


3. Варианты структур при использовании глобалов
Такая структура как упорядоченное дерево имеет разные частные случаи. Рассмотрим те, которые имеют практическую ценность при работе с глобалами.
3.1 Частный случай 1. Один узел без ветвей
 Глобалы можно использовать не только подобно массиву, но и как обычные переменные. Например как счётчик:
Глобалы можно использовать не только подобно массиву, но и как обычные переменные. Например как счётчик:
Set ^counter = 0 ; установка счётчика
Set id=$Increment(^counter) ; атомарное инкрементированиеПри этом глобал, кроме значения, может ещё иметь ещё и ветви. Одно не исключает второго.
3.2 Частный случай 2. Одна вершина и множество ветвей
Вообще — это классическая key-value база. А если в качестве значения мы будем сохранять кортеж значений, то получим самую обыкновенную таблицу с первичным ключом.
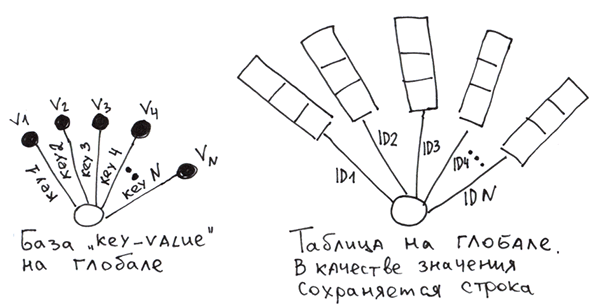
Для реализации таблицы на глобалах нам придётся самим формировать строки из значений колонок, а потом сохранять их в глобал по первичному ключу. Чтобы при считывании было возможно разделить строку опять на колонки можно использовать:
- символы-разделители.
Set ^t(id1) = "col11/col21/col31" Set ^t(id2) = "col12/col22/col32" - жёсткую схему, по которой каждое поле занимает заранее определённое число байт. Как и делается в реляционных БД.
- специальную функцию $LB (есть в Cache), которая составляет строку из значений.
Set ^t(id1) = $LB("col11", "col21", "col31") Set ^t(id2) = $LB("col12", "col22", "col32")
Что интересно, не представляет труда на глобалах сделать нечто подобное вторичным индексам в реляционных БД. Назовём такие структуры индексными глобалами. Индексный глобал — это вспомогательное дерево для быстрого поиска по полям, не являющимися составными частями первичного ключа основного глобала. Для его заполнения и использования нужно написать дополнительный код.
Давайте создадим индексный глобал по первой колонке.
Set ^i("col11", id1) = 1
Set ^i("col12", id2) = 1Теперь для быстрого поиска информации по первой колонке нам предстоит заглянуть в глобал ^i и найти первичные ключи (id) соответствующие нужному значению первой колонки.
При вставке значения мы можем сразу создавать и значение и индексные глобалы по нужным полям. А для надёжности обернём всё это в транзакцию.
TSTART
Set ^t(id1) = $LB("col11", "col21", "col31")
Set ^i("col11", id1) = 1
TCOMMITПодробноcти как сделать на M , .
Работать такие таблицы будут также быстро как и в традиционных БД (или даже быстрее), если функции вставки/обновления/удаления строк написать на COS/M и скомпилировать.Это утверждение я проверял тестами на массовых INSERT и SELECT в одну двухколоночную таблицу, в том числе с использованием команд TSTART и TCOMMIT (транзакций).
Более сложные сценарии с конкурентным доступом и параллельными транзакциями не тестировал.
Без использования транзакций скорость инсертов была на миллионе значений 778 361 вставок/секунду.
При 300 миллионов значений — 422 141 вставок/секунду.
При использовании транзакций — 572 082 вставок/секунду на 50М вставок. Все операции проводились из скомпилированного M-кода.
Жёсткие диски обычные, не SSD. RAID5 с Write-back. Процессор Phenom II 1100T.
Для аналогичного тестирования SQL-базы нужно написать хранимую процедуру, которая в цикле будет делать вставки. При тестировании MySQL 5.5 (хранилище InnoDB) по такой методике получал цифры не больше, чем 11К вставок в секунду.
Да, реализация таблиц на глобалах выглядит более сложной, чем в реляционных БД. Поэтому промышленные БД на глобалах имеют SQL-доступ для упрощения работы с табличными данными.
 Вообще, если схема данных не будет часто меняться, скорость вставки некритична и всю базу можно легко представить в виде нормализованных таблиц, то проще работать именно с SQL, так как он обеспечивает более высокий уровень абстракции.
Вообще, если схема данных не будет часто меняться, скорость вставки некритична и всю базу можно легко представить в виде нормализованных таблиц, то проще работать именно с SQL, так как он обеспечивает более высокий уровень абстракции.
 В этом частном случае я хотел показать, что глобалы могут выступать как конструктор для создания других БД. Как ассемблер, на котором можно написать другие языки. А вот примеры, как можно создать на глобалах аналоги
В этом частном случае я хотел показать, что глобалы могут выступать как конструктор для создания других БД. Как ассемблер, на котором можно написать другие языки. А вот примеры, как можно создать на глобалах аналоги
Если нужно создать какую-то нестандартную БД минимальными усилиями, то стоит взглянуть в сторону глобалов.
3.3 Частный случай 3. Двухуровневое дерево, у каждого узла второго уровня фиксированное число ветвей
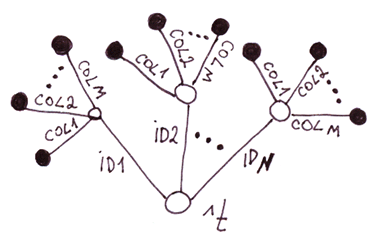 Вы, наверное, догадались: это альтернативная реализация таблиц на глобалах. Сравним эту реализацию с предыдущей.
Вы, наверное, догадались: это альтернативная реализация таблиц на глобалах. Сравним эту реализацию с предыдущей.
Таблицы на двухуровневом дереве vs. на одноуровневом дереве.
Минусы
Плюсы
- Медленнее на вставку, так как нужно устанавливать число узлов равное числу колонок.
- Больше расход дискового пространства. Так как индексы глобала (в понимании как индексы у массивов) с названиями колонок занимают место на диске и дублируются для каждой строки.
- Быстрее доступ к значениям отдельных колонок, так как не нужно парсить строку. По моим тестам быстрее на 11,5% на 2-х колонках и более на большем числе колонок.
- Проще менять схему данных
- Нагляднее код
Вывод: на любителя. Поскольку скорость — одно из самых ключевых преимуществ глобалов, то почти нет смысла использовать эту реализацию, так как она скорее всего будет работать не быстрее таблиц на реляционных базах данных.
3.4 Общий случай. Деревья и упорядоченные деревья
Любая структура данных, которая может быть представлена в виде дерева, прекрасно ложится на глобалы.
3.4.1 Объекты с подобъектами
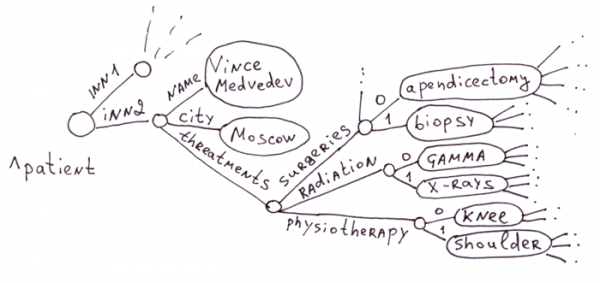
Это область традиционного применения глобалов. В медицинской сфере огромно число болезней, лекарств, симптомов, методов лечения. Создавать на каждого пациента таблицу с миллионом полей нерационально. Тем более, что 99% полей будут пустыми.
Представьте SQL БД из таблиц: «пациент» ~ 100 000 полей, «Лекарство» — 100 000 полей, «Терапия» — 100 000 полей, «Осложнения» — 100 000 полей и т.д. и т.п. Либо можно создать БД из многих тысяч таблиц, каждая под определённый тип пациента (а ведь они могут пересекаться!), лечения, лекарства, и ещё тысячи таблиц для связей между этими таблицами.
Глобалы идеально подошли для медицины, так как позволяют создать для каждого пациента точное описание его истории болезни, различных терапий, действий лекарств, в виде дерева, не тратя при этом лишнее дисковое пространство на пустые колонки, как было бы в реляционном случае.
 На глобалах удобно делать БД с данными о людях, когда важно накопить и систематизировать максимум разнообразной информации о клиенте. Это востребовано в медицине, банковской сфере, маркетинге, архивном деле и других областях
На глобалах удобно делать БД с данными о людях, когда важно накопить и систематизировать максимум разнообразной информации о клиенте. Это востребовано в медицине, банковской сфере, маркетинге, архивном деле и других областях
.
Безусловно, на SQL тоже можно эмулировать дерево всего несколькими таблицами (, ,,,,,,,,,), однако это существенно сложнее и будет медленнее работать. По сути пришлось бы написать глобал работающий на таблицах и спрятать всю работу с таблицами под слоем абстракции. Неправильно эмулировать более низкоуровневую технологию (глобалы) средствами более высокоуровневой (SQL). Нецелесообразно.
Не секрет, что изменение схемы данных на гигантских таблицах (ALTER TABLE) может занять приличное время. MySQL, например, делает ALTER TABLE ADD|DROP COLUMN полным копированием информации из старой в новую таблицу (тестировал движки MyISAM, InnoDB). Что может повесить рабочую базу с миллиардами записей на дни, если не недели.
 Изменение структуры данных, если мы используем глобалы, нам ничего не стоят. В любой момент мы можем добавить любые нужные нам новые свойства к любому объекту, на любом уровне иерархии. Изменения связанные с переименованием ветвей можно запускать в фоновом режиме на работающей БД.
Изменение структуры данных, если мы используем глобалы, нам ничего не стоят. В любой момент мы можем добавить любые нужные нам новые свойства к любому объекту, на любом уровне иерархии. Изменения связанные с переименованием ветвей можно запускать в фоновом режиме на работающей БД.
Поэтому, когда речь идёт о хранении объектов с огромным количеством необязательных свойств, глобалы — отличный выбор.
Причём, напомню, доступ к любому из свойств — моментален, так как в глобале все пути представляют собой B-tree.
Базы данных на глобалах, в общем случае, это разновидность документно-ориентированных БД, со возможностью хранения иерархической информации. Поэтому в сфере хранения медицинских карт с глобалами могут конкурировать документно-ориентированные БД. Но всё равно это не совсем тоВозьмём для сравнения, например, MongoDB. В этой сфере она проигрывает глобалам по причинам:
- Размер документа. Единицей хранения является текст в формате JSON (точнее BSON) максимального объёма около 16МБ. Ограничение сделано специально, чтобы JSON-база не тормозила при парсинге, если в ней сохранят огромный JSON-документ, а потом будут обращаться к нему по полям. В этом документе должна быть сосредоточена вся информация о пациенте. Мы все знаем какими толстыми могут быть карты пациентов. Максимальный размер карты в 16МБ сразу ставит крест на пациентах, в карту болезней которых включены файлы МРТ, сканы ренгенографии и других исследований. В одной ветви глобала же можно иметь информацию на гигабайты и терабайты. В принципе на этом можно поставить точку, но я продолжу.
- Время сознания/изменения/удаления новых свойств в карте пациента. Такая БД должна считать в память всю карту целиком (это большой объём!), распарсить BSON, внести/изменить/удалить новый узел, обновить индексы, запаковать в BSON, сохранить на диск. Глобалу же достаточно только обратиться к конкретному свойству и произвести с ним манипуляции.
- Быстрота доступа к отдельным свойствам. При множестве свойств в документе и его многоуровневой структуре доступ к отдельным свойствам будет быстрее за счёт того, что каждый путь в глобале это B-tree. В BSON же придётся линейно распарсить документ, чтобы найти нужное свойство.
3.3.2 Ассоциативные массивы
Ассоциативные массивы (даже с вложенными массивами) прекрасно ложатся на глобалы. Например такой массив из PHP отобразится в первую картинку 3.3.1.
$a = array(
"name" => "Vince Medvedev",
"city" => "Moscow",
"threatments" => array(
"surgeries" => array("apedicectomy", "biopsy"),
"radiation" => array("gamma", "x-rays"),
"physiotherapy" => array("knee", "shoulder")
)
);3.3.3 Иерархические документы: XML, JSON
Также легко хранятся в глобалах. Для хранения можно разложить разными способами.
XML
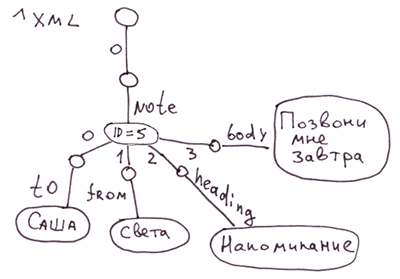
Самый простой способ раскладки XML на глобалы, это когда в узлах храним атрибуты тэгов. А если будет нужен быстрый доступ к аттрибутам тэгов, то мы можем их вынести в отдельные ветви.
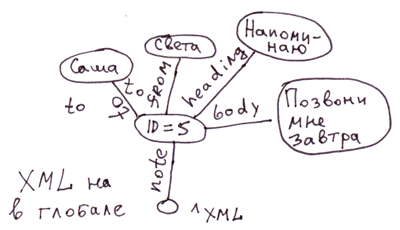
<note id=5>
<to>Вася</to>
<from>Света</from>
<heading>Напоминание</heading>
<body>Позвони мне завтра!</body>
</note>На COS этому будет соответствовать код:
Set ^xml("note")="id=5"
Set ^xml("note","to")="Саша"
Set ^xml("note","from")="Света"
Set ^xml("note","heading")="Напоминание"
Set ^xml("note","body")="Позвони мне завтра!"Замечание: Для XML, JSON, ассоциативных массивов можно придумать много разных способов отображения на глобалах. В данном случае мы не отразили порядок вложенных тэгов в тэге note. В глобале ^xml вложенные тэги будут отображаться в алфавитном порядке. Для строго отражения порядка можно использовать, например, такое отображение:
JSON.
На первой картинке из раздела 3.3.1 показано отражение этого JSON-документа:
var document = {
"name": "Vince Medvedev",
"city": "Moscow",
"threatments": {
"surgeries": ["apedicectomy", "biopsy"],
"radiation": ["gamma", "x-rays"],
"physiotherapy": ["knee", "shoulder"]
},
};3.3.4 Одинаковые структуры, связанные иерархическими отношениями
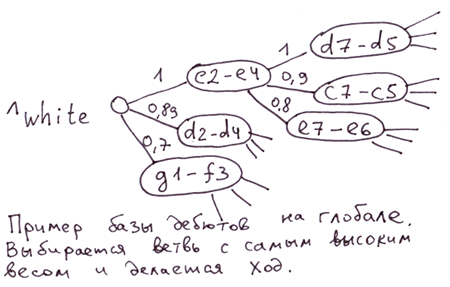
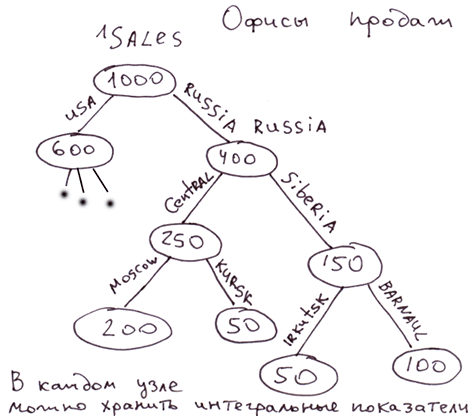
Примеры: структура офисов продаж, расположение людей в МЛМ-структуре, база дебютов в шахматах.
База дебютов. Можно в качестве значения индекса узла глобала использовать оценку силы хода. Тогда, чтобы выбрать самый сильный ход достаточно будет выбрать ветвь с наибольшим весом. В глобале все ветви на каждом уровне будут отсортированы по силе хода.
Структура офисов продаж, структура людей в МЛМ. В узлах можно хранить некие кеширующие значения отражающие характеристики всего поддерева. Например, объём продаж данного поддерева. В любой момент мы можем получить цифру, отражающую достижения любой ветви.
4. В каких случаях наиболее выгодно использовать глобалы
В первой колонке представлены случаи, когда вы получите существенный выигрыш в скорости при использовании глобалов, а во второй когда упростится разработка или модель данных.
Скорость
Удобство обработки/представления данных
- Вставка [с автоматической сортировкой на каждом уровне], [индексированием по главному ключу]
- Удаление поддеревьев
- Объекты с массой вложенный свойств, к которым нужен индивидуальный доступ
- Иерархическая структура с возможностью обхода дочерних ветвей с любой, даже не существующей
- Обход поддеревьев в глубину
- Объекты/сущности с огромным количеством необязательных [и/или вложенных] свойств/сущностей
- Безсхемные данные (schema-less). Когда часто могут появляться новые свойства и исчезать старые.
- Нужно создать нестандартную БД.
- Базы путей и деревья решений. Когда пути удобно представлять в виде дерева.
- Удаление иерархических структур без использования рекурсии
Продолжение .
Disclaimer: данная статья и мои комментарии к ней является моим мнением и не имеют отношения к официальной позиции корпорации InterSystems.
Источник: habr.com
