

В этой статье я расскажу о том, как проект, в котором я работаю, превращался из большого монолита в набор микросервисов.
Проект начал свою историю довольно давно, в начале 2000. Первые версии были написаны на Visual Basic 6. С течением времени стало понятно, что разработку на этом языке в будущем будет сложно поддерживать, так как IDE и сам язык развиваются слабо. В конце 2000-х было решено переходить на более перспективный C#. Новая версия писалась параллельно с доработкой старой, постепенно все больше кода было на .NET. Backend на C# изначально ориентировался на сервисную архитектуру, однако при разработке использовались общие библиотеки с логикой, да и запускались сервисы в едином процессе. Получилось приложение, которое мы называли «сервисный монолит».
Одним из немногих преимуществ такой связки являлась возможность сервисов вызывать друг друга через внешний API. Имелись явные предпосылки к переходу на более правильную сервисную, а в перспективе и микросервисную архитектуру.
Свою работу по декомпозиции мы начали примерно в 2015 году. Пока еще мы не достигли идеального состояния — остались части большого проекта, которые уже трудно назвать монолитами, но и на микросервисы они не похожи. Тем не менее, прогресс существенный.
О нем я и расскажу в статье.
Содержание
Архитектура и проблемы существующего решения
Изначально архитектура выглядела следующим образом: UI — отдельное приложение, монолитная часть написана на Visual Basic 6, приложение на .NET представляло собой набор связанных сервисов, работающий с достаточно большой базой данных.
Недостатки прежнего решения
Единая точка отказа
У нас была единая точка отказа: приложение на .NET запускалось в одном процессе. Если в каком-нибудь из модулей происходил сбой, отказывало все приложение, и его приходилось перезапускать. Так как у нас автоматизируется большое количество процессов для разных пользователей, из-за сбоя в одном из них некоторое время работать не могли все. А при программной ошибке не помогало и резервирование.
Очередь доработок
Этот недостаток скорее организационный. В нашем приложении множество заказчиков, и все они хотят доработать его как можно скорее. Раньше сделать это параллельно было невозможно, и все заказчики вставали в очередь. Этот процесс вызывал негатив у бизнеса, ведь им нужно было доказать, что их задача несет ценность. А команда разработки тратила время на то, чтобы эту очередь организовать. Это отнимало много времени и сил, а продукт в итоге не мог меняться так быстро, как этого бы от него хотели.
Неоптимальное использование ресурсов
При размещении сервисов в едином процессе мы всегда полностью копировали конфигурацию от сервера к серверу. Нам хотелось разместить наиболее нагруженные сервисы отдельно, чтобы не тратить ресурсы впустую, и получить более гибкое управление нашей схемой развертывания.
Трудно внедрять современные технологии
Знакомая всем разработчикам проблема: есть желание внедрить в проект современные технологии, но нет возможности. При большом монолитном решении любое обновление текущей библиотеки, не говоря о переходе на новую, превращается в достаточно нетривиальную задачу. Нужно долго доказывать тимлиду, что это принесет больше бонусов, чем потраченных нервов.
Сложность выдачи изменений
Это была самая серьезная проблема — мы выдавались релизами каждые два месяца.
Каждый релиз превращался в настоящую катастрофу для банка, несмотря на тестирование и усилия разработчиков. Бизнес понимал, что у него в начале недели не будет работать часть функциональности. А разработчики понимали, что их ждет неделя серьезных инцидентов.
Желание изменить ситуацию было у всех.
Ожидания от микросервисов
Выдача компонентов по готовности. Выдача компонентов по мере готовности благодаря декомпозиции решения и отделения различных процессов.
Небольшие продуктовые команды. Это важно, потому что большой командой, работающей над старым монолитом, сложно было управлять. Такая команда вынуждена была работать по строгому процессу, а хотелось больше творчества и независимости. Это могли позволить себе только небольшие команды.
Изоляция сервисов в отдельных процессах. В идеале хотелось изолировать в контейнерах, но большое количество сервисов, написанных на .NET Framework, запускается только под Windows. Сейчас появляются сервисы на .NET Core, но их пока мало.
Гибкость развертывания. Хотелось бы комбинировать сервисы так, как это необходимо нам, а не так, как заставляет код.
Использование новых технологий. Это интересно любому программисту.
Проблемы перехода
Конечно, если бы разбить монолит на микросервисы было просто, об этом не нужно было бы говорить на конференциях и писать статьи. В этом процессе много подводных камней, опишу основные, которые мешали нам.
Первая проблема типична для большинства монолитов: связность бизнес-логики. Когда мы пишем монолит, то хотим переиспользовать наши классы, чтобы не писать лишний код. А при переходе на микросервисы это становится проблемой: весь код достаточно жестко связан, и сложно разделить сервисы.
На момент начала работ в репозитории было более 500 проектов и более 700 тыс. строк кода. Это достаточно большое решение и вторая проблема. Просто взять и разделить его на микросервисы не представлялось возможным.
Третья проблема — отсутствие необходимой инфраструктуры. Фактически мы занимались ручным копированием исходного кода на серверы.
Как перейти от монолита к микросервисам
Выделение микросервисов
Во-первых, мы для себя сразу определили, что разделение микросервисов — процесс итерационный. От нас всегда требовали параллельно вести разработку бизнес-задач. Как мы будем осуществлять это технически — уже наша проблема. Поэтому мы готовились к итерационному процессу. По-другому не получится, если у вас большое приложение, и оно изначально не готово к тому, чтобы его переписывали.
Какие мы используем способы для выделения микросервисов?
Первый способ — выносить существующие модули как сервисы. В этом плане нам повезло: уже были оформленные службы, которые работали по протоколу WCF. Они были разнесены по отдельным сборкам. Мы переносили их отдельно, добавляя к каждой сборке небольшой модуль запуска. Он был написан с помощью замечательной библиотеки Topshelf, которая позволяет запускать приложение и как сервис, и как консоль. Это удобно для отладки, так как не требуется дополнительных проектов в решении.
Службы были связаны по бизнес-логике, так как использовали общие сборки и работали с общей БД. Их трудно было назвать микросервисами в чистом виде. Тем не менее, мы могли эти сервисы выдавать отдельно, в разных процессах. Уже это позволяло уменьшить влияние их друг на друга, уменьшив проблему с параллельной разработкой и единой точкой отказа.
Сборка с хостом — это всего одна строчка кода в классе Program. Работу с Topshelf мы спрятали во вспомогательный класс.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
Второй способ выделения микросервисов: создавать их для решения новых задач. Если при этом монолит не растет, это уже отлично, значит, мы двигаемся в правильном направлении. Для решения новых задач мы старались делать отдельные сервисы. Если была такая возможность, то мы создавали сервисы более «каноничные», которые полностью управляют своей моделью данных, отдельной базой данных.
Мы, как и многие, начинали с сервисов аутентификации и авторизации. Они идеально для этого подходят. Они независимы, как правило, у них обособленная модель данных. Они сами не взаимодействуют с монолитом, только он обращается к ним для решения каких-то задач. На этих сервисах можно начать переход на новую архитектуру, отладить на них инфраструктуру, попробовать какие-то подходы, связанные с сетевыми библиотеками, и т.д. У нас в организации нет команд, у которых не получилось бы сделать сервис аутентификации.
Третий способ выделения микросервисов, которым мы пользуемся, немного специфичен для нас. Это вынесение бизнес-логики из UI-слоя. У нас основное UI-приложение десктопное, оно, как и backend, написано на C#. Разработчики периодически ошибались и выносили на UI части логики, которые должны были существовать в backend и переиспользоваться.
Если посмотреть реальный пример из кода UI-части, то видно, что большая часть этого решения содержит в себе настоящую бизнес-логику, которая полезна в других процессах, не только для построения UI-формы.
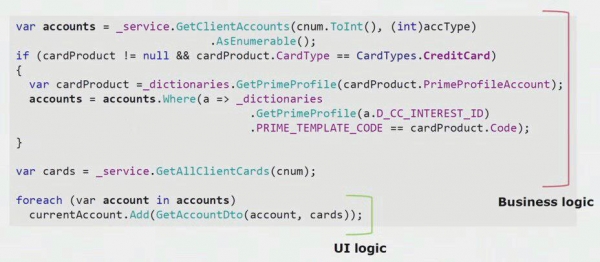
Реальной логики UI там только последняя пара строк. Мы ее переносили на сервер для того, чтобы можно было переиспользовать, тем самым уменьшая UI и добиваясь правильной архитектуры.
Четвертый, самый важный способ выделения микросервисов, который и позволяет уменьшать монолит, — это вынесение существующих сервисов с переработкой. Когда мы выносим существующие модули как есть, результат не всегда нравится разработчикам, и бизнес-процесс со времени создания функционала мог устареть. Благодаря рефакторингу мы можем поддержать новый бизнес-процесс, потому что требования бизнеса постоянно меняются. Мы можем улучшить исходный код, убрать известные дефекты, создать более качественную модель данных. Набирается много преимуществ.
Отделение сервисов с переработкой неразрывно связано с понятием ограниченного контекста. Это понятие из предметно-ориентированного проектирования. Оно означает участок доменной модели, в котором все термины единого языка однозначно определены. Рассмотрим на примере контекста страховок и счетов. У нас монолитное приложение, и необходимо в страховках поработать со счетом. Мы ожидаем, что разработчик найдет в другой сборке существующий класс «Счет», сделает ссылку на него из класса «Страховка», и мы получим рабочий код. Принцип DRY будет соблюден, задача за счет использования существующего кода будет сделана быстрее.
В итоге оказывается, что контексты счетов и страховок связаны. Когда появятся новые требования, эта связь будет мешать разработке, увеличивая сложность и без того сложной бизнес-логики. Для решения этой проблемы нужно в коде находить границы между контекстами и убирать их нарушения. Например, контексту страховок, вполне возможно, будет достаточно 20-значного номера счета ЦБ и даты открытия счета.
Чтобы эти ограниченные контексты отделять друг от друга и начать процесс выделения микросервисов из монолитного решения, мы использовали такой подход, как создание внутри приложения внешних API. Если мы знали, что какой-то модуль должен стать микросервисом, как-то видоизмениться в рамках процесса, то мы сразу же делали вызовы логики, которая принадлежит другому ограниченному контексту, через внешние вызовы. Например, через REST или WCF.
Мы для себя твердо решили, что не будем избегать кода, который потребует делать распределенные транзакции. В нашем случае оказалось достаточно легко соблюдать это правило. У нас до сих пор не возникло таких ситуаций, когда реально нужны жесткие распределенные транзакции — вполне достаточно итоговой согласованности между модулями.
Рассмотрим конкретный пример. У нас есть понятие оркестратора — конвейера, который обрабатывает сущность «заявки». Он по очереди создает клиента, счет и банковскую карту. Если клиент и счет созданы успешно, а создание карты провалилось, заявка не переходит в статус «успешно» и остается в статусе «карта не создана». В будущем фоновая активность подхватит ее и закончит. Система некоторое время находится в состоянии несогласованности, но нас это, в целом, устраивает.
В случае если все же появится ситуация, когда нужно будет согласованно сохранить часть данных, мы, скорее всего, пойдем на укрупнение сервиса, чтобы обработать это в одном процессе.
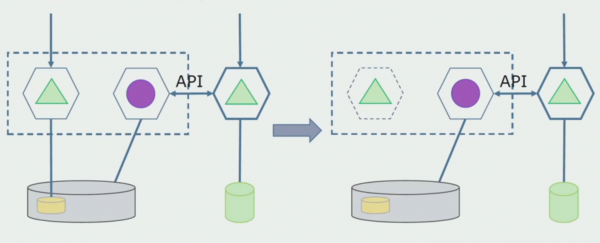
Рассмотрим пример выделения микросервиса. Каким образом можно относительно безопасно довести его до продакшн? В этом примере у нас есть отдельная часть системы — модуль зарплатного обслуживания, один из участков кода которого мы хотели бы сделать микросервисным.
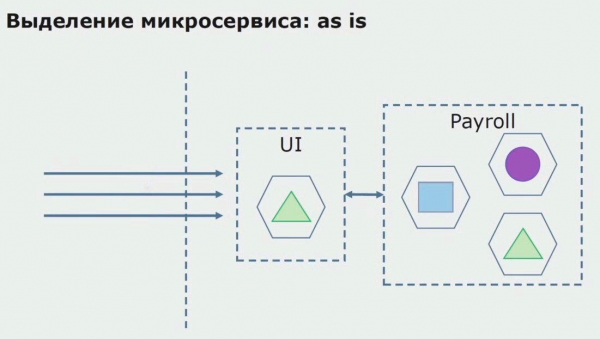
Первым делом создаем микросервис, переписывая код. Улучшаем некоторые моменты, которые нас не устраивали. Реализуем новые бизнес-требования от заказчика. Добавляем в связку между UI и бэкендом API Gateway, который будет обеспечивать проброс вызовов.
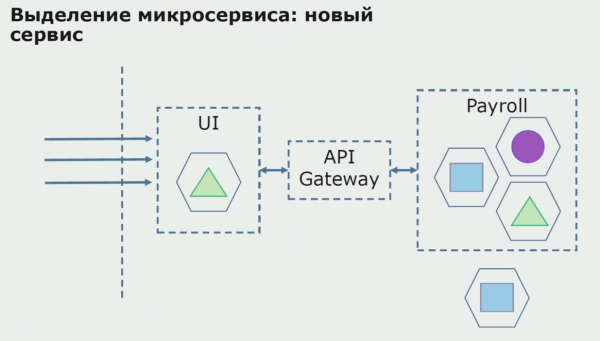
Далее мы выпускаем эту конфигурацию в эксплуатацию, но в состоянии пилота. Большинство пользователей у нас по-прежнему работает со старыми бизнес-процессами. Для новых пользователей мы разрабатываем новую версию монолитного приложения, которое этот процесс уже не содержит. По сути у нас в виде пилота работает связка монолита и микросервиса.
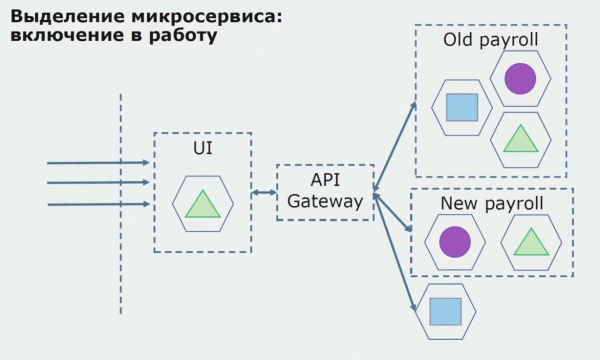
При успешном пилоте мы понимаем, что новая конфигурация действительно работоспособна, можем убрать из уравнения старый монолит и оставить новую конфигурацию на месте старого решения.
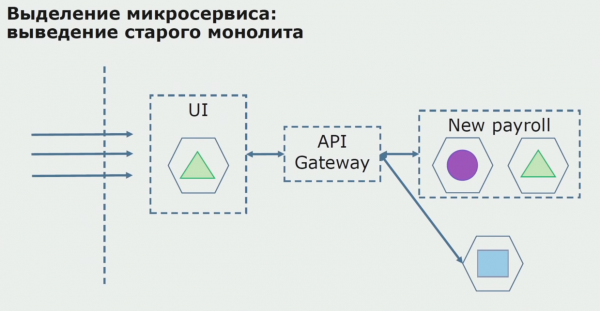
Итого, мы используем практически все существующие методы разделения исходного кода монолита. Все они позволяют нам уменьшать размер частей приложения и переводить их на новые библиотеки, делая более качественный исходный код.
Работа с БД
БД поддается разделению хуже, чем исходный код, так как содержит не только текущую схему, но и накопленные исторические данные.
У нашей БД, как и у многих других, был еще один важный недостаток — огромный размер. Эту БД проектировали в соответствии с запутанной бизнес-логикой монолита, и между таблицами различных ограниченных контекстов накопились связи.
В нашем случае в довершение всех бед (большая база данных, множество связей, иногда непонятные границы между таблицами) возникла проблема, встречающаяся во многих крупных проектах: использование шаблона shared database. Данные брались из таблиц через view, через репликацию и отгружались в другие системы, где нужна эта репликация. В результате мы не могли выносить таблицы в отдельную схему, потому что они активно использовались.
В разделении нам помогает то самое разбиение на ограниченные контексты в коде. Оно, как правило, дает нам достаточно хорошее представление о том, как мы разбиваем данные на уровне базы данных. Мы понимаем, какие таблицы относятся к одному ограниченному контексту, а какие к другому.
Мы применили два глобальных способа разделения базы данных: отделение существующих таблиц и отделение с переработкой.
Отделение существующих таблиц — это метод, который хорошо применять тогда, если структура данных качественная, удовлетворяет бизнес-требованиям и всех устраивает. В этом случае мы можем выделять в отдельную схему существующие таблицы.
Отделение с переработкой нужно тогда, когда бизнес-модель сильно поменялась, и таблицы уже совершенно нас не удовлетворяют.
Отделение существующих таблиц. Нам нужно определить, что мы будем отделять. Без этого знания ничего не получится, и здесь нам поможет разделение ограниченных контекстов в коде. Как правило, если получается понять границы контекстов в исходном коде, становится понятно, какие таблицы должны попасть в перечень на отделение.
Представим, что у нас есть решение, в котором два модуля монолита взаимодействуют с одной базой данных. Нам нужно сделать так, чтобы с участком отделяемых таблиц взаимодействовал только один модуль, а другой начал взаимодействовать с ним через API. Для начала достаточно, чтобы через API велась только запись. Это необходимое условие, чтобы мы могли говорить о независимости микросервисов. Связи на чтение могут оставаться, пока в этом нет большой проблемы.
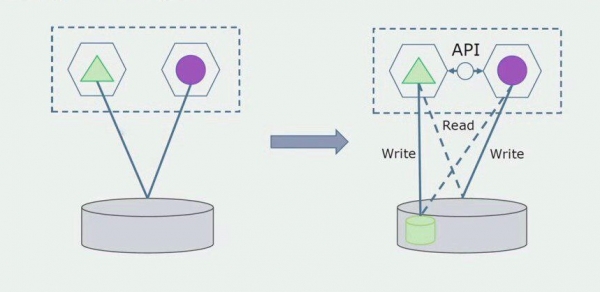
Следующим шагом мы уже можем участок кода, работающий с отделяемыми таблицами, с переработкой или без переработки выделить в отдельный микросервис и запускать в отдельном процессе, контейнере. Это будет отдельный сервис со связью с базой данных монолита и теми таблицами, которые не относятся непосредственно к нему. Монолит еще взаимодействует на чтение с отделяемой частью.
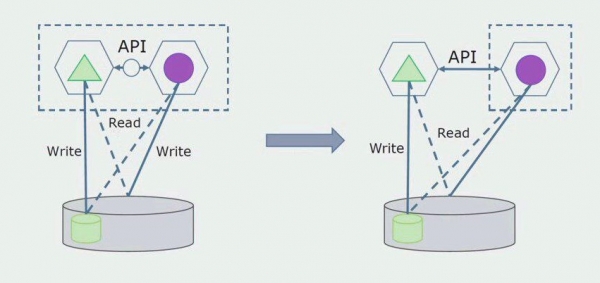
Позднее мы уберем эту связь, то есть чтение данных монолитного приложения из отделяемых таблиц тоже переведем на API.
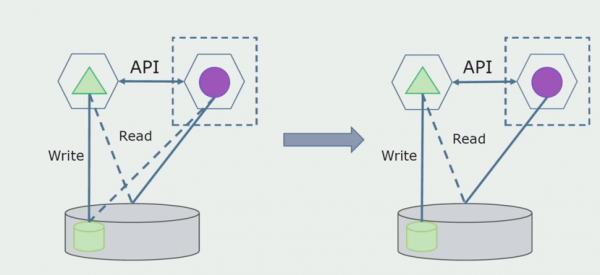
Далее выделим из общей БД таблицы, с которыми работает только новый микросервис. Мы можем вынести таблицы в отдельную схему или даже в отдельную физическую БД. Осталась связь на чтение между микросервисом и БД монолита, но в этом нет ничего страшного, в такой конфигурации он может жить достаточно долго.
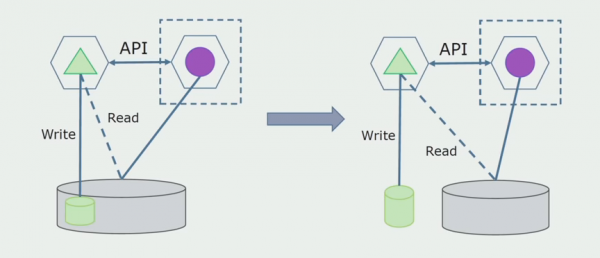
Последний шаг — полностью убрать все связи. В этом случае нам, возможно, потребуется миграция данных от основной базы. Иногда мы захотим переиспользовать в нескольких базах какие-то реплицируемые из внешних систем данные или справочники. У нас это периодически встречается.
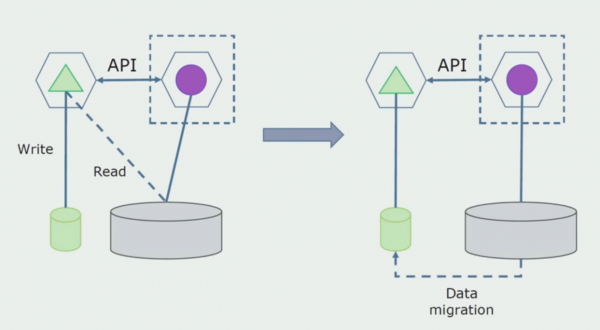
Отделение с переработкой. Этот метод очень похож на первый, только идет в обратном порядке. У нас сразу же выделяется новая база данных и новый микросервис, который взаимодействует с монолитом через API. Но при этом остается набор таблиц БД, которые мы хотим в будущем удалить. Он нам больше не потребуется, в новой модели мы его заменили.
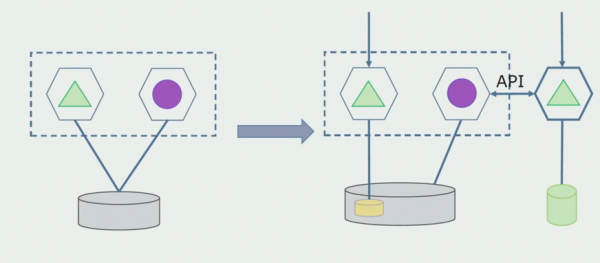
Чтобы эта схема заработала, нам, скорее всего, потребуется переходный период.
Далее есть два возможных подхода.
Первый: мы дублируем все данные в новой и старой базах. В этом случае у нас возникает избыточность данных, могут возникать проблемы с синхронизацией. Но зато мы можем взять два разных клиента. Один будет работать с новой версией, другой со старой.
Второй: разделяем данные по какому-то бизнес-признаку. Например, у нас в системе было 5 продуктов, которые хранятся в старой базе данных. Шестой в рамках новой бизнес-задачи мы помещаем в новую БД. Но нам понадобится API Gateway, который синхронизирует эти данные и покажет клиенту, откуда и что брать.
Оба подхода рабочие, выбирайте в зависимости от ситуации.
После того, как мы убедимся, что все работает, часть монолита, работающую со старыми структурами БД, можно отключить.
Последним шагом будет удаление старых структур данных.
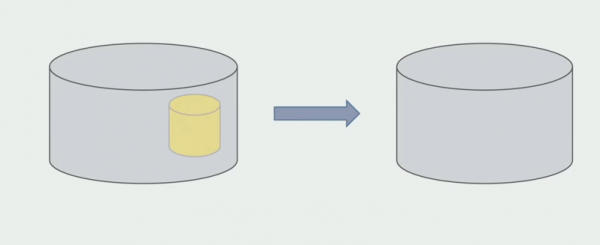
Подводя итог можно сказать, что у нас существуют проблемы с БД: сложно с ней работать по сравнению с исходным кодом, разделять сложнее, но делать это можно и нужно. Мы нашли некоторые способы, которые позволяют это делать достаточно безопасно, все же с данными допустить ошибку проще, чем с исходным кодом.
Работа с исходным кодом
Вот так выглядела схема исходного кода, когда мы начали анализировать монолитный проект.
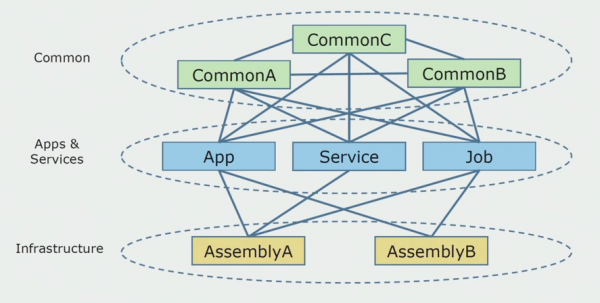
Ее условно можно разделить ее на три слоя. Это слой запускаемых модулей, плагинов, сервисов и отдельных активностей. Фактически, это были входные точки внутри монолитного решения. Все они были намертво скреплены слоем Common. В нем была бизнес-логика, которая использовалась сервисами совместно, и множество связей. Каждый сервис и плагин использовал до 10 и более common-сборок, в зависимости от их размера и совести разработчиков.
Нам повезло, у нас были инфраструктурные библиотеки, которые можно было использовать отдельно.
Иногда возникала ситуация, когда некоторые Сommon-объекты на самом деле не относились к этому слою, а были инфраструктурными библиотеками. Это решалось переименованием.
Больше всего беспокойства вызывали ограниченные контексты. Бывало, что 3-4 контекста смешивались в одной сборке Common и использовали друг друга в рамках одних бизнес-функций. Необходимо было понять, где это можно разделить и по каким границам, и что дальше делать с маппингом этого разделения на сборки исходного кода.
Мы сформулировали несколько правил для процесса разделения кода.
Первое: мы больше не хотели совместного использования бизнес-логики между сервисами, активностями и плагинами. Хотели сделать бизнес-логику независимой в рамках микросервисов. С другой стороны, микросервисы, в идеальном случае, воспринимаются как сервисы, которые существуют совершенно независимо. Я считаю, что этот подход несколько расточителен, да и достигнуть его сложно, ведь, например, сервисы на C# будут в любом случае соединены стандартной библиотекой. Наша система написана на С#, другие технологии пока использовать не приходилось. Поэтому мы решили, что можем себе позволить использовать общие технические сборки. Главное, чтобы в них не было никаких фрагментов бизнес-логики. Если у вас есть удобная обертка над ORM, который вы используете, то скопировать ее из сервиса в сервис очень дорого.
Наша команда является поклонниками предметно-ориентированного проектирования, поэтому «луковая архитектура» нам отлично подошла. Основой в наших сервисах стал не data access layer, а сборка с доменной логикой, которая содержит только бизнес-логику и лишена связей с инфраструктурой. При этом мы можем независимо дорабатывать доменную сборку для решения проблем, связанных с фреймворками.
На этом этапе мы встретили первую серьезную проблему. Сервис должен был ссылаться на одну доменную сборку, логику мы хотели сделать независимой, и нам тут сильно мешал принцип DRY. Разработчики хотели для избежания дублирования переиспользовать классы из соседних сборок, и в результате домены снова начали связываться между собой. Мы проанализировали результаты и решили, что, возможно, проблема лежит еще и в области устройства хранилища исходного кода. У нас имелся большой репозиторий, в котором лежали все исходные коды. Solution для всего проекта очень трудно было собрать на локальной машине. Поэтому для частей проекта создавались отдельные маленькие solution, и никто не запрещал добавить в них какую-нибудь Сommon- или доменную сборку и переиспользовать. Единственный инструмент, который не позволял нам этого делать, это код ревью. Но иногда и он давал сбои.
Тогда мы начали переходить на модель с отдельными репозиториями. Бизнес-логика перестала утекать из сервиса в сервис, домены действительно стали независимыми. Ограниченные контексты поддерживаются более ясно. Как при этом мы переиспользуем инфраструктурные библиотеки? Мы выделили их в отдельный репозиторий, затем поместили в Nuget-пакеты, которые положили в Artifactory. При любом изменении сборка и публикация происходит автоматически.
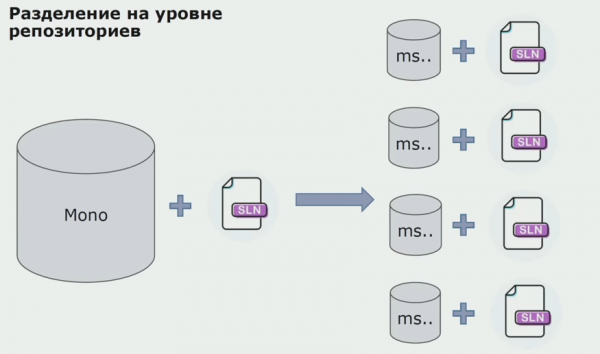
Наши сервисы стали ссылаться на внутренние инфраструктурные пакеты точно так же, как и на внешние. Внешние библиотеки мы скачиваем из Nuget. Для работы с Artifactory, куда мы помещали эти пакеты, мы применили два пакетных менеджера. В маленьких репозиториях мы тоже использовали Nuget. В репозиториях с несколькими сервисами мы использовали Paket, который обеспечивает больше согласованности версий между модулями.
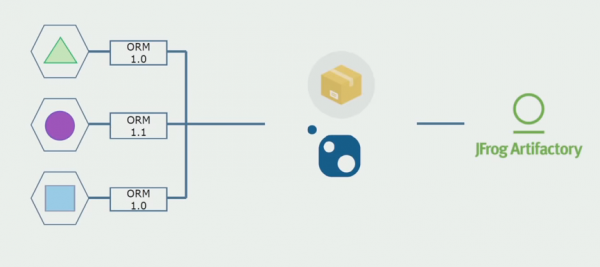
Таким образом, работая над исходным кодом, немного изменив архитектуру и разделяя репозитории, мы делаем наши сервисы более независимыми.
Проблемы инфраструктуры
Большинство недостатков при переходе на микросервисы связано с инфраструктурой. Вам потребуется автоматизированное развертывание, потребуются новые библиотеки для работы инфраструктуры.
Ручная установка в среды
Изначально решение на среды мы устанавливали вручную. Чтобы автоматизировать этот процесс, мы создали CI/CD-конвейер. Выбрали процесс continuous delivery, потому что continuous deployment для нас пока неприемлем с точки зрения бизнес-процессов. Поэтому отправка в эксплуатацию осуществляются по кнопке, а на тестирование — автоматически.
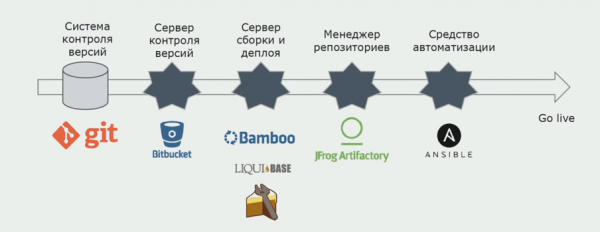
Мы используем Atlassian, Bitbucket для хранения исходных кодов и Bamboo для сборки. Нам нравится писать сборочные скрипты на Cake, потому что это тот же самый C#. В Artifactory приходят уже готовые пакеты, и Ansible автоматически попадает на тестовые серверы, после чего их можно сразу тестировать.
Раздельное логирование
В свое время, одной из идей монолита было обеспечение совместного логирования. Нам также нужно было понять, что делать с отдельными логами, которые лежат на дисках. Логи у нас пишутся в текстовые файлы. Мы решили использовать стандартный ELK-стек. Не стали писать в ELK напрямую через провайдеры, а решили, что доработаем текстовые логи и будем записывать в них ID трассировки в виде идентификатора, добавляя имя сервиса, чтобы эти логи потом можно было разбирать.
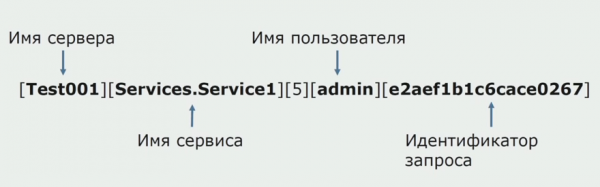
С помощью Filebeat мы получаем возможность собирать наши логи с серверов, затем их преобразовывать, с помощью Kibana строить запросы в UI и смотреть, как шел вызов между сервисами. В этом сильно помогает ID трассировки.
Тестирование и отладка связанных сервисов
Изначально мы не до конца понимали, как нам отлаживать разрабатываемые сервисы. С монолитом все было просто, мы запускали его на локальной машине. Сначала так же пытались делать и с микросервисами, но иногда для полноценного запуска одного микросервиса нужно запускать и несколько других, а это неудобно. Мы поняли, что необходимо переходить к модели, когда мы оставляем на локальной машине только сервис либо сервисы, который хотим отладить. Остальные сервисы используются с серверов, совпадающих по конфигурации с prod. После отладки, при тестировании, для каждой задачи на тестовый сервер выдаются только измененные сервисы. Таким образом, тестируется решение в таком виде, в каком оно в будущем окажется на проде.
Есть серверы, на которых стоят только production-версии сервисов. Эти серверы нужны на случай инцидентов, для проверки поставки перед деплоем и для внутренних обучений.
У нас добавился процесс автоматического тестирования с помощью популярной библиотеки Specflow. Тесты запускаются автоматически с помощью NUnit сразу после развертывания из Ansible. Если покрытие задачи полностью автоматическое, то нет необходимости в ручном тестировании. Хотя иногда все-таки требуется дополнительное ручное тестирование. Для определения, какие тесты запускать для конкретной задачи, мы используем теги в Jira.
Дополнительно выросла потребность в нагрузочном тестировании, ранее оно проводилось только в редких случаях. Для запуска тестов мы используем JMeter, для их хранения — InfluxDB, а для построения графиков процесса — Grafana.
Чего мы добились?
Во-первых, мы избавились от понятия «релиз». Исчезли двухмесячные монструозные релизы, когда эта махина развертывалась в production-среде, ломая на время бизнес-процессы. Сейчас мы разворачиваем сервисы в среднем каждые 1,5 дня, группируя их, потому что в эксплуатацию они выходят после согласования.
В нашей системе нет фатальных сбоев. Если мы выпустили микросервис с ошибкой, то связанная с ней функциональность будет сломана, а вся остальная функциональность не пострадает. Это значительно улучшает пользовательский опыт.
Мы можем управлять схемой развертывания. Можно выделять группы сервисов отдельно от остального решения, если в этом есть необходимость.
Кроме того, мы существенно уменьшили проблему с большой очередью доработок. У нас появились отдельные продуктовые команды, которые работают с частью сервисов независимо. Тут уже неплохо подходит Scrum-процесс. У конкретной команды может быть отдельный владелец продукта, который ставит ей задачи.
Резюме
- Микросервисы хорошо подходят для декомпозиции сложных систем. В процессе мы начинаем понимать, что есть в нашей системе, какие имеются ограниченные контексты, где проходят их границы. Это позволяет правильно распределять доработки по модулям и не допустить запутывания кода.
- Микросервисы дают организационные преимущества. О них часто говорят только как об архитектуре, но любая архитектура нужна для решения потребностей бизнеса, а не сама по себе. Поэтому мы можем сказать, что микросервисы хорошо подходят для решения задач небольшими командами, учитывая, что сейчас очень популярен Scrum.
- Разделение — это итеративный процесс. Нельзя взять приложение и просто разделить на микросервисы. Получившийся продукт вряд ли будет работоспособным. При выделении микросервисов выгодно переписывать существующее legacy, то есть превращать его в код, который нам нравится и лучше удовлетворяет потребностям бизнеса по функциональности и скорости.
Небольшое предостережение: затраты на переход к микросервисам достаточно существенные. Только на решение проблемы инфраструктуры ушло много времени. Поэтому, если у вас небольшое приложение, которое не требует специфического масштабирования, если нет большого числа заказчиков, которые борются за внимание и время вашей команды, то, возможно, микросервисы — это не то, что вам необходимо сегодня. Это достаточно дорого. Если начинать процесс с микросервисов, то затраты поначалу будут больше, чем если тот же самый проект начинать с разработки монолита.
P.S. Более эмоциональный рассказ (и как будто лично вам) – по .
Здесь полная версия доклада.
Источник: habr.com
