


В докладе Андрей Бородин расскажет, как они учли опыт масштабирования PgBouncer при проектировании пулера соединений , как выкатывали его в production. Кроме того, обсудим какие функции пулера хотелось бы видеть в новых версиях: нам важно не только закрывать свои потребности, но развивать сообщество пользователей .
Видео:


Всем привет! Меня зовут Андрей.

В Яндексе я занимаюсь разработкой open source баз данных. И сегодня у нас тема про connection pooler соединений.

Если вы знаете, как назвать connection pooler по-русски, то скажите мне. Я очень хочу найти хороший технический термин, который должен устояться в технической литературе.
Тема довольно сложная, потому что во многих базах данных connection pooler встроенный и про него даже знать не надо. Какие-то настройки, конечно, везде есть, но в Postgres так не получается. И параллельно (на HighLoad++ 2019) идет доклад Николая Самохвалова про настройку запросов в Postgres. И я так понимаю, что сюда пришли люди, которые уже настроили запросы идеально, и это люди, которые сталкиваются с более редкими системными проблемами, связанные с сетью, утилизацией ресурсов. И местами это может было довольно сложно в том плане, что проблемы неочевидные.

В Яндексе есть Postgres. В Яндекс.Облаке живут многие сервисы Яндекса. И у нас несколько петабайт данных, которые генерируют не меньше миллиона запросов в секунду в Postgres.
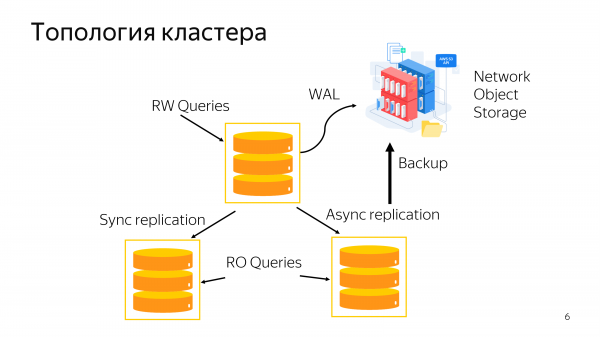
И мы предоставляем достаточно типовой кластер всем сервисам – это основная primary нода узла, обычные две реплики (синхронная и асинхронная), резервное копирование, масштабирование читающих запросов на реплике.
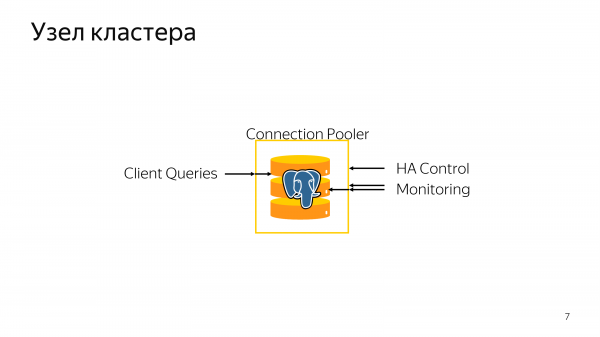
Каждый узел кластера – это Postgres, на котором кроме Postgres и систем мониторинга еще установлен connection pooler. Connection pooler используется для fencing и по своему основному назначению.

Что такое основное назначение connection pooler?

В Postgres принята процессная модель при работе с базой данных. Это означает, что одно соединение – это один процесс, один бэкенд Postgres. И в этом бэкенде очень много различных кэшей, которые довольно дорого делать разными для различных соединений.
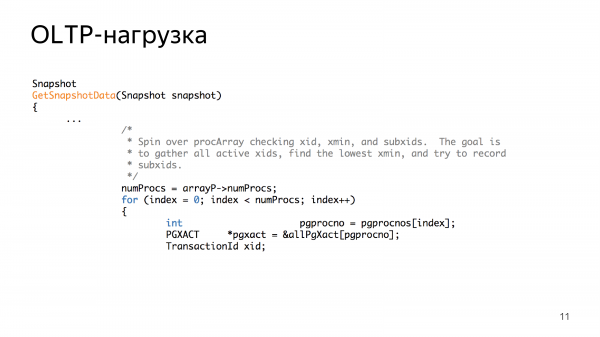
Кроме того, в коде Postgres есть массив, который называется procArray. Он содержит основные данные о сетевых соединениях. И почти все алгоритмы обработки procArray имеют линейную сложность, они пробегаются по всему массиву сетевых соединений. Это довольно быстрый цикл, но с большим количеством входящих сетевых соединений все становится немного дороже. А когда все стало немножко дороже, в итоге можно заплатить очень большую цену за большое количество сетевых соединений.

Существуют 3 возможных подхода:
- На стороне приложения.
- На стороне базы данных.
- И между, т. е. всевозможные комбинации.
К сожалению, встроенный pooler сейчас находится в стадии разработки. Друзья в компании PostgreSQL Professional в основном этим занимаются. Когда он появится, сложно предсказать. И фактически на выбор архитектора у нас два решения. Это application-side pool и proxy pool.
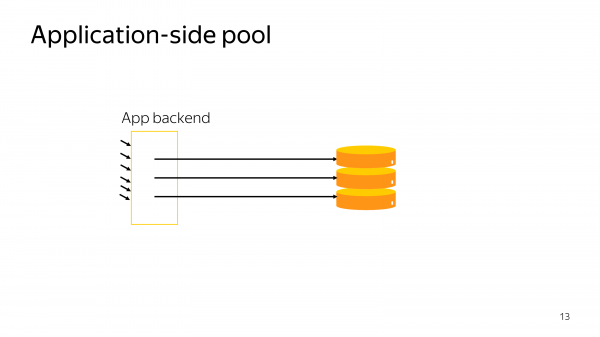
Application-side pool – это самый простой способ. И почти все клиентские драйвера вам предоставляют способ: миллионы ваших соединений в коде представить в виде некоторых десятков соединений в базу данных.
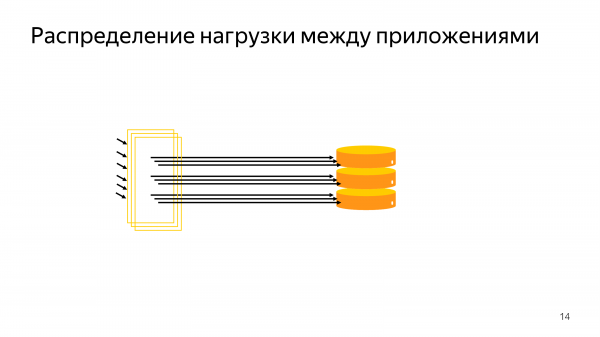
Возникает проблема с тем, что в определенный момент вы хотите масштабировать бэкенд, вы хотите развернуть его на множество виртуальных машин.
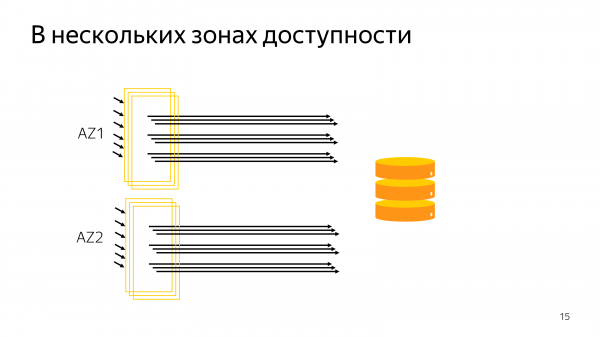
Потом вы еще осознаете, что у вас еще несколько зон доступностей, несколько дата-центров. И подход с client side pooling приводит к большим числам. Большие – это порядка 10 000 соединений. Это край, что может нормально работать.

Если говорить про proxy poolers, то есть два poolers, которые умеют много всего. Они не только poolers. Они poolers + еще классная функциональность. Это и .
Но, к сожалению, эта дополнительная функциональность не всем нужна. И она приводит к тому, что poolers поддерживают только сессионный pooling, т. е. один входящий клиент, один исходящий клиент в базу данных.
Для наших задач это не очень хорошо подходит, поэтому мы используем PgBouncer, который реализует transaction pooling, т. е. серверные соединения сопоставляются клиентским соединениям только на время транзакции.

И на нашей нагрузке – это правда. Но есть несколько проблем.
Проблемы начинаются, когда вы хотите диагностировать сессию, потому что все входящие соединения у вас локальные. Все пришли с loopback и как-то трассировать сессию становится сложно.
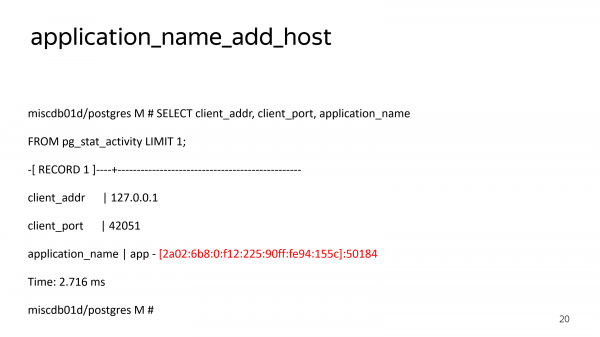
Конечно, вы можете использовать application_name_add_host. Это способ на стороне Bouncer добавить IP-адрес в application_name. Но application_name устанавливается дополнительным соединением.
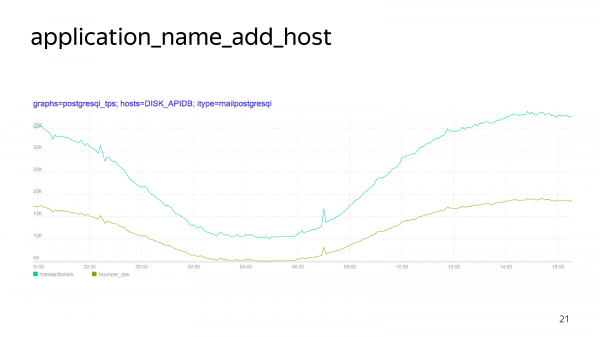
На этом графике, где желтая линия – это реальные запросы, а где синяя – запросы, которые влетают в базу. И вот эта разница – это именно установка application_name, который нужен только для трассировки, но он совершенно не бесплатный.

Кроме того, в Bouncer нельзя ограничить один pool, т. е. количество соединений с базой данных на определенного пользователя, на определенную базу.
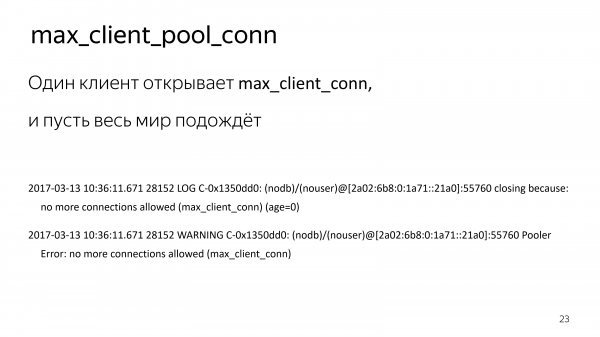
К чему это приводит? У вас есть нагруженный сервис, написанный на C++ и где-то рядом маленький сервис на ноде, который ничего страшного с базой не делает, но его драйвер сходит с ума. Он открывает 20 000 соединений, а все остальное подождет. У вас даже код нормальный.

Мы, конечно, написали маленький патч для Bouncer, который добавил эту настройку, т. е. ограничение клиентов на pool.

Можно было бы это сделать на стороне Postgres, т. е. роли в базе данных ограничить количеством соединений.
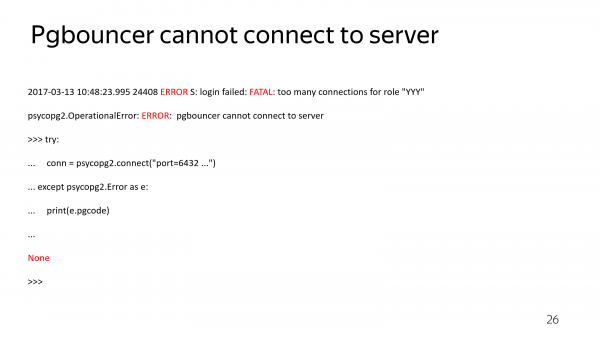
Но тогда вы теряете возможность понять, почему у вас нет соединений с сервером. PgBouncer не пробрасывает ошибку соединения, он возвращает всегда одну и ту же информацию. И вы не можете понять: может быть, у вас пароль поменялся, может быть, просто база легла, может быть, что-то не так. Но диагностики никакой нет. Если сессию нельзя установить, вы не узнаете, почему это нельзя сделать.
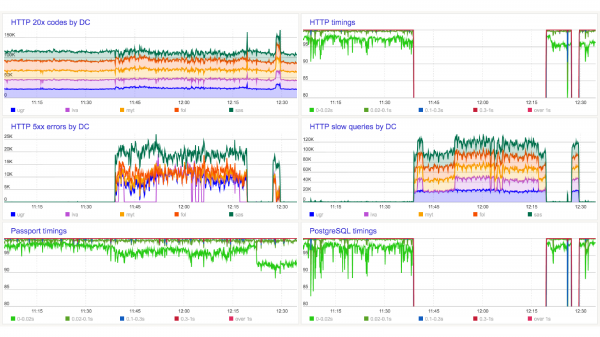
В определенный момент вы смотрите на графики приложения и видите, что приложение не работает.
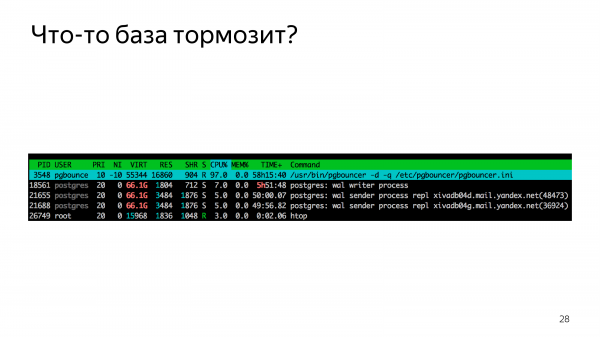
Смотрите в топ и видите, что Bouncer однопоточный. Это поворотный момент в жизни сервиса. Вы понимаете, что вы готовились к масштабированию базы данных через полтора года, а вам нужно масштабировать pooler.

Мы пришли к тому, что нам надо больше PgBouncer’ов.

Немножко запатчили Bouncer.
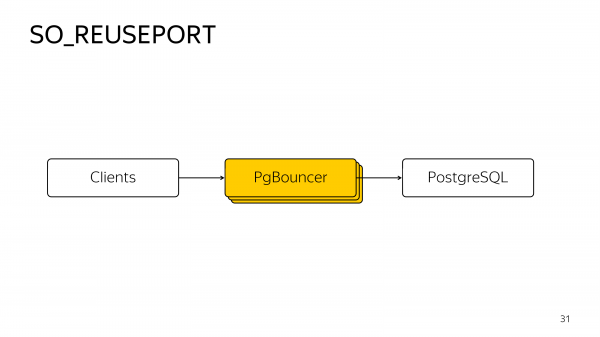
И сделали так, что могут быть подняты с переиспользованием TCP-порта несколько Bouncers. И уже операционная система входящие TCP-соединения между ними автоматически round-robin’ом перекладывает.

Это прозрачно для клиентов, т. е. все выглядит так, как будто у вас один Bouncer, но у вас есть фрагментация idle-соединений между запущенными Bouncer’ами.
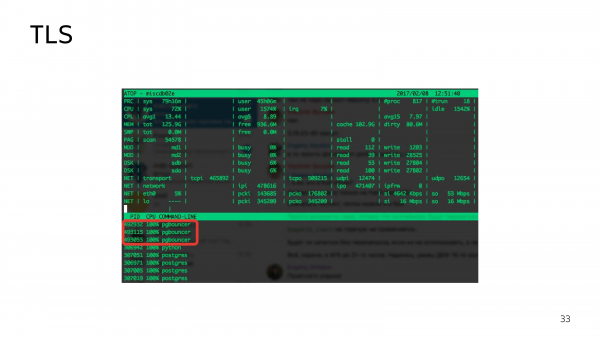
И в определенный момент вы можете заметить, что вот эти 3 Bouncers съедают каждый свое ядро на 100 %. Вам нужно довольно много Bouncers. Почему?

Потому что у вас есть TLS. У вас есть шифрованное соединение. И если пробенчмаркать Postgres с TLS и без TLS, то вы обнаружите, что количество установленных соединений падает почти на два порядка с включением шифрования, потому что TLS handshake потребляет ресурсы центрального процессора.
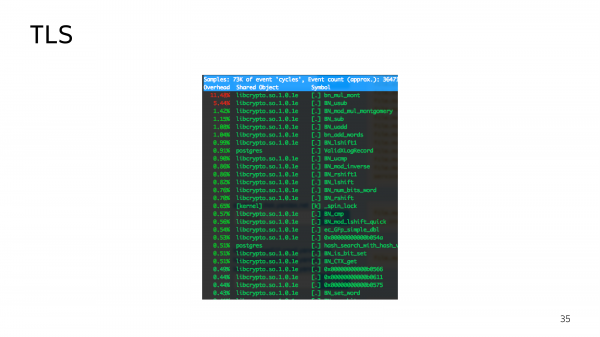
И в топе вы можете увидеть довольно много криптографических функций, которые выполняются при волне входящих соединений. Поскольку у нас primary может переключаться между зонами доступности, то волна входящих соединений – это довольно типичная ситуация. Т. е. по какой-то причине старый primary был недоступен, всю нагрузку отправили в другой дата-центр. Они все одновременно придут поздороваться с TLS.

И большое количество TLS handshake может не здороваться уже с Bouncer, а горло ему сдавить. Из-за таймаута волна входящих соединений может стать незатухающей. Если у вас retry в базу без exponential backoff, они не будут приходят снова и снова когерентной волной.
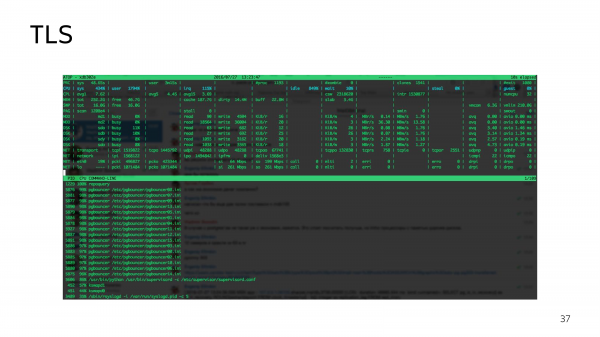
Вот пример 16 PgBouncer, которые грузят 16 ядер на 100 %.
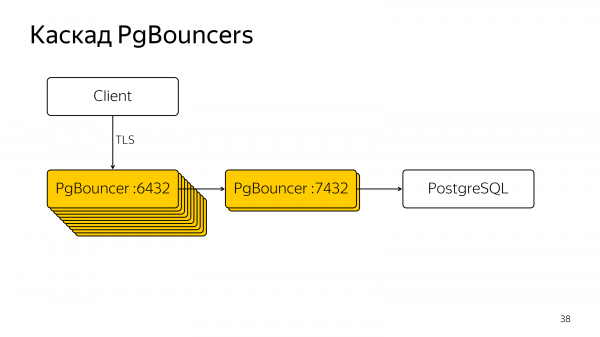
Мы пришли к каскадному PgBouncer. Это лучшая конфигурация, которую можно достигнуть на нашей нагрузке с Bouncer. Внешние Bouncers у нас служат для TCP handshake, а внутренние Bouncers служат для реального pooling, для того, чтобы не сильно фрагментировать внешние соединения.

В такой конфигурации возможен плавный рестарт. Можно рестартить все эти 18 Bouncers по одному. Но поддерживать такую конфигурацию довольно сложно. Системные администраторы, DevOps и люди, которые действительно несут ответственность за этот сервер, будут не очень рады такой схеме.

Казалось бы, можно все наши доработки продвигать в open source, но Bouncer не очень хорошо саппортится. Например, возможность, запустить несколько PgBouncers на одном порту закоммитили месяц назад. А pull request с этой функцией был несколько лет назад.

Или еще один пример. В Postgres вы можете отменить выполняющийся запрос, отправив секрет по-другому соединению без лишней аутентификации. Но некоторые клиенты отправляют просто TCP-reset, т. е. рвут сетевое соединение. Что при этом сделает Bouncer? Он ничего не сделает. Он продолжит выполнять запрос. Если у вас пришло огромное количество соединений, которые маленькими запросами положили базу, то просто оторвать соединение от Bouncer будет недостаточно, нужно еще завершить те запросы, которые бегут в базе.
Это было запатчено и эту проблему все еще не вмержили в upstream Bouncer’а.

И так мы пришли к тому, что нам нужен свой connection pooler, который будет развиваться, патчиться, в котором можно будет оперативно исправлять проблемы и который, конечно, должен быть многопоточным.

Многопоточность мы поставили как основную задачу. Нам нужно хорошо выдерживать волну входящих TLS-соединений.
Для этого нам пришлось разработать отдельную библиотеку, которая называется Machinarium, которая предназначена для описания машинных состояний сетевого соединения как последовательного кода. Если вы посмотрите в исходный код libpq, то вы увидите довольно сложные вызовы, которые могут вернуть вам результат и сказать: «Вызови меня чуть попозже. Сейчас у меня пока что IO, но, когда IO пройдет у меня нагрузка для процессора». И это многоуровневая схема. Сетевое взаимодействие обычно описывают машиной состояний. Множеством правил типа "Если я раньше получил заголовок пакета размера N, то сейчас я жду N байт", "Если я отправлял пакет SYNC, то сейчас я жду пакет с метаданными результата". Получаентся довольно трудный контринтуитивный код, как если бы лабиринт преобразовали в строчную развёртку. Мы сделали так, что вместо машины состояний программист описывает основной путь взаимодействия в виде обычного императивного кода. Просто в этом императивном коде нужно вставлять места, где последовательность выполнения нужно прервать ожиданием данных от сети, передав контекст выполнения другой корутине (green thread-у). Этот подход аналогичен тому, что мы самый ожидаемый путь в лабиринте записываем подряд, а потом добавляем к нему ответвления.

В итоге у нас есть один поток, который делает TCP accept и round-robin’ом передает множеству workers TPC-соединение.
При этом каждое клиентское соединение работает всегда на одном процессоре. И это позволяет сделать его cache-friendly.
И кроме того, мы доработали немножко сбор маленьких пакетов в один большой пакет для того, чтобы разгрузить системный TCP-stack.

Кроме того, мы улучшили транзакционный пулинг в том плане, что Odyssey при установленной настройке может отправить CANCEL и ROLLBACK в случае обрыва сетевого соединения, т. е. если запрос никто не ждет, Odyssey скажет базе, чтобы она не старалась выполнить тот запрос, который может расходовать драгоценные ресурсы.
И по возможности мы сохраняем соединения за одним и тем же клиентом. Это позволяет не переустанавливать application_name_add_host. Если это возможно, то у нас нет дополнительной переустановки параметров, которые нужны для диагностики.

Мы работаем в интересах Яндекс.Облака. И если вы используете managed PostgreSQL и у вас установлен connection pooler, вы можете создать логическую репликацию наружу, т. е. уехать от нас, если вам захочется, при помощи логической репликации. Bouncer наружу поток логической репликации не отдаст.

Это пример настройки логической репликации.

Кроме того, у нас есть поддержка физической репликации наружу. В Облаке она, конечно, невозможна, потому что тогда вам кластер отдаст слишком много информации про себя. Но в ваших инсталляциях, если вам нужна физическая репликация через connection pooler в Odyssey, это возможно.

В Odyssey полностью совместимый мониторинг с PgBouncer. У нас такая же консоль, которая выполняет почти все те же самые команды. Если чего-то не хватает, присылайте pull request, либо хотя бы issue в GitHub, будем доделывать нужные команды. Но основная функциональность консоли PgBouncer у нас уже есть.

И, конечно, у нас есть error forwarding. Мы вернем ту ошибку, которую сообщила база. Вы получите информацию, почему вы не попадаете в базу, а не просто, что вы в нее не попадаете.
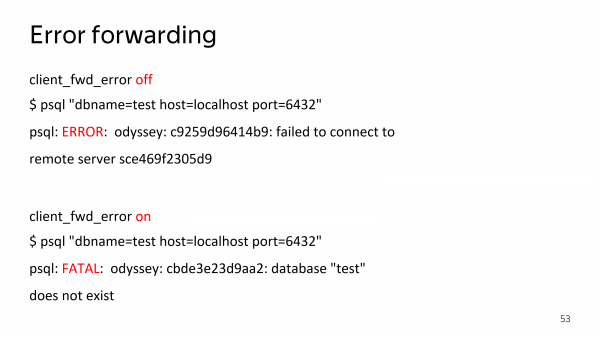
Эта возможность выключается на случай, если вам нужна 100%-ная совместимость с PgBouncer. Мы можем вести себя так же, как Bouncer, просто на всякий случай.
Разработка
Несколько слов об исходном коде Odyssey.
Например, есть команды «Pause /Resume». Они обычно используются для обновления базы данных. Если вам нужно обновить Postgres, то вы можете поставить его на паузу в connection pooler, сделать pg_upgrade, после этого сделать resume. И со стороны клиента это будет выглядеть так, как будто база просто тормозила. Эту функциональность нам принесли люди из сообщества. Она пока еще не помержена, но скоро все будет. (Уже помержена)
— уже помержена
Кроме того, одна из новых фич в PgBouncer, это поддержка SCRAM Authentication, которую нам тоже принес человек, который не работает в Яндекс.Облаке. И то и другое – это сложная функциональность и важная.
Поэтому хочется рассказать из чего сделан Odyssey, вдруг вы тоже сейчас хотите немножко пописать код.
У вас есть исходная база Odyssey, которая опирается на две основные библиотеки. Библиотека Kiwi – это реализация Postgres’ового протокола сообщений. Т. е. нативный proto 3 у Postgres – это стандартные сообщения, которыми фронтенды, бэкенды могут обмениваться. Они реализованы в библиотеке Kiwi.
Библиотека Machinarium – это библиотека реализации потоков. Небольшой фрагмент этого Machinarium написан на ассемблере. Но, не пугайтесь, там всего 15 строчек.
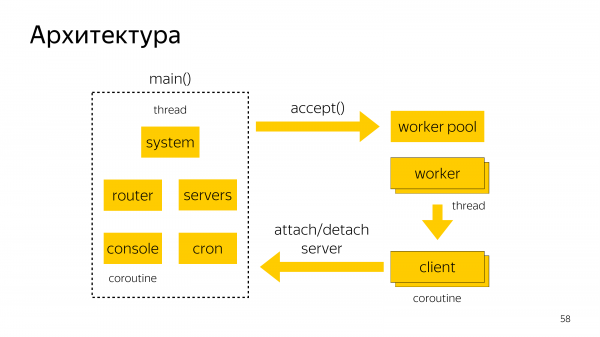
Архитектура Odyssey. Есть основная машина, в которой запущены coroutines. В этой машине реализуется accept входящих TCP-соединений и распределение по workers.
Внутри одного worker может работать обработчик нескольких клиентов. А также в основном потоке крутятся консоль и обработка crone-задач по удалению соединений, которые больше не нужны в pool.

Для тестирования Odyssey используется стандартный набор тестов Postgres. Просто запускаем install-check через Bouncer и через Odyssey, получаем нулевой div. Там несколько тестов, связанные с форматированием дат не проходят абсолютно одинаково в Bouncer и в Odyssey.
Кроме того, есть множество драйверов, которые имеют свое тестирование. И их тесты мы используем для тестирования Odyssey.

Кроме того, из-за нашей каскадной конфигурации нам приходится тестировать различные связки: Postgres + Odyssey, PgBouncer + Odyssey, Odyssey + Odyssey для того, чтобы быть уверенными в том, что, если Odyssey оказался в какой-то из частей в каскаде, он тоже по-прежнему работает так, как мы ожидаем.
Грабли
Мы используем Odyssey в production. И было бы не честно, если бы я сказал, что все просто работает. Нет, т. е. да, но не всегда. Например, в production все просто работало, потом пришли наши друзья из PostgreSQL Professional и сказали, что у нас есть memory leak. Они правда были, мы их исправили. Но это было просто.
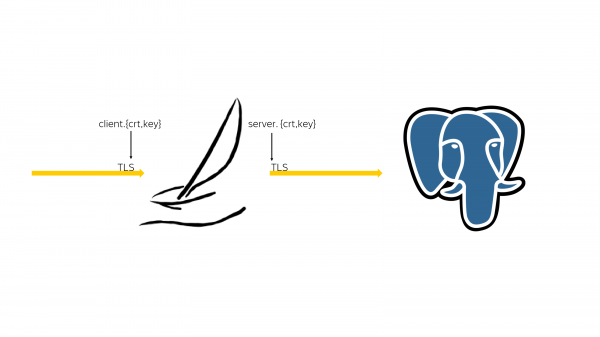
Потом мы обнаружили, что в connection pooler есть входящие TLS-соединения и исходящие TLS-соединения. И в соединениях нужны клиентские сертификаты и серверные сертификаты.
Серверные сертификаты Bouncer и Odyssey перечитывают их pcache, но клиентские сертификаты перечитывать из pcache не надо, потому что наш масштабируемый Odyssey в итоге упирается в системную производительность чтения этого сертификата. Это для нас стало неожиданностью, потому что уперся он далеко не сразу. Сначала он линейно масштабировался, а после 20 000 входящих одновременных соединений эта проблема себя проявила.

Pluggable Authentication Method – это возможность аутентифицироваться встроенными lunux’овыми средствами. В PgBouncer она реализована так, что есть отдельный поток на ожидание ответа от PAM и есть основной поток PgBouncer, который обслуживает текущее соединение и может попросить их пожить в потоке PAM.
Мы это не стали реализовывать по одной простой причине. У нас же много потоков. Зачем нам это нужно?
В итоге это может создавать проблемы с тем, что, если у вас есть PAM-аутентификация и не PAM-аутентификаци, то большая волна PAM-аутентификации может существенно задерживать не PAM-аутентификацию. Это одна из тех штук, которую мы не исправили. Но если вы хотите это исправить, можете заняться вот этим.
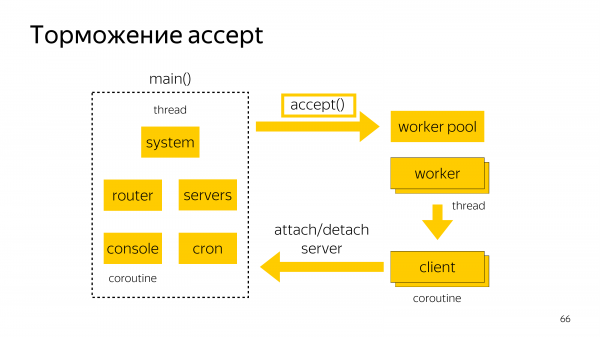
Еще одни грабли были с тем, что у нас есть один поток, который делает accept всем входящим соединениям. И потом их передает на worker pool, где будет происходить TLS handshake.
В итоге, если у вас есть когерентная волна из 20 000 сетевых соединений, они все будут приняты. И на стороне клиента libpq начнет отчет таймаутов. По умолчанию вроде 3 секунды там стоит.
Если они все не могут одновременно зайти в базу, то они не могут зайти в базу, потому что все это может быть покрыто не экспоненциальным retry.
Мы пришли к тому, что скопировали здесь схему с PgBouncer с тем, что у нас есть throttling количества TCP-соединений, которым мы делаем accept.
Если мы видим, что мы аксептим соединения, а они в итоге не успевают похендшейкиться, мы ставим их в очередь для того, чтобы они не расходовали ресурсы центрального процессора. Это приводит к тому, что одновременный handshake может производиться не для всех соединений, которые пришли. Но хотя бы кто-то в базу зайдет, даже если нагрузка достаточно сильная.
Roadmap
Чего хотелось бы увидеть в будущем в Odyssey? Что мы готовы сами разрабатывать и что мы ждем от сообщества?

На август 2019 года.
Вот так выглядел roadmap Odyssey в августе:
- Мы хотели SCRAM и PAM authentication.
- Мы хотели forward читающих запросов на standby.
- Хотелось бы online-restart.
- И возможность делать паузу на сервере.

Половина этого roadmap выполнена, причем не нами. И это хорошо. Поэтому давайте обсудим то, что осталось и добавим еще.
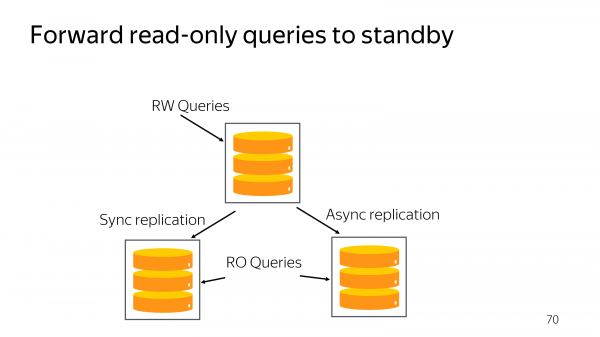
? У нас есть реплики, которые без выполнения запросов будут просто греть воздух. Они нам необходимы для обеспечения failover и switchover. В случае проблем в одном из дата-центре хотелось бы их занять какой-то полезной работой. Потому что те же самые центральные процессоры, ту же самую память мы не можем сконфигурировать по-другому, потому что иначе не будет работать репликация.

В принципе, в Postgres, начиная с 10-ки есть возможность при соединении указать так же session_attrs. Вы в соединении можете перечислить все хосты баз данных и сказать, зачем вы идете в базу данных: записать или только прочитать. И драйвер сам выберет первый по списку хост, который ему больше нравится, который выполняет требования session_attrs.
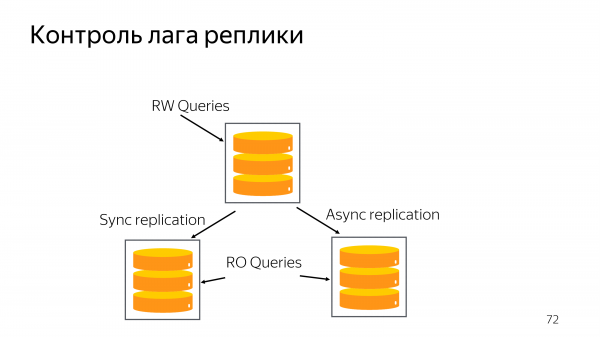
Но проблема этого подхода в том, что он не контролирует лаг репликации. У вас может быть какая-то реплика, которая отстала на неприемлемое для вашего сервиса время. Для того чтобы сделать полнофункциональное выполнение читающих запросов на реплике, по сути, нам нужно поддержать в Odyssey возможность не работать, когда читать нельзя.
Odyssey должен ходить временами в базу и спрашивать репликационное расстояние от primary. И если оно достигло предельного значения, новые запросы в базу не пускать, сказать клиенту, что нужно заново инициировать соединения и, возможно выбрать другой хост для выполнения запросов. Это позволит базе быстрее восстановить репликационный лаг и снова вернуться для ответа запросом.
Сроки реализации сложно назвать, потому что это open source. Но, надеюсь, что не 2,5 года как у коллег из PgBouncer. Вот эту функцию хотелось бы видеть в Odyssey.

. Сейчас вы можете создать prepared statement двумя способами. Во-первых, вы можете выполнить SQL-команду, а именно «prepared». Для того чтобы понять эту SQL-команду нам нужно научиться понимать SQL на стороне Bouncer. Это был бы overkill, потому что это перебор, т. к. нам нужен целиком парсер. Мы не можем парсить каждую SQL-команду.
Но есть prepared statement на уровне протокола сообщений на proto3. И это то место, когда информация о том, что создается prepared statement, приходит в структурированном виде. И мы могли бы поддержать понимание того, что на каком-то серверном соединении клиент попросил создать prepared statements. И даже если транзакция закрылась, нам нужно по-прежнему поддерживать связность сервера и клиента.
Но тут возникает расхождение в диалоге, потому что кто-то говорит о том, что нужно понимать, какой именно prepared statements создал клиент и разделять серверное соединение между всеми клиентами, которые создали это серверное соединение, т. е. которые создали такой prepared statement.
Андрес Фройнд сказал, что если к вам пришел клиент, который уже создавал в другом серверном соединении такой prepared statement, то создайте его за него. Но, кажется, это немножко неправильно выполнять запросы в базе вместо клиента, но с точки зрения разработчика, который пишет протокол взаимодействия с базой, это было бы удобно, если бы ему просто дали сетевое соединение, в котором есть такой подготовленный запрос.
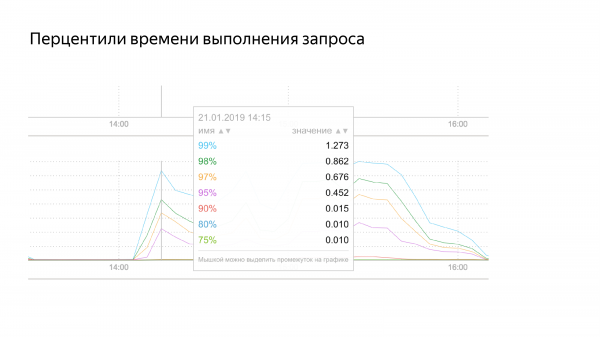
И еще одна фича, которую нам нужно реализовать. У нас сейчас есть мониторинг, совместимый с PgBouncer. Мы можем вернуть среднее время выполнения запроса. Но среднее время – это средняя температура по больнице: кто-то холодный, кто-то теплый – в среднем все здоровы. Это неправда.
Нам нужно реализовать поддержку перцентилей, которые бы указывали на то, что есть медленные запросы, которые расходуют ресурсы, и сделали бы мониторинг более приемлемым.
Самое главное – хочется версию 1.0 (Уже вышла версия 1.1). Дело в том, что сейчас Odyssey находится в версии 1.0rc, т. е. release candidate. И все грабли, которые я перечислил, были починены ровно с той самой версией, кроме memory leak.
Что для нас будет означать версия 1.0? Мы выкатываем Odyssey на свои базы. Он уже сейчас работает на наших базах, но когда он достигнет точки в 1 000 000 запросов в секунду, то мы можем сказать, что это релизная версия и это версия, которую можно назвать 1.0.
В сообществе несколько человек попросили, чтобы в версии 1.0 были еще пауза и SCRAM. Но это будет означать, что нам нужно будет выкатить в production уже следующую версию, потому что ни SCRAM, ни пауза до сих пор не помержены. Но, скорее всего, этот вопрос будет достаточно оперативно решен.

Я жду ваших pull request. И еще хотелось бы услышать, какие у вас есть проблемы с Bouncer. Давайте их обсудим. Может быть, мы сможем какие-то функции реализовать, которые нужны вам.
На этом моя часть закончена, я хотел бы послушать вас. Спасибо!
Вопросы
Если я свой поставлю application_name, он будет правильно прокидываться, в том числе в transaction pooling в Odyssey?
В Odyssey или в Bouncer?
В Odyssey. В Bouncer прокидывается.
Сет мы сделаем.
И если мое реальное соединение будет прыгать по другим соединениям, то он будет передаваться?
Мы сделаем сет всех параметров, которые перечислены в списке. Я не могу сказать, есть ли в этом списке application_name. Кажется, его там видел. Мы установим все те же параметры. Одним запросом там сет сделает все то, что было установлено клиентом при стартапе.
Спасибо, Андрей, за доклад! Хороший доклад! Рад, что Odyssey с каждой минутой развивается все быстрее и быстрее. Желаю так же продолжать. Мы уже к вам обращались с просьбой иметь multi data-source подключение, чтобы Odyssey мог подключаться одновременно к разным базам данных, т. е. мастер slave, а потом автоматически после failover подключаться к новому мастеру.
Да, я, кажется, припоминаю эту дискуссию. Сейчас есть несколько storages. Но переключения между ними нет. Мы должны на своей стороне опрашивать сервер, что он еще жив и понимать, что произошел failover, кто вызовет pg_recovery. У меня есть стандартный способ понять, что мы пришли не на мастер. И мы должны понять как-то из ошибок или как? Т. е. идея интересная, она обсуждается. Пишите больше комментариев. Если у вас есть рабочие руки, которые знают C, то это вообще замечательно.
Вопрос масштабирования по репликам нас тоже интересует, потому что мы хотим сделать adoption реплицированных кластеров максимально простым для разработчиков приложения. Но тут хотелось бы больше комментариев, т. е. как именно сделать, как хорошо сделать.
Вопрос тоже про реплики. Получается, что у вас есть мастер и несколько реплик. И понятно, что в реплику ходят реже, чем в мастер за соединениями, потому что у них может быть отличие. Вы говорили, что отличие в данных может быть такое, что не будет удовлетворять ваш бизнес и вы не будете туда ходить, пока она не дореплицируется. При этом, если вы долго туда не ходили, а потом начали ходить, то те данные, которые нужны, не будут сразу доступны. Т. е. если мы постоянно ходим в мастер, то там кэш прогрет, а в реплике кэш немного отстает.
Да, это правда. В pcache не будет блоков данных, которые вы хотите, в real cache не будет информации о таблицах, которые вы хотите, в планах не будет распарсенных запросов, вообще ничего не будет.
И когда у вас есть какой-то кластер, и вы добавляете туда новую реплику, то пока она стартует, в ней все плохо, т. е. она наращивает свой кэш.
Я понял идею. Правильным подходом было бы запустить маленький процент запросов сначала на реплику, которые бы прогрели кэш. Грубо говоря, у нас есть условие, что мы должны отставать не более, чем на 10 секунд от мастера. И это условие включать не одной волной, а плавно для некоторых клиентов.
Да, увеличивать вес.
Это хорошая идея. Но сначала нужно реализовать это отключение. Сначала надо выключиться, а потом подумаем, как включиться. Это отличная фича, чтобы плавно включаться.
В nginx есть такая опция slowly start в кластере для сервера. И он постепенно наращивает нагрузку.
Да, отличная идея, попробуем, когда дойдем до этого.
Источник: habr.com
