


В начале этого месяца, 3 мая, был анонсирован крупный релиз «системы управления для распределённых хранилищ данных в Kubernetes» — . Более года назад мы уже общий обзор Rook. Тогда же нас просили рассказать об опыте его использования на практике — и вот, как раз к столь значимой вехе в истории проекта, мы рады поделиться накопленными впечатлениями.
Если кратко, Rook представляет собой набор для Kubernetes, которые полностью берут под контроль развертывание, управление, автоматическое восстановление таких решений для хранения данных, как Ceph, EdgeFS, Minio, Cassandra, CockroachDB.
На данный момент самым развитым (и в стабильной стадии) решением является .
Примечание: среди значимых изменений в релизе Rook 1.0.0, связанных с Ceph, можно отметить поддержку Сeph Nautilus и возможность использовать NFS для CephFS- или RGW-бакетов. Из прочих выделяется «созревание» поддержки EdgeFS до уровня беты.
Итак, в этой статье мы:
- ответим на вопрос, какие плюсы видим в использовании Rook для развертывания Ceph в кластере Kubernetes;
- поделимся опытом и впечатлениями от использования Rook в production;
- расскажем, почему мы говорим Rook’у «Да!», и о своих планах на него.
Начнём с общих концепций и теории.
«У меня преимущество в одну Ладью!» (неизвестный шахматист)
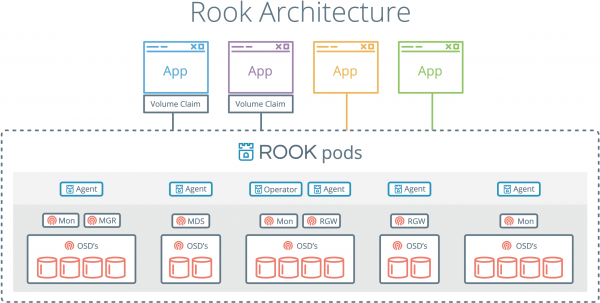
Одним из главных преимуществ Rook является то, что взаимодействие с хранилищами данных ведется через механизмы Kubernetes. Это означает, что больше не нужно копировать команды для настройки Ceph с листочка в консоль.
— Хочешь развернуть в кластере CephFS? Просто напиши YAML-файл!
— Что? Хочешь развернуть ещё и object store с S3 API? Просто напиши второй YAML-файл!
Rook создан по всем правилам типичного оператора. Взаимодействие с ним происходит при помощи , в которых мы описываем необходимые нам характеристики сущностей Ceph (поскольку это единственная стабильная реализация, по умолчанию в статье будет идти речь именно про Ceph, если явно не указано иное). Согласно заданным параметрам, оператор автоматически выполнит необходимые для настройки команды.
Конкретику давайте рассмотрим на примере создания Object Store, а точнее — CephObjectStoreUser.
apiVersion: ceph.rook.io/v1
kind: CephObjectStore
metadata:
name: {{ .Values.s3.crdName }}
namespace: kube-rook
spec:
metadataPool:
failureDomain: host
replicated:
size: 3
dataPool:
failureDomain: host
erasureCoded:
dataChunks: 2
codingChunks: 1
gateway:
type: s3
sslCertificateRef:
port: 80
securePort:
instances: 1
allNodes: false
---
apiVersion: ceph.rook.io/v1
kind: CephObjectStoreUser
metadata:
name: {{ .Values.s3.crdName }}
namespace: kube-rook
spec:
store: {{ .Values.s3.crdName }}
displayName: {{ .Values.s3.username }}Указанные в листинге параметры достаточно стандартны и вряд ли нуждаются в комментариях, однако стоит обратить особое внимание на те, что выделены в переменные шаблонов.
Общая схема работы сводится к тому, что через YAML-файл мы «заказываем» ресурсы, для чего оператор выполняет нужные команды и возвращает нам «не самый настоящий» секрет, с которым мы можем дальше работать (см. ниже). А из переменных, что указаны выше, будет составлена команда и имя секрета.
Что же это за команда? При создании пользователя для объектного хранилища Rook-оператор внутри pod’а выполнит следующее:
radosgw-admin user create --uid="rook-user" --display-name="{{ .Values.s3.username }}"Результатом выполнения этой команды станет JSON-структура:
{
"user_id": "rook-user",
"display_name": "{{ .Values.s3.username }}",
"keys": [
{
"user": "rook-user",
"access_key": "NRWGT19TWMYOB1YDBV1Y",
"secret_key": "gr1VEGIV7rxcP3xvXDFCo4UDwwl2YoNrmtRlIAty"
}
],
...
} Keys — то, что потребуется в будущем приложениям для доступа к объектному хранилищу через S3 API. Rook-оператор любезно выбирает их и складывает в свой namespace в виде секрета с именем rook-ceph-object-user-{{ $.Values.s3.crdName }}-{{ $.Values.s3.username }}.
Чтобы использовать данные из этого секрета, достаточно добавить их в контейнер в качестве переменных окружения. Как пример приведу шаблон для Job, в котором мы автоматически создаем bucket’ы для каждого пользовательского окружения:
{{- range $bucket := $.Values.s3.bucketNames }}
apiVersion: batch/v1
kind: Job
metadata:
name: create-{{ $bucket }}-bucket-job
annotations:
"helm.sh/hook": post-install
"helm.sh/hook-weight": "2"
spec:
template:
metadata:
name: create-{{ $bucket }}-bucket-job
spec:
restartPolicy: Never
initContainers:
- name: waitdns
image: alpine:3.6
command: ["/bin/sh", "-c", "while ! getent ahostsv4 rook-ceph-rgw-{{ $.Values.s3.crdName }}; do sleep 1; done" ]
- name: config
image: rook/ceph:v1.0.0
command: ["/bin/sh", "-c"]
args: ["s3cmd --configure --access_key=$(ACCESS-KEY) --secret_key=$(SECRET-KEY) -s --no-ssl --dump-config | tee /config/.s3cfg"]
volumeMounts:
- name: config
mountPath: /config
env:
- name: ACCESS-KEY
valueFrom:
secretKeyRef:
name: rook-ceph-object-user-{{ $.Values.s3.crdName }}-{{ $.Values.s3.username }}
key: AccessKey
- name: SECRET-KEY
valueFrom:
secretKeyRef:
name: rook-ceph-object-user-{{ $.Values.s3.crdName }}-{{ $.Values.s3.username }}
key: SecretKey
containers:
- name: create-bucket
image: rook/ceph:v1.0.0
command:
- "s3cmd"
- "mb"
- "--host=rook-ceph-rgw-{{ $.Values.s3.crdName }}"
- "--host-bucket= "
- "s3://{{ $bucket }}"
ports:
- name: s3-no-sll
containerPort: 80
volumeMounts:
- name: config
mountPath: /root
volumes:
- name: config
emptyDir: {}
---
{{- end }}Все действия, перечисленные в этом Job’е, были произведены, не выходя за рамки Kubernetes. Описанные в YAML-файлах структуры сложены в Git-репозиторий и многократно повторно использованы. В этом мы видим огромный плюс для DevOps-инженеров и процесса CI/CD в целом.
С Rook и Rados в радость
Использование связки Ceph + RBD накладывает определенные ограничения на монтирование томов к pod’ам.
В частности, в namespace обязательно должен лежать секрет для доступа к Ceph, чтобы stateful-приложения могли функционировать. Нормально, если у вас есть 2-3 окружения в своих пространствах имен: можно пойти и скопировать секрет вручную. Но что делать, если на каждую feature для разработчиков создается отдельное окружение со своим namespace?
У себя мы решили данную проблему при помощи , который автоматически копировал секреты в новые namespace (пример подобного хука описан в ).
#! /bin/bash
if [[ $1 == “--config” ]]; then
cat <<EOF
{"onKubernetesEvent":[
{"name": "OnNewNamespace",
"kind": "namespace",
"event": ["add"]
}
]}
EOF
else
NAMESPACE=$(kubectl get namespace -o json | jq '.items | max_by( .metadata.creationTimestamp ) | .metadata.name')
kubectl -n ${CEPH_SECRET_NAMESPACE} get secret ${CEPH_SECRET_NAME} -o json | jq ".metadata.namespace="${NAMESPACE}"" | kubectl apply -f -
fiОднако при использовании Rook данной проблемы попросту не существует. Процесс монтирования происходит при помощи собственных драйверов на базе или (пока в бета-стадии) и поэтому не требует секретов.
Rook автоматически решает многие проблемы, что и подталкивает нас использовать его в новых проектах.
Осада Rook
Завершим практическую часть разворачиванием Rook и Ceph для возможности проведения собственных экспериментов. Для того, чтобы брать штурмом эту неприступную башню было легче, разработчики подготовили Helm-пакет. Давайте скачаем его:
$ helm fetch rook-master/rook-ceph --untar --version 1.0.0 В файле rook-ceph/values.yaml можно найти множество различных настроек. Самое важное — указать tolerations для агентов и поиска. Для чего можно использовать механизм taints/tolerations, мы подробно рассказывали в .
Если вкратце, мы не хотим, чтобы pod’ы с клиентским приложением располагались на тех же узлах, где расположены диски для хранения данных. Причина проста: так работа агентов Rook не будет влиять на само приложение.
Итак, открываем файл rook-ceph/values.yaml любимым редактором и добавляем в конец следующий блок:
discover:
toleration: NoExecute
tolerationKey: node-role/storage
agent:
toleration: NoExecute
tolerationKey: node-role/storage
mountSecurityMode: AnyНа каждый узел, зарезервированный под хранение данных, добавляем соответствующий taint:
$ kubectl taint node ${NODE_NAME} node-role/storage="":NoExecuteПосле чего устанавливаем Helm-чарт командой:
$ helm install --namespace ${ROOK_NAMESPACE} ./rook-cephТеперь необходимо создать кластер и указать местоположение :
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
clusterName: "ceph"
finalizers:
- cephcluster.ceph.rook.io
generation: 1
name: rook-ceph
spec:
cephVersion:
image: ceph/ceph:v13
dashboard:
enabled: true
dataDirHostPath: /var/lib/rook/osd
mon:
allowMultiplePerNode: false
count: 3
network:
hostNetwork: true
rbdMirroring:
workers: 1
placement:
all:
tolerations:
- key: node-role/storage
operator: Exists
storage:
useAllNodes: false
useAllDevices: false
config:
osdsPerDevice: "1"
storeType: filestore
resources:
limits:
memory: "1024Mi"
requests:
memory: "1024Mi"
nodes:
- name: host-1
directories:
- path: "/mnt/osd"
- name: host-2
directories:
- path: "/mnt/osd"
- name: host-3
directories:
- path: "/mnt/osd" Проверяем статус Ceph — ожидаем увидеть HEALTH_OK:
$ kubectl -n ${ROOK_NAMESPACE} exec $(kubectl -n ${ROOK_NAMESPACE} get pod -l app=rook-ceph-operator -o name -o jsonpath='{.items[0].metadata.name}') -- ceph -sЗаодно проверим, что pod’ы с клиентским приложением не попадают на зарезервированные под Ceph узлы:
$ kubectl -n ${APPLICATION_NAMESPACE} get pods -o custom-columns=NAME:.metadata.name,NODE:.spec.nodeNameДалее по желанию настраиваются дополнительные компоненты. Подробнее о них указано в . Для администрирования настоятельно рекомендуем установить dashboard и toolbox.
Rook’и-крюки: на всё ли хватает Rook?
Как видно, разработка Rook идёт полным ходом. Но всё ещё остаются проблемы, которые не позволяют нам полностью отказаться от ручной настройки Ceph:
- Ни один драйвер Rook экспортировать метрики по использованию смонтированных блоков, что лишает нас мониторинга.
- Flexvolume и CSI изменять размер томов (в отличие от того же RBD), поэтому Rook лишается полезного (а иногда и критически нужного!) инструмента.
- Rook всё ещё не такой гибкий, как обычный Ceph. Если мы захотим настроить, чтобы пул для метаданных CephFS хранился на SSD, а сами данные — на HDD, потребуется прописывать отдельные группы устройств в CRUSH maps вручную.
- Несмотря на то, что rook-ceph-operator считается стабильным, на данный момент существуют определенные проблемы при обновлении Ceph c версии 13 до 14.
Выводы
«Сейчас Ладья закрыта от внешнего мира пешками, но мы верим, что однажды она сыграет решающую роль в партии!» (цитата придумана специально для этой статьи)
Проект Rook, несомненно, завоевал наши сердца — мы считаем, что [со всеми своими плюсами и минусами] он точно заслуживает и вашего внимания.
У нас же дальнейшие планы сводятся к тому, что сделать rook-ceph модулем для , что сделает его использование в наших многочисленных Kubernetes-кластерах ещё более простым и удобным.
P.S.
Читайте также в нашем блоге:
- «»;
- «»;
- «»;
- «»;
- «».
Источник: habr.com
