

От редактора блога Google: Интересовались ли вы когда-нибудь тем, как инженеры Google Cloud Technical Solutions (TSE) занимаются вашими обращениями в техподдержку? В сфере ответственности инженеров технической поддержки TSE лежит обнаружение и устранение указанных пользователями источников проблем. Некоторые из этих проблем довольно просты, но иногда попадается обращение, требующее внимания сразу нескольких инженеров. В этой статье один из сотрудников TSE расскажет нам про одну очень заковыристую проблему из своей недавней практики — . В ходе этого рассказа мы увидим, каким образом инженерам удалось разрешить ситуацию, и что нового они узнали в ходе устранения ошибки. Мы надеемся, что эта история не только расскажет вам о глубоко укоренившемся баге, но и даст понимание процессов, проходящих при подаче обращения в поддержку Google Cloud.

Устранение неполадок это одновременно и наука, и искусство. Все начинается с построения гипотезы о причине нестандартного поведения системы, после чего она проверяется на прочность. Однако, прежде чем сформулировать гипотезу, мы должны четко определить и точно сформулировать проблему. Если вопрос звучит слишком расплывчато то вам придется как следует все проанализировать; в этом и заключается «искусство» устранения неполадок.
В условиях Google Cloud подобные процессы усложняются в разы, так как Google Cloud изо всех сил старается гарантировать конфиденциальность своих пользователей. Из-за этого у инженеров TSE нет ни доступа к редактированию ваших систем, ни возможности так же широко обозревать конфигурации, как это делают пользователи. Поэтому для проверки какой либо из наших гипотез мы (инженеры) не можем быстро модифицировать систему.
Некоторые пользователи полагают, что мы исправим все будто механики в автосервисе, и попросту высылают нам id виртуальной машины, тогда как в реальности процесс протекает в формате разговора: сбор информации, формирование и подтверждение (либо опровержение) гипотез, и, в конце концов, решение проблемы строится на общении с клиентом.
Рассматриваемая проблема
Сегодня перед нами история с хорошим концом. Одна из причин успешного разрешения предложенного кейса заключается в очень детальном и точном описании проблемы. Ниже можно увидеть копию первого тикета (отредактированного, с целью скрыть конфиденциальную информацию):
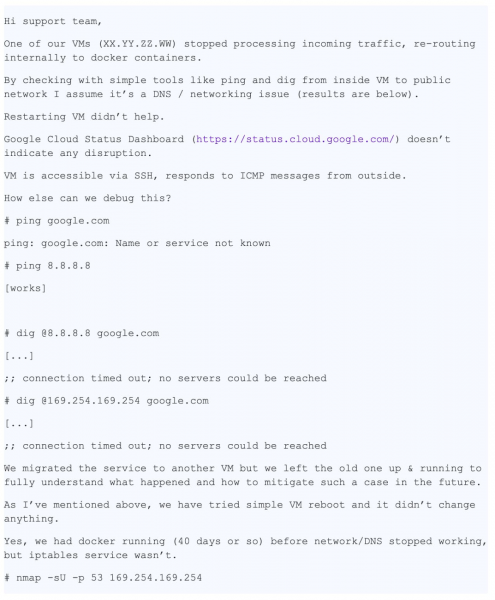
В этом сообщении очень много полезной для нас информации:
- Указана конкретная VM
- Указана сама проблема — не работает DNS
- Указано где проблема себя проявляет — VM и контейнер
- Указаны шаги, которые совершил пользователь для определения проблемы
Обращение было зарегистрировано как «P1: Critical Impact — Service Unusable in production», что означает постоянный контроль ситуации 24/7 по схеме «Follow the Sun» (по ссылке можно подробнее почитать про ), с передачей ее от одной команды техподдержки к другой при каждом сдвиге часовых поясов. По сути, к тому моменту как проблема дошла до нашей команды в Цюрихе, она успела обогнуть земной шар. К этому времени пользователь принял меры по снижению последствий, однако опасался повторения ситуации на продакшне, так как основная причина все еще не была обнаружена.
К моменту, когда тикет дошел до Цюриха, у нас на руках уже была следующая информация:
- Содержимое
/etc/hosts - Содержимое
/etc/resolv.conf - Вывод
iptables-save - Собранный командой
ngrepфайл pcap
С этими данными мы были готовы приступить к этапу «расследования» и устранения неполадок.
Наши первые шаги
В первую очередь мы проверили логи и статус сервера метаданных и убедились что он работает корректно. Сервер метаданных отвечает IP адресу 169.254.169.254 и, кроме всего прочего, отвечает за контроль над именами доменов. Мы так же перепроверили, что файервол корректно работает с VM и не блокирует пакеты.
Это была какая-то странная проблема: проверка nmap опровергла нашу основную гипотезу о потере UDP пакетов, поэтому мы мысленно вывели еще несколько вариантов и способов их проверки:
- Пропадают ли пакеты выборочно? => Проверить правила iptables
- Не слишком ли мал ? => Проверить вывод
ip a show - Затрагивает ли проблема только UDP-пакеты или же и TCP? => Прогнать
dig +tcp - Возвращаются ли сгенерированные dig пакеты? => Прогнать
tcpdump - Корректно ли работает libdns? => Прогнать
straceдля проверки передачи пакетов в обе стороны
Тут мы решаем созвониться с пользователем для устранения неполадок вживую.
В ходе звонка нам удается проверить несколько вещей:
- После нескольких проверок мы исключаем правила iptables из списка причин
- Мы проверяем интерфейсы сети и таблицы маршрутизации, и перепроверяем корректность MTU
- Мы обнаруживаем что
dig +tcp google.com(TCP) работает как надо, но вотdig google.com(UDP) не работает - Прогнав
tcpdumpпока работаетdig, мы обнаруживаем что UDP пакеты возвращаются - Мы прогоняем
strace dig google.comи видим как dig корректно вызываетsendmsg()иrecvms(), однако второй прерывается по таймауту
К несчастью, наступает конец смены и мы вынуждены передать проблему в следующую временную зону. Обращение, тем не менее, вызвало в нашей команде интерес, и коллега предлагает создать исходный DNS пакет питоновским модулем scrapy.
from scapy.all import *
answer = sr1(IP(dst="169.254.169.254")/UDP(dport=53)/DNS(rd=1,qd=DNSQR(qname="google.com")),verbose=0)
print ("169.254.169.254", answer[DNS].summary())Этот фрагмент создает DNS пакет и отправляет запросу серверу метаданных.
Пользователь запускает код, DNS ответ возвращается, и приложение его получает, что подтверждает отсутствие проблемы на уровне сети.
После очередного «кругосветного путешествия» обращение возвращается к нашей команде, и я полностью перевожу его на себя, посчитав, что пользователю будет удобнее, если обращение перестанет кружить с места на место.
Тем временем, пользователь любезно соглашается предоставить снимок образа системы. Это очень хорошие новости: возможность самому тестировать систему значительно ускоряет устранение неполадок, ведь больше не надо просить пользователя запускать команды, высылать мне результаты и анализировать их, я могу все сделать сам!
Коллеги начинают мне понемногу завидовать. За обедом мы обсуждаем обращение, однако ни у кого нет идей о том, что же происходит. К счастью, сам пользователь уже принял меры по смягчению последствий и никуда не спешит, так что у нас есть время препарировать проблему. И так как у нас есть образ, мы можем провести любые интересующие нас тесты. Отлично!
Возвращаясь на шаг назад
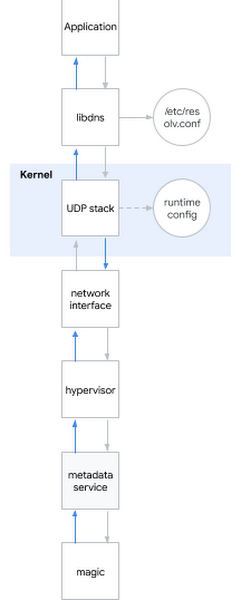
Один из самых популярных вопросов на интервью на должность системного инженера звучит так: «Что происходит, когда вы пингуете ?» Вопрос шикарный, так как кандидату необходимо описать пусть от оболочки до пользовательского пространства, до ядра системы и далее к сети. Я улыбаюсь: иногда вопросы с интервью оказываются полезны и в реальной жизни…
Я решаю применить этот эйчарский вопрос к текущей проблеме. Грубо говоря, когда вы пытаетесь определить DNS имя, происходит следующее:
- Приложение вызывает системную библиотеку, например libdns
- libdns проверяет конфигурацию системы к какому DNS серверу ей обращаться (на диаграмме это 169.254.169.254, сервер метаданных)
- libdns использует системные вызовы для создания UDP сокета (SOKET_DGRAM) и передачи UDP пакетов с DNS запросом в обе стороны
- Через интерфейс sysctl можно настроить UDP стек на уровне ядра
- Ядро взаимодействует с железом для передачи пакетов по сети через сетевой интерфейс
- Гипервизор ловит и передает пакет серверу метаданных при контакте с ним
- Сервер метаданных своим колдунством определяет DNS имя и таким же методом возвращает ответ
Напомню, какие гипотезы мы уже успели рассмотреть:
Гипотеза: Сломаны библиотеки
- Тест 1: прогнать в системе strace, проверить что dig вызывает корректные системные вызовы
- Результат: вызываются корректные системные вызовы
- Тест 2: через srapy проверить можем ли мы определять имена в обход системных библиотек
- Результат: можем
- Тест 3: прогнать rpm –V на пакете libdns и md5sum файлах библиотеки
- Результат: код библиотеки полностью идентичен коду в в рабочей операционной системе
- Тест 4: монтировать образ корневой системы пользователя на VM без подобного поведения, прогнать chroot, посмотреть работает ли DNS
- Результат: DNS работает корректно
Вывод на основе тестов: проблема не в библиотеках
Гипотеза: Присутствует ошибка в настройках DNS
- Тест 1: проверить tcpdump и пронаблюдать корректно ли отправляются и возвращаются DNS пакеты после запуска dig
- Результат: пакеты передаются корректно
- Тест 2: перепроверить на сервере
/etc/nsswitch.confи/etc/resolv.conf - Результат: все корректно
Вывод на основе тестов: проблема не в конфигурации DNS
Гипотеза: повреждено ядро
- Тест: установить новое ядро, проверить подпись, перезапустить
- Результат: аналогичное поведение
Вывод на основе тестов: ядро не повреждено
Гипотеза: некорректное поведение пользовательской сети (либо интерфейса сети гипервизора)
- Тест 1: проверить настройки файервола
- Результат: файервол пропускает DNS пакеты и на хосте, и на GCP
- Тест 2: перехватить трафик и отследить корректность передачи и возврата DNS запросов
- Результат: tcpdump подтверждает получение обратных пакетов хостом
Вывод на основе тестов: проблема не в сети
Гипотеза: не работает сервер метаданных
- Тест 1: проверить логии сервера метаданных на аномалии
- Результат: в логах аномалий нет
- Тест 2: обойти сервер метаданных через
dig @8.8.8.8 - Результат: разрешение нарушается даже без использования сервера метаданных
Вывод на основе тестов: проблема не в сервере метаданных
Итог: мы протестировали все подсистемы кроме настроек среды выполнения!
Погружаясь в настройки среды выполнения ядра
Для настройки среды исполнения ядра вы можете воспользоваться опциями командной строки (grub) либо интерфейсом sysctl. Я заглянул в /etc/sysctl.conf и подумать только, обнаружил несколько кастомных настроек. Чувствуя будто я ухватился за что-то, я отмел все несетевые или не-tcp настройки, оставшись с горской настроек net.core. Затем я обратился туда, где у VM лежат разрешения хоста и начал применять друг за дружкой, одна за другой настройки со сломанной VM, пока не вышел на преступника:
net.core.rmem_default = 2147483647Вот она, ломающая DNS конфигурация! Я нашел орудие преступления. Но почему это происходит? Мне все еще нужен был мотив.
Настройка базового размера буфера DNS пакетов происходит через net.core.rmem_default. Типичное значение варьируется где-то в пределах 200КиБ, однако если ваш сервер получает много DNS пакетов, вы можете увеличить размер буфера. Если в момент поступления нового пакета буфер полон, например потому что приложение недостаточно быстро его обрабатывает, то вы начнете терять пакеты. Наш клиент правильно увеличил размер буфера так как опасался потерь данных, поскольку пользовался приложением по сбору метрик через DNS пакеты. Значение, которое он выставил, было максимально возможным: 231-1 (если выставить 231, ядро вернет «INVALID ARGUMENT»).
Внезапно я осознал почему nmap и scapy работали корректно: они использовали сырые сокеты! Сырые сокеты отличаются от обычных: они работают в обход iptables, и они не буферизуются!
Но почему «слишком большой буфер» вызывает проблемы? Он явно работает не так как задумано.
К этому моменту я мог воспроизвести проблему на нескольких ядрах и множестве дистрибутивов. Проблема уже проявлялась на ядре 3.х и теперь так же проявлялась на ядре 5.х.
Действительно, при запуске
sysctl -w net.core.rmem_default=$((2**31-1))DNS переставал работать.
Я принялся искать рабочие значения через простой алгоритм двоичного поиска и обнаружил что с 2147481343 система работает, однако это число было для меня бессмысленным набором цифр. Я предложил клиенту попробовать это число, и он ответил что система заработала с google.com, но все еще выдавала ошибку с другими доменами, поэтому я продолжил мое расследование.
Я установил , инструмент, которым стоило воспользоваться раньше: он показывает куда именно в ядре попадает пакет. Виновной оказалась функция udp_queue_rcv_skb. Я скачал исходники ядра и добавил несколько чтобы отслеживать куда конкретно попадает пакет. Я быстро обнаружил нужное условие if, и некоторое время попросту пялился на него, ведь именно тогда все наконец сошлось в цельную картину: 231-1, бессмысленное число, неработающий домен… Дело было в куске кода в __udp_enqueue_schedule_skb:
if (rmem > (size + sk->sk_rcvbuf))
goto uncharge_drop;Обратите внимание:
rmemимеет тип intsizeимеет тип u16 (неподписанный шестнадцатибитный int) и хранит размер пакетаsk->sk_rcybufимеет тип int и хранит размер буфера который по определению равен значению вnet.core.rmem_default
Когда sk_rcvbuf приближается к 231, суммирование размера пакета может привести к . И так как это int, его значение становится отрицательным, таким образом условие становится истинным когда должно быть ложным (больше об этом можно узнать по ).
Ошибка исправляется тривиальным образом: приведением к unsigned int. Я применил исправление и перезапустил систему, после чего DNS вновь заработал.
Вкус победы
Я переслал мои находки клиенту и выслал патч ядра. Я доволен: каждый кусочек головоломки сошелся в единое целое, я могу точно объяснить почему мы наблюдали то что мы наблюдали, и что самое главное, мы смогли найти решение проблемы благодаря совместной работе!
Стоит признать, что случай оказался редким, и к счастью к нам от пользователей редко поступают настолько сложные обращения.
Источник: habr.com
