

Первый API МоегоСклада появился 10 лет назад. Всё это время мы работаем над существующими версиями API и разрабатываем новые. А несколько версий API уже успели похоронить.
В этой статье будет много всего: как создавали API, зачем он нужен облачному сервису, что дает пользователям, на какие грабли мы успели наступить и что хотим делать дальше.
Меня зовут Олег Алексеев , я технический директор и сооснователь МоегоСклада.
Зачем делать API для сервиса
Наши клиенты, а это десятки тысяч предпринимателей, активно пользуются облачными решениями: банкингом, интернет-магазинами, товарным учетом, CRM. Подключился к одному — и уже трудно остановиться. И вот уже пятый, восьмой, десятый сервис делает работу предпринимателя легче, но данные между этими облачными сервисами пользователи переносят вручную. Работа превращается в кошмар.
Очевидное решение — дать пользователям возможность передавать данные между облачными сервисами. Например, импортировать и экспортировать данные как файлы, которые затем можно загрузить в нужный сервис. Файлы обычно меняют под формат каждого сервиса. Это более-менее простая ручная работа, но с ростом количества этих сервисов выполнять ее становится всё сложнее.
Поэтому следующий шаг — API. С ним облачный сервис выигрывает от того, что связывает несколько сервисов в одной точке. Появление такой экосистемы притягивает новых клиентов за счет дополнительных возможностей. Продукт с новым функционалом становится более выгодным и полезным.
Если создавать собственные программные интерфейсы, это привлекает сторонних продажников в виде программистов, которые знают о вашем продукте благодаря API. Они начинают строить решения на основе предложенного API и зарабатывают деньги на автоматизации задач своих заказчиков.
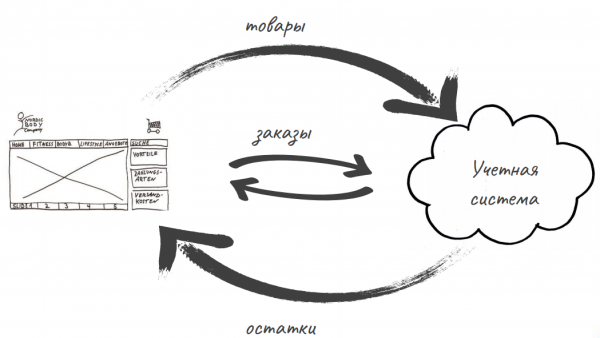
Учетная система МоегоСклада строится на простых процессах. Главное — работа с первичными документами, возможность проводить приемку и отгрузку товара, получать на основе первички отчеты для бизнеса. Также есть передача данных, например в облачную бухгалтерию, и их получение из банковских систем или розничных точек. Еще мы работаем с интернет-магазинами: получаем сведения о товарах и отправляем данные об остатках.
Первый API МоегоСклада
За 10 лет работы МоегоСклада с API мы обросли всевозможными интеграциями, которые позволяют обмениваться данными, работать с банками, проводить оплату и использовать внешнюю телефонию.
В первый год мы сделали возможность выгружать любые данные в формате XML. Тогда пользователям было куда понятнее и привычнее держать данные в офлайне, а не в каком-то там облаке, и мы дали им это. Выгрузка запускалась ручным экспортом из интерфейса. То есть API это еще нельзя было назвать.
Тогда же мы стали сотрудничать с компанией Русагро — они уже использовали «взрослую» ERP для планирования производства и сбыта, а вот загрузку вагонов на заводах автоматизировали в МоемСкладе. Так у нас появились первые зачатки настоящего API: обмен между нашим сервисом и ERP происходил путем пересылки большого файла с данными по всем типам документов.
Это неплохой вариант для пакетного обмена данными, но вместе с документами приходилось передавать их зависимости: сведения о товарах, контрагентах и складах. Такую свалку не так трудно сгенерировать при экспорте, но довольно трудно разбирать при импорте, так как в одном пакете приезжают все сведения: и про новые документы, и про уже существующие.
Первый XML API прожил недолго — спустя два года мы начали его перестройку. Еще на старте его работы мы совершили несколько ошибок при построении программного интерфейса.

Как делался XML API: иллюстрация от одного из наших архитекторов. Кстати, ждите его статей.
Вот наши основные ошибки:
- JAXB-разметка была сделана напрямую на entity beans. Для общения с базой мы используем Hibernate, и на эти же бины была сделана JAXB-разметка. Эта ошибка вылезла почти сразу: любое обновление структуры данных приводило к необходимости срочного уведомления всех, кто использует API, либо построению костылей, которые обеспечивали бы совместимость с предыдущей структурой данных.
- API произрастал как некое дополнение, и изначально мы не определили, какую часть продукта он составляет. Не думали и над тем, является ли API чем-то важным, нужно ли поддерживать обратную совместимость для первых его клиентов. На какой-то момент число пользователей API составляло около 5% от общего небольшого числа, и внимания на них не обращали. Сделанная в свое время универсальная фильтрация привела к тому, что нас стали использовать как бэкенд. Фильтрация эта была совсем не GraphQL, но что-то типа того — работала через уйму параметров строки запроса. С таким мощным инструментом пользователям было трудно удержаться, и на нас перевели запросы так, что они отправлялись напрямую с UI их интернет-магазинов. Ситуация стала неприятным сюрпризом, потому что предоставление такой услуги должно требовать иной тарификации и вообще иного понимания самого API как продукта.
- Из-за того, что API развивался не как основной продукт, документация по API производилась и публиковалась по остаточному принципу — через реверс-инжиниринг. Такой путь кажется достаточно простым и удобным, но противоречит работе по контракту. Это когда есть некий компонент с предустановленной схемой работы. Разработчик реализует его в соответствии с этой схемой и задачей, компонент проходит тестирование, клиент получает продукт, который соответствует задумке аналитика. Реверс-инжиниринг же на рынок выбрасывает продукт, который просто есть: с костылями, странными решениями и велосипедами вместо нужного функционала.
- Весь поток запросов, который приходил через API, можно было проанализировать не более как лог Nginx’а или application server’а. Это не позволяло выделить предметные области, разве что разбить по пользователям и подписчикам. Если нет возможности регулировать регистрацию приложения или клиентов, анализировать ситуацию становится невозможно. Эта проблема в наименьшей степени повлияла на развитие API, она больше про понимание его востребованности и наполненности функционалом.
Попытка номер два: REST API
В 2010 году мы пытались построить систему обмена с онлайн-бухгалтерией — БухСофтом. Не взлетело. Зато в процессе интеграции появился полноценный API: REST-сервис обмена, где отсутствовали вольности вроде обращений к операциям в виде RPC вызовов. Всё общение с API было приведено к стандартному для реста режиму: в строке запроса содержится название сущности, а операция, которая с ней производится, задается с помощью http-метода. Мы добавили фильтрацию по моменту обновления сущностей, и у пользователей появилась возможность строить репликацию со своими системами.
В том же году появился API для выгрузки складских и товарных остатков. Для пользователей стали доступны через API наиболее ценные части системы — обмен первичными документами и расчетные данные по остаткам и себестоимости товаров.
В декабре 2015 года RetailCRM опубликовал первую стороннюю библиотеку для доступа к нашему API. Ее стали довольно активно использовать, при этом росла популярность сервиса в целом, нагрузка на API росла быстрее нагрузки на веб-интерфейс. Однажды рост превратился в скачок нагрузки.
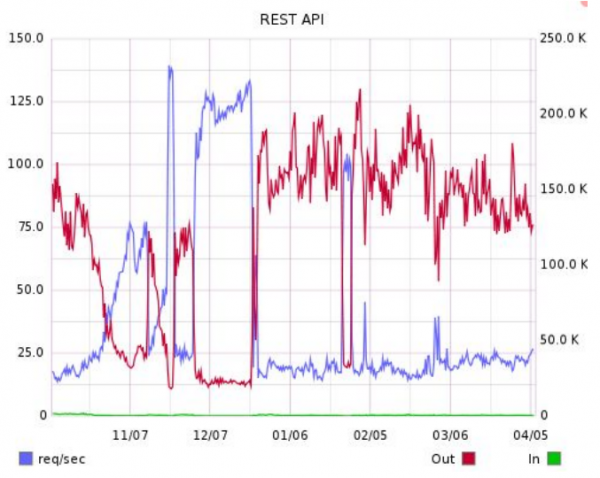
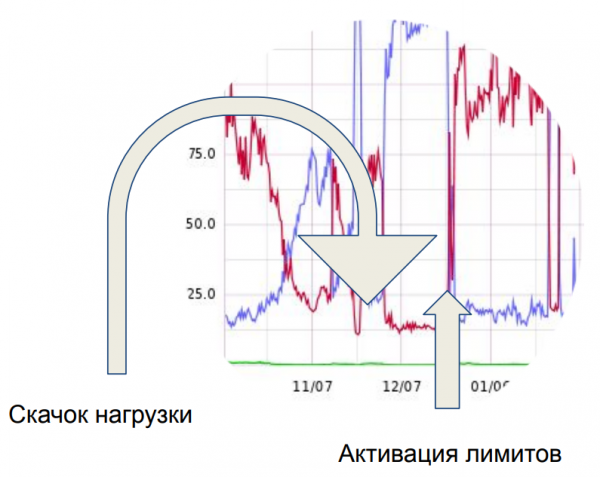
И этот скачок, на который показывает стрелка слева, привел в полнейшее изумление сервер, обслуживающий наш API. Неделю мы разбирались, что именно эту нагрузку генерирует. Оказалось, что это те самые запросы, транслируемые на наш API с фронтов у клиентов. Всё съели около 50 клиентов. Тут-то мы и поняли одну из своих ошибок — полное отсутствие лимитов.
В итоге мы ввели лимит на количество одновременных запросов. С одной учетки стало можно одновременно открывать не более двух запросов. Этого достаточно для работы в режиме репликации для обмена данными в пакетном режиме. А те, кто хотел использовать нас как бэкенд, с этого момента были вынуждены больше соответствовать тарифам, так как ввели в свои программные средства работу по нескольким учеткам.
Приводим в порядок
Уже с 2014 года спрос на существующий API стал важной частью бизнеса, а сам API генерировал самый большой объем данных в обмене данными с клиентами. В 2015 году мы запустили проект приведения API в порядок. Выбрали в качестве формата JSON вместо XML и стали строить его на основе особенностей, которые выявили при реализации предыдущей версии:
- Возможность управлять версиями. Версионирование позволяет разрабатывать новую версию, не затрагивая существующее приложение и не нарушая работу пользователей.
- Возможность пользователю видеть метаданные в самом ответе, который он получает.
- Возможность обмена большими документами. Если мы обрабатываем документ с количеством позиций больше 4-5 тысяч, это становится проблемой для сервера: длинная транзакция, длинный http-запрос. Построили специальный механизм, позволяющий обновлять документ частями и управлять отдельными позициями этого документа, отправляя их на сервер.
- Инструменты для репликации — были и в предыдущей версии.
- Лимиты по нагрузке — как наследие граблей, на которые наступили в предыдущей версии. Ввели лимиты на количество запросов в промежуток времени, количество параллельных запросов и запросов с одного ip-адреса.
С того момента мы выпустили две минорные версии API и запустили несколько специализированных API, но в целом подход остался без изменений. Обновленный формат обмена и новая архитектура позволили исправлять недостатки в API куда быстрее.
API МоегоСклада сегодня
Сегодня API МоегоСклада решает много задач:
- обмен данными с интернет-магазинами, учетными системами, банками;
- получение расчетных данных, отчетов;
- использование в качестве бэкенда для клиентских приложений — наши мобильные приложения и десктопная касса работают через API
- отправка уведомлений об изменениях данных в МоемСкладе — webhooks;
- телефония;
- системы лояльности.
На основе API наш гендиректор Аскар Рахимбердиев за четыре часа написал телеграм-бот, который тягает через API остатки:
Теперь сухие цифры.
Вот наша статистика по старому REST API:
- 400 компаний;
- 600 пользователей;
- 2 млн запросов в сутки;
- 200 Гб/сутки исходящего трафика.
А вот к чему мы пришли по всем API МоегоСклада:
- более 70 интеграций (часть из них можно посмотреть здесь );
- 8500 компаний;
- 12 000 пользователей;
- 46 млн запросов в сутки;
- 2 Тб/сутки исходящего трафика.
Что дальше
Планы по развитию API находятся в активном обсуждении. Мы стараемся учитывать опыт эксплуатации, которым нас снабжают пользователи. Не всегда и не всё получается делать сразу, но не за горами новая версия API с более удобными метаданными и менее развесистой структурой, OAuth для аутентификации, API для встраиваемых в интерфейс приложений.
Следить за новостями можно на специальном сайте для разработчиков интеграций с МоимСкладом: .
Источник: habr.com
