

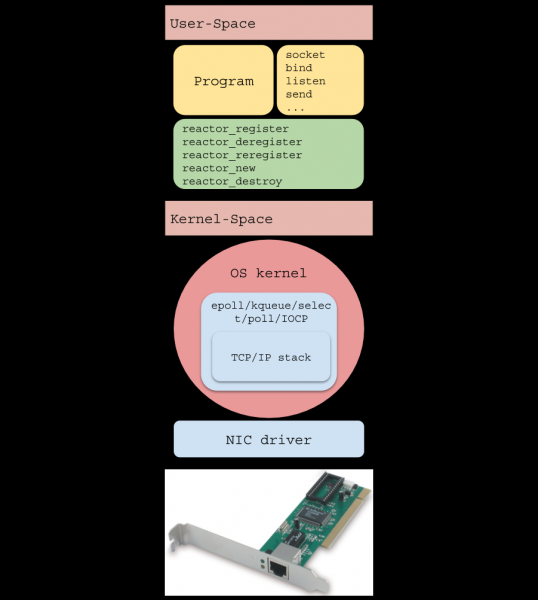
Введение
(однопоточный ) — это паттерн для написания высоконагруженного ПО, используемый во многих популярных решениях:
- …
В данной статье мы рассмотрим подноготную I/O реактора и принцип его работы, напишем реализацию на меньше, чем 200 строк кода и заставим простой HTTP сервер обрабатывать свыше 40 миллионов запросов/мин.
Предисловие
- Статья написана с целью помочь разобраться в функционировании I/O реактора, а значит и осознать риски при его использовании.
- Для усвоения статьи требуется знание основ и небольшой опыт разработки сетевых приложений.
- Весь код написан на языке Си строго по (осторожно: длинный PDF) для Linux и доступен на .
Зачем это нужно?
С ростом популярности Интернета веб-серверам стало нужно обрабатывать большое количество соединений одновременно, в связи с чем было опробовано два подхода: блокирующее I/O на большом числе потоков ОС и неблокирующее I/O в комбинации с системой оповещения о событиях, ещё называемой «системным селектором» (///etc).
Первый подход подразумевал создание нового потока ОС для каждого входящего соединения. Его недостатком является плохая масштабируемость: операционной системе придётся осуществлять множество и . Они являются дорогими операциями и могут привести к недостатку свободной ОЗУ при внушительном числе соединений.
Модифицированная версия выделяет (thread pool), тем самым не позволяя системе аварийно прекратить исполнение, но вместе с тем привносит новую проблему: если в данный момент времени пул потоков блокируют продолжительные операции чтения, то другие сокеты, которые уже в состоянии принять данные, не смогут этого сделать.
Второй подход использует (системный селектор), которую предоставляет ОС. В данной статье рассмотрен наиболее часто встречающийся вид системного селектора, основанный на оповещениях (событиях, уведомлениях) о готовности к I/O операциям, нежели на . Упрощённый пример его использования можно представить следующей блок-схемой:
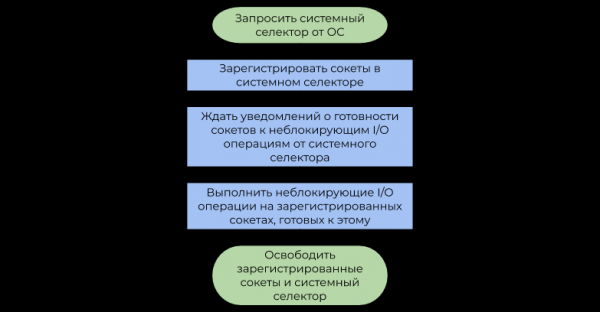
Разница между данными подходами заключается в следующем:
- Блокирующие I/O операции приостанавливают пользовательский поток до тех пор, пока ОС должным образом не поступающие в поток байт (, получение данных) или не освободится достаточно места во внутренних буферах записи для последующей отправки через (отправка данных).
- Системный селектор через некоторое время уведомляет программу о том, что ОС уже дефрагментировала IP пакеты (TCP, получение данных) или достаточно места во внутренних буферах записи уже доступно (отправка данных).
Подводя итог, резервирование потока ОС для каждого I/O — пустая трата вычислительной мощи, ведь на самом деле, потоки не заняты полезной работой (отсюда берёт свои корни термин ). Системный селектор решает эту проблему, позволяя пользовательской программе расходовать ресурсы ЦПУ значительно экономнее.
Модель I/O реактора
I/O реактор выступает как прослойка между системным селектором и пользовательским кодом. Принцип его работы описан следующей блок-схемой:
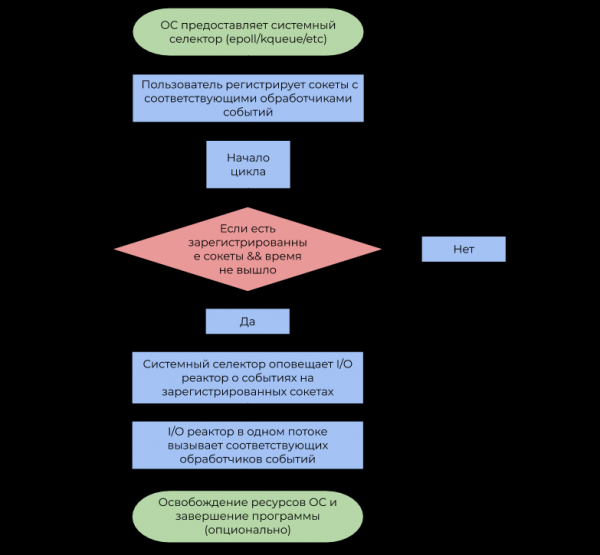
- Напомню, что событие — это уведомление о том, что определённый сокет в состоянии выполнить неблокирующую I/O операцию.
- Обработчик событий — это функция, вызываемая I/O реактором при получении события, которая далее совершает неблокирующую I/O операцию.
Важно отметить, что I/O реактор по определению однопоточен, но ничего не мешает использовать концепт в многопточной среде в отношении 1 поток: 1 реактор, тем самым утилизируя все ядра ЦПУ.
Реализация
Публичный интерфейс мы поместим в файл , а реализацию — в . reactor.h будет состоять из следующих объявлений:
Показать объявления в reactor.h
typedef struct reactor Reactor;
/*
* Указатель на функцию, которая будет вызываться I/O реактором при поступлении
* события от системного селектора.
*/
typedef void (*Callback)(void *arg, int fd, uint32_t events);
/*
* Возвращает `NULL` в случае ошибки, не-`NULL` указатель на `Reactor` в
* противном случае.
*/
Reactor *reactor_new(void);
/*
* Освобождает системный селектор, все зарегистрированные сокеты в данный момент
* времени и сам I/O реактор.
*
* Следующие функции возвращают -1 в случае ошибки, 0 в случае успеха.
*/
int reactor_destroy(Reactor *reactor);
int reactor_register(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg);
int reactor_deregister(const Reactor *reactor, int fd);
int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg);
/*
* Запускает цикл событий с тайм-аутом `timeout`.
*
* Эта функция передаст управление вызывающему коду если отведённое время вышло
* или/и при отсутствии зарегистрированных сокетов.
*/
int reactor_run(const Reactor *reactor, time_t timeout);Структура I/O реактора состоит из селектора и , которая каждый сокет сопоставляет с CallbackData (структура из обработчика события и аргумента пользователя для него).
Показать Reactor и CallbackData
struct reactor {
int epoll_fd;
GHashTable *table; // (int, CallbackData)
};
typedef struct {
Callback callback;
void *arg;
} CallbackData;Обратите внимание, что мы задействовали возможность обращения с по указателю. В reactor.h мы объявляем структуру reactor, а в reactor.c её определяем, тем самым не позволяя пользователю явно изменять её поля. Это один из паттернов , лаконично вписывающийся в семантику Си.
Функции reactor_register, reactor_deregister и reactor_reregister обновляют список интересующих сокетов и соответствующих обработчиков событий в системном селекторе и в хеш-таблице.
Показать функции регистрации
#define REACTOR_CTL(reactor, op, fd, interest)
if (epoll_ctl(reactor->epoll_fd, op, fd,
&(struct epoll_event){.events = interest,
.data = {.fd = fd}}) == -1) {
perror("epoll_ctl");
return -1;
}
int reactor_register(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg) {
REACTOR_CTL(reactor, EPOLL_CTL_ADD, fd, interest)
g_hash_table_insert(reactor->table, int_in_heap(fd),
callback_data_new(callback, callback_arg));
return 0;
}
int reactor_deregister(const Reactor *reactor, int fd) {
REACTOR_CTL(reactor, EPOLL_CTL_DEL, fd, 0)
g_hash_table_remove(reactor->table, &fd);
return 0;
}
int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg) {
REACTOR_CTL(reactor, EPOLL_CTL_MOD, fd, interest)
g_hash_table_insert(reactor->table, int_in_heap(fd),
callback_data_new(callback, callback_arg));
return 0;
}После того, как I/O реактор перехватил событие с дескриптором fd, он вызывает соответствующего обработчика события, в который передаёт fd, сгенерированных событий и пользовательский указатель на void.
Показать функцию reactor_run()
int reactor_run(const Reactor *reactor, time_t timeout) {
int result;
struct epoll_event *events;
if ((events = calloc(MAX_EVENTS, sizeof(*events))) == NULL)
abort();
time_t start = time(NULL);
while (true) {
time_t passed = time(NULL) - start;
int nfds =
epoll_wait(reactor->epoll_fd, events, MAX_EVENTS, timeout - passed);
switch (nfds) {
// Ошибка
case -1:
perror("epoll_wait");
result = -1;
goto cleanup;
// Время вышло
case 0:
result = 0;
goto cleanup;
// Успешная операция
default:
// Вызвать обработчиков событий
for (int i = 0; i < nfds; i++) {
int fd = events[i].data.fd;
CallbackData *callback =
g_hash_table_lookup(reactor->table, &fd);
callback->callback(callback->arg, fd, events[i].events);
}
}
}
cleanup:
free(events);
return result;
}Подводя итог, цепочка вызовов функций в пользовательском коде будет принимать следующий вид:
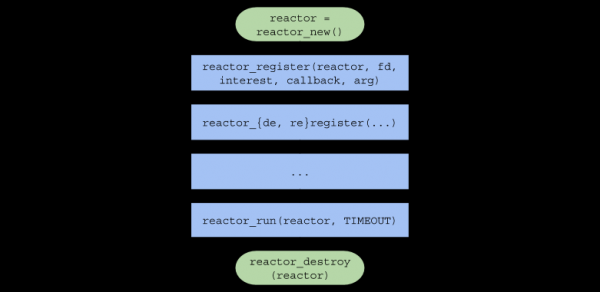
Однопоточный сервер
Для того чтобы протестировать I/O реактор на высокой нагрузке, мы напишем простой HTTP веб-сервер, на любой запрос отвечающий изображением.
Краткая справка по протолу HTTP
— это протокол , преимущественно использующийся для взаимодействия сервера с браузером.
HTTP можно с лёгкостью использовать поверх протокола , отправляя и принимая сообщения формата, определённого .
Формат запроса
<КОМАНДА> <URI> <ВЕРСИЯ HTTP>CRLF
<ЗАГОЛОВОК 1>CRLF
<ЗАГОЛОВОК 2>CRLF
<ЗАГОЛОВОК N>CRLF CRLF
<ДАННЫЕ>CRLF— это последовательность из двух символов:rиn, разделяющая первую строку запроса, заголовки и данные.<КОМАНДА>— одно изCONNECT,DELETE,GET,HEAD,OPTIONS,PATCH,POST,PUT,TRACE. Браузер нашему серверу будет отправлять командуGET, означающую «Отправь мне содержимое файла».<URI>— . Например, если URI =/index.html, то клиент запрашивает главную страницу сайта.<ВЕРСИЯ HTTP>— версия протокола HTTP в форматеHTTP/X.Y. Наиболее часто используемая версия на сегодняшний день —HTTP/1.1.<ЗАГОЛОВОК N>— это пара ключ-значение в формате<КЛЮЧ>: <ЗНАЧЕНИЕ>, отправляемая серверу для дальнейшего анализа.<ДАННЫЕ>— данные, требуемые серверу для выполнения операции. Часто это просто или любой другой формат.
Формат ответа
<ВЕРСИЯ HTTP> <КОД СТАТУСА> <ОПИСАНИЕ СТАТУСА>CRLF
<ЗАГОЛОВОК 1>CRLF
<ЗАГОЛОВОК 2>CRLF
<ЗАГОЛОВОК N>CRLF CRLF
<ДАННЫЕ><КОД СТАТУСА>— это число, представляющее собой результат операции. Наш сервер будет всегда возвращать статус 200 (успешная операция).<ОПИСАНИЕ СТАТУСА>— строковое представление кода статуса. Для кода статуса 200 — этоOK.<ЗАГОЛОВОК N>— заголовок того же формата, что и в запросе. Мы будем возвращать заголовкиContent-Length(размер файла) иContent-Type: text/html(тип возвращаемых данных).<ДАННЫЕ>— запрашиваемые пользователем данные. В нашем случае это путь к изображению в .
Файл (однопоточный сервер) включает файл , который содержит следующие прототипы функций:
Показать прототипы функций в common.h
/*
* Обработчик событий, который вызовется после того, как сокет будет
* готов принять новое соединение.
*/
static void on_accept(void *arg, int fd, uint32_t events);
/*
* Обработчик событий, который вызовется после того, как сокет будет
* готов отправить HTTP ответ.
*/
static void on_send(void *arg, int fd, uint32_t events);
/*
* Обработчик событий, который вызовется после того, как сокет будет
* готов принять часть HTTP запроса.
*/
static void on_recv(void *arg, int fd, uint32_t events);
/*
* Переводит входящее соединение в неблокирующий режим.
*/
static void set_nonblocking(int fd);
/*
* Печатает переданные аргументы в stderr и выходит из процесса с
* кодом `EXIT_FAILURE`.
*/
static noreturn void fail(const char *format, ...);
/*
* Возвращает файловый дескриптор сокета, способного принимать новые
* TCP соединения.
*/
static int new_server(bool reuse_port);Также описан функциональный макрос SAFE_CALL() и определена функция fail(). Макрос сравнивает значение выражения с ошибкой, и если условие выпонилось, вызывает функцию fail():
#define SAFE_CALL(call, error)
do {
if ((call) == error) {
fail("%s", #call);
}
} while (false)Функция fail() печатает переданные аргументы в терминал (как ) и завершает работу программы с кодом EXIT_FAILURE:
static noreturn void fail(const char *format, ...) {
va_list args;
va_start(args, format);
vfprintf(stderr, format, args);
va_end(args);
fprintf(stderr, ": %sn", strerror(errno));
exit(EXIT_FAILURE);
}Функция new_server() возвращает файловый дескриптор «серверного» сокета, созданного системными вызовами , и и способного принимать входящие соединения в неблокирующем режиме.
Показать функцию new_server()
static int new_server(bool reuse_port) {
int fd;
SAFE_CALL((fd = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, IPPROTO_TCP)),
-1);
if (reuse_port) {
SAFE_CALL(
setsockopt(fd, SOL_SOCKET, SO_REUSEPORT, &(int){1}, sizeof(int)),
-1);
}
struct sockaddr_in addr = {.sin_family = AF_INET,
.sin_port = htons(SERVER_PORT),
.sin_addr = {.s_addr = inet_addr(SERVER_IPV4)},
.sin_zero = {0}};
SAFE_CALL(bind(fd, (struct sockaddr *)&addr, sizeof(addr)), -1);
SAFE_CALL(listen(fd, SERVER_BACKLOG), -1);
return fd;
}- Обратите внимание, что сокет изначально создаётся в неблокирующем режиме с помощью флага
SOCK_NONBLOCK, чтобы в функцииon_accept()(читать дальше) системный вызовaccept()не остановил исполнение потока. - Если
reuse_portравенtrue, то данная функция сконфигурирует сокет с опцией посредством , чтобы использовать один и тот же порт в многопоточной среде (смотреть секцию «Многопоточный сервер»).
Обработчик событий on_accept() вызывается после того, как ОС сгенерирует событие EPOLLIN, в данном случае означающее, что новое соединение может быть принято. on_accept() принимает новое соединение, переключает его в неблокирующий режим и регистрирует с обработчиком события on_recv() в I/O реакторе.
Показать функцию on_accept()
static void on_accept(void *arg, int fd, uint32_t events) {
int incoming_conn;
SAFE_CALL((incoming_conn = accept(fd, NULL, NULL)), -1);
set_nonblocking(incoming_conn);
SAFE_CALL(reactor_register(reactor, incoming_conn, EPOLLIN, on_recv,
request_buffer_new()),
-1);
}Обработчик событий on_recv() вызывается после того, как ОС сгенерирует событие EPOLLIN, в данном случае означающее, что соединение, зарегистрированное on_accept(), готово к принятию данных.
on_recv() считывает данные из соединения до тех пор, пока HTTP запрос полностью не будет получен, затем она регистрирует обработчик on_send() для отправки HTTP ответа. Если клиент оборвал соединение, то сокет дерегистрируется и закрывается посредством .
Показать функцию on_recv()
static void on_recv(void *arg, int fd, uint32_t events) {
RequestBuffer *buffer = arg;
// Принимаем входные данные до тех пор, что recv возвратит 0 или ошибку
ssize_t nread;
while ((nread = recv(fd, buffer->data + buffer->size,
REQUEST_BUFFER_CAPACITY - buffer->size, 0)) > 0)
buffer->size += nread;
// Клиент оборвал соединение
if (nread == 0) {
SAFE_CALL(reactor_deregister(reactor, fd), -1);
SAFE_CALL(close(fd), -1);
request_buffer_destroy(buffer);
return;
}
// read вернул ошибку, отличную от ошибки, при которой вызов заблокирует
// поток
if (errno != EAGAIN && errno != EWOULDBLOCK) {
request_buffer_destroy(buffer);
fail("read");
}
// Получен полный HTTP запрос от клиента. Теперь регистрируем обработчика
// событий для отправки данных
if (request_buffer_is_complete(buffer)) {
request_buffer_clear(buffer);
SAFE_CALL(reactor_reregister(reactor, fd, EPOLLOUT, on_send, buffer),
-1);
}
}Обработчик событий on_send() вызывается после того, как ОС сгенерирует событие EPOLLOUT, означающее, что соединение, зарегистрированное on_recv(), готово к отправке данных. Эта функция отправляет HTTP ответ, содержащий HTML с изображением, клиенту, а затем меняет обработчик событий снова на on_recv().
Показать функцию on_send()
static void on_send(void *arg, int fd, uint32_t events) {
const char *content = "<img "
"src="https://habrastorage.org/webt/oh/wl/23/"
"ohwl23va3b-dioerobq_mbx4xaw.jpeg">";
char response[1024];
sprintf(response,
"HTTP/1.1 200 OK" CRLF "Content-Length: %zd" CRLF "Content-Type: "
"text/html" DOUBLE_CRLF "%s",
strlen(content), content);
SAFE_CALL(send(fd, response, strlen(response), 0), -1);
SAFE_CALL(reactor_reregister(reactor, fd, EPOLLIN, on_recv, arg), -1);
}И наконец, в файле http_server.c, в функции main() мы создаём I/O реактор посредством reactor_new(), создаём серверный сокет и регистрируем его, запускаем реактор с помощью reactor_run() ровно на одну минуту, а затем освобождаем ресурсы и выходим из программы.
Показать http_server.c
#include "reactor.h"
static Reactor *reactor;
#include "common.h"
int main(void) {
SAFE_CALL((reactor = reactor_new()), NULL);
SAFE_CALL(
reactor_register(reactor, new_server(false), EPOLLIN, on_accept, NULL),
-1);
SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1);
SAFE_CALL(reactor_destroy(reactor), -1);
}Проверим, что всё работает как положено. Компилируем (chmod a+x compile.sh && ./compile.sh в корне проекта) и запускаем самописный сервер, открываем в браузере и наблюдаем то, что и ожидали:
Замер производительности
Показать характеристики моей машины
$ screenfetch
MMMMMMMMMMMMMMMMMMMMMMMMMmds+. OS: Mint 19.1 tessa
MMm----::-://////////////oymNMd+` Kernel: x86_64 Linux 4.15.0-20-generic
MMd /++ -sNMd: Uptime: 2h 34m
MMNso/` dMM `.::-. .-::.` .hMN: Packages: 2217
ddddMMh dMM :hNMNMNhNMNMNh: `NMm Shell: bash 4.4.20
NMm dMM .NMN/-+MMM+-/NMN` dMM Resolution: 1920x1080
NMm dMM -MMm `MMM dMM. dMM DE: Cinnamon 4.0.10
NMm dMM -MMm `MMM dMM. dMM WM: Muffin
NMm dMM .mmd `mmm yMM. dMM WM Theme: Mint-Y-Dark (Mint-Y)
NMm dMM` ..` ... ydm. dMM GTK Theme: Mint-Y [GTK2/3]
hMM- +MMd/-------...-:sdds dMM Icon Theme: Mint-Y
-NMm- :hNMNNNmdddddddddy/` dMM Font: Noto Sans 9
-dMNs-``-::::-------.`` dMM CPU: Intel Core i7-6700 @ 8x 4GHz [52.0°C]
`/dMNmy+/:-------------:/yMMM GPU: NV136
./ydNMMMMMMMMMMMMMMMMMMMMM RAM: 2544MiB / 7926MiB
.MMMMMMMMMMMMMMMMMMMИзмерим производительность однопоточного сервера. Откроем два терминала: в одном запустим ./http_server, в другом — . Спустя минуту во втором терминале высветится следующая статистика:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive"
Running 1m test @ http://127.0.0.1:18470
8 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 493.52us 76.70us 17.31ms 89.57%
Req/Sec 24.37k 1.81k 29.34k 68.13%
11657769 requests in 1.00m, 1.60GB read
Requests/sec: 193974.70
Transfer/sec: 27.19MBНаш однопоточный сервер смог обработать свыше 11 миллионов запросов в минуту, исходящих из 100 соединений. Неплохой результат, но можно ли его улучшить?
Многопоточный сервер
Как было сказано выше, I/O реактор можно создавать в отдельных потоках, тем самым утилизируя все ядра ЦПУ. Применим данный подход на практике:
Показать http_server_multithreaded.c
#include "reactor.h"
static Reactor *reactor;
#pragma omp threadprivate(reactor)
#include "common.h"
int main(void) {
#pragma omp parallel
{
SAFE_CALL((reactor = reactor_new()), NULL);
SAFE_CALL(reactor_register(reactor, new_server(true), EPOLLIN,
on_accept, NULL),
-1);
SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1);
SAFE_CALL(reactor_destroy(reactor), -1);
}
}Теперь каждый поток реактором:
static Reactor *reactor;
#pragma omp threadprivate(reactor)Обратите внимание на то, что аргументом функции new_server() выступает true. Это значит, что мы присваиваем серверному сокету опцию , чтобы использовать его в многопоточной среде. Подробнее можете почитать .
Второй заход
Теперь измерим производительность многопоточного сервера:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive"
Running 1m test @ http://127.0.0.1:18470
8 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.14ms 2.53ms 40.73ms 89.98%
Req/Sec 79.98k 18.07k 154.64k 78.65%
38208400 requests in 1.00m, 5.23GB read
Requests/sec: 635876.41
Transfer/sec: 89.14MBКоличество обработанных запросов за 1 минуту возросло в ~3.28 раза! Но до круглого числа не хватило всего ~два миллиона, попробуем это исправить.
Сперва посмотрим на статистику, сгенерированную :
$ sudo perf stat -B -e task-clock,context-switches,cpu-migrations,page-faults,cycles,instructions,branches,branch-misses,cache-misses ./http_server_multithreaded
Performance counter stats for './http_server_multithreaded':
242446,314933 task-clock (msec) # 4,000 CPUs utilized
1 813 074 context-switches # 0,007 M/sec
4 689 cpu-migrations # 0,019 K/sec
254 page-faults # 0,001 K/sec
895 324 830 170 cycles # 3,693 GHz
621 378 066 808 instructions # 0,69 insn per cycle
119 926 709 370 branches # 494,653 M/sec
3 227 095 669 branch-misses # 2,69% of all branches
808 664 cache-misses
60,604330670 seconds time elapsed, компиляция с -march=native, , увеличение числа попаданий в , увеличение MAX_EVENTS и использование EPOLLET не дало значительного прироста в производительности. Но что получится, если увеличить количество одновременных соединений?
Статистика при 352 одновременных соединениях:
$ wrk -c352 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive"
Running 1m test @ http://127.0.0.1:18470
8 threads and 352 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 2.12ms 3.79ms 68.23ms 87.49%
Req/Sec 83.78k 12.69k 169.81k 83.59%
40006142 requests in 1.00m, 5.48GB read
Requests/sec: 665789.26
Transfer/sec: 93.34MBЖеланный результат получен, а вместе с ним и интересный график, демонстрирующий зависимость числа обработанных запросов за 1 минуту от количества соединений:
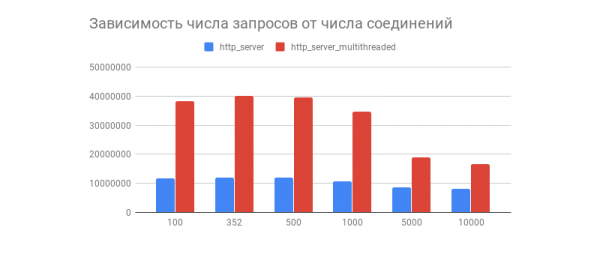
Видим, что после пары сотен соединений число обработанных запросов у обоих серверов резко падает (у многопоточного варианта это более заметно). Связано ли это с реализацией TCP/IP стека Linux? Свои предположения насчёт такого поведения графика и оптимизаций многопоточного и однопоточного вариантов смело пишите в комментариях.
Как в комментариях, данный тест производительности не показывает поведения I/O реактора на реальных нагрузках, ведь почти всегда сервер взаимодействует с БД, выводит логи, использует криптографию с и т.д., вследствие чего нагрузка становится неоднородной (динамической). Тесты вместе со сторонними компонентами будут проведены в статье про I/O проактор.
Недостатки I/O реактора
Нужно понимать, что I/O реактор не лишён недостатков, а именно:
- Пользоваться I/O реактором в многопоточной среде несколько сложнее, т.к. придётся вручную управлять потоками.
- Практика показывает, что в большинстве случаев нагрузка неоднородна, что может привести к тому, что один поток будет проставивать, пока другой будет загружен работой.
- Если один обработчик события заблокирует поток, то также заблокируется и сам системный селектор, что может привести к трудноотлавливаемым багам.
Эти проблемы решает , зачастую имеющий планировщик, который равномерно распределяет нагрузку в пул потоков, и к тому же имеющий более удобный API. Речь о нём пойдёт позже, в моей другой статье.
Заключение
На этом наше путешествие из теории прямиком в выхлоп профайлера подошло к концу.
Не стоит на этом останавливаться, ведь существуют множество других не менее интересных подходов к написанию сетевого ПО с разным уровнем удобства и скорости. Интересные, на мой взгляд, ссылки приведены ниже.
До новых встреч!
Интересные проекты
- Си
Что ещё почитать?
Источник: habr.com
