

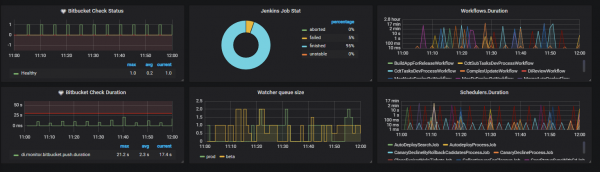
На РИТ 2019 наш коллега Александр Коротков сделал про автоматизацию разработки в ЦИАН: чтобы упростить жизнь и работу, мы используем собственную платформу Integro. Она отслеживает жизненный цикл задач, снимает с разработчиков рутинные операции и заметно сокращает количество багов в production. В этом посте мы дополним доклад Александра и расскажем, как прошли путь от простых скриптов к объединению open source продуктов через собственную платформу и чем у нас занимается отдельная команда автоматизации.
Нулевой уровень
«Нулевого уровня не бывает, я такого не знаю»
Мастер Shifu из м/ф «Кунг-фу Панда»
Автоматизация в ЦИАН началась через 14 лет после основания компании. Тогда в команде разработки было 35 человек. С трудом верится, да? Конечно, в каком-то виде автоматизация все-таки существовала, но отдельное направление по непрерывной интеграции и доставке кода начало формироваться именно в 2015 году.
На тот момент у нас был огромный монолит из Python, C# и PHP, развернутый на Linux/Windows серверах. Для деплоя этого монстра у нас был набор скриптов, который мы запускали вручную. Была еще сборка монолита, приносящая боль и страдания из-за конфликтов при слиянии веток, правках дефектов и пересборке «с другим набором задач в билде». Упрощенно процесс выглядел так:
Нас это не устраивало, и мы хотели построить повторяемый, автоматизированный и управляемый процесс сборки и деплоя. Для этого нам была нужна CI/CD система, и мы выбирали между бесплатной версией Teamcity и бесплатной Jenkins, так как мы с ними работали и обе устраивали нас по набору функций. Выбрали Teamcity как более свежий продукт. Тогда мы еще не использовали микросервисную архитектуру и не рассчитывали на большое количество задач и проектов.
Приходим к идее о собственной системе
Внедрение Teamcity убрало только часть ручной работы: осталось еще создание Pull Request-ов, продвижение задач по статусам в Jira, выбор задач для релиза. С этим система Teamcity уже не справлялась. Нужно было выбирать путь дальнейшей автоматизации. Мы рассматривали варианты работы со скриптами в Teamcity или переход на сторонние системы автоматизации. Но в итоге решили, что нужна максимальная гибкость, которую дает только собственное решение. Так появилась первая версия внутренней системы автоматизации под названием Integro.
Teamcity занимается автоматизацией на уровне запуска процессов сборки и деплоя, а Integro сфокусировалась на верхнеуровневой автоматизации процессов разработки. Нужно было объединить работу с задачами в Jira с обработкой связанного исходного кода в Bitbucket. На этом этапе внутри Integro стали появляться свои workflow для работы с задачами разных типов.
Из-за увеличения автоматизации в бизнес-процессах выросло число проектов и run-ов в Teamcity. Так пришла новая проблема: одного бесплатного инстанса Teamcity стало не хватать (3 агента и 100 проектов), мы добавили еще один инстанс (еще 3 агента и 100 проектов), потом еще. В итоге мы получили систему из нескольких кластеров, которой было сложно управлять:
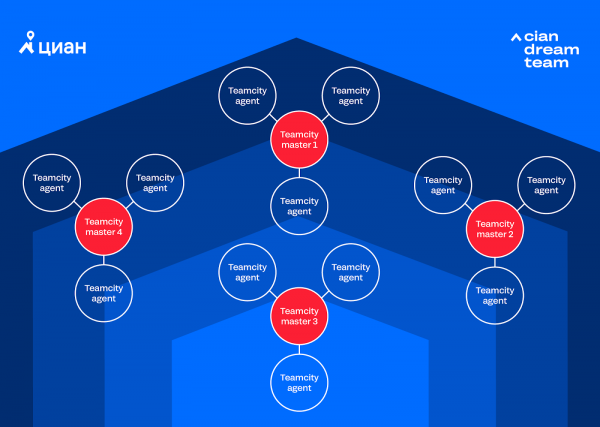
Когда встал вопрос о 4 инстансе, мы поняли, что дальше так жить нельзя, т. к. совокупные издержки на поддержку 4 инстансов уже не лезли ни в какие рамки. Возник вопрос покупки платной Teamcity или выбора в пользу бесплатной Jenkins. Мы провели расчеты по инстансам и планам по автоматизации и решили, что будем жить на Jenkins. Спустя пару недель мы перешли на Jenkins и избавились от части головной боли, связанной с поддержкой нескольких инстансов Teamcity. Поэтому мы смогли сосредоточиться на разработке Integro и допиливании Jenkins под себя.
С ростом базовой автоматизации (в виде автоматического создания Pull Request-ов, сбора и публикации Code coverage и иных проверок) появилось стойкое желание максимально отказаться от ручных релизов и отдать эту работу роботам. Помимо этого внутри компании начался переезд на микросервисы, которые требовали частых релизов, причем отдельно друг от друга. Так мы постепенно пришли к автоматическим релизам наших микросервисов (монолит пока что выпускаем вручную из-за сложности процесса). Но, как это обычно бывает, возникла новая сложность.
Автоматизируем тестирование
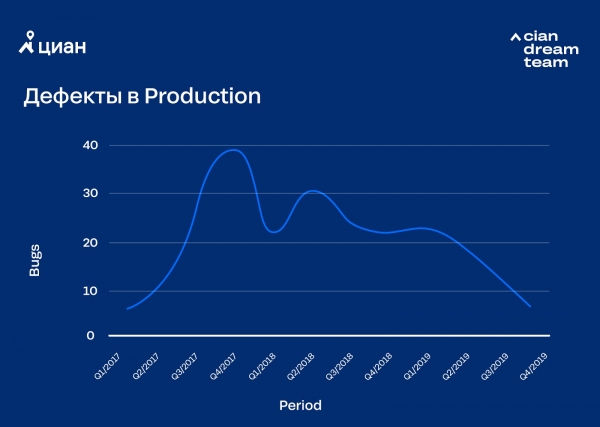
Из-за автоматизации релизов ускорились процессы разработки, причем частично за счет пропуска некоторых этапов тестирования. А это привело к временной потере качества. Звучит банально, но вместе с ускорением релизов нужно было менять и методологию разработки продукта. Нужно было задуматься об автоматизации тестирования, привитии персональной ответственности (тут речь про «принятие идеи в голове», а не денежные штрафы) разработчика за выпускаемый код и баги в нем, а также о решении по выпуску/не выпуску задачи через автоматический деплой.
Устраняя проблемы с качеством, мы пришли к двум важным решениям: стали проводить канареечное тестирование и внедрили автоматический мониторинг фона ошибок с автоматическим реагированием на его превышение. Первое решение позволило находить очевидные ошибки до полноценного попадания кода в production, второе уменьшило время реагирования на проблемы в production. Ошибки, конечно, бывают, но мы тратим бо́льшую часть времени и сил не на исправление, а на минимизацию.
Команда автоматизации
Сейчас у нас штат из 130 разработчиков, и мы продолжаем . Команда по непрерывной интеграции и доставке кода (далее — команда Deploy and Integration или DI) состоит из 7 человек и работает в 2 направлениях: разработка платформы автоматизации Integro и DevOps.
DevOps отвечает за Dev/Beta окружения сайта CIAN, окружения Integro, помогает разработчикам в решении проблем и вырабатывает новые подходы к масштабированию окружений. Направление разработки Integro занимается как самой Integro, так и смежными сервисами, например, плагинами для Jenkins, Jira, Confluence, а также разрабатывает вспомогательные утилиты и приложения для команд разработчиков.
Команда DI работает совместно с командой Платформы, которая занимается разработкой архитектуры, библиотек и подходов к разработке внутри компании. Вместе с этим, любой разработчик внутри ЦИАН может внести вклад в автоматизацию, например, сделать микроавтоматизацию под нужды команды или поделиться классной идеей, как сделать автоматизацию еще лучше.
Слоеный пирог автоматизации в ЦИАН
Все системы, задействованные в автоматизации, можно разделить на несколько слоев:
- Внешние системы (Jira, Bitbucket и др.). С ними работают команды разработки.
- Платформа Integro. Чаще всего разработчики не работают с ней напрямую, но именно она поддерживает работу всей автоматизации.
- Сервисы доставки, оркестрирования и обнаружения (к примеру, Jeknins, Consul, Nomad). С их помощью мы разворачиваем код на серверах и обеспечиваем работу сервисов друг с другом.
- Физический уровень (сервера, ОС, смежное ПО). На этом уровне работает наш код. Это может быть как физический сервер, так и виртуальный (LXC, KVM, Docker).
Исходя из этой концепции мы делим зоны ответственности внутри команды DI. Два первых уровня лежат в зоне ответственности направления разработки Integro, а два последних уровня уже в зоне ответственности DevOps. Такое разделение позволяет сфокусироваться на задачах и не мешает взаимодействию, т. к. мы находимся рядом друг с другом и постоянно обмениваемся знаниями и опытом.
Integro
Сосредоточимся на Integro и начнем с технологического стека:
- CentOs 7
- Docker + Nomad + Consul + Vault
- Java 11 (старый монолит Integro останется на Java 8)
- Spring Boot 2.X + Spring Cloud Config
- PostgreSql 11
- RabbitMQ
- Apache Ignite
- Camunda (embedded)
- Grafana + Graphite + Prometheus + Jaeger + ELK
- Web UI: React (CSR) + MobX
- SSO: Keycloak
Мы придерживаемся принципа микросервисной разработки, хотя у нас и присутствует legacy в виде монолита ранней версии Integro. Каждый микросервис крутится в своем docker-контейнере, сервисы общаются между собой посредством HTTP-запросов и RabbitMQ-сообщений. Микросервисы находят друг друга через Consul и выполняют к нему запрос, проходя авторизацию через SSO (Keycloak, OAuth 2/OpenID Connect).
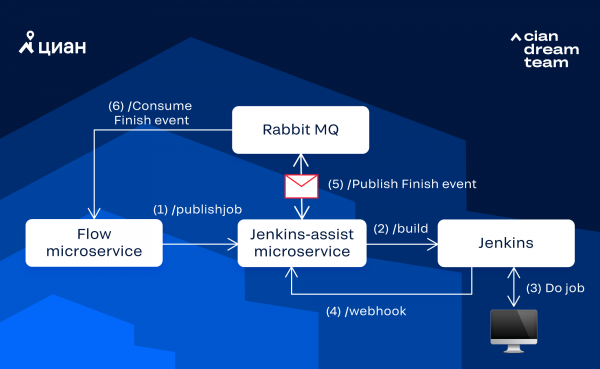
В качестве реального примера рассмотрим взаимодействие с Jenkins, которое состоит из следующих шагов:
- Микросервис управления workflow (далее Flow-микросервис) хочет запустить сборку в Jenkins. Для этого он через Consul находит IP:PORT микросервиса интеграции с Jenkins (далее Jenkins-микросервис) и отправляет в него асинхронный запрос на запуск сборки в Jenkins.
- Jenkins-микросервис после получения запроса формирует и отдает в ответ Job ID, по которому потом можно будет идентифицировать результат работы. Вместе с этим он запускает сборку в Jenkins через вызов REST API.
- Jenkins выполняет сборку и после ее окончания отправляет webhook с результатами выполнения в Jenkins-микросервис.
- Jenkins-микросервис, получив webhook, формирует сообщение об окончании обработки запроса и прикрепляет к нему результаты выполнения. Сформированное сообщение отправляется в очередь RabbitMQ.
- Через RabbitMQ опубликованное сообщение попадает к Flow-микросервису, который узнает о результате обработки своей задачи, сопоставив Job ID из запроса и полученного сообщения.
Сейчас у нас порядка 30 микросервисов, которые можно разбить на несколько групп:
- Управление конфигурациями.
- Информирование и взаимодействие с пользователями (мессенджеры, почта).
- Работа с исходным кодом.
- Интеграция с инструментами деплоя (jenkins, nomad, consul и т. д.).
- Мониторинг (релизов, ошибок и т. д.).
- Web-утилиты (UI для управления тестовыми средами, сбора статистики и т. д.).
- Интеграция с таск-трекерами и подобными системами.
- Управление workflow для разных задач.
Workflow задачи
Integro автоматизирует действия, связанные с жизненным циклом задачи. Упрощенно под жизненным циклом задачи будем понимать workflow задачи в Jira. В наших процессах разработки есть несколько вариаций workflow в зависимости от проекта, типа задачи и опций, выбранных в конкретной задаче.
Рассмотрим workflow, который используем чаще всего:
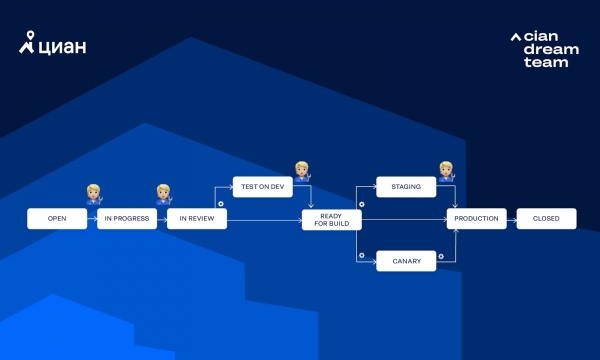
На схеме шестеренка указывает, что transition вызывается Integro автоматически, в то время как фигурка человека означает, что transition вызывается вручную человеком. Рассмотрим несколько путей, по которым задача может пройти в этом workflow.
Полностью ручное тестирование на DEV+BETA без канареечных тестов (обычно так выпускаем монолит):
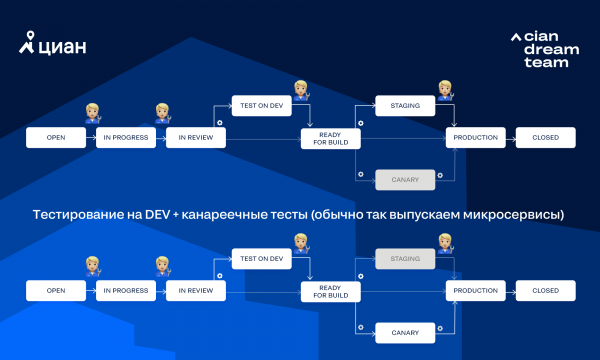
Могут быть и другие комбинации transition. Иногда путь, по которому пойдет задача, можно выбрать через опции в Jira.
Движение задачи
Рассмотрим основные шаги, которые выполняются при движении задачи по workflow «Тестирование на DEV + канареечные тесты»:
1. Разработчик или PM создает задачу.
2. Разработчик берет задачу в работу. После завершения переводит ее в статус IN REVIEW.
3. Jira отправляет Webhook в сторону Jira-микросервиса (отвечает за интеграцию с Jira).
4. Jira-микросервис отправляет запрос в Flow-сервис (отвечает за внутренние workflow, в которых выполняется работа) для запуска workflow.
5. Внутри Flow-сервиса:
- Назначаются ревьюеры для задачи (Users-микросервис, который знает все о пользователях + Jira-микросервис).
- Через Source-микросервис (знает о репозиториях и ветках, но не работает с самим кодом) осуществляется поиск репозиториев, в которых есть ветка нашей задачи (для упрощения поиска имя ветки совпадает с номером задачи в Jira). Чаще всего задача имеет лишь одну ветку в одном репозитории, это упрощает управление очередью на деплой и уменьшает связность между репозиториями.
- Для каждой найденной ветки выполняется такая последовательность действий:
i) Подлив master-ветки (Git-микросервис для работы с кодом).
ii) Ветка блокируется от изменений разработчиком (Bitbucket-микросервис).
iii) Создается Pull Request на эту ветку (Bitbucket-микросервис).
iv) Отправляется сообщение о новом Pull Request в чаты разработчиков (Notify-микросервис для работы с оповещениями).
v) Запускаются сборка, тестирование и деплой задачи на DEV (Jenkins-микросервис для работы с Jenkins).
vi) Если все предыдущие пункты завершились успешно, то Integro ставит свой Approve в Pull Request (Bitbucket-микросервис). - Integro ожидает Approve в Pull Request от назначенных ревьюеров.
- Как только получены все необходимые Approve (в т. ч. положительно пройдены автоматизированные тесты), Integro переводит задачу в статус Test on Dev (Jira-микросервис).
6. Тестировщики проводят тестирование задачи. Если проблем нет, то переводят задачу в статус Ready For Build.
7. Integro «видит», что задача готова к релизу, и запускает ее деплой в канареечном режиме (Jenkins-микросервис). Готовность к релизу определяется набором правил. Например, задача в нужном статусе, нет блокировок на другие задачи, сейчас нет активных выкладок этого микросервиса и т. п.
8. Задача переводится в статус Canary (Jira-микросервис).
9. Jenkins запускает через Nomad деплой задачи в канареечном режиме (обычно 1-3 инстанса) и уведомляет о выкладке сервис мониторинга релизов (DeployWatch-микросервис).
10. DeployWatch-микросервис собирает фон ошибок и реагирует на него, если нужно. При превышении фона ошибок (норма фона рассчитывается автоматически) производится уведомление разработчиков через Notify-микросервис. Если через 5 минут разработчик не отреагировал (нажал Revert или Stay), то запускается автоматический откат канареечных инстансов. Если фон не превышен, то разработчик должен вручную запустить деплой задачи на Production (нажатием кнопки в UI). Если в течение 60 минут разработчик не запустил деплой в Production, то канареечные инстансы также в целях безопасности будут откачены.
11. После запуска деплоя на Production:
- Задача переводится в статус Production (Jira-микросервис).
- Jenkins-микросервис запускает процесс деплоя и уведомляет о выкладке DeployWatch-микросервис.
- DeployWatch-микросервис проверяет, что на Production обновились все контейнеры (были случаи, когда обновлялось не все).
- Через Notify-микросервис отправляется оповещение о результатах деплоя в Production.
12. У разработчиков будет 30 минут на запуск отката задачи с Production в случае обнаружения некорректного поведения микросервиса. По истечении этого времени задача будет автоматически влита в master (Git-микросервис).
13. После успешного merge-а в master статус задачи будет изменен на Closed (Jira-микросервис).
Схема не претендует на полную детализацию (в реальности шагов еще больше), но позволяет оценить степень интеграции в процессы. Мы не считаем эту схему идеальной и улучшаем процессы автоматического сопровождения релизов и деплоя.
Что дальше
У нас большие планы по развитию автоматизации, например, отказ от ручных операций при релизах монолита, улучшение мониторинга при автоматическом деплое, улучшение взаимодействия с разработчиками.
Но на этом месте пока остановимся. Много тем в обзоре автоматизации мы охватили поверхностно, некоторые не затронули вообще, поэтому мы с радостью ответим на вопросы. Ждем предложений, что осветить детально, пишите в комментариях.
Источник: habr.com
