


Мы в Skyeng пользуемся Amazon Redshift, в том числе параллельным масштабированием, поэтому статья Стефана Громолла, основателя dotgo.com, для intermix.io, показалась нам интересной. После перевода — немного нашего опыта от инженера по данным Данияра Белходжаева.
позволяет масштабирование путем добавления новых узлов в кластер. Необходимость справляться с пиковым количеством запросов может привести к избыточному резервированию узлов (over-provisioning). Параллельное масштабирование (Concurrency Scaling), в отличие от добавления новых узлов, наращивает вычислительную мощность по мере необходимости.
Параллельное масштабирование Amazon Redshift дает кластерам Redshift дополнительные мощности для обработки пикового количества запросов. Оно работает путем перенесения запросов на новые «параллельные» кластеры в фоновом режиме. Запросы маршрутизируются на основе конфигурации и правил WLM.
Ценообразование для параллельного масштабирования основывается на кредитной модели с нормой бесплатного пользования. Сверх нормы бесплатных кредитов оплата основывается на времени, когда кластер параллельного масштабирования обрабатывает запросы.
Автор протестировал параллельное масштабирование на одном из внутренних кластеров. В этом посте он расскажет о результатах тестирования и даст советы о том, как начать работу.
Требования к кластеру
Для использования параллельного масштабирования кластер Amazon Redshift должен соответствовать следующим требованиям:
— платформа: EC2-VPC;
— тип узла: dc2.8xlarge, ds2.8xlarge, dc2.large или ds2.xlarge;
— число узлов: от 2 до 32 (кластеры с одним узлом не поддерживаются).
Допустимые типы запросов
Параллельное масштабирование подходит не для всех типов запросов. В первой версии оно обрабатывает только запросы на чтение, которые удовлетворяют трем условиям:
— SELECT-запросы только для чтения (хотя планируется больше типов);
— запрос не ссылается на таблицу со стилем сортировки INTERLEAVED;
— запрос не использует Amazon Redshift Spectrum для ссылки на внешние таблицы.
Для маршрутизации в кластер параллельного масштабирования запрос должен встать в очередь. Кроме того, запросы, подходящие для очереди , не будут выполняться в кластерах параллельного масштабирования.
Очереди и SQA требуют правильной настройки . Мы рекомендуем сначала оптимизировать ваш WLM — это уменьшит потребность в параллельном масштабировании. И это важно, потому что параллельное масштабирование производится бесплатно только в течение определенного количества часов. AWS утверждает, что параллельное масштабирование будет бесплатным для 97% клиентов, что подводит нас к вопросу ценообразования.
Стоимость параллельного масштабирования
Для параллельного масштабирования AWS предлагает кредитную модель. Каждый активный кластер ежечасно накапливает кредиты, до одного часа бесплатных кредитов параллельного масштабирования в день.
Вы платите только тогда, когда использование кластеров параллельного масштабирования превышает сумму кредитов, которые вы получили.
Стоимость рассчитывается по посекундному тарифу по требованию для параллельного кластера, который используется сверх бесплатной нормы. Плата производится только за время выполнения ваших запросов, с минимальной оплатой за одну минуту, каждый раз при активации кластера параллельного масштабирования. Посекундный тариф по требованию вычисляется на основании общих принципов ценообразования , то есть зависит от типа узла и количества узлов в вашем кластере.
Запуск параллельного масштабирования
Параллельное масштабирование запускается для каждой очереди WLM. Перейдите в консоль AWS Redshift и выберите «Workload Management» в левом меню навигации. Выберите группу параметров WLM вашего кластера в следующем раскрывающемся меню.
Вы увидите новый столбец под названием «Concurrency Scaling Mode» (Режим параллельного масштабирования) рядом с каждой очередью. По умолчанию установлено значение «Выключено». Нажмите «Изменить», и вы сможете поменять настройки для каждой очереди.
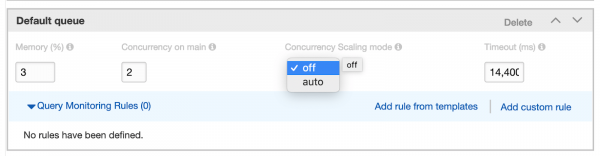
Конфигурация
Параллельное масштабирование работает путем направления соответствующих запросов в новые выделенные кластеры. Новые кластеры имеют тот же размер (тип и количество узлов), что и основной кластер.
Количество кластеров, используемых для параллельного масштабирования, по умолчанию равно одному (1) с возможностью настройки в общей сложности до десяти (10) кластеров.
Общее количество кластеров для параллельного масштабирования может быть установлено параметром max_concurrency_scaling_clusters. Увеличение значения этого параметра обеспечивает дополнительные резервные кластеры.
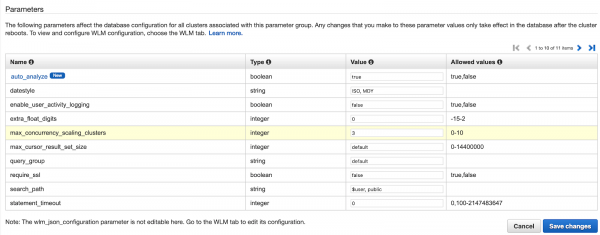
Мониторинг
В консоли AWS Redshift есть несколько дополнительных графиков. Диаграмма «Max Configured Concurrency Scaling Clusters» отображает значение max_concurrency_scaling_clusters с течением времени.

Количество кластеров активного масштабирования отображается в пользовательском интерфейсе в разделе «Concurrency Scaling Activity»:

Во вкладке «Запросы» есть столбец, показывающий, выполнялся ли запрос в основном кластере или в кластере параллельного масштабирования:
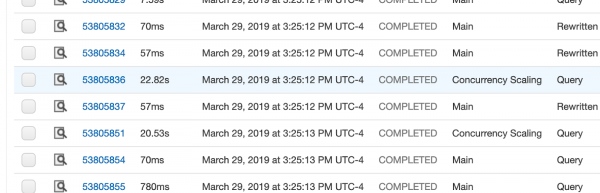
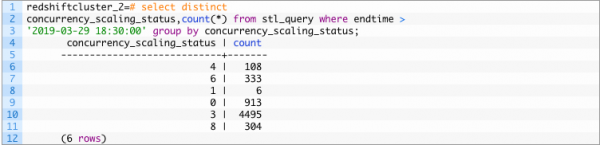
Независимо от того, выполнялся ли конкретный запрос в основном кластере или через кластер параллельного масштабирования, он хранится в stl_query.concurrency_scaling_status.

Значение 1 говорит о том, что запрос выполнялся в кластере параллельного масштабирования, а другие значения говорят о том, что он выполнялся в основном кластере.
Пример:
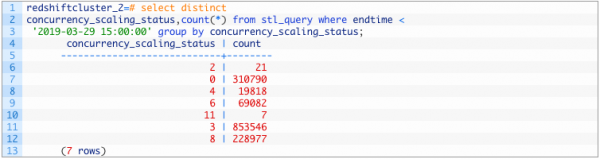
Информация о параллельном масштабировании также хранится в некоторых других таблицах и представлениях (views), например, SVCS_CONCURRENCY_SCALING_USAGE. Кроме того, есть ряд catalog таблиц, в которых хранится информация о параллельном масштабировании.
Результаты
Авторы запустили параллельное масштабирование для одной очереди во внутреннем кластере примерно в 18:30:00 по Гринвичу 29.03.2019 г. Изменили параметр max_concurrency_scaling_clusters на 3 примерно в 20:30:00 29.03.2019 г.
Чтобы смоделировать очередь запросов, и уменьшили количество слотов для этой очереди с 15 до 5.
Ниже приведена диаграмма дэшборда intermix.io, показывающая количество выполняющихся и стоящих в очереди запросов после уменьшения количества слотов.
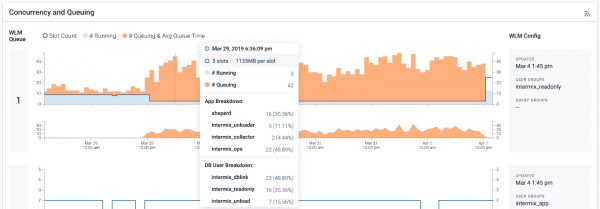
Мы видим, что время ожидания запросов в очереди увеличилось, при этом максимальное время составило более 5 минут.
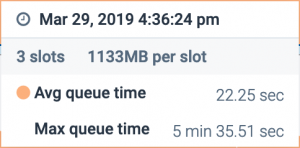
Вот соответствующая информация из консоли AWS о том, что произошло за это время:
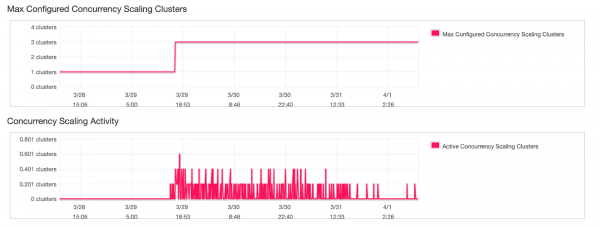
Redshift запустил три (3) кластера параллельного масштабирования в соответствии с настройкой. Похоже, что эти кластеры были использованы не полностью, даже не смотря на то, что многие запросы в нашем кластере стояли в очереди.
График использования коррелирует с графиком активности масштабирования:
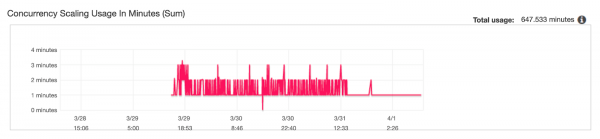
Через несколько часов авторы проверили очередь, и, похоже, 6 запросов выполнялись с параллельным масштабированием. Также выборочно проверили два запроса через пользовательский интерфейс. Не проверяли, как пользоваться этими значениями, когда активны сразу несколько параллельных кластеров.
Выводы
Параллельное масштабирование может уменьшить время нахождения в очереди запросов во время пиковых нагрузок.
По результатам базового теста получилось, что ситуация с загрузкой запросов частично улучшилась. Однако само по себе параллельное масштабирование не решило всех проблем с параллелизмом.
Это связано с ограничениями по типам запросов, которые могут использовать параллельное масштабирование. Например, у авторов есть много таблиц с чередующимися (interleaved) ключами сортировки, и большая часть нашей рабочей нагрузки — это запись.
Хотя параллельное масштабирование и не универсальное решение в настройке WLM, в любом случае пользоваться этой функцией просто и понятно.
Поэтому автор рекомендует использовать ее для ваших WLM-очередей. Начните с одного параллельного кластера и отслеживайте пиковую нагрузку через консоль, чтобы определить, полностью ли используются новые кластеры.
По мере того, как AWS будет добавлять поддержку дополнительных типов запросов и таблиц, параллельное масштабирование постепенно должно становиться все более и более эффективным.
Комментарий от Белходжаева Данияра, инженера по данным Skyeng
Мы в Skyeng тоже сразу обратили внимание на появившуюся возможность параллельного масштабирования.
Функционал очень привлекательный, особенно с учетом того, что по оценке AWS большинству пользователей даже не придется за это доплачивать.Так получилось, что в середине апреля у нас был необычный шквал запросов к кластеру Redshift. В этот период мы часто прибегали к помощи Concurrency Scaling, иногда дополнительный кластер работал по 24 часа в сутки без остановки.
Это позволило если не полностью решить проблему с очередями, то как минимум сделать ситуацию приемлемой.
Наши наблюдения во многом совпадают с впечатлением ребят из intermix.io.
Мы также заметили, что несмотря на наличие запросов ожидающих в очереди, не все запросы сразу перенаправлялись на параллельный кластер. Видимо это происходит из-за того, что параллельный кластер все-таки требует времени для старта. Как результат, во время кратковременных пиковых нагрузок у нас все равно образуются небольшие очереди, и успевают срабатывать соответствующие алармы.
Избавившись от аномальных нагрузок в апреле, мы, как и предполагал AWS, вышли в режим эпизодического использования — в рамках бесплатной нормы.
Отслеживать расходы на параллельное масштабирование можно в AWS Cost Explorer. Нужно выбрать Service — Redshift, Usage Type — CS, например USW2-CS:dc2.large.Подробно о ценах на русском языке можно почитать
Источник: habr.com
