


Какая версия прошивки самая “правильная” и “рабочая”? Если СХД гарантирует отказоустойчивость на 99,9999%, то значит ли, что и работать она будет бесперебойно даже без обновления ПО? Или наоборот для получения максимальной отказоустойчивости нужно всегда ставить самую последнюю прошивку? Постараемся ответить на эти вопросы, опираясь на наш опыт.
Небольшое введение
Все мы понимаем, что в каждой версии программного обеспечения, будь то операционная система или драйвер для какого-то устройства, зачастую содержатся недоработки/баги и прочие “особенности”, которые могут, как не «проявиться» до конца службы оборудования, так и “вскрыться” только при определенных условиях. Количество и значимость таких нюансов зависит от сложности (функциональности) ПО и от качества тестирования при его разработке.
Зачастую пользователи остаются на “прошивке с завода” (знаменитое — «работает, значит не лезь») или всегда ставят самую последнюю версию (в их понимании последняя значит самая рабочая). Мы же используем другой подход — смотрим релиз ноты для всего используемого оборудования и внимательно выбираем подходящую прошивку для каждой единицы оборудования.
К такому выводу мы пришли, что называется, с опытом. На своем примере эксплуатации расскажем, почему обещанные 99,9999 % надежности СХД ничего не значат, если вы не будете своевременно следить за обновлением и описанием ПО. Наш кейс подойдет для пользователей СХД любого вендора, так как подобная ситуация может произойти с железом любого производителя.
Выбор новой системы хранения данных
В конце прошлого года, к нашей инфраструктуре добавилась интересная система хранения данных: младшая модель из линейки IBM FlashSystem 5000, которая на момент приобретения именовалась Storwize V5010e. Сейчас она продается под названием FlashSystem 5010, но фактически это та же аппаратная база с тем же самым Spectrum Virtualize внутри.
Наличие единой системы управления — это, кстати, и есть основное отличие IBM FlashSystem. У моделей младшей серии она практически не отличается от моделей более производительных. Выбор определённой модели лишь даёт соответствующую аппаратную базу, характеристики которой дают возможность использовать тот или иной функционал или обеспечить более высокий уровень масштабируемости. ПО при этом идентифицирует аппаратную часть и предоставляет необходимый и достаточный функционал для этой платформы.
 IBM FlashSystem 5010
IBM FlashSystem 5010
Кратко про нашу модель 5010. Это двухконтроллерная блочная система хранения данных начального уровня. Она умеет размещать в себе диски NLSAS, SAS, SSD. Размещение NVMe в ней недоступно,так как эта модель СХД позиционируется для решения задач, которым не требуется производительность NVMe дисков.
СХД приобреталась для размещения архивной информации или данных, к которым не происходит частого обращения. Поэтому нам было достаточно стандартного набора её функционала: тиринг (Easy Tier), Thin Provision. Производительность на NLSAS дисках на уровне 1000-2000 IOPS нас тоже вполне устраивала.
Наш опыт — как мы не обновили прошивку вовремя
Теперь собственно про само обновление ПО. На момент приобретения система имела уже немного устаревшую версию ПО Spectrum Virtualize, а именно, 8.2.1.3.
Мы изучили описание прошивок и запланировали обновление до 8.2.1.9. Если бы мы были чуть расторопнее, то этой статьи бы не было — на более свежей прошивке баг бы не произошел. Однако, по определённым причинам обновление этой системы было отложено.
В результате небольшая задержка обновления привела к крайне неприятной картине, как в описании по ссылке: .
Да, в прошивке той версии как раз был актуален так называемый APAR (Authorized Program Analysis Report) HU02104. Проявляется он следующим образом. Под нагрузкой при определённых обстоятельствах начинает переполняться кэш, далее система уходит в защитный режим, в котором отключает ввод-вывод для пула (Pool). В нашем случае выглядело как отключение 3-х дисков для RAID-группы в режиме RAID 6. Отключение происходит на 6 минут. Далее, доступ к Томам в Пуле восстанавливается.
Если кто не знаком со структурой и именованием логических сущностей в контексте IBM Spectrum Virtualize, я сейчас кратко расскажу.
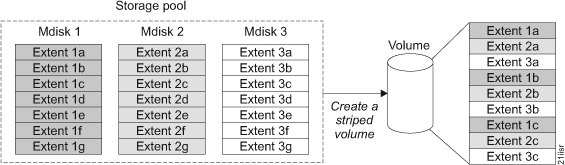 Структура логических элементов СХД
Структура логических элементов СХД
Диски собираются в группы, которые называются MDisk (Managed Disk). MDisk может представлять собой классический RAID (0,1,10,5,6) или виртуализованный – DRAID (Distributed RAID). Использование DRAID позволяет увеличить производительность массива, т.к. будут использоваться все диски группы, и уменьшить время ребилда, благодаря тому, что нужно будет восстанавливать только определённые блоки, а не все данные с вышедшего из строя диска.
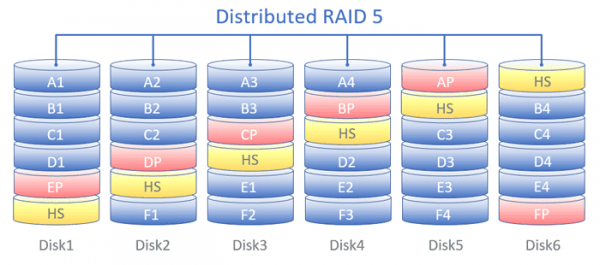 Распределение блоков данных по дискам при использовании Distributed RAID (DRAID) в режиме RAID-5.
Распределение блоков данных по дискам при использовании Distributed RAID (DRAID) в режиме RAID-5.
А эта схема показывает логику работы ребилда DRAID в случае выхода из строя одного диска:
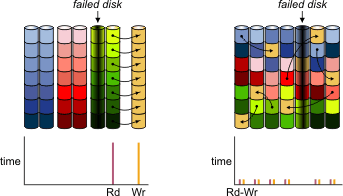 Логика работы ребилда DRAID при выходе из строя одного диска
Логика работы ребилда DRAID при выходе из строя одного диска
Далее, один или несколько MDisk образуют так называемый Pool. В пределах одного пула не рекомендуется использовать MDisk с разным уровнем RAID/DRAID на дисках одного типа. Не будем в это сильно углубляться, т.к. мы планируем рассказать это в рамках одной из следующих статей. Ну и, собственно, Pool делится на Тома (Volumes), которые презентуются по тому или иному протоколу блочного доступа в сторону хостов.
Так вот, у нас, в результате возникновения ситуации, описанной в APAR HU02104, из-за логического отказа трёх дисков, перестал быть работоспособным MDisk, который, в свою очередь, повлёк отказ в работе Pool и соответствующих Томов.
Так как эти системы довольно «умные», их можно подключить к облачной системе мониторинга IBM Storage Insights, которая автоматически, при возникновении неисправности, отправляет запрос на обслуживание в службу поддержки IBM. Создаётся заявка и специалисты IBM в удалённом режиме проводят диагностику и связываются с пользователем системы.
Благодаря этому вопрос решился довольно оперативно и от службы поддержки была получена оперативная рекомендация по обновлению нашей системы на уже ранее выбранную нами прошивку 8.2.1.9, в которой на тот момент этот момент был уже исправлен. Это подтверждает .
Итоги и наши рекомендации
Как говорится: «хорошо то, что хорошо заканчивается». Баг в прошивке не обернулся серьезными проблемами — работа серверов была восстановлена в кратчайшие сроки и без потери данных. У некоторых клиентов пришлось перезапускать виртуальные машины, но в целом мы были готовы к более негативным последствиям, так как ежедневно делаем резервные копии всех элементов инфраструктуры и клиентских машин.
Мы получили подтверждение, что даже надежные системы с 99,9999% обещанной доступности требуют внимания и своевременного обслуживания. Исходя из ситуации мы сделали для себя ряд выводов и делимся нашими рекомендациями:
Нужно обязательно следить за выходом обновлений, изучать Release Notes на предмет исправления потенциально критичных моментов и своевременно выполнять запланированные обновления.
Это организационный и даже довольно очевидный момент, на котором, казалось бы, не стоит заострять внимание. Однако, на этом «ровном месте» можно довольно легко споткнуться. Собственно, именно этот момент и добавил описанные выше неприятности. Относитесь к составлению регламента обновления очень внимательно и не менее внимательно следите за его соблюдением. Этот пункт больше относится к понятию «дисциплина».
Всегда лучше держать систему с актуальной версией ПО. Причём, актуальная – не та, которая имеет большее числовое обозначение, а именно с более поздней датой выхода.
Например, IBM для своих систем хранения данных держит в актуальном состоянии как минимум два релиза ПО. На момент написания этой статьи – это 8.2 и 8.3. Обновления для 8.2 выходят раньше. Следом с небольшой задержкой обычно выходит аналогичное обновление для 8.3.
Релиз 8.3 имеет ряд функциональных преимуществ, например, возможность расширения MDisk (в режиме DRAID) добавлением одного или более новых дисков (такая возможность появилась начиная с версии 8.3.1). Это довольно базовый функционал, но в 8.2 такой возможности, к сожалению, нет.
Если обновиться по каким-либо причинам нет возможности, то для версий ПО Spectrum Virtualize, предшествующих версиям 8.2.1.9 и 8.3.1.0 (где описанный выше баг актуален), для снижения риска его появления техническая поддержка IBM рекомендует ограничить производительность системы на уровне пула, как это показано на рисунке ниже (снимок сделан в русифицированном варианте GUI). Значение 10000 IOPS показано для примера и подбирается согласно характеристикам вашей системы.
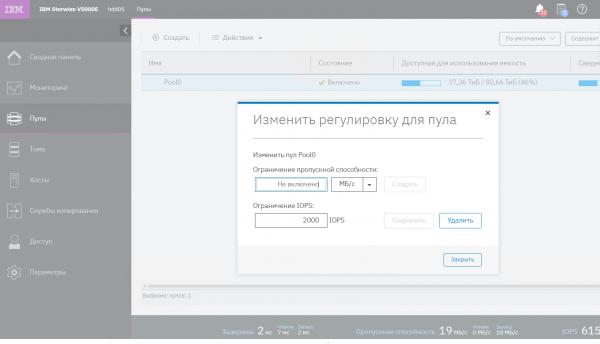 Ограничение производительности СХД IBM
Ограничение производительности СХД IBM
Необходимо правильно рассчитывать нагрузку на системы хранения и не допускать перегрузки. Для этого можно воспользоваться либо сайзером IBM (если есть к нему доступ), либо помощью партнеров, либо сторонними ресурсами. Обязательно при этом понимать профиль нагрузки на систему хранения, т.к. производительность в МБ/с и IOPS сильно разнится в зависимости как минимум от следующих параметров:
тип операции: чтение или запись,
размер блока операции,
процентное соотношение операций чтения и записи в общем потоке ввода-вывода.
Также, на скорость выполнения операций влияет как считываются блоки данных: последовательно или в случайном порядке. При выполнении нескольких операций доступа к данным на стороне приложения есть понятие зависимых операций. Это тоже желательно учитывать. Всё это может помочь увидеть совокупность данных со счётчиков производительности ОС, системы хранения, серверов/гипервизоров, а также понимание особенностей работы приложений, СУБД и прочих «потребителей» дисковых ресурсов.
И напоследок, обязательно иметь резервные копии в актуальном и рабочем состоянии. Расписание резервного копирования нужно настраивать исходя из приемлемых для бизнеса значений RPO и периодически обязательно проверять целостность резервных копий (довольно много производителей ПО для резервного копирования реализовали в своих продуктах автоматизированную проверку) для обеспечения приемлемого значения RTO.
Благодарим, что дочитали до конца.
Готовы ответить на ваши вопросы и замечания в комментариях. Также, в котором мы проводим регулярные акции (скидки на IaaS и розыгрыши промокодов до 100% на VPS), пишем интересные новости и анонсируем новые статьи в блоге Хабра.
Источник: habr.com
