

Привет, хабровчане. Традиционно продолжаем делиться интересным материалом в преддверии старта новых курсов. Сегодня специально для вас мы превели статью о Google Cloud Spanner, приурочив ее к запуску курса .

Первоначально опубликовано в .
Как компания, которая предлагает множество облачных POS-решений для розничных торговцев, рестораторов и онлайн-продавцов по всему миру, Lightspeed использует несколько различных типов платформ баз данных для множества транзакционных, аналитических и поисковых кейсов. Каждая из этих платформ баз данных имеет свои сильные и слабые стороны.Следовательно, когда Google представил на рынке Cloud Spanner — многообещающие функции, невиданные в мире реляционных баз данных, такие как практически неограниченная горизонтальная масштабируемость и 99,999% соглашение об уровне сервиса (SLA), — мы не могли упустить возможность заполучить ее в наши руки!
Чтобы дать исчерпывающий обзор нашего опыта с Cloud Spanner, а также критериев оценки, которые мы использовали, мы рассмотрим следующие темы:
- Наши критерии оценки
- Cloud Spanner в двух словах
- Наша оценка
- Наши выводы

1. Наши критерии оценки
Прежде чем углубляться в особенности Cloud Spanner, ее сходства и различия с другими решениями на рынке, давайте сначала поговорим об основных юзкейсах, которые мы подразумевали при рассмотрении вопроса о том, где развернуть Cloud Spanner в нашей инфраструктуре:
- В качестве замены (преобладающего) традиционного решения для базы данных SQL
- Как OLTP решение с поддержкой OLAP
Примечание: Для простоты и удобства сравнения эта статья сравнивает Cloud Spanner с MySQL вариантами семейств решений GCP Cloud SQL и Amazon AWS RDS.
Использование Cloud Spanner в качестве замены традиционного решения для базы данных SQL
В среде традиционных баз данных, когда время отклика на запрос к базе данных приближается или даже превышает предварительно определенные пороговые значения приложения (в основном из-за увеличения числа пользователей и/или запросов), существует несколько способов снизить время отклика до приемлемых уровней. Однако большинство из этих решений включают ручное вмешательство.
Например, первый шаг, который нужно предпринять, — это посмотреть на различные параметры базы данных, связанные с производительностью, и настроить их так, чтобы они наилучшим образом соответствовали шаблонам сценариев использования приложений. Если этого окажется недостаточно, можно выбрать масштабирование базы данных по вертикали или по горизонтали.
Вертикальное масштабирование приложения влечет за собой обновление инстанса сервера, обычно путем добавления большего количества процессоров/ядер, большего объема оперативной памяти, более быстрого хранилища и т. д. Добавление большего количества аппаратных ресурсов приводит к увеличению производительности базы данных, измеряемой в основном в транзакциях в секунду, и задержке транзакций для систем OLTP. Системы реляционных баз данных (которые используют многопоточный подход), такие как MySQL, хорошо масштабируются по вертикали.
У этого подхода есть несколько недостатков, но наиболее очевидным является максимальный размер сервера на рынке. Как только достигается предел самого большого инстанса сервера, остается только один путь: горизонтальное масштабирование.
Горизонтальное масштабирование — это подход, при котором в кластер добавляется больше серверов, чтобы в идеале линейно увеличивать производительность с добавлением количества серверов. Большинство традиционных систем баз данных плохо масштабируются по горизонтали или вообще не масштабируются. Например, MySQL может горизонтально масштабироваться для операций чтения, добавляя slave-читателей, но не может горизонтально масштабироваться для операций записи.
С другой стороны, благодаря своей природе Cloud Spanner может легко масштабироваться горизонтально с минимальным вмешательством.
Полнофункциональная СУБД как сервис должна оцениваться с разных сторон. В качестве основы мы взяли самую популярную СУБД в облаке — для Google, GCP Cloud SQL и для Amazon, AWS RDS. В нашей оценке мы сосредоточились на следующих категориях:
- Сопоставлении фич: экстент SQL, DDL, DML; библиотеки подключений/коннекторы, поддержка транзакций и так далее.
- Поддержка разработки: простота разработки и тестирования.
- Поддержка администрирования: управление инстансами — например, масштабирование вверх/вниз и апгрейд инстансов; SLA, резервное копирование и восстановление; безопасность/контроль доступа.
Использование Cloud Spanner в качестве решения OLTP с поддержкой OLAP
Хотя Google явно не утверждает, что Cloud Spanner предназначен для аналитической обработки, он разделяет некоторые атрибуты с другими механизмами, такими как Apache Impala & Kudu и YugaByte, которые предназначены для рабочих нагрузок OLAP.
Даже если бы существовала только небольшая вероятность того, что Cloud Spanner включил в себя согласованный горизонтально масштабируемый движок HTAP (гибридной транзакционной/аналитической обработки) с (более-менее) пригодным для использования набором функций OLAP, мы думаем, что это заслуживало бы нашего внимания.
Имея это в виду, мы рассмотрели следующие категории:
- Загрузка данных, индексы и поддержка партиционирования
- Производительность запросов и DML
2. Cloud Spanner в двух словах
Google Spanner — это кластерная система управления реляционными базами данных (РСУБД), которую Google использует для нескольких своих собственных сервисов. Google сделал ее общедоступной для пользователей Google Cloud Platform в начале 2017 года.
Вот некоторые из атрибутов Cloud Spanner:
- Сильно согласованный масштабируемый кластер РСУБД: использует аппаратную синхронизацию времени для обеспечения согласованности данных.
- Поддержка кросстабличных транзакций: транзакции могут охватывать несколько таблиц — не обязательно ограничиваться одной таблицей (в отличие от Apache HBase или Apache Kudu).
- Таблицы на основе первичного ключа: все таблицы должны иметь объявленный первичный ключ (ПК), который может состоять из нескольких столбцов таблицы. Табличные данные хранятся в порядке ПК, что делает их очень эффективными и быстрыми для поиска по ПК. Как и другие системы на основе ПК, реализация должна быть смоделирована с оглядкой на предварительно продуманные юзкейсы для достижения .
- Чередующиеся таблицы: таблицы могут иметь физические зависимости друг от друга. Строки дочерней таблицы могут быть сопоставлены со строками родительской таблицы. Такой подход ускоряет поиск отношений, которые могут быть определены на этапе моделирования данных, например, при совместном размещении клиентов и их счетов-фактур.
- Индексы: Cloud Spanner поддерживает вторичные индексы. Индекс состоит из проиндексированных столбцов и всех столбцов ПК. При желании индекс также может содержать другие неиндексированные столбцы. Индекс может чередоваться с родительской таблицей для ускорения запросов. К индексам применяются несколько ограничений, например, максимальное количество дополнительных столбцов, хранящихся в индексе. Также запросы через индексы могут быть не такими прямолинейными, как в других РСУБД.
«Cloud Spanner выбирает индекс автоматически только в редких случаях. В частности, Cloud Spanner не выбирает вторичный индекс автоматически, если запрос запрашивает какие-либо столбцы, которые не сохранены в ».
- Соглашение об уровне обслуживания (SLA): развертывание в одном регионе со SLA с 99,99%; мультирегиональные развертывания с 99,999% SLA. Хотя само соглашение об уровне обслуживания является всего лишь соглашением, а не какой-либо гарантией, я полагаю, что у сотрудников Google действительно есть некоторые точные данные, чтобы сделать такое серьезное утверждение. (Для справки, 99,999% означает 26,3 секунды недоступности услуги в месяц.)
- Больше:
Примечание: Проект Apache Tephra добавляет расширенную поддержку транзакций в Apache HBase (также теперь реализован в Apache Phoenix в качестве бета-версии).
3. Наша оценка
Итак, мы все читали заявления Google о преимуществах Cloud Spanner — практически неограниченное горизонтальное масштабирование при сохранении высокой согласованности и очень высокого SLA. Хотя эти требования, во всяком случае, чрезвычайно трудно достичь, нашей целью было не опровергать их. Вместо этого давайте сосредоточимся на других вещах, которые волнуют большинство пользователей баз данных: четность и удобство использования.
Мы оценили Cloud Spanner как замену Sharded MySQL
Google Cloud SQL и Amazon AWS RDS, две наиболее популярные OLTP СУБД на облачном рынке, имеют очень большой набор функций. Однако, чтобы масштабировать эти базы данных за пределы размера одного узла, вам необходимо выполнять разбиение приложений. Такой подход создает дополнительную сложность как для приложений, так и для администрирования. Мы рассмотрели, как Spanner вписывается в сценарий объединения нескольких сегментов в один инстанс и какими функциями (если таковые имеются), возможно, придется пожертвовать.
Поддержка SQL, DML и DDL, а также коннектор и библиотеки?
Во-первых, при запуске с любой базой данных необходимо создавать модель данных. Если вы думаете, что вы можете подключить JDBC Spanner к вашему любимому инструменту SQL, вы обнаружите, что можете запрашивать ваши данные с его помощью, но не можете использовать его для создания таблицы или изменения (DDL) или любых операций вставки/обновления/удаления (DML). Официальный JDBC от Google не поддерживает ни того, ни другого.
«В настоящее время драйверы не поддерживают операторы DML или DDL».
Документация Spanner
С консолью GCP ситуация не лучше — вы можете отправлять только SELECT-запросы. К счастью, существует драйвер JDBC с поддержкой DML и DDL от сообщества, включая транзакции . Хотя этот драйвер чрезвычайно полезен, отсутствие собственного драйвера JDBC от Google вызывает удивление. К счастью, Google предлагает довольно широкую поддержку клиентских библиотек (на основе gRPC): C#, Go, Java, node.js, PHP, Python и Ruby.
Практически обязательное использование пользовательских API-интерфейсов Cloud Spanner (из-за отсутствия DDL и DML в JDBC) приводит к некоторым ограничениям для связанных областей кода, таких как пулы соединений или фреймворки связывания базы данных (например, Spring MVC). Как правило, при использовании JDBC можно свободно выбирать любимый пул соединений (например, HikariCP, DBCP, C3PO и т. д.), который протестирован и хорошо работает. В случае пользовательских API Spanner мы должны полагаться на фреймворки/пулы связывания/сессий, которые мы создали сами.
Конструкция, ориентированная на первичный ключ (ПК), позволяет Cloud Spanner быть очень быстрой при доступе к данным через ПК, но также приводит к некоторым проблемам с запросами.
- Вы не можете обновить значение первичного ключа; Вы должны сначала удалить запись с оригинальным ПК и заново вставить ее с новым значением. (Это похоже на другие ПК ориентированные базы данных/механизмы хранения.)
- Любые операторы UPDATE и DELETE должны указывать ПК в WHERE, следовательно, не может быть пустых операторов DELETE all — всегда должен быть подзапрос, например: UPDATE xxx WHERE id IN (SELECT id FROM table1)
- Отсутствие опции автоинкремента или чего-либо подобного, что задает последовательность для поля ПК. Чтобы это работало, соответствующее значение должно быть создано на стороне приложения.
Вторичные индексы?
Google Cloud Spanner имеет встроенную поддержку вторичных индексов. Это очень приятная особенность, которая не всегда присутствует в других технологиях. Apache Kudu в настоящее время вообще не поддерживает вторичные индексы, а Apache HBase не поддерживает индексы напрямую, но может добавлять их через Apache Phoenix.
Индексы в Kudu и HBase можно моделировать как отдельную таблицу с разным составом первичных ключей, но атомарность операций, выполняемых с родительской таблицей и связанными индексными таблицами, должна выполняться на уровне приложения и не является тривиальной в правильной реализации.
Как упоминалось в обзоре Cloud Spanner, его индексы могут отличаться от индексов MySQL. Таким образом, следует проявлять особую осторожность при построении запросов и профилировании, чтобы обеспечить использование надлежащего индекса там, где он необходим.
Представления?
Очень популярный и полезный объект в базе данных — представления. Они могут полезны для большого количества юзкейсов; два моих фаворита — это уровень логической абстракции и уровень безопасности. К сожалению, Cloud Spanner НЕ поддерживает представления. Однако это лишь частично ограничивает нас, поскольку для разрешений доступа нет детализации на уровне столбцов, где представления могут быть приемлемым решением.
В документации Cloud Spanner в разделе, в котором подробно описываются квоты и ограничения (), есть, в частности, одна, которая может быть проблематичной для некоторых приложений: Cloud Spanner из коробки имеет ограничение в максимум 100 базы данных на инстанс. Очевидно, что это может стать серьезным препятствием для базы данных, которая предназначена для масштабирования на более чем 100 баз данных. К счастью, после разговора с нашим техническим представителем Google мы выяснили, что этот лимит может быть увеличен практически до любого значения через службу поддержки Google.
Поддержка разработки?
Cloud Spanner предлагает довольно приличную поддержку языков программирования для работы с его API. Официально поддерживаемые библиотеки находятся в области C#, Go, Java, node.js, PHP, Python и Ruby. Документация достаточно детализирована, но, как и в случае с другими передовыми технологиями, сообщество довольно небольшое по сравнению с наиболее популярными технологиями баз данных, что может привести к увеличению времени, затрачиваемого на решение менее распространенных случаев использования или проблем.
Итак, как насчет поддержки локальной разработки?
Мы не нашли способ создать инстанс Cloud Spanner в локальной среде. Самым близкое, что мы получили — Docker-образ , что в принципе похоже, но на практике сильно отличается. Например, CockroachDB может использовать PostgreSQL JDBC. Поскольку среда разработки должна быть максимально приближена к рабочей среде, Cloud Spanner не идеален, поскольку нужно полагаться на полный инстанс Spanner. Для экономии затрат вы можете выбрать инстанс для одного региона.
Поддержки администрирования?
Создать инстанс Cloud Spanner очень просто. Нужно просто выбрать между созданием мультирегионального или инстанса для одного региона, указать регион(ы) и количество узлов. Менее чем через минуту инстанс будет запущен и готов к работе.
Несколько элементарных метрик непосредственно доступны на странице Spanner в консоли Google. Более подробные представления доступны через Stackdriver, где вы также можете установить пороговые значения метрик и политики оповещений.
Доступ к ресурсам?
MySQL предлагает обширные и очень детальные настройки разрешений/ролей пользователей. Можно легко настроить доступ к определенной таблице или даже просто к подмножеству ее столбцов. Cloud Spanner использует инструмент Google Identity & Access Management (IAM), который позволяет устанавливать политики и разрешения только на очень высоком уровне. Наиболее детализированный вариант — это разрешение на уровне базы данных, которое не вписывается в большую часть производственных случаев. Это ограничение вынуждает вас добавлять дополнительные меры безопасности в ваш код, инфраструктуру или и то и другое для предотвращения несанкционированного использования ресурсов Spanner.
Резервные копии?
Говоря по простому, резервных копий в Cloud Spanner не существует. Хотя высокие требования Google SLA могут гарантировать, что вы не потеряете какие-либо данные из-за сбоев оборудования или базы данных, от человеческих ошибок, дефектов приложений и т. д. Мы все знаем правило: высокая доступность не заменяет разумную стратегию резервного копирования. На данный момент единственным способом резервного копирования данных является программная потоковая передача их из базы данных в отдельную среду хранения.
Производительность запросов?
Для загрузки данных и тестирования запросов мы использовали Yahoo! Cloud Serving Benchmark. В таблице ниже представлена рабочая нагрузка B YCSB с соотношением чтения 95% и записи 5%.
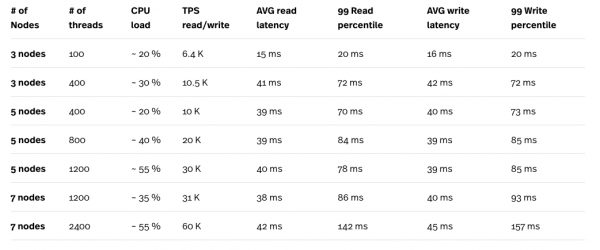
* Нагрузочный тест выполнялся на вычислительном движке (CE) n1-standard-32 (32 vCPU, 120 ГБ памяти), и тестовы инстанс никогда не был узким местом в тестах.
** Максимальное количество потоков в одном экземпляре YCSB составляет 400. Всего нужно было запустить шесть параллельных экземпляров YCSB тестов, чтобы получить в общей сложности 2400 потоков.
Глядя на результаты тестов, в частности сочетание нагрузки на процессор и TPS, мы ясно видим, что Cloud Spanner достаточно хорошо масштабируется. Большая нагрузка, создаваемая большим количеством потоков, компенсируется большим количеством узлов в кластере Cloud Spanner. Хотя задержка выглядит довольно высокой, особенно при работе с 2400 потоками, для получения более точных чисел может потребоваться повторное тестирование с 6 меньшими экземплярами вычислительного движка. Каждый экземпляр будет запускать один тест YCSB вместо одного большого инстанса CE с 6 параллельными тестами. Таким образом, будет легче различить задержки запросов Cloud Spanner и задержки, добавленные сетевым соединением между Cloud Spanner и инстансом CE, на котором выполняется тест.
Как Cloud Spanner справляется в качестве OLAP?
Партиционирование?
Разделение данных на физически и/или логически независимые сегменты, называемые партициями, является очень популярной концепцией, присущей большинству механизмов OLAP. Партиции могут значительно улучшить производительность запросов и поддерживаемость базы данных. Дальнейшее углубление в партиции выплыло бы в отдельную статью (статьи), поэтому давайте просто упомянем о важности наличия схемы партиционирования и sub-партиционирования. Возможность разбивать данные на партиции и даже дальше на подпартиции является ключом к производительности аналитических запросов.
Cloud Spanner не поддерживает партиции как таковые. Он разделяет данные внутри на так называемые split-ы на основе диапазонов первичного ключа. Разделение выполняется автоматически для балансировки нагрузки в кластере Cloud Spanner. Очень удобная функция Cloud Spanner — это разбиение базовой нагрузки родительской таблицы (таблицы, которая не чередуется с другой). Spanner автоматически определяет, содержит ли split данные, которые считываются чаще, чем данные в других split-ах, и может принять решение о дальнейшем разделении. Таким образом, в запросе может быть задействовано больше узлов, что также эффективно увеличивает пропускную способность.
Загрузка данных?
Способ Cloud Spanner для объемных данных такой же, как при обычной загрузке. Для достижения максимальной производительности вам необходимо следовать некоторым рекомендациям, в том числе:
- Сортируйте ваши данные по первичному ключу.
- Разделите их на 10*количество узлов отдельных секций.
- Создайте набор рабочих задач, которые загружают данные параллельно.
При такой загрузке данных используются все узлы Cloud Spanner.
Мы использовали рабочую нагрузку A YCSB для генерации набора данных из 10M строк.
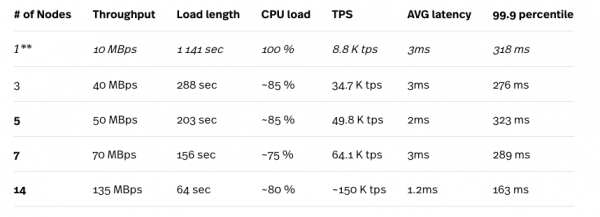
* Нагрузочный тест выполнялся на вычислительном движке n1-standard-32 (32 vCPU, 120 ГБ памяти), и тестовый инстанс никогда не был узким местом в тестах.
** Настройка из 1 узла не рекомендуется для любой производственной нагрузки.
Как упоминалось выше, Cloud Spanner автоматически обрабатывает split-ы в зависимости от их нагрузки, поэтому результаты улучшаются после нескольких последовательных повторов теста. Результаты, представленные здесь, являются лучшими результатами, которые мы получили. Глядя на числа выше, мы можем видеть, как Cloud Spanner (хорошо) масштабируется с увеличением числа узлов в кластере. Цифры, которые выделяются, представляют собой чрезвычайно низкие средние задержки, которые контрастируют с результатами смешанных рабочих нагрузок (95% для чтения и 5% для записи), как описано в разделе выше.
Масштабирование?
Увеличение и уменьшение количества узлов Cloud Spanner — это задача, выполняемая одним кликом. Если вы хотите быстро загрузить данные, вы можете рассмотреть возможность бустинга инстанса до максимума (в нашем случае это было 25 узлов в регионе US-EAST), а затем уменьшить число узлов, подходящих для вашей обычной загрузки, после того как все данные в базе данных, имея в виду ограничение 2 ТБ/узел.
Нам напомнили об этом пределе даже с гораздо меньшей базой данных. После нескольких прогонов нагрузочных тестов наша база данных имела размер около 155 ГБ, а при уменьшении до инстанса из 1 узла мы получили следующую ошибку:
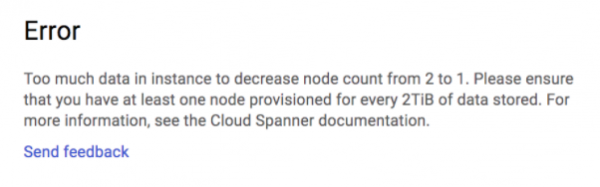
Нам удалось уменьшить масштаб с 25 до 2 инстансов, но мы застряли на двух узлах.
Увеличение и уменьшение количества узлов в кластере Cloud Spanner можно автоматизировать с помощью REST API. Это может быть особенно полезно для уменьшения повышенной нагрузки на систему в часы напряженной работы.
Производительность OLAP запросов?
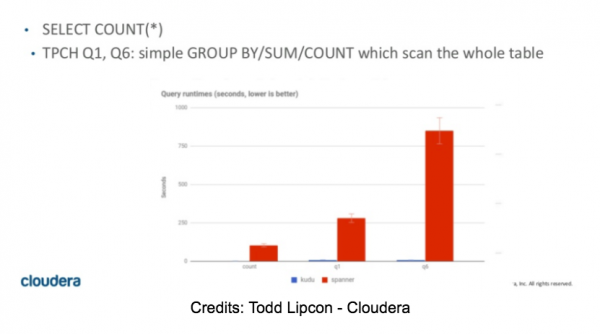
Первоначально мы планировали уделить значительное время нашей оценки Spanner этой части. После нескольких SELECT COUNT мы сразу поняли, что тестирование будет коротким и что Spanner НЕ будет подходящим для OLAP движком. Независимо от количества узлов в кластере, простой выбор количества строк в таблице из 10M строк занял от 55 до 60 секунд. Кроме того, любой запрос, который требовал большего объема памяти для хранения промежуточных результатов, завершился с ошибкой OOM.
SELECT COUNT(DISTINCT(field0)) FROM usertable; — (10M distinct values)-> SpoolingHashAggregateIterator ran out of memory during new row.
Некоторые цифры для TPC-H запросов можно найти в статье Тодда Липкона , слайды 42 и 43. Эти цифры согласуются с нашими собственными результатами (к сожалению).
4. Наши выводы
Учитывая текущее состояние фич Cloud Spanner, трудно представить его простой заменой существующего OLTP-решения, особенно когда ваши потребности перерастут его. Нужно было бы потратить значительное количество времени на то, чтобы построить решение с учетом недостатков Cloud Spanner.
Когда мы начали оценку Cloud Spanner, мы ожидали, что его функции управления будут на уровне или, по крайней мере, не так далеко от других решений Google SQL. Но мы были удивлены полным отсутствием резервных копий и очень ограниченным контролем доступа к ресурсам. Не говоря уже об отсутствии представлений, отсутствии локальной среды разработки, неподдерживаемых последовательностей, JDBC без поддержки DML и DDL и так далее.
Итак, куда же деваться тому, кому нужно масштабировать транзакционную базу данных? Похоже, на рынке пока нет единственного решения, которое бы подходило для всех вариантов использования. Существует множество решений с закрытым и открытым исходным кодом (некоторые из которых упоминаются в этой статье), каждое из которых имеет свои сильные и слабые стороны, но ни одно из них не предлагает SaaS с SLA 99,999% и высокой степенью согласованности. Если высокий уровень SLA является вашей основной целью, и вы не склонны создавать собственное решение для нескольких облачных сред, Cloud Spanner может оказаться тем решением, которое вы ищете. Но вы должны знать обо всех его ограничениях.
Справедливости ради следует отметить, что Cloud Spanner была выпущена для общего доступа только весной 2017 года, поэтому разумно ожидать, что некоторые из его текущих недостатков могут в конечном итоге исчезнуть (надеюсь), и когда это произойдет, это может изменить игру. В конце концов, Cloud Spanner — это не просто сторонний проект для Google. Google использует его в качестве основы для других продуктов Google. А когда Google недавно заменил Megastore в Google Cloud Storage на Cloud Spanner, это позволило Google Cloud Storage стать строго согласованным для списков объектов в мировом масштабе (что по-прежнему не относится к ).
Итак, надежда еще есть… мы надеемся.
На этом все. Как и автор статьи, мы тоже продолжаем надеяться, а что вы думаете по этому поводу? Пишите в комментарии
Всех желающих приглашаем посетить наш в рамках которого подробно расскажем о курсе от OTUS.
Источник: habr.com
