

Еще в 2016 году мы в Buffer , и сейчас около 60 нод (на AWS) и 1500 контейнеров трудятся на нашем k8s-кластере под управлением . Тем не менее, на микросервисы мы переходили методом проб и ошибок, и даже после нескольких лет нашей работы с k8s мы до сих пор сталкиваемся с новыми для себя проблемами. В этом посте мы поговорим про процессорные ограничения: почему мы считали их хорошей практикой и почему в итоге они оказались не столь хороши.
Процессорные ограничения и троттлинг
Как и многие другие пользователи Kubernetes, . Без такой настройки контейнеры в ноде могут занять все мощности процессора, из-за чего, в свою очередь, важные Kubernetes-процессы (например kubelet) перестанут реагировать на запросы. Таким образом, настройка процессорных ограничений это хороший способ защиты ваших нод.
Процессорные ограничения задают контейнеру максимальное процессорное время, которым он может воспользоваться за конкретный период (по умолчанию 100мс), и контейнер никогда не перешагнет этот предел. В Kubernetes для троттлинга контейнера и недопущения превышения им предела используется особый инструмент , однако в итоге такие искусственные процессорные ограничения занижают производительность и увеличивают время отклика ваших контейнеров.
Что может случиться, если мы не зададим процессорные ограничения?
К несчастью, нам самим довелось столкнуться с этой проблемой. На каждой ноде есть отвечающий за управление контейнерами процесс kubelet, и он перестал реагировать на запросы. Нода, когда это случится, перейдет в состояние NotReady, а контейнеры из нее будут перенаправлены куда-то еще и создадут те же проблемы уже на новых нодах. Не идеальный сценарий, мягко говоря.
Проявление проблемы троттлинга и отклика
Ключевая метрика по отслеживанию контейнеров это trottling, она показывает сколько раз троттлился ваш контейнер. Мы с интересом обратили внимание на наличие троттлинга в некоторых контейнерах вне зависимости от того была ли нагрузка на процессор предельной или нет. Для примера давайте взглянем на один из наших основных API:
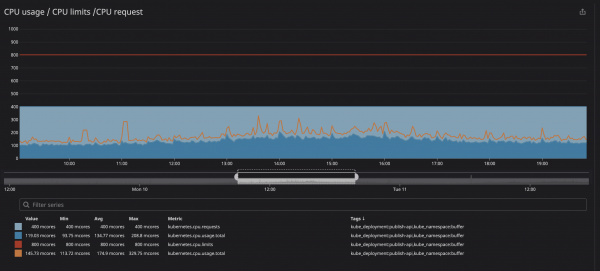
Как можно видеть ниже, мы задали ограничение в 800m (0.8 или 80% ядра), и пиковые значения в лучшем случае достигают 200m (20% ядра). Казалось бы, до троттлинга сервиса у нас еще полно процессорных мощностей, однако…
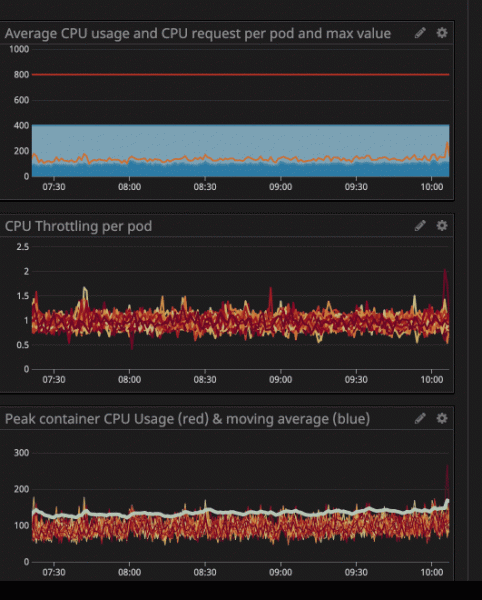
Вы могли заметить, что даже при нагрузке на процессор ниже заданных ограничений — значительно ниже — все равно срабатывает троттлинг.
Столкнувшись с этим, мы вскоре обнаружили несколько ресурсов (, , ) про падение производительности и времени отклика сервисов из-за троттлинга.
Почему мы наблюдаем троттлинг при низкой нагрузке процессора? Краткая версия звучит так: «в ядре Linux есть баг, из-за которого срабатывает необязательный троттлинг контейнеров с заданными процессорными ограничениями». Если вас интересует природа проблемы, вы можете ознакомиться с презентацией ( и варианты) за авторством Дейва Чилука (Dave Chiluk).
Снятие процессорных ограничений (с особой осторожностью)
После длительных обсуждений, мы приняли решение снять процессорные ограничения со всех сервисов, которые прямо или косвенно затрагивали критические важный для наших пользователей функционал.
Решение оказалось непростым, поскольку мы высоко ценим стабильность нашего кластера. В прошлом мы уже экспериментировали с нестабильностью нашего кластера, и тогда сервисы потребляли слишком много ресурсов и тормозили работу всей своей ноды. Теперь же все было несколько иначе: у нас имелось четкое понимание того, что мы ждем от наших кластеров, а так же хорошая стратегия по реализации планируемых изменений.

Деловая переписка по насущному вопросу.
Как защитить ваши ноды при снятии ограничений?
Изолирование «неограниченных» сервисов:
В прошлом мы уже наблюдали, как некоторые ноды попадали в состояние notReady, в первую очередь из-за сервисов которые потребляли слишком много ресурсов.
Мы решили разместить такие сервисы в отдельные («помеченные») ноды, чтобы те не мешали «связанным» сервисам. В итоге благодаря отметкам к некоторым нодам и добавлению параметра toleration («толератность») к «несвязанным» сервисам, мы добились большего контроля над кластером, и нам стало легче определять проблемы с нодами. Чтобы самостоятельно провести аналогичные процессы, вы можете ознакомиться с .
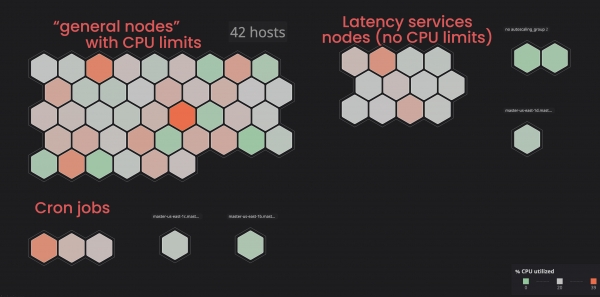
Назначение корректного запроса процессора и памяти:
Больше всего мы опасались, что процесс сожрет слишком много ресурсов и нода перестанет отвечать на запросы. Так как теперь (благодаря Datadog) мы могли четко наблюдать за всеми сервисами на нашем кластере, я проанализировал несколько месяцев работы тех из них, которые мы планировали назначить «несвязанными». Я попросту задал максимальное использование процессора с запасом в 20%, и таким образом выделил место в ноде на случай, если k8s будет пробовать назначать другие сервисы в ноду.
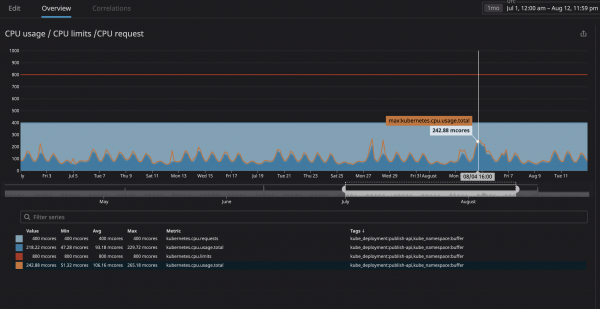
Как можно видеть на графике, максимальная нагрузка на процессор достигла 242m CPU ядер (0.242 ядра процессора). За запрос процессора достаточно взять число чуть большее от этого значения. Обратите внимание, что так как сервисы ориентированы на пользователей, пиковые значения нагрузки совпадают с трафиком.
Сделайте то же самое с использованием памяти и запросами, и вуаля — вы все настроили! Для большей безопасности вы можете добавить горизонтальное автоскалирование подов. Таким образом каждый раз, когда нагрузка на ресурсы будет высока, автоскалирование создаст новые поды, и kubernetes распределит их в ноды со свободным местом. На случай если места не останется в самом кластере, вы можете задать себе оповещение или настроить добавление новых нод через их автоскалирование.
Из минусов стоит отметить, что мы потеряли в «», т.е. числа работающих в одной ноде контейнеров. Еще у нас может оказаться много «послаблений» при низкой плотности трафика, а так же есть шанс, что вы достигнете высокой процессорной нагрузки, но с последним должно помочь автоскалирование нод.
Результаты
Я рад опубликовать эти отличные результаты экспериментов последних нескольких недель, мы уже отметили значительные улучшения отклика среди всех модифицированных сервисов:
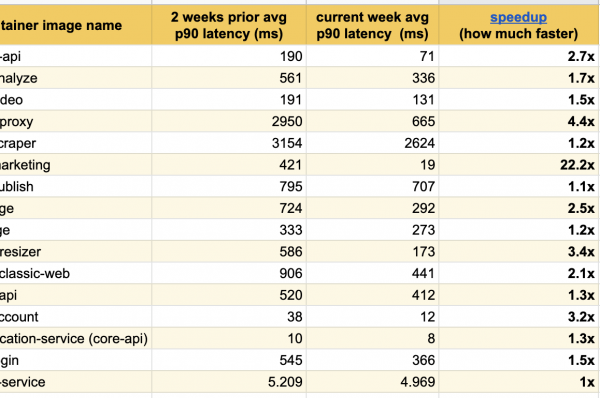
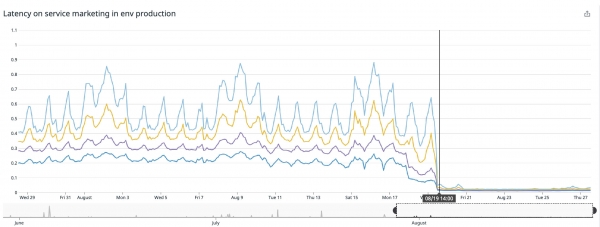
Наилучшего результата мы добились на нашей главной странице (), там сервис ускорился в двадцать два раза!
Исправлен ли баг ядра Linux?
Да, дистрибутивов версии 4.19 и выше.
Тем не менее, при прочтении за второе сентября 2020 года мы все еще сталкиваемся с упоминаниями некоторых Linux-проектов с аналогичным багом. Я полагаю, что в некоторых дистрибутивах Linux все еще есть эта ошибка и сейчас только ведется работа над ее исправлением.
Если ваша версия дистрибутива ниже 4.19, я бы порекомендовал обновиться до последней, но вам в любом случае стоит попробовать снять процессорные ограничения и посмотреть сохранится ли троттлинг. Ниже можно ознакомиться с неполным списком управляющих Kubernetes сервисов и Linux дистрибутивов:
- Debian: фикс интегрирован в последнюю версию дистрибутива, , и выглядит достаточно свежим (). Некоторые предыдущие версии тоже могут быть пофикшены.
- Ubuntu: фикс интегрирован в последнюю версию
- EKS обзавелся фиксом еще . Если ваша версия ниже этой, следует обновить AMI.
- kops: у
kops 1.18+основным образом хоста станет Ubuntu 20.04. Если ваша версия kops старше, вам, вероятно, придется подождать фикса. Мы и сами сейчас ждем. - GKE (Google Cloud): Фикс интегрирован , однако проблемы с троттлингом .
Что делать, если фикс исправил проблему с троттлингом?
Я не уверен, что проблема полностью решена. Когда мы доберемся до версии ядра с фиксом, я протестирую кластер и обновлю пост. Если кто-то уже обновился, я с интересом ознакомлюсь с вашими результатами.
Заключение
- Если вы работаете с Docker-контейнерами под Linux (не важно Kubernetes, Mesos, Swarm или еще какими), ваши контейнеры могут терять в производительности из-за троттлинга;
- Попробуйте обновиться до последней версии вашего дистрибутива в надежде, что баг уже пофиксили;
- Снятие процессорных ограничений решит проблему, но это опасный прием, который следует применять с особой осторожностью (лучше сначала обновить ядро и сравнить результаты);
- Если вы сняли процессорные ограничения, внимательно отслеживайте использование процессора и памяти, и убедитесь, что ваши ресурсы процессора превышают потребление;
- Безопасным вариантом будет автоскалирование подов для создания новых подов в случае высокой нагрузки на железо, чтобы kubernetes назначал их в свободные ноды.
Я надеюсь, этот пост поможет вам улучшить производительность ваших контейнерных систем.
P.S. автор ведет переписку с читателями и комментаторами (на английском).
Источник: habr.com
