так — а мы понимаем, что так оно не бывает — наша система взаимодействует с какими-то другими системами. К примеру, это dns от route 53, s3-хранилища, интеграция с какими-то api. Всё предусмотреть в этом умозрительном эксперименте мы не сможем. И пока мы реально не дёрнем рубильник — не узнаем, заработает оно или нет.

На этом, наверное, всё. Не ленитесь и не переусердствуйте. И да пребудет с вами uptime!
Источник: habr.com
