

В этом материале рассказывается о простейшем и быстром инструменте обнаружения данных, работу которого вы видите на КДПВ. Интересно, что whale создан таким образом, чтобы размещаться на удаленном git-сервере. Подробности под катом.
Как инструмент обнаружения данных Airbnb изменил мою жизнь
В моей карьере мне посчастливилось работать над некоторыми забавными проблемами: я изучал математику потоков во время получения степени в MIT, работал над инкрементальными моделями и с проектом с открытым исходным кодом в Wayfair, а также внедрял новые модели таргетинга на домашнюю страницу и улучшения CUPED в Airbnb. Но вся эта работа никогда не была гламурной — на самом деле я часто тратил большую часть своего времени на поиск, изучение и проверку данных. Хотя это было постоянным состоянием на работе, мне не приходило в голову, что это проблема, пока я не попал в Airbnb, где она была решена с помощью инструмента обнаружения данных — .
Где я могу найти {{data}}? Dataportal.
Что означает эта колонка? Dataportal.
Как дела у {{metric}} сегодня? Dataportal.
В чем смысл жизни? В Dataportal, вероятно.
Ладно, вы представили картину. Найти данные и понять, что они означают, как они были созданы и как их использовать — все это занимает всего несколько минут, а не часов. Я мог бы тратить свое время на то, чтобы делать простые выводы, или на новые алгоритмы, (… или ответы на случайные вопросы о данных), а не рыться в заметках, писать повторяющиеся запросы SQL и упоминать коллег в Slack, чтобы попытаться воссоздать контекст, который уже был у кого-то другого.
А в чем проблема?
Я понял, что большинство моих друзей не имели доступа к такому инструменту. Немногие компании хотят выделять огромные ресурсы на создание и поддержание такого инструмента-платформы, как Dataportal. И хотя существует несколько решений с открытым исходным кодом, они, как правило, разработаны для масштабирования, что затрудняет настройку и обслуживание без посвященного в эту работу инженера DevOps. Поэтому я решил создать нечто новое.
Whale: простой до глупости инструмент обнаружения данных

И да, под простым до глупости подразумеваю простой до глупости. У whale только два компонента:
- Библиотека Python, собирающая метаданные и форматирующая их в MarkDown.
- Интерфейс командной строки на Rust для поиска по этим данным.
С точки зрения внутренней инфраструктуры для обслуживания есть только множество текстовых файлов и обновляющая текст программа. Вот и все, поэтому размещение на git-сервере, таком как Github, тривиально. Никакого нового языка запросов, который пришлось бы изучать, никакой инфраструктуры управления, никаких резервных копий. Git известен всем, так что синхронизация и совместная работа прилагаются бесплатно. Давайте подробнее рассмотрим функциональность .
Полнофункциональный графический интерфейс на основе git
Whale создан, чтобы плыть в океане удаленного сервера git. Он настраивается: определите некоторые соединения, скопируйте скрипт Github Actions (или напишите его для выбранной платформы CI/CD) — и вы сразу же получите веб-инструмент обнаружения данных. Вы сможете искать, просматривать, документировать и делиться своими таблицами непосредственно на Github.
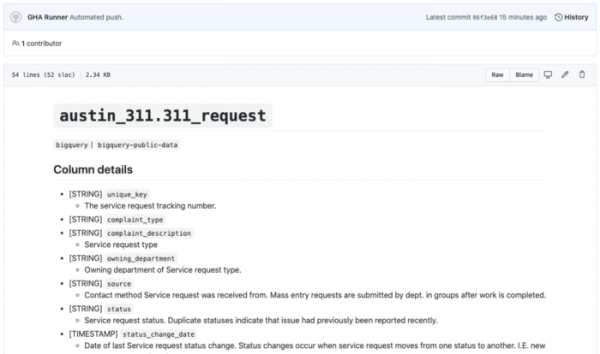
Пример сгенерированной с помощью Github Actions таблицы-заглушки. Полную работающую демонстрацию .
Молниеносно быстрый поиск из CLI по вашему хранилищу
Whale живет и дышит в командной строке, предоставляя функциональный, миллисекундный поиск по вашим таблицам. Даже при миллионах таблиц нам удалось сделать whale невероятно производительным, используя некоторые хитроумные механизмы кэширования, а также перестроив бекенд на Rust. Вы не заметите никакой задержки поиска [привет, Google DS].

Демонстрация whale, поиск по миллиону таблиц.
Автоматическое вычисление метрик [в бете]
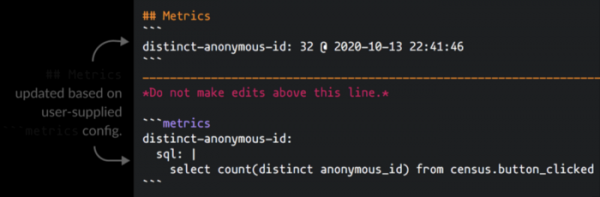
Одна из моих наименее любимых вещей как ученого-исследователя данных — запуск одних и тех же запросов снова и снова просто для проверки качества используемых данных. Whale поддерживает возможность определения метрик в простом SQL, который будут выполняться по расписанию вместе с вашими конвейерами очистки метаданных. Определите блок metrics в формате YAML внутри таблицы заглушки, и Whale будет автоматически выполняться по расписанию и запускать вложенные в metrics запросы.
```metrics
metric-name:
sql: |
select count(*) from table
``` 
В сочетании с Github такой подход означает, что whale может служить легким центральным источником истины для определений метрик. Whale даже сохраняет значения вместе с меткой времени в каталоге»~/. whale/metrics», если вы хотите сделать какой-то график или более глубокое исследование.
Будущее
Поговорив с пользователями наших предрелизных версий whale, мы поняли, что людям нужна более широкая функциональность. Почему именно инструмент табличного поиска? Почему не инструмент поиска метрик? Почему не мониторинга? Почему не инструмент выполнения запросов SQL? Хотя whale v1 изначально задумывался как простой инструмент-компаньон CLI Dataportal/Amundsen, он уже превратился в полнофункциональную автономную платформу, и мы надеемся, что он станет неотъемлемой частью инструментария дата-сайентиста.
Если есть что-то, что вы хотите видеть в процессе разработки, присоединяйтесь к нашему , откройте Issues на , или даже обращайтесь непосредственно в . У нас уже есть целый ряд интересных функций — шаблоны Jinja, закладки, фильтры поиска, оповещения Slack, интеграция с Jupyter, даже панель CLI для метрик — но мы будем рады вашему вкладу.
Заключение
Whale разрабатывается и поддерживается Dataframe, стартапом, который я недавно имел удовольствие основать вместе с другими людьми. Тогда как whale создан для специалистов по обработке данных, Dataframe предназначен для команд обработки данных. Для тех из вас, кто хочет сотрудничать теснее — не стесняйтесь , мы добавим вас в лист ожидания.
А по промокоду HABR, можно получить дополнительные 10% к скидке указанной на баннере.
Eще курсы
Рекомендуемые статьи
Источник: habr.com
