

Редактор Нетологии побеседовала с тимлидом команды BI в Павлом Саяпиным о том, какие задачи решают дата-инженеры в его команде, что за инструменты для этого используют и как же всё-таки правильно подойти к выбору инструментария для решения дата-задач, в том числе нетипичных. Павел — преподаватель на курсе «».
Чем занимаются дата-инженеры в Profi.ru
Profi.ru — это сервис, который помогает встретиться клиентам и специалистам самых различных сфер. В базе сервиса более 900 тысяч специалистов по 700 видам услуг: репетиторы, мастера по ремонту, тренеры, мастера красоты, артисты и другие. Ежедневно регистрируется более 10 тысяч новых заказов — всё это даёт порядка 100 млн событий в день. Поддерживать порядок в таком количестве данных невозможно без профессиональных дата-инженеров.
В идеале Data Engineer развивает культуру работы с данными, с помощью которой компания может получать дополнительную прибыль или сокращать издержки. Приносит ценность бизнесу, работая в команде и выступая важным звеном между различными участниками — от разработчиков до бизнес-потребителей отчётности. Но в каждой компании задачи могут отличаться, поэтому рассмотрим их на примере Profi.ru.
Собирают данные для принятия решения и предоставляют их конечному пользователю — топ-менеджеру, продакт-менеджеру, аналитику
Данные должны быть понятными для принятия решений и удобными для использования. Не нужно прикладывать усилий для поиска описания или составлять сложный SQL-запрос, который учитывает много различных факторов. Идеальная картинка — пользователь смотрит на дашборд и его всё устраивает. А если не хватает данных в каком-то разрезе, то он идёт в базу и с помощью простейшего SQL-запроса получает то, что нужно.
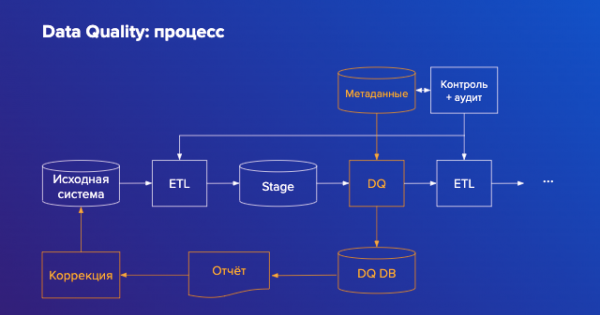
Место процесса Data Quality в общей структуре хранилища данных
Важное значение отводится пояснительной документации по работе с данными. Это упрощает работу и дата-инженера (не отвлекают вопросами), и пользователя данных (может сам найти ответы на свои вопросы). В Profi.ru такие документы собраны на внутреннем форуме.
Под удобством подразумевается в том числе скорость получения данных. Скорость = доступность в одном шаге, клике — дашборде. Но на практике всё сложнее.
Тот же Tableau с точки зрения конечного пользователя дашборда не позволяет вывести все возможные измерения. Пользователь довольствуется теми фильтрами, что сделал разработчик дашборда. Это порождает два сценария:
- Разработчик делает множество разрезов для дашборда ⟶ количество страниц сильно увеличивается. Это снижает доступность данных: становится сложно понять, где что лежит.
- Разработчик создаёт только ключевые разрезы. Найти информацию легче, но за чуть менее стандартным разрезом всё равно придётся идти либо в базу, либо к аналитикам. Что также плохо влияет на доступность.
Доступность — понятие широкое. Это и наличие данных в надлежащем виде, и возможность получить информацию на дашбордах, а также необходимый разрез данных.
Аккумулируют данные со всех источников в одном месте
Источники данных могут быть внутренними и внешними. Например, у кого-то бизнес зависит от погодных сводок, которые нужно собирать и хранить, — от внешних источников.
Складировать информацию нужно с указанием источника, а также чтобы данные можно было легко найти. В Profi.ru эта задача решена при помощи автоматизированной документации. В качестве документации о внутренних источниках данных используются YML-файлы.
Делают дашборды
Визуализацию данных лучше делать в профессиональном инструменте — например, в Tableau.
Большинство принимает решения эмоционально, — важна наглядность и эстетика. Тот же Excel для визуализации, к слову, не очень подходит: не покрывает все потребности пользователей данных. К примеру, продакт-менеджер любит зарываться в цифры, но так, чтобы это было удобно делать. Это позволяет ему решать свои задачи, а не думать, как получить информацию и собрать метрики.
Качественная визуализация данных позволяет легче и быстрее принимать решения.
Чем выше человек по должности, тем острее необходимость иметь под рукой, на телефоне, агрегированные данные. Детали топ-менеджерам не нужны — важно контролировать ситуацию в целом, а BI — хороший инструмент для этого.
Пример продакт-дашборда Profi.ru (один из листов). В целях конфиденциальности информации названия метрик и осей скрыты
Примеры реальных задач
Задача 1 — перелить данные из исходных (операционных) систем в хранилище данных или ETL
Одна из рутинных задач дата-инженера.
Для этого могут использоваться:
- самописные скрипты, запускаемые по cron или с помощью специального оркестровщика типа Airflow или Prefect;
- ETL-решения с открытым кодом: Pentaho Data Integration, Talend Data Studio и другие;
- проприетарные решения: Informatica PowerCenter, SSIS и другие;
- облачные решение: Matillion, Panoply и другие.
В простом исполнении задача решается написанием YML-файла строк на 20. Занимает это минут 5.
В самом сложном случае, когда нужно добавить новый источник — например, новую БД, — может занимать до нескольких дней.
В Profi эта простая задача — при отлаженном процессе — состоит из следующих шагов:
- Выяснить у заказчика, какие нужны данные и где они лежат.
- Понять, есть ли доступы к этим данным.
- Если доступов нет, запросить у админов.
- Добавить новую ветку в Git с кодом задачи в Jira.
- Создать миграцию на добавление данных в якорную модель через интерактивный Python-скрипт.
- Добавить файлы прогрузок (YML-файл с описанием того, откуда данные берутся и в какую таблицу записываются).
- Протестировать на стенде.
- Залить данные в репозиторий.
- Создать pull request.
- Пройти код ревью.
- После прохождения код-ревью данные заливаются в мастер-ветку и автоматически раскатываются в продуктив (CI/CD).
Задача 2 — удобно разместить загруженные данные
Другая частая задача — разместить загруженные данные так, чтобы конечному пользователю (или BI-инструменту) было удобно с ними работать и не приходилось делать лишних движений для выполнения большинства задач. То есть построить или обновить Dimension Data Store (DDS).
Для этого могут применяться решения из 1-й задачи, так как это также ETL-процесс. В самом простом варианте обновление DDS осуществляется с помощью SQL-скриптов.
Задача 3 — из разряда нетипичных задач
В Profi зарождается стриминговая аналитика. Генерируется большое количество событий от продуктовых команд — записываем их в ClickHouse. Но там нельзя вставлять записи по одной в большом количестве, поэтому приходится объединять записи в пачки. То есть писать напрямую нельзя — нужен промежуточный обработчик.
Используем движок на базе Apache Flink. Пока порядок действий такой: движок обрабатывает входящий поток событий ⟶ складывает их пачками в ClickHouse ⟶ на ходу считает количество событий за 15 минут ⟶ передаёт их сервису, который определяет, есть ли аномалии — сравнивает со значениями за аналогичные 15 минут с глубиной в 3 месяца ⟶ если есть, кидает оповещение в Slack.
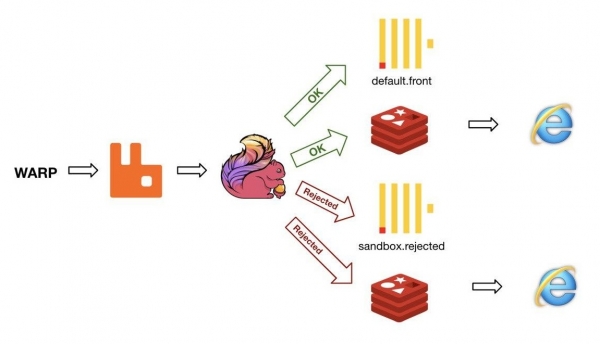
Схема для фронтовой аналитики (часть загрузки)
Фреймворк Apache Flink гарантирует доставку как минимум один раз. Тем не менее появляется вероятность дубликатов. В случае с RabbitMQ это можно решить, используя Correlation ID. Тогда гарантируется единичная доставка ⟶ целостность данных.
Считаем количество событий опять же с помощью Apache Flink, выводим через самописный дашборд, написанный на NodeJS, + фронт на ReactJS. Быстрый поиск не дал похожих решений. Да и сам код получился простым — написание не заняло много времени.
Мониторинг скорее технический. Смотрим аномалии, чтобы на ранних стадиях предотвращать проблемы. Какие-то существенные глобальные метрики компании в мониторинг пока не входят, поскольку направление стриминговой аналитики находится на стадии формирования.
Основные инструменты дата-инженеров
С задачами дата-инженеров более-менее понятно, теперь немного об инструментах, которые используются для их решения. Конечно, инструменты в разных компаниях могут (и должны) отличаться — всё зависит от объема данных, их скорости поступления и неоднородности. Также может зависеть от пристрастности специалиста к какому-то одному инструменту только потому, что он с ним работал и хорошо его знает. В Profi.ru остановились на таких вариантах →
Для визуализации данных — Tableau, Metabase
Tableau выбрали давно. Эта система позволяет оперативно анализировать большие массивы данных, при этом не требует затратного внедрения. Для нас он удобен, красив и привычен — часто в нём работаем.
Про Metabase знают немногие, между тем для прототипирования он очень хорош.
Из инструментов визуализации ещё можно сказать про Superset от Airbnb. Его особенная фича — много коннектов к базам данных и возможностей для визуализации. Однако для рядового пользователя он менее удобен, чем Metabase, — в нём нельзя соединять таблицы, для этого нужно делать отдельные представления.
В том же Metabase соединять таблицы можно, более того сервис делает это сам с учётом схемы базы данных. Да и интерфейс у Metabase проще и приятнее.
Инструментов очень много — просто найдите свой.
Для хранения данных — ClickHouse, Vertica
ClickHouse — бесплатный быстрый инструмент для хранения продуктовых событий. На нём аналитики сами делают обособленную аналитику (если им хватает данных) или дата-инженеры берут агрегаты и перезаливают их в Vertica для построения витрин.
Vertica — крутой удобный продукт для отображения конечных витрин.
Для управления потоками данных и проведения вычислений — Airflow
Данные мы грузим через консольные инструменты. Например, через клиент, который идёт с MySQL, — так получается быстрее.
Плюс консольных инструментов — скорость. Данные не прокачиваются через память того же Python-процесса. Из минусов — меньше контроля данных, которые транзитом пролетают из одной БД в другую.
Основной язык программирования — Python
У Python намного ниже порог вхождения + в компании есть компетенции по этому языку. Другая причина — под Airflow DAGи пишутся на Python. Эти скрипты просто обёртка над загрузками, основная работа делается через консольные скрипты.
Java мы используем для разработки под аналитику в режиме реального времени.
Подход к выбору дата-инструментов — что делать, чтобы не разводить технологический зоопарк
На рынке много инструментов для работы с данными на каждом этапе: от их появления до вывода на дашборд для совета директоров. Неудивительно, что у некоторых компаний может появиться ряд несвязанных решений — так называемый технологический зоопарк.
Технологический зоопарк — это инструменты, которые выполняют одни и те же функции. Например, Kafka и RabbitMQ для обмена сообщениями или Grafana и Zeppelin для визуализации.

— видно, как много дублирующих решений может быть
Также многие для личных целей могут использовать разные ETL-инструменты. В Profi как раз такая ситуация. Основной ETL — на Airflow, но кто-то для личных прогрузок использует Pentaho. Они тестируют гипотезы, и через инженеров эти данные им прогонять не нужно. В основном инструменты «самообслуживания» используют достаточно опытные специалисты, которые занимаются исследовательской деятельностью — изучают новые пути развития продукта. Набор их данных для анализа интересен в основном им, к тому же, он постоянно меняется. Соответственно нет смысла заносить эти прогрузки в основную платформу.
Возвращаясь к зоопарку. Часто использование дублирующих технологий связано с человеческим фактором. Обособленные внутренние команды привыкли работать с тем или иным инструментом, который другая команда может и не использовать. И иногда автономия — единственный путь для решения особых задач. Например, команде R&D нужно что-то протестировать при помощи определённого инструмента — он просто удобен, кто-то из команды уже использовал его или есть другая причина. Ждать ресурса системных администраторов на установку и настройку этого инструмента долго. При этом вдумчивым и дотошным администраторам ещё нужно доказать, что это действительно нужно. Вот команда и ставит инструмент на своих виртуалках и решает свои специфические задачи.
Зоопарк решений не проблема, только если это не требует значительных трудозатрат сисадмина на поддержку инструмента. Нужно учитывать, как использование инструмента влияет на ресурсы поддержки.
Другая распространённая причина появления нового инструментария — желание попробовать неизвестный продукт в достаточно новой области, где ещё не сформированы стандарты или нет проверенных рекомендаций. Дата-инженер, как и разработчик, всегда должен исследовать новый инструментарий в надежде найти более эффективное решение текущим задачам или чтобы быть в курсе, что предлагает рынок.
Соблазн попробовать новые инструменты действительно большой. Но чтобы сделать целесообразный выбор, нужна в первую очередь самодисциплина. Она поможет не отдаваться полностью исследовательским порывам, а учитывать возможности компании в поддержке инфраструктуры для нового инструмента.
Не стоит использовать технологии ради технологий. Лучше всего к вопросу подходить прагматично: задача ⟶ набор инструментов, которые могут эту задачу решить.
А дальше оценить каждый из них и выбрать оптимальный. Например, этот инструмент может решить задачу эффективнее, но по нему нет компетенций, а этот чуть менее эффективный, но в компании есть люди, которые знают, как с ним работать. Вот этот инструмент платный, но простой в поддержке и использовании, а это модный open source, но для его поддержки нужен штат админов. Такие возникают дихотомии, для решения которых нужна холодная голова.
Выбор инструмента — наполовину прыжок веры, наполовину личный опыт. Нет полной уверенности, что инструмент подойдёт.
Например, в Profi начинали с Pentaho, потому что была экспертность по этому инструменту, но в итоге это оказалось ошибочным решением. Внутренний репозиторий Pentaho по мере роста проекта стал сильно замедлять работу. На сохранение данных, к слову, уходила минута, а если есть привычка постоянно сохранять работу, то время просто утекало сквозь пальцы. К этому добавлялся сложный запуск, задачи по расписанию — компьютер зависал.
Страдания завершились после перехода на Airflow — популярный инструмент, у которого большое комьюнити.
Наличие комьюнити сервиса, инструмента важно для решения сложных задач — можно спросить совета у коллег.
Если компания зрелая и располагает ресурсами, имеет смысл задуматься о покупке техподдержки. Это поможет оперативно устранять проблемы и получать рекомендации по использованию продукта.
Если говорить о подходе к выбору, то в Profi придерживаются таких принципов:
- Не принимать решение в одиночку. Когда человек что-то выбирает, он автоматически убеждён в своей правоте. Другое дело — убедить других, когда нужно привести серьёзные доводы в защиту. Это помогает в том числе увидеть слабые стороны инструмента.
- Советоваться с главным специалистом по данным (диалог по вертикали). Это может быть главный дата-инженер (Chief Data Engineer), руководитель BI-команды. Топы видят ситуацию более широко.
- Общаться с другими командами (диалог по горизонтали). Какие инструменты они используют и насколько удачно. Возможно, инструмент коллег может решить и ваши задачи и не придётся устраивать зоопарк решений.
Внутренние компетенции как эффективная замена внешнему поставщику услуг
Подходом к выбору инструментов можно считать и использование внутренних компетенций компании.
Довольно часто встречаются ситуации, когда у бизнеса есть сложная задача, но нет денег для её реализации. Задача масштабная и важная, и по-хорошему лучше всего привлечь внешнего поставщика услуг, у которого есть соответствующий опыт. Но поскольку такой возможности (денег) нет, решить задачу поручается внутренней команде. К тому же, обычно бизнес больше доверяет своим сотрудникам, если те уже доказали свою эффективность.
Среди примеров таких задач, когда новое направление развивается силами сотрудников, — проведение нагрузочного тестирования и создание хранилища данных. Особенно хранилище данных, так как это уникальная история для каждого бизнеса. Хранилище нельзя купить, можно лишь нанять внешних специалистов, которые его построят при поддержке внутренней команды.
Кстати, по мере развития нового направления команда может понять, что необходимость во внешнем поставщике услуг отпала.
В Profi внедрение BI было in-house. Основная сложность была в том, что бизнес хотел запустить BI быстро. Но на построение такого проекта требовалось время: нарастить компетенции, залить данные, построить удобную схему хранилища, выбрать инструменты и освоить их.
Основная — горячая — фаза, когда всё строилось и кристаллизовывалось, длилась где-то год. А развивается проект до сих пор.
При построении корпоративного хранилища данных важно придерживаться высоких стандартов, отстаивать свои позиции и не делать кое-как в угоду бизнесу.
С большой болью мы переделывали большую часть проекта, которую пришлось тогда сделать по-быстрому.
Но иногда подход «на скорую» целесообразен. Так, в продуктовой разработке он может быть даже единственно верным. Нужно быстро двигаться вперёд, тестировать продуктовые гипотезы и другое. Но хранилище должно быть основано на крепкой архитектуре, иначе оно не сможет быстро адаптироваться к растущему бизнесу и проект заглохнет.
В этом сложном проекте очень помог наш руководитель, который отстаивал ход работ, пояснял руководству, что мы делаем, выбивал ресурсы и просто защищал нас. Без такой поддержки не уверен, что у нас получилось бы запустить проект.
В подобных историях важную роль играют так называемые early adopters — те, кто готов пробовать новое, — среди топ-менеджеров, аналитиков, продакт-менеджеров. Чтобы сырая тема взлетела, нужны первопроходцы, которые подтвердят, что всё работает и этим удобно пользоваться.
Если кто хочет поделиться решением третьей задачки из описанных выше — welcome 🙂
Источник: habr.com
