

Этот пост написан поскольку у наших сотрудников было довольно много разговоров с клиентами о разработке приложений на Kubernetes и о специфике такой разработки на OpenShift.

Начинаем мы обычно с тезиса, что Kubernetes – это просто Kubernetes, а OpenShift – это уже Kubernetes-платформа, как Microsoft AKS или Amazon EKS. У каждой из этих платформ есть свои плюсы, ориентированные на ту или иную целевую аудиторию. И после этого разговор уже перетекает в сравнение сильных и слабых сторон конкретных платформ.
В общем, мы думали написать этот пост с выводом типа «Слушайте, да без разницы, где запускать код, на OpenShift или на AKS, на EKS, на каком-то кастомном Kubernetes, да на каком-угодно-Kubernetes (для краткости назовем его КУК) – это реально просто, и там, и там».
Затем мы планировали взять простейший «Hello World» и на его примере показать, что общего и в чем различия между КУК и Red Hat OpenShift Container Platform (далее, OCP или просто OpenShift).
Однако по ходу написания этого поста, мы поняли, что так давно и сильно привыкли использовать OpenShift, что просто не осознаем, как он вырос и превратился в потрясающую платформу, которая стала гораздо больше, чем просто Kubernetes-дистрибутив. Мы привыкли воспринимать зрелость и простоту OpenShift как должное, упуская из виду его великолепие.
В общем, пришла пора деятельного раскаяния, и сейчас мы пошагово сравним ввод в строй своего «Hello World» на КУК и на OpenShift, и сделаем это максимально объективно (ну разве что выказывая иногда личное отношение к предмету). Если вам интересно сугубо субъективное мнение по этому вопросу, то его можно прочитать . А в этом посте мы будем придерживаться фактов и только фактов.
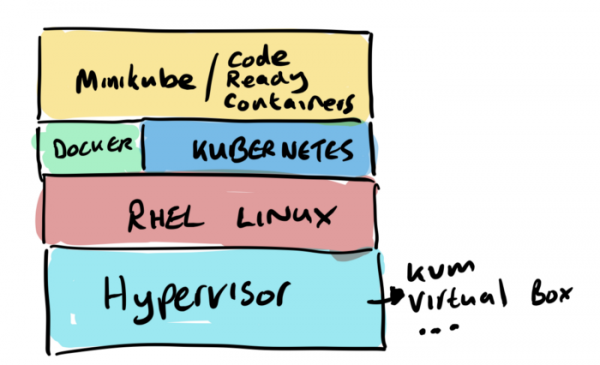
Кластеры
Итак, для нашего «Hello World» нужны кластеры. Сразу скажем «нет» всяким публичным облакам, чтобы не платить за сервера, реестры, сети, передачу данных и т.д. Соответственно, мы выбираем простой одноузловой кластер на (для КУК) и (для кластера OpenShift). Оба этих варианта реально просты в установке, но потребуют довольно много ресурсов на вашем ноуте.
Сборка на КУК-е
Итак, поехали.
Шаг 1 – собираем наш контейнерный образ
Начнем я с того, что развернем наш «Hello World» на minikube. Для этого потребуется:
- 1. Установленный Docker.
- 2. Установленный Git.
- 3. Установленный Maven (вообще-то в этом проекте используется mvnw-бинарник, так что можно обойтись и без этого).
- 4. Собственно, сам исходник, т.е. клон репозитория
Первым делом надо создать проект Quarkus. Не пугайтесь, если никогда не работали с сайтом Quarkus.io – это легко. Просто выбираете компоненты, которые хотите использовать в проекте (RestEasy, Hibernate, Amazon SQS, Camel и т.д.), а дальше Quarkus уже сам, без какого-либо вашего участия, настраивает архетип maven и выкладывает всё на github. То есть буквально один клик мышью – и готово. За это мы и любим Quarkus.
Самый простой способ собрать наш «Hello World» в контейнерный образ – использовать расширения quarkus-maven для Docker’а, которые и проделают всю необходимую работу. С появлением Quarkus это стало действительно легко и просто: добавляете расширение container-image-docker и можете создавать образы командами maven.
./mvnw quarkus:add-extension -Dextensions=”container-image-docker”
И, наконец, выполняем сборку нашего образа, используя Maven. В результате наш исходный код превращается в готовый контейнерный образ, который уже можно запускать в среде исполнения контейнеров.
./mvnw -X clean package -Dquarkus.container-image.build=true
Вот, собственно, и всё, теперь можно запускать контейнер командой docker run, подмапив наш сервис на порт 8080, чтобы к нему можно было обращаться.
docker run -i — rm -p 8080:8080 gcolman/quarkus-hello-world

После того, как контейнерный инстанс запустился, остается только проверить командой curl, что наш сервис работает:
![]()
Итак, всё работает, и это было действительно легко и просто.
Шаг 2 – отправляем наш контейнер в репозиторий контейнерных образов
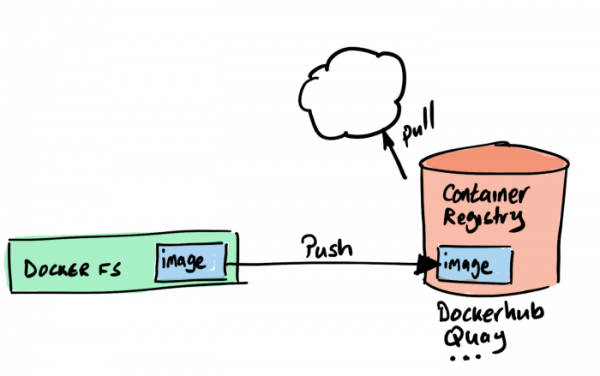
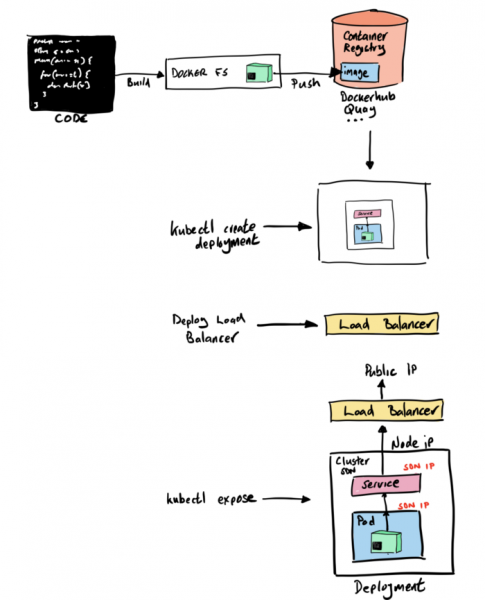
Пока что созданный нами образ хранится локально, в нашем локальном контейнерном хранилище. Если мы хотим использовать этот образ в своей среде КУК, то его надо положить в какой-то другой репозиторий. В Kubernetes нет таких функций, поэтому мы будем использовать dockerhub. Потому что, во-первых, он бесплатный, а во-вторых, (почти) все так делают.
Это тоже очень просто, и нужен здесь только аккаунт на dockerhub.
Итак, ставим dockerhub и отправляем туда наш образ.
Шаг 3 – запускаем Kubernetes
Есть много способов собрать конфигурацию kubernetes для запуска нашего «Hello World», но мы будем использовать наипростейший из них, уж такие мы люди…
Для начала запускаем кластер minikube:
minikube start
Шаг 4 – развертываем наш контейнерный образ
Теперь надо преобразовать наш код и контейнерный образ в конфигурации kubernetes. Иначе говоря, нам нужен pod и deployment definition с указанием на наш контейнерный образ на dockerhub. Один из самых простых способов это сделать – запустить команду create deployment, указав на наш образ:
kubectl create deployment hello-quarkus — image =gcolman/quarkus-hello-world:1.0.0-SNAPSHOT
Этой командной мы сказали нашей КУК создать deployment configuration, которая должна содержать спецификацию pod’а для нашего контейнерного образа. Эта команда также применит эту конфигурацию к нашему кластеру minikube, и создаст deployment, который скачает наш контейнерный образ и запустит pod в кластере.
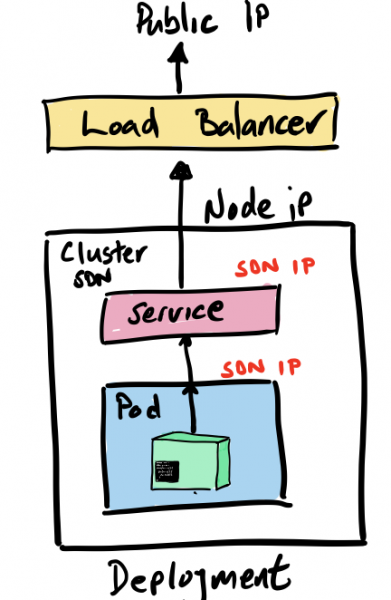
Шаг 5 – открываем доступ к нашему сервису
Теперь, когда у нас есть развернутый контейнерный образ, пора подумать, как сконфигурировать внешний доступ к этому Restful-сервису, который, собственно, и запрограммирован в нашем коде.
Тут есть много способов. Например, можно использовать команду expose, чтобы автоматически создавать соответствующие Kubernetes-компоненты, такие как services и endpoints. Собственно, так мы и сделаем, выполнив команду expose для нашего deployment-объекта:
kubectl expose deployment hello-quarkus — type=NodePort — port=8080
Давайте на минутку остановимся на опции « — type» команды expose.
Когда мы делаем expose и создаем компоненты, необходимые для запуска нашего сервиса, нам, среди прочего, надо, чтобы снаружи можно было подключиться к службе hello-quarkus, которая сидит внутри нашей программно-определяемой сети. И параметр type позволяет нам создать и подключить такие вещи, как балансировщики нагрузки, чтобы маршрутизировать трафик в эту сеть.
Например, прописав type=LoadBalancer, мы автоматически инициализируем балансировщик нагрузки в публичном облаке, чтобы подключаться к нашему кластеру Kubernetes. Это, конечно, замечательно, но надо понимать, что такая конфигурация будет жестко привязана к конкретному публичному облаку и ее будет сложнее переносить между Kubernetes-инстансам в разных средах.
В нашем примере type=NodePort, то есть обращение к нашему сервису идет по IP-адресу узла и номеру порта. Такой вариант позволяет не использовать никакие публичные облака, но требует ряд дополнительных шагов. Во-первых, нужен свой балансировщик нагрузки, поэтому мы развернем в своем кластере балансирощик нагрузки NGINX.
Шаг 6 – ставим балансировщик нагрузки
У minikube есть ряд платформенных функций, облегчающих создание необходимых для доступа извне компонентов, вроде ingress-контроллеров. Minikube идет в комплекте с ingress-контроллером Nginx, и нам остается только включить его и настроить.
minikube addons enable ingress
Теперь мы всего одной командой создам ingress-контроллер Nginx, который будет работать внутри нашего кластера minikube:
ingress-nginx-controller-69ccf5d9d8-j5gs9 1/1 Running 1 33m
Шаг 7 – Настраиваем ingress
Теперь нам надо настроить ingress-контроллер Nginx, чтобы он воспринимал запросы hello-quarkus.

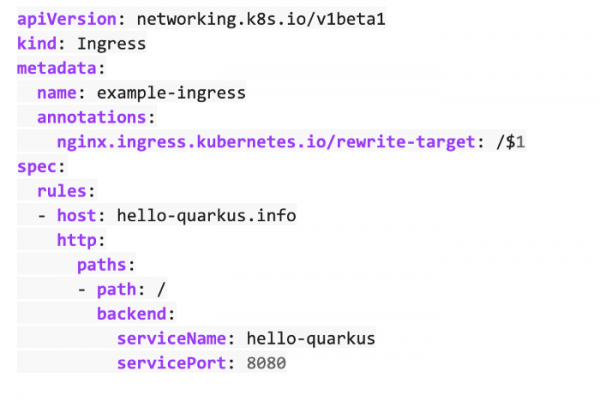
И, наконец, нам надо применить эту конфигурацию.
kubectl apply -f ingress.yml
![]()
Поскольку мы делаем все это на своем компе, то просто добавляем IP-адрес своей ноды в файл /etc/ hosts, чтобы направлять http-запросы к нашему minikube на балансировщик нагрузки NGINX.
192.168.99.100 hello-quarkus.info
Всё, теперь наш сервис minikube доступен снаружи через ingress-контроллер Nginx.
Ну что, это же было легко, да? Или не очень?
Запуск на OpenShift (Code Ready Containers)
А теперь посмотрим, как это все делается на Red Hat OpenShift Container Platform (OCP).
Как в случае с minikube, мы выбираем схему с одноузловым кластером OpenShift в форме Code Ready Containers (CRC). Раньше это называлось minishift и базировалось на проекте OpenShift Origin, а теперь это CRC и построено на Red Hat’овской OpenShift Container Platform.
Здесь мы, извините, не можем сдержаться и не сказать: «OpenShift прекрасен!»
Изначально мы думали написать, что разработка на OpenShift ничем не отличается от разработки на Kubernetes. И по сути так оно и есть. Но в процессе написания этого поста мы вспомнили, сколько лишних движений приходится совершать, когда у вас нет OpenShift, и поэтому он, повторимся, прекрасен. Мы любим, когда всё делается легко, и то, как легко по сравнению с minikube наш пример развертывается и запускается на OpenShift, собственно, и подвигло нас написать этот пост.
Давайте пробежимся по процессу и посмотрим, что нам потребуется сделать.
Итак, в примере с minikube мы начинали с Docker… Стоп, нам больше не надо, чтобы на машине был установлен Docker.
И локальный git нам не нужен.
И Maven не нужен.
И не надо руками создавать контейнерный образ.
И не надо искать какой-нибудь репозиторий контейнерных образов.
И не надо устанавливать ingress-контроллер.
И конфигурировать ingress тоже не надо.
Вы поняли, да? Чтобы развернуть и запустить наше приложение на OpenShift, не нужно ничего из вышеперечисленного. А сам процесс выглядит следующим образом.
Шаг 1 – Запускаем свой кластер OpenShift
Мы используем Code Ready Containers от Red Hat, который по сути есть тот же Minikube, но только с полноценным одноузловым кластером Openshift.
crc start
Шаг 2 – Выполняем сборку и развертывание приложения в кластере OpenShift
Именно на этом шаге простота и удобство OpenShift проявляются во всей красе. Как и во всех дистрибутивах Kubernetes, у нас есть много способов запустить приложение в кластере. И, как и в случае КУК, мы специально выбираем самый наипростейший.
OpenShift всегда строился как платформа для создания и запуска контейнерных приложений. Сборка контейнеров всегда была неотъемлемой частью этой платформы, поэтому здесь есть куча дополнительных Kubernetes-ресурсов для соответствующих задач.
Мы будем использовать OpenShift’овский процесс Source 2 Image (S2I), у которого есть несколько различных способов для того, чтобы взять наш исходник (код или двоичные файлы) и превратить его в контейнерный образ, запускаемый в кластере OpenShift.
Для этого нам понадобятся две вещи:
- Наш исходный код в репозитории git
- Builder-образ, на основании которого будет выполняться сборка.
Существует множество таких образов, сопровождаемых как силами Red Hat, так и на уровне сообщества, и мы воспользуемся образом OpenJDK, ну поскольку я же собираю Java-приложение.
Запустить S2I-сборку можно, как и из графической консоли OpenShift Developer, так и из командной строки. Мы воспользуемся командой new-app, указав ей, где брать builder-образ и наш исходный код.
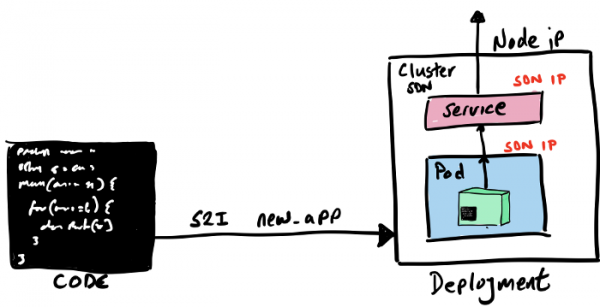
oc new-app registry.access.redhat.com/ubi8/openjdk-11:latest~https://github.com/gcolman/quarkus-hello-world.git
Всё, наше приложение создано. При этом процесс S2I выполнил следующие вещи:
- Создал служебный build-pod для всяких вещей, связанных со сборкой приложения.
- Создал конфиг OpenShift Build.
- Скачал builder-образ во внутренний docker-реестр OpenShift.
- Клонировал «Hello World» в локальный репозиторий.
- Увидел, что там есть maven pom, и поэтому скомпилировал приложение с помощью maven.
- Создал новый контейнерный образ, содержащий скомпилированное Java-приложение, и положил этот образ во внутренний реестр контейнеров.
- Создал Kubernetes Deployment со спецификациями pod’а, сервиса и т.д.
- Запустил deploy контейнерного образа.
- Удалил служебный build-pod.
В этом списке много всего, но главное, что вся сборка происходит исключительно внутри OpenShift, внутренний Docker-реестр находится внутри OpenShift, а процесс сборки создает все компоненты Kubernetes и запускает их в кластере.
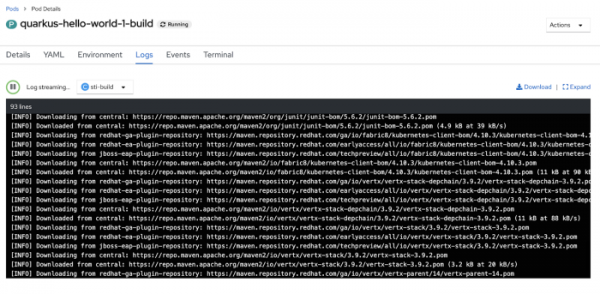
Если визуально отслеживать запуск S2I в консоли, то можно увидеть, как при выполнении сборки запускается build pod.

А теперь взглянем логи builder pod’а: во-первых, там видно, как maven делает свою работу и скачивает зависимости для сборки нашего java-приложения.
После того, как закончена maven-сборка, запускается сборка контейнерного образа, и затем этот собранный образ отправляется во внутренний репозиторий.
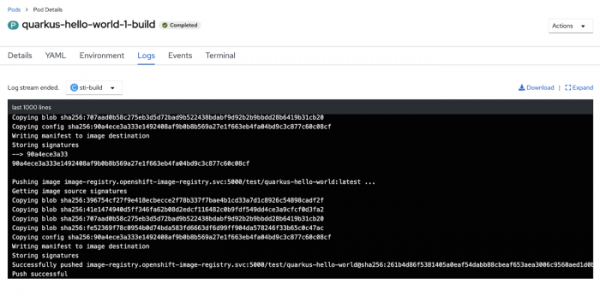
Всё, процесс сборки завершен. Теперь убедимся, что в кластере запустились pod’ы и сервисы нашего приложения.
oc get service
![]()
Вот и всё. И всего одна команда. Нам остается только сделать expose этого сервиса для доступа извне.
Шаг 3 – делаем expose сервиса для доступа извне
Как и в случае КУК, на платформе OpenShift нашему «Hello World» тоже нужен роутер, чтобы направлять внешний трафик на сервис внутри кластера. В OpenShift это делает очень просто. Во-первых, в кластере по умолчанию установлен компонент маршрутизации HAProxy (его можно поменять на тот же NGINX). Во-вторых, здесь есть специальные и допускающие широкие возможности настройки ресурсы, которые называются Routes и напоминают Ingress-объекты в старом добром Kubernetes (на самом деле OpenShift’овкие Routes сильно повлияли на дизайн Ingress-объектов, которые теперь можно использовать и в OpenShift), но для нашего «Hello World», да и почти во всех остальных случаях, нам хватит стандартного Route без дополнительной настройки.
Чтобы создать для «Hello World» маршрутизируемый FQDN (да, в OpenShiift есть свой DNS для маршрутизации по именам сервисов), мы просто выполним expose для нашего сервиса:
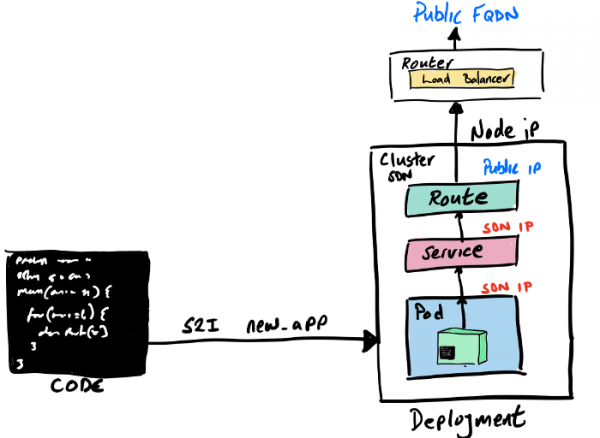
oc expose service quarkus-hello-world
Если посмотреть только что созданный Route, то там можно найти FQDN и другие сведения по маршрутизации:
oc get route
![]()
И наконец, обращаемся к нашему сервису из браузера:

А вот теперь это было действительно легко!
Мы любим Kubernetes и всё, что позволяет делать эта технология, а также мы любим простоту и легкость. Kubernetes создавался, чтобы невероятно упростить эксплуатацию распределенных масштабируемых контейнеров, но вот для ввода в строй приложений его простоты сегодня уже недостаточно. И здесь в игру вступает OpenShift, который идет в ногу со временем и предлагает Kubernetes, ориентированный в первую очередь на разработчика. Была вложена масса усилий, чтобы заточить платформу OpenShift именно под разработчика, включая создание таких инструментов, как S2I, ODI, Developer Portal, OpenShift Operator Framework, интеграция с IDE, Developer Catalogues, интеграция с Helm, мониторинг и многие другие.
Надеемся, что эта статься была для вас интересной и полезной. А найти дополнительные ресурсы, материалы и другие полезные для разработки на платформе OpenShift вещи можно на портале .
Источник: habr.com
