

Микросервисная архитектура, как и все в этом мире, имеет свои плюсы и свои минусы. Одни процессы с ней становятся проще, другие — сложнее. И в угоду скорости изменений и лучшей масштабируемости нужно приносить свои жертвы. Одна из них — усложнение аналитики. Если в монолите всю оперативную аналитику можно свести к SQL запросам к аналитической реплике, то в мультисервисной архитектуре у каждого сервиса своя база и, кажется, что одним запросом не обойтись (а может обойтись?). Для тех, кому интересно, как мы решили проблему оперативной аналитики у себя в компании и как научились жить с этим решением — welcome.

Меня зовут Павел Сиваш, в ДомКлике я работаю в команде, которая отвечает за сопровождение аналитического хранилища данных. Условно нашу деятельность можно отнести к дата инженерии, но, на самом деле, спектр задач гораздо шире. Есть стандартные для дата инженерии ETL/ELT, поддержка и адаптация инструментов для анализа данных и разработка своих инструментов. В частности, для оперативной отчетности мы решили «притвориться», что у нас монолит и дать аналитикам одну базу, в которой будут все необходимые им данные.
Вообще, мы рассматривали разные варианты. Можно было построить полноценное хранилище — мы даже пробовали, но, если честно, так и не удалось подружить достаточно частые изменения в логике с достаточно медленным процессом построения хранилища и внесения в него изменений (если у кого-то получилось, напишите в комментариях как). Можно было сказать аналитикам: «Ребята, учите python и ходите в аналитические реплики», но это дополнительное требование к подбору персонала, и казалось, что этого стоит избежать, если возможно. Решили попробовать использовать технологию FDW (Foreign Data Wrapper): по сути, это стандартный dblink, который есть в стандарте SQL, но со своим гораздо более удобным интерфейсом. На базе нее мы сделали решение, которое в итоге и прижилось, на нем мы остановились. Его подробности — тема отдельной статьи, а может и не одной, поскольку рассказать хочется о многом: от синхронизации схем баз до управления доступом и обезличивания персональных данных. Также нужно оговориться, что это решение не является заменой реальным аналитическим базам и хранилищам, оно решает лишь конкретную задачу.
Верхнеуровнево это выглядит так:
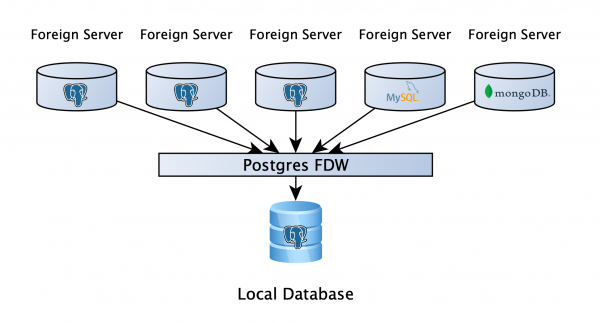
Есть база PostgreSQL, там пользователи могут хранить свои рабочие данные, а самое важное — к этой базе через FDW подключены аналитические реплики всех сервисов. Это дает возможность написать запрос к нескольким базам, причем неважно, что это: PostgreSQL, MySQL, MongoDB или еще что-то (файл, API, если вдруг нет подходящего враппера, можно написать свой). Ну вроде все, супер! Расходимся?
Если бы все заканчивалось так быстро и просто, то, наверное, статьи бы и не было.
Важно четко осознавать, как постгрес обрабатывает запросы к удаленным серверам. Это кажется логичным, однако зачастую на это не обращают внимание: постгрес делит запрос на части, которые выполняются на удаленных серверах независимо, собирает эти данные, а финальные вычисления проводит уже сам, поэтому скорость выполнения запроса будет сильно зависеть от того, как он написан. Следует так же отметить: когда данные поступают с удаленного сервера у них уже нет индексов, нет ничего, что поможет планировщику, следовательно, помочь и подсказать ему можем только мы сами. И именно об этом хочется рассказать подробнее.
Простой запрос и план с ним
Чтобы показать, как постгрес выполняет запрос к таблице на 6 миллионов строк на удаленном сервере, посмотрим на простой план.
explain analyze verbose
SELECT count(1)
FROM fdw_schema.table;
Aggregate (cost=418383.23..418383.24 rows=1 width=8) (actual time=3857.198..3857.198 rows=1 loops=1)
Output: count(1)
-> Foreign Scan on fdw_schema."table" (cost=100.00..402376.14 rows=6402838 width=0) (actual time=4.874..3256.511 rows=6406868 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Remote SQL: SELECT NULL FROM fdw_schema.table
Planning time: 0.986 ms
Execution time: 3857.436 msИспользование инструкции VERBOSE позволяет увидеть запрос, который будет отправлен на удаленный сервер и результаты которого мы получим для дальнейшей обработки (строка RemoteSQL).
Пойдем чуть дальше и добавим в наш запрос несколько фильтров: один по boolean полю, один по вхождению timestamp в интервал и один по jsonb.
explain analyze verbose
SELECT count(1)
FROM fdw_schema.table
WHERE is_active is True
AND created_dt BETWEEN CURRENT_DATE - INTERVAL '7 month'
AND CURRENT_DATE - INTERVAL '6 month'
AND meta->>'source' = 'test';
Aggregate (cost=577487.69..577487.70 rows=1 width=8) (actual time=27473.818..25473.819 rows=1 loops=1)
Output: count(1)
-> Foreign Scan on fdw_schema."table" (cost=100.00..577469.21 rows=7390 width=0) (actual time=31.369..25372.466 rows=1360025 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Filter: (("table".is_active IS TRUE) AND (("table".meta ->> 'source'::text) = 'test'::text) AND ("table".created_dt >= (('now'::cstring)::date - '7 mons'::interval)) AND ("table".created_dt <= ((('now'::cstring)::date)::timestamp with time zone - '6 mons'::interval)))
Rows Removed by Filter: 5046843
Remote SQL: SELECT created_dt, is_active, meta FROM fdw_schema.table
Planning time: 0.665 ms
Execution time: 27474.118 msВот именно здесь и кроется момент, на который необходимо обращать внимание при написании запросов. Фильтры не передались на удаленный сервер, а это значит, что для его выполнения постгрес вытягивает все 6 миллионов строк, чтобы уже потом локально отфильтровать (строка Filter) и произвести агрегацию. Залог успеха — это написать запрос так, чтобы фильтры передавались на удаленную машину, а мы получали и агрегировали только нужные строки.
That’s some booleanshit
С boolean полями — все просто. В исходном запросе проблема возникала из-за оператора is. Если заменить его на =, то мы получим следующий результат:
explain analyze verbose
SELECT count(1)
FROM fdw_schema.table
WHERE is_active = True
AND created_dt BETWEEN CURRENT_DATE - INTERVAL '7 month'
AND CURRENT_DATE - INTERVAL '6 month'
AND meta->>'source' = 'test';
Aggregate (cost=508010.14..508010.15 rows=1 width=8) (actual time=19064.314..19064.314 rows=1 loops=1)
Output: count(1)
-> Foreign Scan on fdw_schema."table" (cost=100.00..507988.44 rows=8679 width=0) (actual time=33.035..18951.278 rows=1360025 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Filter: ((("table".meta ->> 'source'::text) = 'test'::text) AND ("table".created_dt >= (('now'::cstring)::date - '7 mons'::interval)) AND ("table".created_dt <= ((('now'::cstring)::date)::timestamp with time zone - '6 mons'::interval)))
Rows Removed by Filter: 3567989
Remote SQL: SELECT created_dt, meta FROM fdw_schema.table WHERE (is_active)
Planning time: 0.834 ms
Execution time: 19064.534 msКак видите, фильтр улетел на удаленный сервер, а время выполнения сократилось с 27 до 19 секунд.
Стоит отметить, что оператор is отличается от оператора = тем, что умеет работать со значением Null. Это означает, что is not True в фильтре оставит значения False и Null, тогда как != True оставит только значения False. Поэтому при замене оператора is not следует передавать в фильтр два условия с оператором OR, к примеру, WHERE (col != True) OR (col is null).
С boolean разобрались, двигаемся дальше. А пока вернем фильтр по булеву значению в изначальный вид, чтобы независимо рассмотреть эффект от других изменений.
timestamptz? hz
Вообще, часто приходится экспериментировать с тем, как правильно написать запрос, в котором участвуют удаленные сервера, а уже потом искать объяснение, почему происходит именно так. Очень мало информации по этому поводу можно найти в Интернете. Так, в экспериментах мы обнаружили, что фильтр по фиксированной дате улетает на удаленный сервер на ура, а вот когда мы хотим задать дату динамически, например, now() или CURRENT_DATE, такого не происходит. В нашем примере, мы добавили такой фильтр, чтобы столбец created_at содержал в себе данные ровно за 1 месяц в прошлом (BETWEEN CURRENT_DATE — INTERVAL ‘7 month’ AND CURRENT_DATE — INTERVAL ‘6 month’). Что же мы предприняли в данном случае?
explain analyze verbose
SELECT count(1)
FROM fdw_schema.table
WHERE is_active is True
AND created_dt >= (SELECT CURRENT_DATE::timestamptz - INTERVAL '7 month')
AND created_dt <(SELECT CURRENT_DATE::timestamptz - INTERVAL '6 month')
AND meta->>'source' = 'test';
Aggregate (cost=306875.17..306875.18 rows=1 width=8) (actual time=4789.114..4789.115 rows=1 loops=1)
Output: count(1)
InitPlan 1 (returns $0)
-> Result (cost=0.00..0.02 rows=1 width=8) (actual time=0.007..0.008 rows=1 loops=1)
Output: ((('now'::cstring)::date)::timestamp with time zone - '7 mons'::interval)
InitPlan 2 (returns $1)
-> Result (cost=0.00..0.02 rows=1 width=8) (actual time=0.002..0.002 rows=1 loops=1)
Output: ((('now'::cstring)::date)::timestamp with time zone - '6 mons'::interval)
-> Foreign Scan on fdw_schema."table" (cost=100.02..306874.86 rows=105 width=0) (actual time=23.475..4681.419 rows=1360025 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Filter: (("table".is_active IS TRUE) AND (("table".meta ->> 'source'::text) = 'test'::text))
Rows Removed by Filter: 76934
Remote SQL: SELECT is_active, meta FROM fdw_schema.table WHERE ((created_dt >= $1::timestamp with time zone)) AND ((created_dt < $2::timestamp with time zone))
Planning time: 0.703 ms
Execution time: 4789.379 msМы подсказали планировщику заранее вычислить дату в подзапросе и передать уже готовую переменную в фильтр. И эта подсказка дала нам прекрасный результат, запрос стал быстрее почти в 6 раз!
Опять же, здесь важно быть внимательным: тип данных в подзапросе должен быть таким же, что и у поля, по которому фильтруем, иначе планировщик решит, что раз типы разные и необходимо сначала достать все данные и уже локально отфильтровать.
Вернем фильтр по дате в исходное значение.
Freddy vs. Jsonb
В общем-то булевы поля и даты уже достаточно ускорили наш запрос, однако оставался еще один тип данных. Битва с фильтрацией по нему, честно говоря, до сих пор не окончена, хотя и здесь есть успехи. Итак, вот как у нас получилось передать фильтр по jsonb полю на удаленный сервер.
explain analyze verbose
SELECT count(1)
FROM fdw_schema.table
WHERE is_active is True
AND created_dt BETWEEN CURRENT_DATE - INTERVAL '7 month'
AND CURRENT_DATE - INTERVAL '6 month'
AND meta @> '{"source":"test"}'::jsonb;
Aggregate (cost=245463.60..245463.61 rows=1 width=8) (actual time=6727.589..6727.590 rows=1 loops=1)
Output: count(1)
-> Foreign Scan on fdw_schema."table" (cost=1100.00..245459.90 rows=1478 width=0) (actual time=16.213..6634.794 rows=1360025 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Filter: (("table".is_active IS TRUE) AND ("table".created_dt >= (('now'::cstring)::date - '7 mons'::interval)) AND ("table".created_dt <= ((('now'::cstring)::date)::timestamp with time zone - '6 mons'::interval)))
Rows Removed by Filter: 619961
Remote SQL: SELECT created_dt, is_active FROM fdw_schema.table WHERE ((meta @> '{"source": "test"}'::jsonb))
Planning time: 0.747 ms
Execution time: 6727.815 msВместо операторов фильтрации необходимо использовать оператор наличия одного jsonb в другом. 7 секунд вместо исходных 29. Пока это единственный успешный вариант передачи фильтров по jsonb на удаленный сервер, но здесь важно учесть одно ограничение: мы используем версию базы 9.6, однако до конца апреля планируем завершить последние тесты и переехать на 12 версию. Как обновимся, напишем, как это повлияло, ведь изменений, на которые много надежд, достаточно много: json_path, новое поведение CTE, push down (существующий с 10 версии). Очень хочется скорее попробовать.
Finish him
Мы проверили, как каждое изменение влияет на скорость запроса по отдельности. Давайте теперь посмотрим, что будет, когда все три фильтра будут написаны правильно.
explain analyze verbose
SELECT count(1)
FROM fdw_schema.table
WHERE is_active = True
AND created_dt >= (SELECT CURRENT_DATE::timestamptz - INTERVAL '7 month')
AND created_dt <(SELECT CURRENT_DATE::timestamptz - INTERVAL '6 month')
AND meta @> '{"source":"test"}'::jsonb;
Aggregate (cost=322041.51..322041.52 rows=1 width=8) (actual time=2278.867..2278.867 rows=1 loops=1)
Output: count(1)
InitPlan 1 (returns $0)
-> Result (cost=0.00..0.02 rows=1 width=8) (actual time=0.010..0.010 rows=1 loops=1)
Output: ((('now'::cstring)::date)::timestamp with time zone - '7 mons'::interval)
InitPlan 2 (returns $1)
-> Result (cost=0.00..0.02 rows=1 width=8) (actual time=0.003..0.003 rows=1 loops=1)
Output: ((('now'::cstring)::date)::timestamp with time zone - '6 mons'::interval)
-> Foreign Scan on fdw_schema."table" (cost=100.02..322041.41 rows=25 width=0) (actual time=8.597..2153.809 rows=1360025 loops=1)
Output: "table".id, "table".is_active, "table".meta, "table".created_dt
Remote SQL: SELECT NULL FROM fdw_schema.table WHERE (is_active) AND ((created_dt >= $1::timestamp with time zone)) AND ((created_dt < $2::timestamp with time zone)) AND ((meta @> '{"source": "test"}'::jsonb))
Planning time: 0.820 ms
Execution time: 2279.087 msДа, запрос выглядит сложнее, это вынужденная плата, но скорость выполнения составляет 2 секунды, что более чем в 10 раз быстрее! И это мы говорим о простом запросе к относительно небольшому набору данных. На реальных запросах мы получали прирост до нескольких сотен раз.
Подведем итоги: если вы используете PostgreSQL с FDW, всегда проверяйте, все ли фильтры отправляются на удаленный сервер, и будет вам счастье… По крайней мере, пока вы не дойдете до джойнов между таблицами с разных серверов. Но это уже история для еще одной статьи.
Спасибо за внимание! Буду рад услышать вопросы, комментарии, а также истории о вашем опыте в комментариях.
Источник: habr.com
