

Немалое число Enterprise приложений и систем виртуализации имеют собственные механизмы для построения отказоустойчивых решений. В частности, Oracle RAC (Oracle Real Application Cluster) представляет собой кластер из двух или более серверов баз данных Oracle, работающих совместно с целью балансировки нагрузки и обеспечения отказоустойчивости на уровне сервера/приложения. Для работы в таком режиме необходимо общее хранилище, в роли которого обычно выступает СХД.
Как мы уже рассматривали в одной из своих , сама по себе СХД, несмотря на наличие дублированных компонент (в том числе и контроллеров), все же имеет точки отказа – главным образом, в виде единого набора данных. Поэтому, для построения решения Oracle с повышенными требованиями к надежности, схему «N серверов – одна СХД» необходимо усложнить.

Сперва, конечно, нужно определиться, от каких рисков мы пытаемся застраховаться. В рамках данной статьи мы не будем рассматривать защиту от угроз типа «метеорит прилетел». Так что построение территориально разнесенного решения disaster recovery останется темой для одной из следующих статей. Здесь мы рассмотрим так называемое решение Cross-Rack disaster recovery, когда защита строится на уровне серверных шкафов. Сами шкафы могут находиться как в одном помещении, так и в разных, но обычно в пределах одного здания.
Эти шкафы должны содержать в себе весь необходимый набор оборудования и программного обеспечения, который позволит обеспечивать работу баз данных Oracle независимо от состояния «соседа». Другими словами, используя решение Cross-Rack disaster recovery, мы исключаем риски при отказе:
- Сервера приложения Oracle
- Системы хранения
- Систем коммутации
- Полный выход из строя всего оборудования в шкафу:
- Отказ по питанию
- Отказ системы охлаждения
- Внешние факторы (человек, природа и пр.)
Дублирование серверов Oracle подразумевает под собой сам принцип работы Oracle RAC и реализуется посредством приложения. Дублирование средств коммутации тоже не представляет собой проблему. А вот с дублированием системы хранения все не так просто.
Самый простой вариант – это репликация данных с основной СХД на резервную. Синхронная или асинхронная, в зависимости от возможностей СХД. При асинхронной репликации сразу встает вопрос об обеспечении консистентности данных по отношению к Oracle. Но даже если имеется программная интеграция с приложением, в любом случае, при аварии на основной СХД, потребуется вмешательство администраторов в ручном режиме для того, чтобы переключить кластер на резервное хранилище.
Более сложный вариант – это программные и/или аппаратные «виртуализаторы» СХД, которые избавят от проблем с консистентностью и ручного вмешательства. Но сложность развертывания и последующего администрирования, а также весьма неприличная стоимость таких решений отпугивает многих.
Как раз для таких сценариев, как Cross-Rack disaster recovery отлично подходит решение All Flash массив AccelStor NeoSapphire™ с использованием архитектуры Shared-Nothing. Данная модель представляет собой двухнодовую систему хранения, использующую собственную технологию FlexiRemap® для работы с флэш накопителями. Благодаря NeoSapphire™ H710 способна обеспечивать производительность до 600K IOPS@4K random write и 1M+ IOPS@4K random read, что недостижимо при использовании классических RAID-based СХД.
Но главная особенность NeoSapphire™ H710 – это исполнение двух нод в виде отдельных корпусов, каждая из которых имеет собственную копию данных. Синхронизация нод осуществляется через внешний интерфейс InfiniBand. Благодаря такой архитектуре можно разнести ноды по разным локациям на расстояние до 100м, обеспечив тем самым решение Cross-Rack disaster recovery. Обе ноды работают полностью в синхронном режиме. Со стороны хостов H710 выглядит как обыкновенная двухконтроллерная СХД. Поэтому никаких дополнительных программных и аппаратных опций и особо сложных настроек выполнять не нужно.
Если сравнить все вышеописанные решения Cross-Rack disaster recovery, то вариант от AccelStor заметно выделяется на фоне остальных:
AccelStor NeoSapphire™ Shared Nothing Architecture
Программный или аппаратный «виртуализатор» СХД
Решение на базе репликации
Доступность
Отказ сервера
No Downtime
No Downtime
No Downtime
Отказ коммутатора
No Downtime
No Downtime
No Downtime
Отказ системы хранения
No Downtime
No Downtime
Downtime
Отказ всего шкафа
No Downtime
No Downtime
Downtime
Стоимость и сложность
Стоимость решения
Низкая*
Высокая
Высокая
Сложность развертывания
Низкая
Высокая
Высокая
*AccelStor NeoSapphire™ – это все же All Flash массив, который по определению стоит не «3 копейки», тем более имея двукратный запас по емкости. Однако сравнивая итоговую стоимость решения на его базе с аналогичными от других вендоров, стоимость можно считать низкой.
Топология подключения серверов приложений и нод All Flash массива будет выглядеть следующим образом:
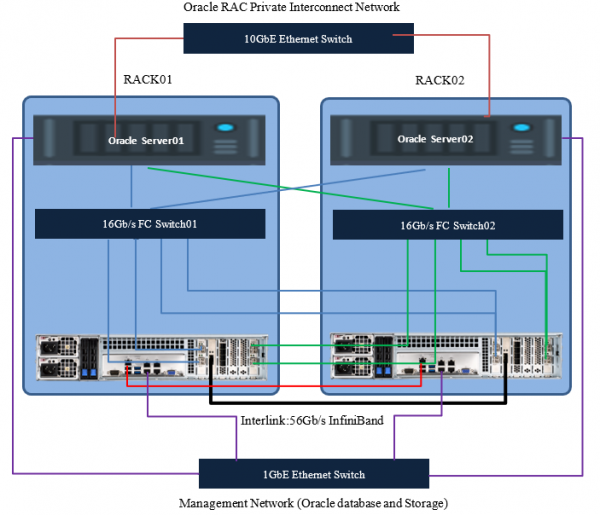
При планировании топологии также крайне рекомендуется сделать дублирование коммутаторов управления и интерконнекта серверов.
Здесь и далее речь будет идти о подключении через Fibre Channel. В случае использования iSCSI будет все то же самое, с поправкой на используемые типы коммутаторов и немного другие настройки массива.
Подготовительная работа на массиве
Используемое оборудование и программное обеспечение
Спецификации серверов и коммутаторов
Компоненты
Описание
Oracle Database 11g servers
Два
Server operating system
Oracle Linux
Oracle database version
11g (RAC)
Processors per server
Два 16 cores Intel® Xeon® CPU E5-2667 v2 @ 3.30GHz
Physical memory per server
128GB
FC network
16Gb/s FC with multipathing
FC HBA
Emulex Lpe-16002B
Dedicated public 1GbE ports for cluster management
Intel ethernet adapter RJ45
16Gb/s FC switch
Brocade 6505
Dedicated private 10GbE ports for data synchonization
Intel X520
Спецификация AccelStor NeoSapphhire™ All Flash массива
Компоненты
Описание
Storage system
NeoSapphire™ high availability model: H710
Image version
4.0.1
Total number of drives
48
Drive size
1.92TB
Drive type
SSD
FC target ports
16х 16Gb ports ( 8 на ноду)
Management ports
The 1GbE ethernet cable connecting to hosts via an ethernet switch
Heartbeat port
The 1GbE ethernet cable connecting between two storage node
Data synchronization port
56Gb/s InfiniBand cable
Перед началом использования массива его необходимо инициализировать. По умолчанию адрес управления обоих нод одинаковый (192.168.1.1). Нужно поочередно подключиться к ним и задать новые (уже разные) адреса управления и настроить синхронизацию времени, после чего Management порты можно подключить в единую сеть. После производится объединение нод в HA пару путем назначения подсетей для Interlink соединений.
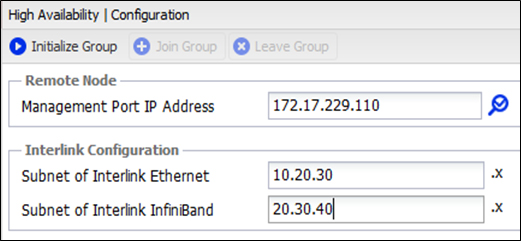
После завершения инициализации управлять массивом можно с любой ноды.
Далее создаем необходимые тома и публикуем их для серверов приложений.
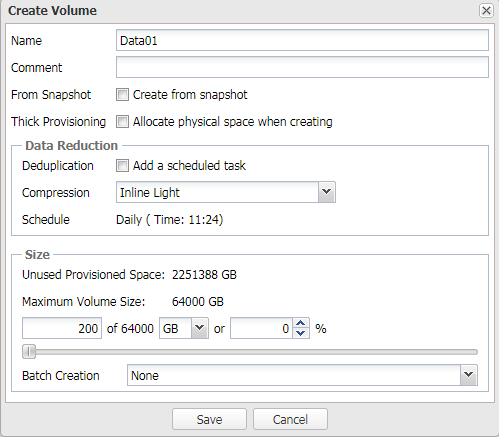
Крайне рекомендуется создать несколько томов для Oracle ASM, поскольку это увеличит количество target для серверов, что в итоге улучшит общую производительность (подробнее об очередях в другой ).
Тестовая конфигурация
Storage Volume Name
Volume Size
Data01
200GB
Data02
200GB
Data03
200GB
Data04
200GB
Data05
200GB
Data06
200GB
Data07
200GB
Data08
200GB
Data09
200GB
Data10
200GB
Grid01
1GB
Grid02
1GB
Grid03
1GB
Grid04
1GB
Grid05
1GB
Grid06
1GB
Redo01
100GB
Redo02
100GB
Redo03
100GB
Redo04
100GB
Redo05
100GB
Redo06
100GB
Redo07
100GB
Redo08
100GB
Redo09
100GB
Redo10
100GB
Некоторые пояснения по поводу режимов работы массива и происходящих процессах при нештатных ситуациях
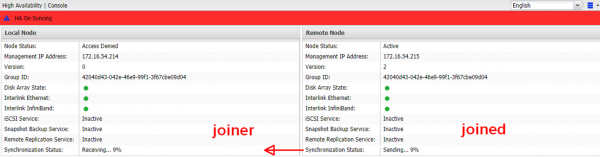
У набора данных каждой ноды имеется параметр «номер версии». После первичной инициализации он одинаков и равен 1. Если по каким-либо причинам номер версии различен, то всегда происходит синхронизация данных от старшей версии к младшей, после чего у младшей версии номер выравнивается, т.е. это означает, что копии идентичны. Причины, по которым версии могут быть различны:
- Запланированная перезагрузка одной из нод
- Авария на одной из нод из-за внезапного отключения (питание, перегрев и пр.).
- Обрыв InfiniBand соединения с невозможностью синхронизации
- Авария на одной из нод из-за повреждения данных. Здесь уже потребуется создание новой HA группы и полная синхронизация набора данных.
В любом случае нода, остающаяся в online, увеличивает свой номер версии на единицу, чтобы после восстановления связи с парой синхронизировать ее набор данных.
Если происходит обрыв соединения по Ethernet линку, то Heartbeat временно переключается на InfiniBand и возвращается обратно в течение 10с при его восстановлении.
Настройка хостов
Для обеспечения отказоустойчивости и увеличения производительности необходимо включить поддержку MPIO для массива. Для этого нужно добавить в файл /etc/multipath.conf строки, после чего перезагрузить сервис multipath
Скрытый текстdevices {
device {
vendor «AStor»
path_grouping_policy «group_by_prio»
path_selector «queue-length 0»
path_checker «tur»
features «0»
hardware_handler «0»
prio «const»
failback immediate
fast_io_fail_tmo 5
dev_loss_tmo 60
user_friendly_names yes
detect_prio yes
rr_min_io_rq 1
no_path_retry 0
}
}
Далее, для того, чтобы ASM работал с MPIO через ASMLib, необходимо изменить файл /etc/sysconfig/oracleasm и затем выполнить /etc/init.d/oracleasm scandisks
Скрытый текст
# ORACLEASM_SCANORDER: Matching patterns to order disk scanning
ORACLEASM_SCANORDER=«dm»
# ORACLEASM_SCANEXCLUDE: Matching patterns to exclude disks from scan
ORACLEASM_SCANEXCLUDE=«sd»
Примечание
Если нет желания использовать ASMLib, можно использовать правила UDEV, которые являются основой для ASMLib.
Начиная с версии 12.1.0.2 Oracle Database опция доступна для установки как часть ПО ASMFD.
Обязательно следует убедиться, чтобы создаваемые диски для Oracle ASM были выровненными по отношению к размеру блока, с которым физически работает массив (4K). Иначе возможны проблемы с производительностью. Поэтому необходимо создавать тома с соответствующими параметрами:
parted /dev/mapper/device-name mklabel gpt mkpart primary 2048s 100% align-check optimal 1
Распределение баз данных по созданным томам для нашей тестовой конфигурации
Storage Volume Name
Volume Size
Volume LUNs mapping
ASM Volume Device Detail
Allocation Unit Size
Data01
200GB
Map all storage volumes to storage system all data ports
Redundancy: Normal
Name:DGDATA
Purpose:Data files
4MB
Data02
200GB
Data03
200GB
Data04
200GB
Data05
200GB
Data06
200GB
Data07
200GB
Data08
200GB
Data09
200GB
Data10
200GB
Grid01
1GB
Redundancy: Normal
Name: DGGRID1
Purpose:Grid: CRS and Voting
4MB
Grid02
1GB
Grid03
1GB
Grid04
1GB
Redundancy: Normal
Name: DGGRID2
Purpose:Grid: CRS and Voting
4MB
Grid05
1GB
Grid06
1GB
Redo01
100GB
Redundancy: Normal
Name: DGREDO1
Purpose: Redo log of thread 1
4MB
Redo02
100GB
Redo03
100GB
Redo04
100GB
Redo05
100GB
Redo06
100GB
Redundancy: Normal
Name: DGREDO2
Purpose: Redo log of thread 2
4MB
Redo07
100GB
Redo08
100GB
Redo09
100GB
Redo10
100GB
Настройки базы данных
- Block size = 8K
- Swap space = 16GB
- Disable AMM (Automatic Memory Management)
- Disable Transparent Huge Pages
Прочие настройки
# vi /etc/sysctl.conf
✓ fs.aio-max-nr = 1048576
✓ fs.file-max = 6815744
✓ kernel.shmmax 103079215104
✓ kernel.shmall 31457280
✓ kernel.shmmn 4096
✓ kernel.sem = 250 32000 100 128
✓ net.ipv4.ip_local_port_range = 9000 65500
✓ net.core.rmem_default = 262144
✓ net.core.rmem_max = 4194304
✓ net.core.wmem_default = 262144
✓ net.core.wmem_max = 1048586
✓ vm.swappiness=10
✓ vm.min_free_kbytes=524288 # don’t set this if you’re using Linux x86
✓ vm.vfs_cache_pressure=200
✓ vm.nr_hugepages = 57000
# vi /etc/security/limits.conf
✓ grid soft nproc 2047
✓ grid hard nproc 16384
✓ grid soft nofile 1024
✓ grid hard nofile 65536
✓ grid soft stack 10240
✓ grid hard stack 32768
✓ oracle soft nproc 2047
✓ oracle hard nproc 16384
✓ oracle soft nofile 1024
✓ oracle hard nofile 65536
✓ oracle soft stack 10240
✓ oracle hard stack 32768
✓ soft memlock 120795954
✓ hard memlock 120795954
sqlplus “/as sysdba”
alter system set processes=2000 scope=spfile;
alter system set open_cursors=2000 scope=spfile;
alter system set session_cached_cursors=300 scope=spfile;
alter system set db_files=8192 scope=spfile;
Тест на отказоустойчивость
В целях демонстрации использовался HammerDB для эмуляции OLTP нагрузки. Конфигурация HammerDB:
Number of Warehouses
256
Total Transactions per User
1000000000000
Virtual Users
256
В результате был получен показатель 2.1M TPM, что далеко от предела производительности массива , но является «потолком» для текущей аппаратной конфигурации серверов (прежде всего из-за процессоров) и их количества. Целью данного теста все же является демонстрация отказоустойчивости решения в целом, а не достижения максимумов производительности. Поэтому будем просто отталкиваться от этой цифры.
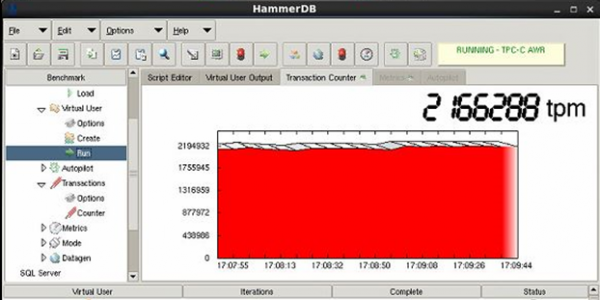
Тест на отказ одной из нод
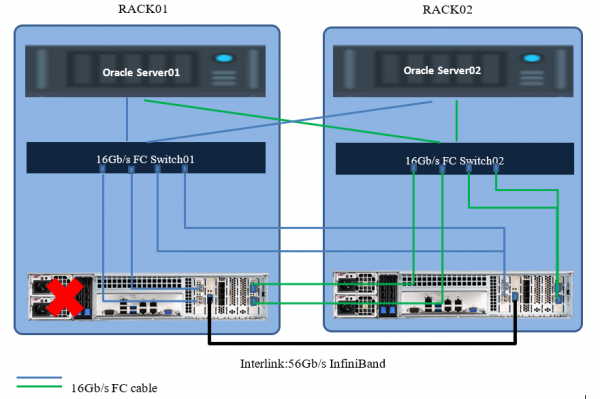
Хосты потеряли часть путей до хранилища, продолжив работать через оставшиеся со второй нодой. Производительность просела на несколько секунд из-за перестройки путей, а затем вернулась к нормальным показателям. Перерыва в обслуживании не произошло.
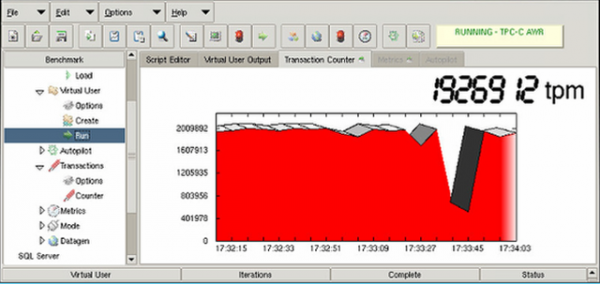
Тест на отказ шкафа со всем оборудованием
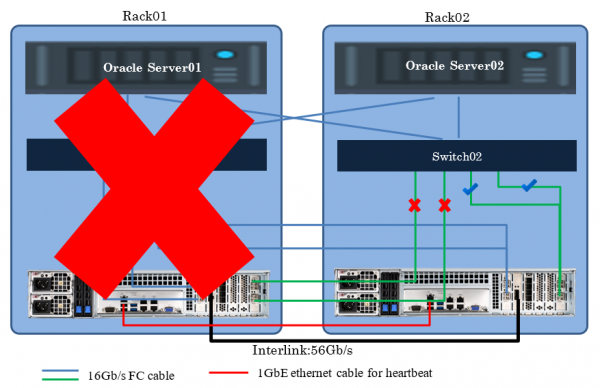
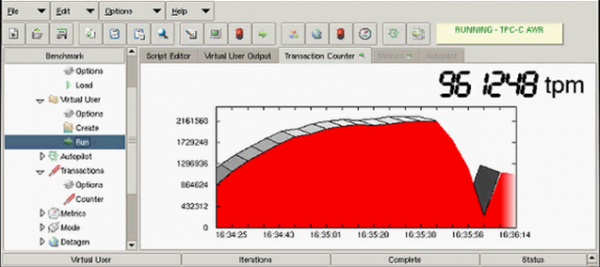
В этом случае производительность также просела на несколько секунд из-за перестройки путей, а затем вернулась к половинному значению от исходного показателя. Результат снизился вдвое от первоначального из-за исключения из работы одного сервера приложений. Перерыва в обслуживании также не произошло.
Если имеются потребности в реализации отказоустойчивого решения Cross-Rack disaster recovery для Oracle за разумную стоимость и с небольшими усилиями по развертыванию/администрированию, то совместная работа Oracle RAC и архитектуры будет одним из лучших вариантов. Вместо Oracle RAC может быть любое другое ПО, предусматривающее кластеризацию, те же СУБД или системы виртуализации, например. Принцип построения решения останется тем же. И итоговый показатель – это нулевое значение для RTO и RPO.
Источник: habr.com
