

Приветствуем вас, Хабр!
В свое время мы первыми вывели на российский рынок тему и продолжаем за ее развитием. В частности, нам показалась интересной тема взаимодействия Kafka и . Обзорная (и довольно осторожная) на эту тему выходила в блоге компании Confluent еще в октябре прошлого года под авторством Гвен Шапиры. Сегодня же мы хотим обратить ваше внимание на более свежую, апрельскую статью Йоханна Гайгера (Johann Gyger), который, хотя и не обошелся без вопросительного знака в названии, рассматривает тему в более предметном ключе, сопровождая текст интересными ссылками. Простите нам пожалуйста вольный перевод «chaos monkey», если сможете!
Введение
Kubernetes предназначен для работы с нагрузками, не сохраняющими состояние. Как правило, такие рабочие нагрузки представлены в форме микросервисной архитектуры, они легковесны, хорошо поддаются горизонтальному масштабированию, подчиняются принципам 12-факторных приложений, позволяют работать с автоматическими выключателями (circuit breaker) и мартышками-ломашками (chaos monkeys).
Kafka, расположенный с другой стороны, в сущности, выступает в роли распределенной базы данных. Таким образом, при работе вам приходится иметь дело с состоянием, а оно гораздо тяжеловеснее микросервиса. Kubernetes поддерживает нагрузки с сохранением состояния, но, как указывает Келси Хайтауэр в двух своих твитах, с ними следует обращаться осторожно:
Некоторым кажется, что, если накатить Kubernetes на нагрузку с сохранением состояния, он превращается в полностью управляемую базу данных, способную соперничать с RDS. Это не так. Может быть, если достаточно потрудиться, прикрутить дополнительные компоненты и привлечь команду SRE-инженеров, то удастся обустроить RDS поверх Kubernetes.
Всегда всем рекомендую проявлять исключительную осторожность, запуская нагрузки с сохранением состояния на Kubernetes. Большинство из тех, кто интересуется, «смогу ли я запускать на Kubernetes нагрузки с сохранением состояния» не обладают достаточным опытом в работе с Kubernetes, а зачастую – и с той нагрузкой, о которой спрашивают.
Итак, следует ли запускать Kafka на Kubernetes? Встречный вопрос: а будет ли Kafka лучше работать без Kubernetes? Вот почему я хочу подчеркнуть в этой статье, как Kafka и Kubernetes дополняют друг друга, и какие подводные камни могут попасться при их сочетании.
Время исполнения
Давайте поговорим о базовой вещи — среде времени исполнения как таковой
Процесс
Брокеры Kafka удобны при работе с CPU. TLS может привнести некоторые издержки. При этом, клиенты Kafka могут сильнее нагружать CPU, если используют шифрование, но это не влияет на брокеров.
Память
Брокеры Kafka отжирают память. Размер кучи JVM обычно модно ограничить 4–5 Гб, но вам также понадобится много системной памяти, поскольку Kafka очень активно использует страничный кэш. В Kubernetes соответствующим образом задавайте пределы контейнера на ресурсы и запросы.
Хранилище данных
Хранилище данных в контейнерах является эфемерным – данные теряются при перезапуске. Для данных Kafka можно использовать том emptyDir, и эффект будет аналогичным: данные вашего брокера будут утеряны после завершения. Ваши сообщения все равно могут сохраниться на других брокерах в качестве реплик. Поэтому, после перезапуска отказавший брокер должен первым делом реплицировать все данные, а на этот процесс может потребоваться немало времени.
Вот почему следует использовать долговременное хранилище данных. Пусть это будет нелокальное долговременное хранилище с файловой системой XFS или, точнее, ext4. Не используйте NFS. Я предупредил. NFS версий v3 или v4 работать не будет. Короче говоря, брокер Kafka завершится, если не сможет удалить каталог с данными из-за проблемы с «глупыми переименованиями», актуальной в NFS. Если я вас до сих пор не убедил, очень внимательно . Хранилище данных должно быть нелокальным, чтобы Kubernetes мог более гибко выбирать новый узел после перезапуска или релокации.
Сеть
Как и в случае с большинством распределенных систем, производительность Kafka очень сильно зависит от того, чтобы задержки в сети были минимальными, а ширина полосы – максимальной. Не пытайтесь разместить все брокеры на одном и том же узле, так как в результате уменьшится доступность. Если откажет узел Kubernetes, то откажет и весь кластер Kafka. Также не рассредоточивайте кластер Kafka по целым датацентрам. То же касается кластера Kubernetes. Хороший компромисс в данном случае – выбрать разные зоны доступности.
Конфигурация
Обычные манифесты
На сайте Kubernetes есть о том, как настроить ZooKeeper при помощи манифестов. Поскольку ZooKeeper входит в состав Kafka, именно с этого удобно начинать знакомиться с тем, какие концепции Kubernetes здесь применимы. Разобравшись с этим, вы сможете задействовать те же концепции и с кластером Kafka.
- Под: под – это минимальная развертываемая единица в Kubernetes. В поде содержится ваша рабочая нагрузка, а сам под соответствует процессу у вас в кластере. В поде содержится один или более контейнеров. Каждый сервер ZooKeeper в ансамбле и каждый брокер в кластере Kafka будут работать в отдельном поде.
- StatefulSet: StatefulSet – это объект Kubernetes, работающий со множественными рабочими нагрузками, сохраняющими состояниями, а такие нагрузки требуют координации. StatefulSet предоставляют гарантии относительно упорядочения подов и их уникальности.
- Headless-сервисы: Сервисы позволяют откреплять поды от клиентов при помощи логического имени. Kubernetes в данном случае отвечает за балансировку нагрузки. Однако, при операциях с рабочими нагрузками, сохраняющими состояние, как в случае с ZooKeeper и Kafka, клиентам необходимо обмениваться информацией с конкретным инстансом. Именно здесь вам и пригодятся headless-сервисы: в таком случае у клиента все равно будет логическое имя, но напрямую к поду можно будет не обращаться.
- Том для долговременного хранения: такие тома нужны для конфигурации нелокального блочного долговременного хранилища, которое упоминалось выше.
На предоставляется исчерпывающий набор манифестов, при помощи которых удобно начать работу с Kafka на Kubernetes.
Helm-диаграммы
Helm – это менеджер пакетов для a Kubernetes, который можно сравнить с менеджерами пакетов для ОС, такими как yum, apt, Homebrew или Chocolatey. С его помощью удобно устанавливать заранее определенные программные пакеты, описанные в диаграммах Helm. Хорошо подобранная диаграмма Helm облегчает сложную задачу: как правильно сконфигурировать все параметры для использования Kafka на Kubernetes. Есть несколько диаграмм Kafka: официальная находится , есть одна от , еще одна – от .
Операторы
Поскольку Helm свойственны определенные недостатки, немалую популярность приобретает еще одно средство: операторы Kubernetes. Оператор не просто упаковывает софт для Kubernetes, но и позволяет вам развертывать такой софт, а также управлять им.
В списке упоминаются два оператора для Kafka. Один из них — . При помощи Strimzi не составляет никакого труда поднять кластер Kafka за считанные минуты. Практически никакой конфигурации вносить не требуется, кроме того, сам оператор предоставляет кое-какие приятные возможности, например, шифрование TLS вида «точка-точка» внутри кластера. Confluent также предоставляет .
Производительность
Очень важно тестировать производительность, снабжая установленный у вас экземпляр Kafka контрольными точками. Такие тесты помогут вам обнаружить потенциальные узкие места, пока не начались проблемы. К счастью, в Kafka уже предоставляется два инструмента для тестирования производительности: kafka-producer-perf-test.sh и kafka-consumer-perf-test.sh. Активно пользуйтесь ими. Для справки можете сверяться с результатами, описанными в Джеем Крепсом, либо ориентироваться на Amazon MSK от Stéphane Maarek.
Операции
Мониторинг
Прозрачность в системе очень важна – иначе вы не поймете, что в ней происходит. Сегодня имеется солидный инструментарий, обеспечивающий мониторинг на основе метрик в стиле cloud native. Два популярных инструмента для этой цели — Prometheus и Grafana. Prometheus может собирать метрики со всех процессов Java (Kafka, Zookeeper, Kafka Connect) при помощи экспортера JMX – самым простым образом. Если присовокупить метрики cAdvisor, то можно будет полнее представлять, как в Kubernetes используются ресурсы.
У Strimzi есть очень удобный пример дашборда Grafana для Kafka. Он визуализирует ключевые метрики, например, о недореплицированных секторах или о тех, что находятся оффлайн. Там все очень понятно. Эти метрики дополняются сведениями об использовании ресурсов и производительности, а также индикаторами стабильности. Таким образом, вы получаете базовый мониторинг кластера Kafka за просто так!
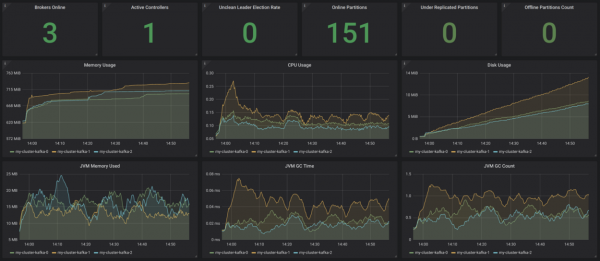
Источник:
Все это неплохо было бы дополнить мониторингом клиентов (метрики по консьюмерам и продьюсерам), а также мониторингом запаздывания (для этого есть ) и сквозным мониторингом – для этого используйте .
Логирование
Логирование – еще одна важнейшая задача. Убедитесь, что все контейнеры в вашей установке Kafka логируются в stdout и stderr, а также позаботьтесь о том, чтобы ваш кластер Kubernetes агрегировал все логи в центральной журнальной инфраструктуре, например, в .
Проверка работоспособности
Kubernetes использует зонды «живости» (liveness) и готовности (readiness) чтобы проверить, нормально ли работают ваши поды. Если проверка на живость не удается, Kubernetes остановит этот контейнер, а затем автоматически перезапустит его, если политика перезапуска установлена соответствующим образом. Если не удается проверка на готовность, то Kubernetes изолирует этот под от обслуживания запросов. Таким образом, в подобных случаях больше вообще не требуется вмешательства вручную, а это большой плюс.
Выкатывание обновлений
StatefulSet поддерживают автоматические обновления: при выборе стратегии RollingUpdate каждый под Kafka будет обновляться по очереди. Таким образом можно свести длительность простоев к нулю.
Масштабирование
Масштабирование кластера Kafka – непростая задача. Однако, в Kubernetes очень просто масштабировать поды до определенного количества реплик, а это значит, что вы сможете декларативно определить столько брокеров Kafka, сколько захотите. Самое сложное в данном случае – переприсваивание секторов после масштабирования вверх или перед масштабированием вниз. Опять же, с этой задачей вам поможет Kubernetes.
Администрирование
Задачи, связанные с администрированием вашего кластера Kafka, в частности, создание топиков и переприсваивание секторов можно сделать при помощи имеющихся шелл-скриптов, открывая интерфейс командной строки в ваших подах. Однако, такое решение не слишком красивое. Strimzi поддерживает управление топиками при помощи другого оператора. Здесь есть что дорабатывать.
Резервное копирование и восстановление
Теперь доступность Kafka у нас будет зависеть и от доступности Kubernetes. Если у вас упадет кластер Kubernetes, то в худшем случае упадет и кластер Kafka. По закону Мёрфи это обязательно произойдет, и вы потеряете данные. Чтобы снизить риск такого рода, хорошо проработайте концепцию резервного копирования. Можно воспользоваться MirrorMaker, другой вариант – задействовать для этого S3, как описано в этом от Zalando.
Заключение
При работе с небольшими или средними кластерами Kafka определенно целесообразно использовать Kubernetes, поскольку он обеспечивает дополнительную гибкость и упрощает работу с операторами. Если перед вами стоят очень серьезные нефункциональные требования, касающиеся задержки и/или пропускной способности, то, возможно, лучше рассмотреть какой-нибудь другой вариант развертывания.
Источник: habr.com
