


Или можно? Конечно, миграция SAP-систем — это сложный и кропотливый процесс, для успеха которого важна слаженная работа всех участников. А если миграция проводится в сжатые сроки — задача многократно усложняется. Не все решаются на это. Причин может быть несколько. Например, процесс сам по себе длителен и организационно сложен. Плюс есть риск незапланированных простоев систем. Или клиенты не уверены, что, пережив такую операцию, получат бенефиты, соразмерные потраченным усилиям. Однако бывают и исключения.
Под катом расскажем о трудностях, с которыми сталкиваются заказчики в процессе миграции и сопровождения SAP-систем, обсудим, почему стереотипы не всегда соответствуют реальности, и поделимся кейсом, как нам удалось мигрировать системы заказчика в новую инфраструктуру всего за три с небольшим месяца.
Хостинг SAP-систем
Еще каких-то пять лет назад сложно было представить, что клиенты массово начнут использовать хостинговые ресурсы для SAP-приложений. В большинстве случаев их внедряли on-premise. Однако с развитием моделей аутсорсинга и рынка облачных услуг мировоззрение заказчиков начало меняться. Каковы аргументы, влияющие на выбор в пользу облака для SAP?
- Для новичков, которые только запланировали внедрение SAP, облачная инфраструктура это практически стандартный выбор – масштабируемость ресурсов под текущую потребность системы и нежелание отвлекать ресурсы на развитие непрофильных компетенций.
- В компаниях с большим системным ландшафтом с помощью хостинга SAP-систем CIO выходят на качественно иной уровень управления рисками, т.к. за SLA отвечает партнер.
- Третий из наиболее часто встречаемых аргументов – высокая стоимость построения инфраструктуры для реализации сценариев высокой доступности и DR.
- Фактор 2027 – анонсированное вендором прекращение поддержки устаревших систем в 2027 году. Это означает перевод БД на HANA, что влечет за собой расходы на модернизацию и закупку новых вычислительных мощностей.
Рынок SAP-хостинга в России сейчас можно считать достаточно зрелым. И это предоставляет широкие возможности для клиентов, которые хотят сменить свои хостинг-платформы. Однако такие проекты справедливо могут вызывать опасения у бизнеса из-за сложности процедуры миграции. Это вынуждает заказчиков предъявлять повышенные требования к поставщикам услуг, которые должны обладать не только исключительными компетенциями по хостингу и сопровождению систем SAP, но и успешным опытом в области миграции.
В чем заключаются сложности смены SAP-хостинга?
Хостинги бывают разные. Несоответствие заявленному уровню сервиса, множество «но» и звездочек с оговорками мелким текстом, ограниченность ресурсов и возможностей хостинг-провайдера, отсутствие гибкости в вопросах коммуникации с клиентом, бюрократия, технические ограничения, низкая компетентность специалистов технической поддержки, а также многие другие нюансы — это лишь малая часть подводных камней, с которыми могут столкнуться клиенты в процессе эксплуатации их бизнес-систем в аутсорсинговых инфраструктурах. Зачастую для клиента все это остается в тени, в дебрях многостраничного контракта, и всплывает уже в процессе пользования услугами.
В какой-то момент для заказчика становится очевидным, что уровень сервиса, который он получает, далек от его ожиданий. Это является неким катализатором к поиску решений по исправлению ситуации и в случае неуспеха, когда проблемы накапливаются до предела и становится совсем больно, переходят к активным действиям по проработке альтернативных вариантов в направлении смены поставщика услуги.
Почему тянут до последнего? Причина проста — процесс переноса систем для клиентов не всегда прозрачен и понятен. Клиенту сложно оценить действительные риски, связанные с процессом миграции. Можно сказать, что миграция для клиентов — это своеобразный черный ящик: непонятно, цена, время простоя систем, риски и как их нивелировать, да и вообще темно и страшно. Тут ведь как, если не получится, то головы полетят и у топов, и у исполнителей.
SAP — это системы корпоративного уровня, сложные и мягко говоря не дешевые. На их внедрение, доработку, сопровождение тратятся приличные бюджеты и от их доступности и корректной работы зависит жизнедеятельность предприятия. А теперь представьте последствия остановки какого-нибудь крупного производства. Это финансовые потери, которые могут исчисляться цифрами с большим количеством нулей, а также репутационные и другие, не менее значимые риски.
Разберем сложности, которые могут возникнуть на каждом из этапов на кейсе миграции SAP-систем одного из наших заказчиков.
Подготовка и проектирование
Миграция — это формула со множеством различных составляющих. И одним из самых важных является этап проектирования и подготовки целевой (новой) инфраструктуры.
Нам необходимо было погрузиться в существующую реализацию систем, их архитектуру. В целевой инфраструктуре мы где-то повторили существующие решения, в каких-то моментах дополнили и улучшили, где-то переделали, продумали и выбрали решения по обеспечению отказоустойчивости и доступности, а также максимально консолидировали все ресурсы.
В процессе проектирования было выполнено много разных упражнений, которые в итоге позволили максимально подготовиться к миграции и учесть всевозможные нюансы и подводные камни (о них позднее).
Что у нас в результате получилось — индивидуально спроектированная инфраструктура частного облака на базе нашего ЦОД:
- выделенные физические серверы для SAP HANA;
- платформа виртуализации VMware для серверов приложений и инфраструктурных сервисов;
- дублированные каналы связи между ЦОД для L2 VPN;
- две основных СХД для разделения продуктива и «всего остального»;
- СРК на базе Veritas Netbackup с отдельным сервером, дисковой полкой и ленточной библиотекой.
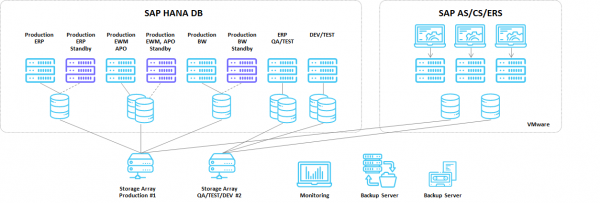
А вот как реализовали все это с технической точки зрения.
SAP
- Для эффективного использования хранилищ под продуктивные HANA использовали общие диски без системной репликации БД средствами SAP. Все это завернули в Active-Standby кластер SUSE HAE на базе Pacemaker. Да, время восстановления немного дольше, чем с репликацией, зато получаем экономию пространства СХД в два раза и как следствие экономию бюджета заказчика.
- В препродуктивных средах от кластеров HANA отказались, но технически повторили конфигурацию продуктива.
- Тестовые среды и среды разработки разнесли еще на несколько серверов без кластеров в конфигурации MCOS.
- Все серверы приложений виртуализировали и разместили в VMware.
Сети
- Физически разделили контуры сетей управления и продуктивных сетей стеками коммутаторов, завернув продуктивные в сторону ЦОД заказчика.
- Заложили достаточное количество сетевых интерфейсов, чтобы не смешивать большие потоки трафика.
- Для передачи данных с СХД сделали классические FC SAN фабрики.
СХД
- Продуктивную и препродуктивную нагрузку SAP оставили на all-flash массиве.
- Тестовые среды разработчиков и инфраструктурные сервисы поместили на отдельный гибридный массив.
СРК
- Сделали на базе Veritas Netbackup.
- Немного дописали встроенные скрипты, чтобы бекапить MCOS-конфигурации.
- Оперативные копии положили на дисковую полку, чтобы быстро восстановиться, а для долгосрочного хранения используем ленты.
Мониторинг
- Все железо, ОС и SAP завели под Zabbix.
- Собрали множество полезных дашбордов в Grafana.
- При возникновении алерта Zabbix умеет заводить заявку в системе управления инцидентами, у нас она реализована на Jira. Также информация дублируется в Telegram-канал.
Telegram
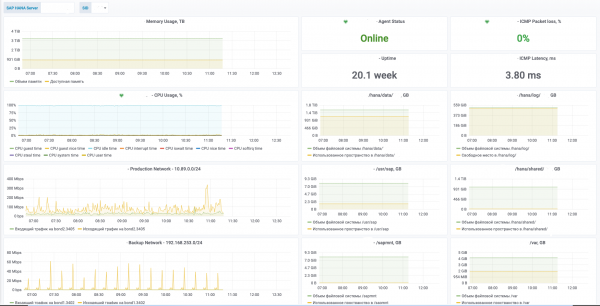
Общее состояние HANA
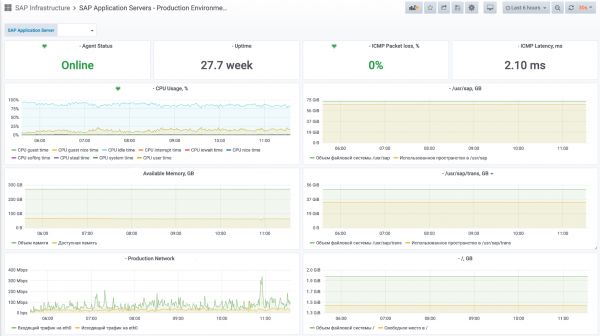
Состояние сервера приложений SAP:
Инфраструктурные сервисы
- Для обслуживания внутренних пространств имен подняли кластер DNS-серверов, который синхронизируется с серверами заказчика.
- Сделали отдельный файловый сервер для обмена данными.
- Чтобы хранить различные конфигурации, добавили Gitlab.
- Для различной Sensitive-информации взяли HashiCorp Vault.
Процесс миграции
В общем случае процесс миграции состоит из следующих этапов:
- подготовка всей необходимой проектной документации;
- переговоры с текущим провайдером — решение организационных вопросов;
- закупка, доставка и установка нового оборудования под проект;
- тестовая миграция и отладка процесса;
- перенос систем, боевая миграция.
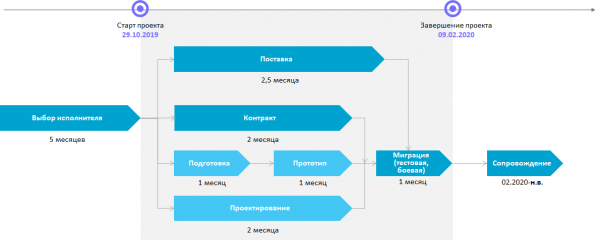
В конце октября 2019 года мы подписали контракт, далее спроектировали архитектуру, а после ее согласования с заказчиком заказали необходимое оборудование.
На что нужно обратить внимание в первую очередь — сроки поставки оборудования. В среднем поставка сертифицированного железа под SAP NAHA, соответствующего требованиям производителя ПО к аппаратным платформам, занимает 10-12 недель. А с учетом сезонности (реализация проекта выпадала аккурат на новый год) — этот срок мог увеличиться еще на месяц. Соответственно, требовалось максимально ускорить процесс: работали с дистрибьютором-поставщиком, договаривались об ускоренной доставке самолетами (вместо сухопутных и морских путей).
Ноябрь и декабрь ушли на то, чтобы выполнить подготовку к миграции и получить часть оборудования. Подготовку мы провели на тестовом стенде в нашем публичном облаке, где отработали все основные шаги и отловили возможные сложности и проблемы:
- подготовили детальный план взаимодействия участников проектных команд с поминутными таймингами;
- построили тестовый стенд для БД и серверов приложений примерно так же, как в целевой инфраструктуре;
- настроили необходимые каналы связи и инфраструктурные сервисы, чтобы проверить работу интеграций;
- отработали cutover-сценарии;
- облако также помогло нам сформировать преднастроенные шаблоны виртуальных машин, которые впоследствии мы просто импортировали и развернули в целевом ландшафте.
Незадолго до новогодних праздников к нам приехала первая партия оборудования. Это позволило развернуть часть систем на реальном железе. Так как приехало далеко не все, мы подключили подменное оборудование, о поставке которого нам удалось договориться с вендором и дистрибьюторами. Остатки целевой инфраструктуры мы получили уже на финальном этапе.
Чтобы успеть в срок, нашим инженерам пришлось пожертвовать новогодними каникулами и начать работу по подготовке целевой инфраструктуры 2 января, в самый разгар праздников. Да, такое иногда случается, когда горит и других вариантов просто нет. На кону была работоспособность систем, от которых зависит жизнедеятельность предприятия.
Общий порядок миграции выглядел так: в первую очередь — наименее критичные системы (ландшафт разработки, ландшафт тестирования), затем — продуктивные системы. Финальный этап миграции проходил в конце января-начале февраля.
Процесс миграции был расписан с точностью до минуты. Это cutover-план со списком всех задач, временем выполнения и ответственными лицами. Все шаги уже были отработаны на тестовой миграции, поэтому в боевой миграции необходимо было просто следовать плану и координировать процесс.
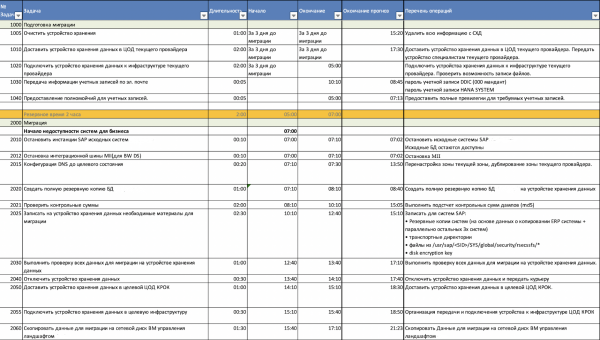
Миграция проводилась посистемно в несколько этапов. В каждом этапе по две системы.
Итогом трехмесячного спринта стала система, полностью функционирующая в ЦОД КРОК. В целом, положительный результат получен благодаря совместной работе, вклад и самоотдача всех участников процесса была максимальной.
Роль заказчика в проекте
Коммуницировать с провайдером, которого покидал наш клиент, было непросто. Оно и понятно, они были последние в списке лиц заинтересованных в успешном завершении проекта. Заказчик взял на себя задачи по эскалации и педалированию всех коммуникационных вопросов и справился с этим на 100500%. За это ему отдельное спасибо. Без такого посильного участия в процессе результат проекта мог бы быть совсем иным.
В силу формализованности процессов на стороне «бывшего» провайдера сопровождением инфраструктуры занимались специалисты, в прямом смысле далекие от проблем, на тот момент еще их заказчика. Например, процесс экспорта одной и той же БД мог занимать от часа до пяти. Тогда казалось, что это какая-то магия, секрет который так нам и не открылся. Наверное инженеры техподдержки между делом предавались медитации, забывая о том, что где-то там в далекой России дедлайны, инженеры без новогодних салатов, плачет и страдает заказчик…
Итоги проекта
Финальным аккордом миграции была передача систем на сопровождение.
Сейчас мы предоставляем сервис единого окна для обращений заказчика и закрываем весь объем задач по сопровождению компонент инфраструктуры и SAP basis вместе с партнером — itelligence. Клиент живет в частном облаке уже полгода. Вот статистика по сервисным случаям за это время:
- 90 инцидентов (20% решены без привлечения заказчика)
- Решены в рамках SLA – 100%
- Внеплановых остановок систем – 0
Если у вас есть задачи, аналогичные тому, что были у нашего клиента, и вы хотите узнать подробнее, как их решить, пишите: ahaidukov@croc.ru
Источник: habr.com
