

Предлагаю ознакомиться с расшифровкой доклада начала 2016 года Владимира Ситникова "PostgreSQL и JDBC выжимаем все соки"


Добрый день! Меня зовут Владимир Ситников. Я работаю 10 лет в компании NetCracker. И в основном я занимаюсь производительностью. Все, что связано с Java, все, что связано с SQL – это то, что я люблю.
И сегодня я расскажу о том, с чем мы столкнулись в компании, когда начали использовать PostgreSQL в качестве сервера баз данных. И мы в основном работаем с Java. Но то, что я сегодня расскажу, связано не только с Java. Как практика показала, это возникает и в других языках.

Мы будем говорить:
- про выборку данных.
- Про сохранение данных.
- А также про производительность.
- И про подводные грабли, которые там зарыты.

Давайте начнем с простого вопроса. Мы выбираем одну строку из таблицы по первичному ключу.

База находится на том же хосте. И все это хозяйство занимает 20 миллисекунд.

Вот эти 20 миллисекунд – это очень много. Если у вас таких 100 запросов, то вы тратите время в секунду на то, чтобы эти запросы прокрутить, т. е. в пустую тратим время.
Мы это не любим делать и смотрим, что нам предлагает база для этого. База предлагает нам два варианта выполнения запросов.

Первый вариант – это простой запрос. Чем он хорош? Тем, что мы его берем и посылаем, и ничего больше.

У базы есть еще и расширенный запрос, который более хитрый, но более функциональный. Можно отдельно посылать запрос на парсинг, выполнение, связывание переменных и т. д.
Super extended query – это то, что мы не будем покрывать в текущем докладе. Мы, может быть, что-то хотим от базы данных и есть такой список хотелок, который в каком-то виде сформирован, т. е. это то, что мы хотим, но невозможно сейчас и в ближайший год. Поэтому просто записали и будем ходить, трясти основных людей.

А то, что мы можем сделать, так – это simple query и extended query.
В чем особенность каждого подхода?
Простой запрос хорошо использовать для одноразового выполнения. Раз выполнили и забыли. И проблема в том, что он не поддерживает бинарный формат данных, т. е. для каких-то высокопроизводительных систем он не подходит.

Extended query – позволяет экономить время на парсинге. Это то, что мы сделали и начали использовать. Нам это крайне-крайне помогло. Там есть не только экономия на парсинге. Есть экономия на передаче данных. Передавать данные в бинарном формате намного эффективнее.

Перейдем к практике. Вот так выглядит типичное приложение. Это может быть Java и т. д.
Мы создали statement. Выполнили команду. Создали close. Где здесь ошибка? В чем проблема? Нет проблем. Так во всех книгах написано. Так надо писать. Если вы хотите максимальную производительность, пишите так.

Но практика показала, что это не работает. Почему? Потому что у нас есть метод «close». И когда мы так делаем, то с точки зрения базы данных получается – это как работа курильщика с базой данных. Мы сказали «PARSE EXECUTE DEALLOCATE».
Зачем эти лишние создания и выгрузка statements? Они никому не нужны. Но обычно в PreparedStatement так и получается, когда мы их закрываем, они закрывают все на базе данных. Это не то, что мы хотим.

Мы хотим, как здоровые люди, работать с базой. Один раз взяли и подготовили наш statement, потом его выполняем много раз. На самом деле много раз – это один раз за всю жизнь приложения запарсили. И на разных REST используем один и тот же statement id. Вот это наша цель.

Как нам этого достичь?

Очень просто – не надо закрывать statements. Пишем вот так: «prepare» «execute».


Если мы такое запустим, то понятно, что у нас где-то что-то переполнится. Если не понятно, то можно померить. Возьмем и напишем бенчмарк, в котором такой простой метод. Создаем statement. Запускаем на какой-то версии драйвера и получаем, что он довольно быстро валится с потерей всей памяти, которая у на сбыла.
Понятно, что такие ошибки легко исправляются. Я не буду про них говорить. Но я скажу, что в новой версии работает гораздо быстрее. Метод бестолковый, но тем не менее.

Как работать правильно? Что нам для этого надо делать?
В реальности приложения всегда закрывают statements. Во всех книжках пишут, чтобы закрывали, иначе память утечет.
И PostgreSQL не умеет кэшировать запросы. Надо, чтобы каждая сессия сама для себя создавала этот кэш.
И время тратить на парсинг мы тоже не хотим.

И как обычно у нас есть два варианта.
Первый вариант – мы берем и говорим, что давайте все завернем в PgSQL. Там есть кэш. Он все кэширует. Получится замечательно. Мы такое посмотрели. У нас 100500 запросов. Не работает. Мы не согласны – ручками в процедуры превращать запросы. Нет-нет.
У нас есть второй вариант – взять и самим запилить. Открываем исходники, начинаем пилить. Пилим-пилим. Оказалось, что не так это сложно сделать.

Появилось это в августе 2015 года. Сейчас уже более современная версия. И все здорово. Работает настолько хорошо, что мы ничего не меняем в приложении. И мы даже перестали думать в сторону PgSQL, т. е. нам этого вполне хватило, чтобы все накладные расходы снизить практически до нуля.
Соответственно Server-prepared statements активируется на 5-ом выполнении для того, чтобы не тратить память в базе данных на каждый одноразовый запрос.

Можно спросить – где цифры? Что вы получаете? И тут я цифры не дам, потому что у каждого запроса они свои.
У нас запросы были такие, что мы на OLTP-запросах тратили где-то 20 миллисекунд на парсинг. Там было 0,5 миллисекунды на выполнение, 20 миллисекунд на парсинг. Запрос – 10 КиБ текста, 170 строк плана. Это OLTP запрос. Он запрашивает 1, 5, 10 строк, иногда больше.
Но нам совершенно не хотелось тратить 20 миллисекунд. Мы в 0 свели. Все здорово.
Что вы отсюда можете вынести? Если у вас Java, то вы берете современную версию драйвера и радуетесь.
Если у вас какой-то другой язык, то вы подумайте – может быть вам это тоже надо? Потому что с точки зрения конечного языка, например, если PL 8 или у вас LibPQ, то вам не очевидно, что вы тратите время не на выполнение, на парсинг и это стоит проверить. Как? Все бесплатно.
За исключением того, что есть ошибки, какие-то особенности. И про них как раз сейчас будем говорить. Большая часть будет о промышленной археологии, о том, что мы нашли, на что натолкнулись.

Если запрос генерируется динамически. Такое бывает. Кто-то строки склеивает, получается SQL-запрос.
Чем он плох? Он плох тем, что каждый раз у нас в итоге получается разная строка.
И у этой разной строки нужно заново считать hashCode. Это действительно CPU задача – найти длинный текст запроса в даже имеющейся hash’е не так просто. Поэтому вывод простой – не генерируйте запросы. Храните их в какой-то одной переменной. И радуйтесь.

Следующая проблема. Типы данных важны. Бывают ORM, которые говорят, что не важно какой NULL, пусть будет какой-нибудь. Если Int, то мы говорим setInt. А если NULL, то пусть VARCHAR будет всегда. И какая разница в конце концов какой там NULL? База данных сама все поймет. И такая картинка не работает.
На практике базе данных совершенно не все равно. Если вы в первый раз сказали, что это у вас число, а второй раз сказали, что это VARCHAR, то невозможно переиспользовать Server-prepared statements. И в таком случае приходится заново пересоздавать наш statement.

Если вы выполняете один и тот же запрос, то следите за тем, чтобы типы данных в колонке у вас не путались. Нужно следить за NULL. Это частая ошибка, которая у нас была после того, как мы начали использовать PreparedStatements

Хорошо, включили. Взяли, может быть, драйвер. И производительность упала. Все стало плохо.
Как такое бывает? Баг это или фича? К сожалению, не удалось понять – баг это или фича. Но есть вполне простой сценарий воспроизведения этой проблемы. Она совершенно неожиданно подкараулила нас. И заключается в выборке буквально из одной таблицы. У нас, конечно, таких запросов было больше. Они, как правило, две-три таблицы включали, но есть вот такой сценарий воспроизведения. Берете на вашей базе любой версии и воспроизводите.

Смысл в том, что у нас две колонки, каждая из которых проиндексирована. В одной колонке по значению NULL лежит миллион строк. А во второй колонке лежит всего 20 строк. Когда мы выполняем без связных переменных, то все хорошо работает.
Если мы начнем выполнять со связанными переменными, т. е. мы выполняем знак «?» или «$1» для нашего запроса, то что мы в итоге получаем?
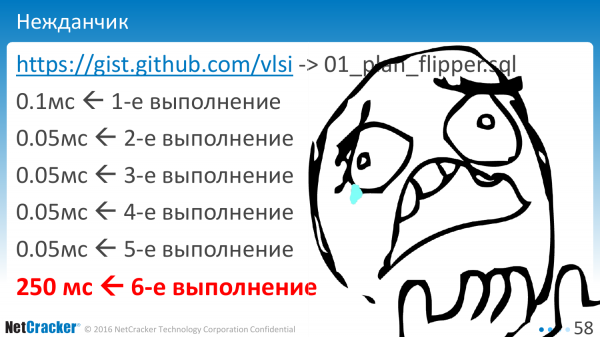
Первое выполнение – как положено. Второе – чуть побыстрее. Что-то прокэшировалось. Третье-четвертое-пятое. Потом хлоп – и как-то вот так. И самое плохое, что это происходит на шестом выполнении. Кто знал, что надо делать именно шесть выполнений для того, чтобы понять, какой там реально план выполнения?

Кто виноват? Что произошло? База данных содержит оптимизацию. И она как бы оптимизирована под generic случай. И, соответственно, начиная с какого-то раза она переходит на generic план, который, к сожалению, может оказаться, другим. Он может оказаться таким же, а может и другим. И там есть какое-то пороговое значение, которое приводит к такому поведению.
Что с этим можно делать? Здесь, конечно, более сложно что-то предполагать. Есть простое решение, которое мы используем. Это +0, OFFSET 0. Наверняка, вы такие решения знаете. Просто берем и в запрос добавляем «+0» и все хорошо. Покажу попозже.
И есть еще вариант – внимательнее планы смотреть. Разработчик должен не только запрос написать, но и 6 раз сказать «explain analyze». Если 5, то не подойдет.
И есть еще третий вариант – это написать в pgsql-hackers письмо. Я написал, правда, пока не понятно – баг это или фича.

Пока мы думаем – баг это или фича, давайте починим. Возьмем наш запрос и добавим «+0». Все хорошо. Два символа и даже не надо думать, как там и чего там. Очень просто. Мы просто базе данных запретили использовать индекс по этой колонке. Нет у нас индекса по колонке «+0» и все, база данных не использует индекс, все хорошо.

Вот это правило 6-и explain’ов. Сейчас в текущих версиях надо делать 6 раз, если у вас связанные переменные. Если у вас нет связанных переменных, то мы вот так делаем. И у нас в конце концов именно этот запрос падает. Дело не хитрое.
Казалось бы, сколько можно? Тут баг, там баг. Реально баг везде.

Давайте еще посмотрим. Например, у нас есть две схемы. Схема А с таблицей Ы и схема Б с таблицей Ы. Запрос – выбрать данные из таблицы. Что у нас при этом будет? У нас ошибка будет. У нас будет все выше перечисленное. Правило такое – баг везде, у нас будет все вышеперечисленное.

Теперь вопрос: «Почему?». Казалось бы, есть документация, что, если у нас есть схема, то есть переменная «search_path», которая говорит о том, где нужно искать таблицу. Казалось бы, переменная есть.
В чем проблема? Проблема в том, что server-prepared statements не подозревают, что search_path может кто-то менять. Вот это значение остается как бы константным для базы данных. И какие-то части могут не подхватить новые значения.

Конечно, это зависит от версии, на которой вы тестируете. Зависит от того, насколько серьезно у вас таблицы различаются. И версия 9.1 просто выполнит старые запросы. Новые версии могут обнаружить подвох и сказать, что у вас ошибка.

Как это лечить? Есть простой рецепт – не делайте так. Не надо менять search_path в работе приложения. Если вы меняете, то лучше создать новое соединение.
Можно пообсуждать, т. е. открыть, пообсуждать, дописать. Может быть, и убедим разработчиков базы данных, что в случае, когда кто-то меняет значение, база данных должна об этом клиенту говорить: «Смотрите, у вас тут значение обновилось. Может быть, вам надо statements сбросить, пересоздать?». Сейчас база данных скрытно себя ведет и не сообщает никак о том, что где-то внутри statements поменялись.
И я снова подчеркну – это то, что не типично для Java. Мы то же самое увидим в PL/ pgSQL один к одному. Но там воспроизведется.

Давайте попробуем еще выбрать данные. Выбираем-выбираем. У нас есть таблица в миллион строк. Каждая строка по килобайту. Примерно гигабайт данных. И у нас есть рабочая память в Java-машине в 128 мегабайт.
Мы, как рекомендовано во всех книгах, пользуемся потоковой обработкой. Т. е. мы открываем resultSet и читаем оттуда данные понемногу. Сработает ли это? Не упадет ли по памяти? Будет по чуть-чуть читать? Давайте поверим в базу, в Postgres поверим. Не верим. Упадем OutOFMemory? У кого падал OutOfMemory? А кто сумел починить после этого? Кто-то сумел починить.
Если у вас миллион строк, то нельзя просто так выбирать. Надо обязательно OFFSET/LIMIT. Кто за такой вариант? И кто за вариант, что надо autoCommit’ом играться?
Здесь, как обычно, самый неожиданный вариант оказывается правильным. И если вы вдруг выключите autoCommit, то оно поможет. Почему так? Науке об этом неизвестно.

Но по умолчанию все клиенты, соединяющиеся с базой данных Postgres, выбирают данные целиком. PgJDBC в этом плане не исключение, выбирает все строки.
Есть вариация на тему FetchSize, т. е. можно на уровне отдельного statement сказать, что здесь, пожалуйста, выбирай данные по 10, 50. Но это не работает до тех пор, пока вы не выключите autoCommit. Выключили autoCommit – начинает работать.
Но ходить по коду и везде ставить setFetchSize – это неудобно. Поэтому мы сделали такую настройку, которая для всего соединения будет говорить значение по умолчанию.
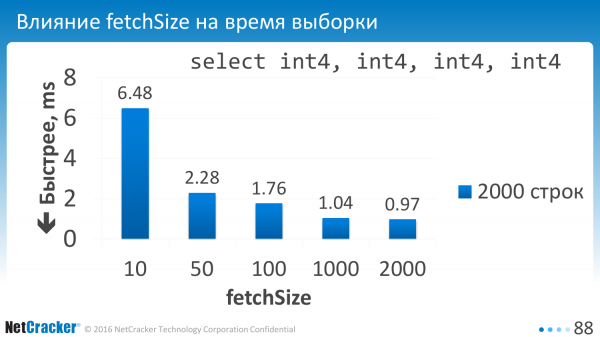
Вот мы это сказали. Настроили параметр. И что у нас получилось? Если мы выбираем по малому, если, например, по 10 строк выбираем, то у нас весьма большие накладные расходы. Поэтому надо это значение ставить порядка сотни.
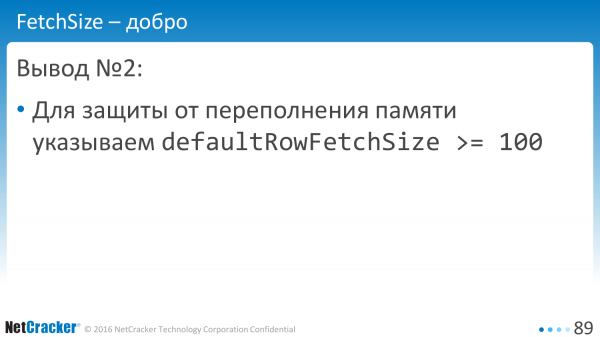
В идеале, конечно, в байтах еще научиться ограничивать, но рецепт такой: ставим defaultRowFetchSize больше ста и радуемся.

Давайте перейдем к вставке данных. Вставка – проще, там есть разные варианты. Например, INSERT, VALUES. Это хороший вариант. Можно говорить «INSERT SELECT». На практике это одно и то же. Никакого различия нет по производительности.
Книги говорят, что надо выполнять Batch statement, книги говорят, что можно выполнять более сложные команды с несколькими скобочками. И в Postgres есть замечательная функция – можно COPY делать, т. е. делать это быстрее.

Если померить, то можно снова несколько интересных открытий сделать. Как мы хотим, чтобы это работало? Хотим не парсить и лишних команд не выполнять.
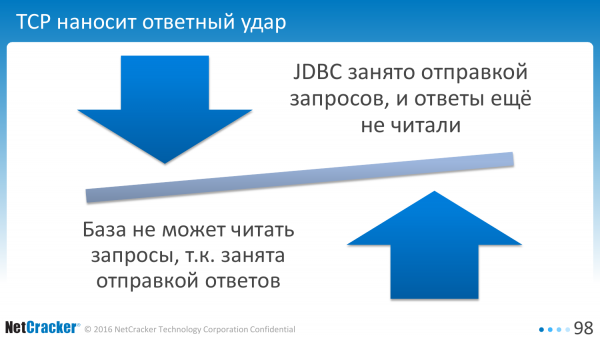
На практике TCP нам так делать не дает. Если клиент занят отправкой запроса, то база данных в попытках отправить нам ответы, запросы не читает. В итоге клиент ждет базу данных, пока она прочитает запрос, а база данных ждет клиента, пока он прочитает ответ.

И поэтому клиент вынужден отправлять периодически пакет синхронизации. Лишние сетевые взаимодействия, лишняя потеря времени.
 И чем больше мы их добавляем, тем хуже становится. Драйвер весьма пессимистичен и добавляет их довольно часто, примерно раз в 200 строк, в зависимости от размера строк и т. д.
И чем больше мы их добавляем, тем хуже становится. Драйвер весьма пессимистичен и добавляет их довольно часто, примерно раз в 200 строк, в зависимости от размера строк и т. д.
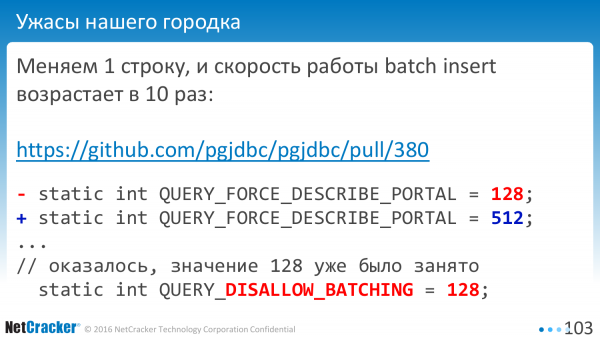
Бывает, что строчку поправишь одну всего и в 10 раз все ускорится. Такое бывает. Почему? Как обычно, константа где-то такая уже была использована. И значение «128» означало – не использовать batching.

Хорошо, что это не попало в официальную версию. Обнаружили до того, как начали выпускать релиз. Все значения, которые я называю, основываются на современных версиях.

Давайте померим. Мы мерим InsertBatch простой. Мы мерим InsertBatch многократный, т. е. тоже самое, но values много. Хитрый ход. Не все так умеют, но это такой простой ход, гораздо проще, чем COPY.

Можно делать COPY.

И можно это делать на структурах. Объявить User default type, передавать массив и INSERT напрямую в таблицу.
Если вы откроете ссылку: pgjdbc/ubenchmsrk/InsertBatch.java, то этот код есть на GitHub. Можно посмотреть конкретно, какие запросы там генерируются. Не суть важно.
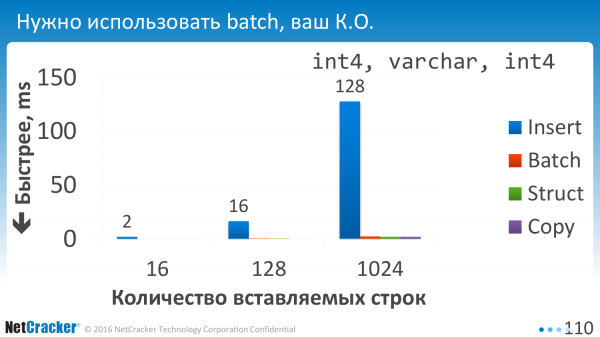
Мы запустили. И первое, что мы поняли, что не использовать batch – это просто нельзя. Все варианты batching равны нулю, т. е. время выполнения практически равно нулю по сравнению с однократным выполнением.
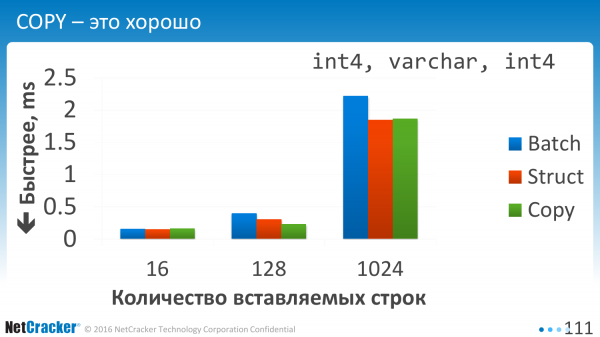
Мы вставляем данные. Весьма там простая таблица. Три колонки. И что мы здесь видим? Мы видим, что все эти три варианта примерно сравнимы. И COPY, конечно, лучше.
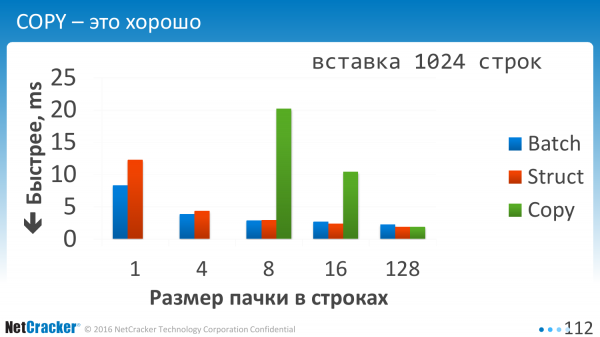
Это когда мы кусочками вставляем. Когда мы говорили, что одно значение VALUES, два значение VALUES, три значение VALUES или мы их там 10 через запятую указали. Это как раз сейчас по горизонтали. 1, 2, 4, 128. Видно, что Batch Insert, который синеньким нарисован, ему от этого сильно легчает. Т. е. когда вы вставляете по одному или даже когда вы вставляете по четыре, то становится в два раза лучше, просто от того, что мы в VALUES чуть побольше запихнули. Меньше операций EXECUTE.
Использовать COPY на маленьких объемах – это крайне неперспективно. Я на первых двух даже не нарисовал. Они в небеса идут, т. е. вот эти зеленькие цифры для COPY.
COPY надо использовать, когда у вас объем данных хотя бы больше ста строк. Накладные расходы на открытие этого соединения большие. И, честно скажу, в эту строну не копал. Batch я оптимизировал, COPY – нет.
Что мы делаем дальше? Померили. Понимаем, что надо использовать или структуры, или хитроумный bacth, объединяющий несколько значений.

Что нужно вынести из сегодняшнего доклада?
- PreparedStatement – это наше все. Это очень много дает для производительности. Оно дает большую бочку дегтя.
- И надо делать EXPLAIN ANALYZE 6 раз.
- И надо разбавлять OFFSET 0, и трюками типа +0 для того, чтобы править оставшийся там процент от наших проблемных запросов.
Источник: habr.com
