

Многие знакомы с СУБД PostgreSQL, и она отлично зарекомендовала себя на небольших инсталляциях. Однако тенденция к переходу на Open Source стала все более явной, даже когда речь идет о крупных компаниях и enterprise требованиях. В этой статье мы расскажем, как встроить Postgres в корпоративную среду, и поделимся опытом создания системы резервного копирования (СРК) для этой базы данных на примере системы резервного копирования Commvault.

PostgreSQL уже доказала свою состоятельность — СУБД прекрасно работает, ее используют модные цифровые бизнесы типа Alibaba и TripAdvisor, а отсутствие лицензионных платежей делает ее соблазнительной альтернативой таких монстров, как MS SQL или Oracle DB. Но как только мы начинаем размышлять о PostgreSQL в ландшафте Enterprise, сразу упираемся в жесткие требования: «А как же отказоустойчивость конфигурации? катастрофоустойчивость? где всесторонний мониторинг? а автоматизированное резервное копирование? а использование ленточных библиотек как напрямую, так и вторичного хранилища?»
С одной стороны, у PostgreSQL нет встроенных средств резервного копирования, как у «взрослых» СУБД типа RMAN у Oracle DB или SAP Database Backup. С другой — поставщики корпоративных систем резервного копирования (Veeam, Veritas, Commvault) хотя и поддерживают PostgreSQL, но по факту работают только с определенной (обычно standalone) конфигурацией и с набором различных ограничений.
Такие специально разработанные для PostgreSQL системы резервного копирования, как Barman, Wal-g, pg_probackup, крайне популярны в небольших инсталляциях СУБД PostgreSQL или там, где не нужны тяжёлые бэкапы других элементов ИТ-ландшафта. Например, помимо PostgreSQL, в инфраструктуре могут быть физические и виртуальные серверы, OpenShift, Oracle, MariaDB, Cassandra и т.д. Всё это желательно бэкапить общим инструментом. Ставить отдельное решение исключительно для PostgreSQL— неудачная затея: данные будут копироваться куда-то на диск, а потом их нужно убирать на ленту. Такое задвоение резервного копирования увеличивает время бэкапа, а также, что более критично, — восстановления.
В enterprise решении резервное копирование инсталляции происходит с некоторым числом нод выделенного кластера. При этом, например, Commvault умеет работать только с двухнодовым кластером, в котором Primary и Secondary жестко закреплены за определенными нодами. Да и смысл бэкапиться есть только с Primary, потому что резервное копирование с Secondary имеет свои ограничения. Из-за особенностей СУБД дамп на Secondary не создается, и поэтому остается только возможность файлового бэкапа.
Чтобы снизить риски простоя, при создании отказоустойчивой системы образуется «живая» кластерная конфигурация, и Primary может постепенно мигрировать между разными серверами. Например, ПО Patroni само запускает Primary на рандомно выбранной ноде кластера. У СРК нет способа отслеживать это «из коробки», и, если меняется конфигурация, процессы ломаются. То есть внедрение внешнего управления мешает СРК эффективно работать, потому что управляющий сервер просто не понимает, откуда и какие данные нужно копировать.
Еще одна проблема — реализация бэкапа в Postgres. Она возможна через dump, и на малых базах это работает. Но в больших БД дамп делается долго, требует много ресурсов и может привести к сбою экземпляра БД.
Файловый бэкап исправляет ситуацию, но на больших базах он идет медленно, потому что работает в однопоточном режиме. К тому же у вендоров появляется целый ряд дополнительных ограничений. То нельзя одновременно использовать файловый и дамповый бэкап, то не поддерживается дедупликация. Проблем оказывается много, и чаще всего проще вместо Postgres выбрать дорогую, но проверенную СУБД.
Отступать некуда! Позади Москва разработчики!
Однако недавно наша команда оказалась перед непростым вызовом: в проекте создания АИС ОСАГО 2.0, где мы делали ИТ-инфраструктуру, разработчики для новой системы выбрали PostgreSQL.
Крупным разработчикам ПО намного проще использовать «модные» open-source решения. В штате того же Facebook достаточно специалистов, поддерживающих работу этой СУБД. А в случае с РСА все задачи «второго дня» ложились на наши плечи. От нас требовалось обеспечить отказоустойчивость, собрать кластер и, конечно, наладить резервное копирование. Логика действий была такая:
- Научить СРК делать бэкап с Primary-ноды кластера. Для этого СРК должна находить ее — значит, нужна интеграция с тем или иным решением по управлению кластером PostgreSQL. В случае с РСА для этого использовалось программное обеспечение Patroni.
- Определиться с типом бэкапа, исходя из объемов данных и требований к восстановлению. Например, когда надо восстанавливать страницы гранулярно, использовать дамп, а если базы большие и гранулярного восстановления не требуется — работать на уровне файлов.
- Прикрутить к решению возможность блочного бэкапа, чтобы создавать резервную копию в многопоточном режиме.
При этом изначально мы задались целью создать эффективную и простую систему без монструозной обвязки из дополнительных компонентов. Чем меньше костылей, тем меньше нагрузка на персонал и ниже риск выхода СРК из строя. Подходы, в которых использовались Veeam и RMAN, мы сразу исключили, потому что комплект из двух решений уже намекает на ненадежность системы.
Немного магии для enterprise
Итак, нам нужно было гарантировать надежное резервное копирование для 10 кластеров по 3 ноды каждый, при этом в резервном ЦОД зеркально располагается такая же инфраструктура. ЦОД в плане PostgreSQL работают по принципу active-passive. Общий объем баз данных составлял 50 ТБ. С этим легко справится любая СРК корпоративного уровня. Но нюанс в том, что изначально в Postgres нет и зацепки для полной и глубокой совместимости с системами резервного копирования. Поэтому нам пришлось искать решение, которое изначально обладает максимумом функциональности в связке с PostgreSQL, и дорабатывать систему.
Мы провели 3 внутренних «хакатона» — отсмотрели больше полусотни наработок, тестировали их, вносили изменения в связи со своими гипотезами, снова проверяли. Проанализировав доступные опции, мы выбрали Commvault. Этот продукт уже «из коробки» мог работать с простейшей кластерной инсталляцией PostgreSQL, а его открытая архитектура вызывала надежду (которая оправдалась) на успешную доработку и интеграцию. Также Commvault умеет выполнять бэкап логов PostgreSQL. Например, Veritas NetBackup в части PostgreSQL умеет делать только полные бэкапы.
Подробнее про архитектуру. Управляющие серверы Commvault были установлены в каждом из двух ЦОД в конфигурации CommServ HA. Система зеркальная, управляется через одну консоль и с точки зрения HA отвечает всем требованиям enterprise.
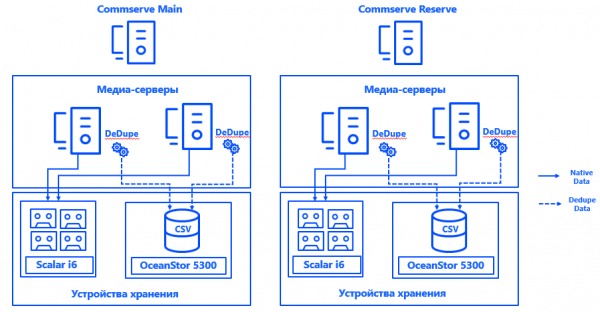
Также в каждом ЦОД мы запустили по два физических медиа-сервера, к которым через SAN по Fibre Channel подключили выделенные специально для бэкапов дисковые массивы и ленточные библиотеки. Растянутые базы дедупликации обеспечили отказоустойчивость медиасерверов, а подключение каждого сервера к каждому CSV — возможность непрерывной работы при выходе из строя любой компоненты. Архитектура системы позволяет продолжать резервное копирование, даже если упадет один из ЦОД.
Patroni для каждого кластера определяет Primary-ноду. Ей может оказаться любая свободная нода в ЦОД — но только в основном. В резервном все ноды — Secondary.
Чтобы Commvault понимал, какая нода кластера является Primary, мы интегрировали систему (спасибо открытой архитектуре решения) с Postgres. Для этого был создан скрипт, который сообщает о текущем расположении Primary-ноды управляющему серверу Commvault.
В целом, процесс выглядит так:
Patroni выбирает Primary → Keepalived поднимает IP-кластер и запускает скрипт → агент Commvault на выбранной ноде кластера получает уведомление, что это Primary → Commvault автоматически перенастраивает бэкап в рамках псевдоклиента.
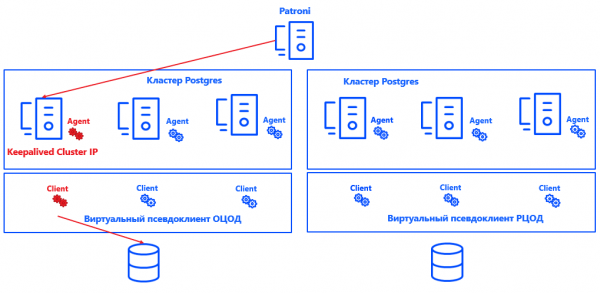
Плюс такого подхода в том, что решение не влияет ни на консистентность, ни на корректность логов, ни на восстановление инстанса Postgres. Оно также легко масштабируется, потому что теперь не обязательно фиксировать для Commvault Primary и Secondary-ноды. Достаточно, что система понимает, где Primary, и число узлов может быть увеличено практически до любого значения.
Решение не претендует на идеальность и имеет свои нюансы. Commvault умеет бэкапить только инстанс целиком, а не отдельные базы. Поэтому для каждой БД создан отдельный инстанс. Реальные клиенты объединены в виртуальные псевдоклиенты. Каждый псевдоклиент Commvault представляет собой UNIX кластер. В него добавляются те ноды кластера, на которых установлен агент Commvault для Postgres. В результате все виртуальные ноды псевдоклиента бэкапятся как один инстанс.
Внутри каждого псевдоклиента указана активная нода кластера. Именно ее и определяет наше интеграционное решение для Commvault. Принцип его работы достаточно прост: если на ноде поднимается кластерный IP, скрипт устанавливает в бинарнике агента Commvault параметр «активная нода» — фактически скрипт ставит «1» в нужной части памяти. Агент передает эти данные на CommServe, и Commvault делает бэкап с нужного узла. Кроме этого, на уровне скрипта проверяется корректность конфигурации, помогая избежать ошибок при запуске резервного копирования.
При этом большие базы данных бэкапятся блочно в несколько потоков, отвечая требованиям RPO и окна резервного копирования. Нагрузка на систему незначительна: Full-копии происходят не так часто, в остальные дни собираются только логи, причем в периоды низкой нагрузки.
Кстати, мы применили отдельные политики для резервного копирования архивных журналов PostgreSQL — они хранятся по другим правилам, копируются по другому расписанию и для них не включается дедупликация, так как эти журналы несут в себе уникальные данные.
Чтобы обеспечить консистентность всей ИТ-инфраструктуры, отдельные файловые клиенты Commvault установлены на каждой из нод кластера. Они исключают из резервных копий файлы Postgres и предназначены только для бэкапа ОС и прикладных приложений. Для этой части данных тоже предусмотрена своя политика, и свой срок хранения.

Сейчас СРК не влияет на продуктивные сервисы, но, если ситуация изменится, в Commvault можно будет включить систему ограничения нагрузки.
Годится? Годится!
Итак, мы получили не просто работоспособный, но и полностью автоматизированный бэкап для кластерной инсталляции PostgreSQL, причем соответствующий всем требованиями вызовам enterprise.
Параметры RPO и RTO в 1 час и 2 часа перекрыты с запасом, а значит, система будет соответствовать им и при значительном росте объемов хранимых данных. Вопреки множеству сомнений, PostgreSQL и enterprise-среда оказались вполне совместимы. И теперь мы по своему опыту знаем, что бэкап для подобных СУБД возможен в самых разнообразных конфигурациях.
Конечно, на этом пути нам пришлось износить семь пар железных сапог, преодолеть ряд трудностей, наступить на несколько граблей и исправить некоторое количество ошибок. Но теперь подход уже опробован и может применяться для внедрения Open Source вместо проприетарных СУБД в суровых условиях enterprise.
А вы пробовали работать с PostgreSQL в корпоративной среде?
Авторы:
Олег Лавренов, инженер-проектировщик систем хранения данных «Инфосистемы Джет»
Дмитрий Ерыкин, инженер-проектировщик вычислительных комплексов «Инфосистемы Джет»
Источник: habr.com
