

Что влияет на скорость работы программ на C++ и как её добиться при высоком уровне кода? Ведущий разработчик библиотеки CatBoost Евгений Петров ответил на эти вопросы на примерах и иллюстрациях из опыта работы над CatBoost для x86_64.
Видео доклада

— Всем привет. Я занимаюсь оптимизацией для CPU библиотеки машинного обучения CatBoost. Основная часть нашей библиотеки написана на C++. Сегодня расскажу, какими простыми способами мы добиваемся скорости.

Скорость вычислений складывается из двух частей. Первая часть — алгоритм. Если мы ошибаемся с выбором алгоритма, то потом уже его быстро работать не заставишь. Вторая часть — то, насколько наш алгоритм оптимизирован для вычислительной системы, которая у нас есть, с ее производительностью и пропускной способностью.

Отдельно учитывать обмен данными и вычисления приходится из-за большой разницы в их скорости. Если принять скорость памяти за скорость пешехода, то скорость вычислений — это примерно крейсерская скорость пассажирского самолета.
Чтобы эту разницу сгладить, в архитектуре есть несколько уровней кэширования. Самый быстрый и самый маленький — L1-кэш. Потом есть кэш побольше и помедленнее, второго уровня. И есть совсем большой кэш, который может быть на десятки мегабайт, кэш третьего уровня, но он самый медленный.
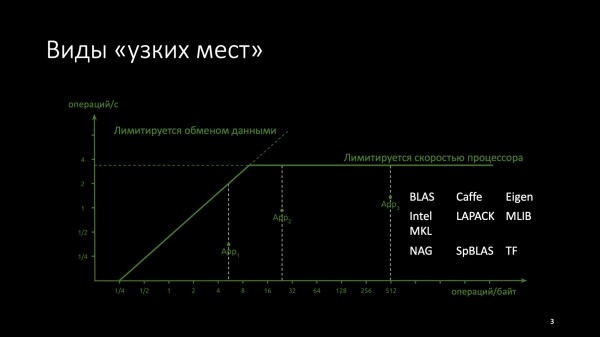
Из-за разной скорости обмена данными вычислений, вычислительный код делится на два класса. Один класс лимитируется пропускной способностью, то есть скоростью обмена данными. Второй класс лимитируется скоростью работы процессора. Граница между ними выставляется в зависимости от числа операций, которые выполняются с одним байтом данных. Это обычно константа для конкретного кода.
Большая часть тяжелого вычислительного кода давно написана, очень хорошо оптимизирована, и есть большое число библиотек, поэтому имеет смысл, если вы видите в своем коде тяжелые вычисления, поискать библиотеку, которая могла бы их за вас сделать.

Из оставшегося компиляторы умеют не всё, так как на их разработку тратится очень ограниченный процент ресурсов. Какие из них сегодня развиваются более-менее активно, то есть поддерживают стандарты, пытаются за ними следить? Это frontend EDG, который используется в различных деривативах, например, компилятор Intel; LLVM; GNU и frontend Microsoft.
Поскольку их мало, компиляторы поддерживают только частотные шаблоны управления и зависимости по данным. Если мы смотрим на управление, то это линейные участки и простые циклы, то есть последовательность инструкций и повторение. Частотные зависимости по данным они узнают от редукции, когда мы, скажем, суммируем много элементов в один, сворачиваем и выполняем поэлементные действия над одним или несколькими массивами.
Что же остается разработчикам? Это можно условно поделить на четыре части. Первая — архитектура приложения, компиляторы просто не в состоянии придумать ее за нас.

Параллелизация — тоже сложная вещь для компиляторов. Работа с памятью — потому что это реально сложно: нужно учитывать и архитектуру, и параллелизацию, и все вместе. Кроме этого, компиляторы не умеют нормально оценивать качество оптимизации, то, насколько быстрым получается код. Это тоже приходится делать нам, разработчикам, принимать решение — оптимизировать дальше или остановиться.
В части архитектуры мы посмотрим на амортизацию накладных расходов, виртуальных вызовов, на которых в большом числе случаев архитектура основывается.
Параллелизацию оставим за скобками. По поводу использования памяти: это тоже в каком-то смысле амортизация и правильная работа с данными, правильное их размещение в памяти. В части оценки эффективности поговорим про профилировку и то, как искать узкие места в коде.
Использование интерфейсов и абстрактных типов данных — один из основных методов проектирования. Рассмотрим подобный вычислительный код из машинного обучения. Это условный код, который обновляет прогноз градиентным методом.

Если заглянуть немножко внутрь и попытаться понять, что внутри происходит, то у нас есть интерфейс IDerCalcer для вычисления производных функции потерь, и функция, которая сдвигает прогноз (наше предсказание) в соответствии с градиентом функции потерь.
Справа на слайде вы видите, что это значит для двумерного случая. А в машинном обучении размер прогноза — не два и не три, а миллионы, десятки миллионов элементов. Посмотрим, насколько хорош этот код для вектора порядка 10 млн элементов.

Возьмем в качестве целевой функции среднеквадратичное отклонение и померяем, как она работает, за сколько она сдвинет этот прогноз. Производная этой целевой функции показана на слайде. Время работы на условной машине, которая дальше остается фиксированной, — 40 мс.

Попробуем понять, что же тут не так. Первое, что привлекает внимание, — виртуальные вызовы. Если смотреть в профилировщик, видно, что в зависимости от числа параметров это примерно пять-десять инструкций. И если, как в нашем случае, вычисление самой производной — это всего два арифметических действия, то это запросто может оказаться существенным накладным расходом. Для большого тела при вычислении производных это ок. Для короткого тела, которое вычисляет производную —скажем, даже не 500 инструкций, а 20, 50 или еще меньше, — это уже будет существенный процент по времени. Что же делать? Попробуем самортизировать вызов виртуальной функции, изменив интерфейс.

Первоначально мы вычисляли производные поточечно, для каждого элемента вектора отдельно. Перейдем от поэлементной обработки к обработке векторами. Возьмем стандартный шаблон C++, который позволяет работать с view на вектор. Или, если ваш компилятор не поддерживает последний стандарт, можно использовать простой самодельный класс, где хранится указатель на данные и размер. Как поменяется код? У нас останется один вызов, который вычисляет производные, и потом нам придется добавить цикл, который будет, собственно, обновлять прогноз.

Кроме того, что добавляется цикл, нам еще придется второй раз посмотреть на данные, то есть второй раз прочитать сам вектор прогнозов и вектор градиента, который мы только что вычислили.

Померяем снова на той же машине и увидим, что получилось хуже, что-то пошло не так. Давайте разбираться, что случилось с кодом.

Подозревать в чем-то цикл смысла нет, поскольку это как раз тот самый частотный паттерн, который компиляторы узнают и хорошо оптимизируют. Количество операций на один элемент данных там будет меньше, чем стоимость виртуального вызова.

А вот создание большого вектора и повторный проход по нему — в этом месте стоит подозревать проблему. Чтобы понять, почему это плохо и приводит к замедлению, нужно себе представить, что происходит в памяти, когда работает код, который мы видим на слайде справа.

Когда посчитан вектор производных, дело доходит до цикла, который сдвигает прогноз. Перед этим циклом в быстром кэше первого уровня, который работает на частоте процессора, останется только очень маленькая часть данных. На слайде это зеленый цвет на светофоре. Остальные данные будут вытеснены из кэша в память, и когда цикл пойдет обновлять прогнозы, данные придется второй раз читать из памяти. А она у нас работает, в общем, весьма небыстро, со скоростью пешехода.

Когда мы обновляем прогноз, нам не обязательно читать все производные сразу. Достаточно считать их большими пачками, чтобы самортизировать виртуальные вызовы. Поэтому есть смысл раздробить вычисление производных и обновление прогноза на небольшие блоки и перемешать эти два действия. К чему это приведет, если посмотреть на то, откуда будут читаться данные?

Это приведет к тому, что мы будем все время брать данные, и к тому, что данные будут оставаться в L1-кэше и не успеют уйти в медленную память. А дальше нам нужно понять, кто же нам скажет этот размер блока.

Это логично поручить самому вычислителю производных, потому что только он знает, сколько кэша ему требуется. Дальше нужно переписать цикл, который у нас просматривал массив. Его нужно разделить на два. Внешний цикл будет идти по блокам, а внутри мы будем два раза проходить по элементам блока.

Вот он, внешний по блокам.

А вот внутренний по элементам блока.

Мы учитываем, что последний блок может быть неполным.

Посмотрим, что из этого получается. Видим, что мы угадали, правильно поняли, в чем дело, и ценой довольно небольших изменений в коде уменьшили время работы на восемь процентов. Но мы можем сделать еще больше. Нужно еще раз критически посмотреть на то, что мы написали. Посмотреть на функцию, которая нам вычисляет производные. Она возвращает нам вектор производных, доступ к элементам которого в неблагоприятных ситуациях будет медленным.

Причин тут две. Во-первых, размещение вектора в «куче». Велики шансы, что этот вектор будет многократно создаваться и уничтожаться. Второй минус с точки зрения скорости в том, что мы каждый раз будем получать память, вероятно, по новому адресу. Эта память будет «холодная» с точки зрения кэша, то есть перед записью в нее процессор будет выполнять вспомогательное чтение, чтобы проинициализировать данные в кэше.
Чтобы это исправить, нужно вынести аллокацию из цикла. Для этого нам придется еще раз поменять интерфейс, перестать возвращать векторы и начать записывать производные в память, которую мы получаем от вызывающего кода.

Это стандартный прием — вынос всех манипуляций с ресурсами из узких мест в вычислительном коде. Добавим к методу CalcDer еще один параметр, view на вектор, куда должны попасть производные.

Код тоже изменится очевидным образом. Вектор производных будет один, снаружи от всех циклов, и к методу просто добавится новый параметр.

Смотрим. Получается, что мы выиграли еще где-то восемь процентов по сравнению с предыдущей версией, а по сравнению с базовой — уже 15%.
Понятно, что оптимизации не исчерпываются амортизацией накладных расходов, что узкие места бывают и других видов.

Для иллюстрации того, как искать узкие места, понадобится еще один простой подопытный код. Например, я взял транспонирование матрицы. У нас есть матрица approx и матрица approxByCol, куда мы должны положить транспонированные данные. И простое гнездо из двух циклов. Здесь нет никаких виртуальных вызовов, создания векторов. Это просто перекладывание данных. Цикл относительно удобен для компилятора.
Померяем, как работает этот код на достаточно большой матрице и на конкретной машине.

Для примера я взял число строк 1000, число колонок 100 000. Машина — интеловский сервер, одно ядро. Память именно такая, нам это важно, потому что вся работа с памятью и скорость будет зависеть от скорости работы памяти. Замерили и получили 1,4 с. Много это или мало? Что мы успеваем сделать за это время?

Мы успеваем прочитать 800 мегабайт, это не транспонированная матрица, а исходная. А также прочитать и записать 1,6 ГБ, это уже транспонированная матрица. Процессор выполняет вспомогательное чтение перед записью, чтобы проинициализировать данные в кэше.

Посчитаем, сколько пропускной способности мы использовали с пользой. Получается, пропускная способность нашего кода составила 1,7 ГБ/с.
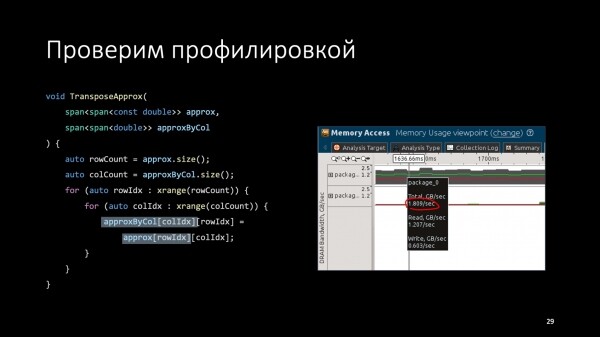
Это был теоретический расчет. Дальше можно взять профилировщик, который умеет мерить скорость работы с памятью. Я взял VTune. Посмотрим, что он покажет. Показывает похожую цифру — 1,8 ГБ. В принципе хорошо согласуется, потому что в нашем расчете мы не учитывали, что приходится читать адреса строк и адреса колонок. Плюс к этому VTune регистрирует фоновую деятельность в операционной системе. Поэтому наша модель согласуется с реальностью.
Чтобы понять, 1,7 ГБ — это много или мало, нужно выяснить, какая максимальная пропускная способность нам доступна.
Для этого нужно почитать спеки по процессору. Есть специальный сайт ark.intel.com, где про любой процессор можно все узнать. Если мы смотрим конкретно на наш сервер, то видим, что у него восемь ядер и для самой быстрой памяти DDR3, которую он поддерживает, обеспечивается передача со скоростью примерно 60 ГБ/с в одну сторону.

Но тут надо учесть, что мы используем только одно ядро и память у нас помедленнее, то есть нужно масштабировать эти 60 ГБ на наши условия пропорционально числу ядер и частоте памяти.
Получается, что наш код мог бы использовать 5,3 ГБ в одну сторону. А поскольку параллельно можно читать и записывать, то в идеале, если бы мы просто копировали данные с места на место, достигли бы 10,6. Поскольку у нас два чтения и одна запись, то должно быть примерно 8 ГБ/с. Мы помним, что у нас получилось 1,7. То есть мы использовали где-то 20%.
Почему так получается? Снова нужно разбираться с архитектурой. Дело в том, что данные между памятью и кэшем передаются не произвольными пакетами, а по 64 байта ровно, ни больше ни меньше. Это первое соображение.

Второе соображение: мы записываем транспонированные данные не последовательно, а произвольно, поскольку строки матрицы расположены в памяти непредсказуемым образом.
Получается, что перед тем, как записать одно вещественное число, нам приходится вычитывать 64 байта данных. Если обозначить размер матрицы N, то вместо оптимального времени работы (N/5,3 + N/10,6) у нас получается (8*N/5,3 + N/10,6). Где-то в четыре-пять раз больше, что и объясняет эту эффективность в 20%.

Что с этим делать? Нужно перестать записывать данные по одному столбцу и начать записывать столько колонок, сколько укладывается в одну кэш-линию (64 байта). Для этого разобьем цикл по столбцам на цикл по кэш-линиям и вложенный цикл по элементам кэш-линии.

Вот они, итерации по кэш-линиям.

И вот они, итерации внутри кэш-линии. Тут мы для простоты считаем, что данные выровнены на границу кэш-линии. Теперь проверим с помощью VTune, что получится.
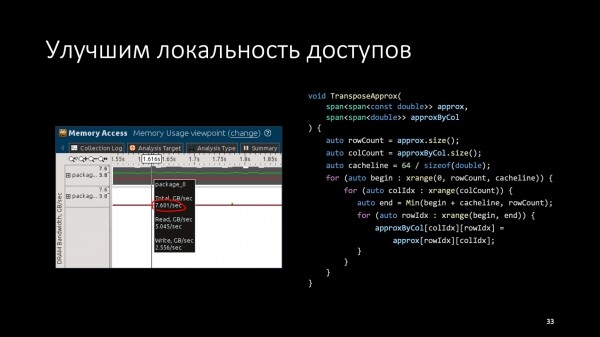
Видим, что получилось близко к расчетным восьми гигабайтам в секунду — 7,6. Но еще не факт, что все эти 7,6 — полезная работа. Может быть, сколько-то из них — накладные расходы.
Чтобы понять, сколько пользы мы получили, измерим время работы после оптимизации. Получается 0,5 с на той же самой машине. Пропускная способность, которая приходится на само транспонирование, стала 4,8 ГБ/с. Видно, что еще остался запас, который мы не выбрали, но все равно, мы из 20-процентной эффективности получили 60-процентную.
С помощью профилировщика можно разобраться, почему мы не получили 80% или 95%.

Дело в том, что мы храним матрицы в виде вектора векторов, то есть используем доступ в память с двойной косвенностью.
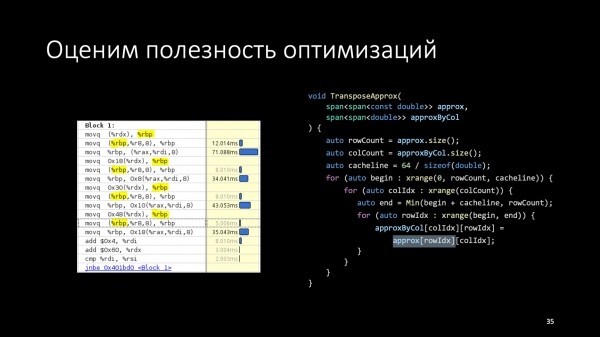
С помощью VTune можно увидеть, какие инструкции сгенерированы для доступа к элементам массива. Желтым цветом слева выделены инструкции, которые вычитывают адреса колонок транспонированной матрицы. И это, во-первых, дополнительные инструкции, а во-вторых, дополнительные передачи данных. Но дальше оптимизировать уже не будем, остановимся и подведем итоги.

О чем я сегодня вам рассказал? Полезный совет для работы с вычислительным кодом — обрабатывать блоками, амортизировать накладные расходы, которые связаны, например, с виртуальными вызовами. Плюс за счет блочности улучшается локальность данных, и мы получаем более высокую скорость доступа.
Вынос аллокаций из узких мест — это тоже их амортизация. И тоже повышение скорости доступа за счет фиксации временных буферов в памяти.
По поводу профилировки. Во-первых, профилировка — полезный метод для поиска узких мест «в общем случае». Во-вторых, это позволяет оценить эффективность кода, принять решение, удовлетворены мы скоростью или хотим оптимизировать дальше, и показывает, в каком направлении двигаться.
На этом у меня все. Если вы пользуетесь CatBoost или первый раз про него услышали и хотите узнать, что это такое, — читайте , приходите к нам на , пишите в . Большое спасибо за внимание.
Источник: habr.com
