

Идеи и встречи о том, какие ещё процессы можно автоматизировать, возникают в бизнесе разного масштаба ежедневно. Но помимо того, что много времени может уходить на создание модели, нужно потратить его на её оценку и проверку того, что получаемый результат не является случайным. После внедрения любую модель необходимо поставить на мониторинг и периодически проверять.
И это всё этапы, которые нужно пройти в любой компании, не зависимо от её размера. Если мы говорим о масштабе и legacy Сбербанка, количество тонких настроек возрастает в разы. К концу 2019 года в Сбере использовалось уже более 2000 моделей. Недостаточно просто разработать модель, необходимо интегрироваться с промышленными системами, разработать витрины данных для построения моделей, обеспечить контроль её работы на кластере.
Наша команда разрабатывает платформу Sber.DS. Она позволяет решать задачи машинного обучения, ускоряет процесс проверки гипотез, в принципе упрощает процесс разработки и валидации моделей, а также контролирует результат работы модели в ПРОМ.
Чтобы не обмануть ваших ожиданий, хочу заранее сказать, что этот пост — вводный, и под катом для начала рассказано о том, что в принципе под капотом платформы Sber.DS. Историю о жизненном цикле модели от создания до внедрения мы расскажем отдельно.
Sber.DS состоит из нескольких компонентов, ключевыми из которых являются библиотека, система разработки и система исполнения моделей.

Библиотека контролирует жизненный цикл модели с момента появления идеи её разработать до внедрения в ПРОМ, постановки на мониторинг и вывода из эксплуатации. Многие возможности библиотеки продиктованы правилами регулятора, например, отчетность и хранение обучающих и валидационных выборок. По факту это реестр всех наших моделей.
Система разработки предназначена для визуальной разработки моделей и валидационных методик. Разработанные модели проходят первичную валидацию и поставляются в систему исполнения для выполнения своих бизнес функций. Также в системе исполнения модель может быть поставлена на монитор с целью периодического запуска валидационных методик для контроля ее работы.
В системе есть несколько типов узлов. Одни предназначены для подключения к различным источникам данных, другие — для трансформации исходных данных и их обогащения (разметки). Есть множество узлов для построения различных моделей и узлов для их валидации. Разработчик может загружать данные из любых источников, преобразовывать, фильтровать, визуализировать промежуточные данные, разбивать их на части.
Также платформа содержит уже готовые модули, которые можно перетаскивать на проектную область. Все действия производятся с использованием визуализированного интерфейса. Фактически можно решить задачу без единой строчки кода.
Если встроенных возможностей не хватает, то система предоставляет возможность для быстрого создания своих собственных модулей. Мы сделали режим интегрированной разработки на основе для тех, кто создает новые модули «с нуля».
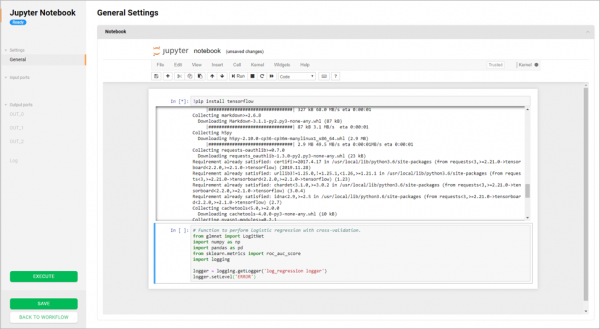
Архитектура Sber.DS построена на микросервисах. Есть много мнений о том, что такое микросервисы. Некоторые считают, что достаточно разделить монолитный код на части, но при этом они все равно ходят в одну и ту же базу данных. У нас микросервис должен общаться с другим микросервисом только по REST API. Никаких обходных путей доступа к базе данных напрямую.
Мы стараемся, чтобы сервисы не становились очень большими и неповоротливыми: один экземпляр не должен потреблять больше 4-8 гигабайт оперативной памяти и обязан обеспечивать возможность горизонтального масштабирования запросов запуском новых экземпляров. Каждый сервис общается с другими только по REST API (). Команда, ответственная за сервис, обязана сохранять обратную совместимость API до последнего клиента, который им пользуется.
Ядро приложения написано на Java с использованием Spring Framework. Решение изначально проектировалось для быстрого развертывания в облачной инфраструктуре, поэтому приложение построено с использованием системы контейнеризации (). Платформа постоянно развивается, как в части наращивания бизнес функционала (добавляются новые коннекторы, AutoML), так и в части технологической эффективности.
Одна из «фишек» нашей платформы состоит в том, что мы можем запускать код, разработанный в визуальном интерфейсе, на любой системе исполнения моделей Сбербанка. Сейчас их уже две: одна на Hadoop, другая — на OpenShift (Docker). Мы на этом не останавливаемся и создаем интеграционные модули для запуска кода на любой инфраструктуре, в том числе on-premise и в облаке. В части возможностей эффективного встраивания в экосистему Сбербанка, мы также планируем поддержать работу с имеющимися средами исполнения. В перспективе – решение может быть гибко встроено «из коробки» в любой ландшафт любой организации.
Те, кто когда-нибудь пробовал поддерживать решение, запускающее Python на Hadoop в ПРОМ, знают, что мало подготовить и доставить пользовательский environment питона на каждую датаноду. Огромное количество C/C++ библиотек для машинного обучения, которые используют Python модули, не позволят вам отдыхать спокойно. Надо не забывать обновлять пакеты при добавлении новых библиотек или серверов, сохраняя обратную совместимость с уже внедренным кодом моделей.
Есть несколько подходов к тому, как это делать. Например, заранее подготовить несколько часто используемых библиотек и внедрить их в ПРОМ. В дистрибутиве Hadoop от Cloudera для этого обычно используют . Также сейчас в Hadoop появляется возможность запуска -контейнеров. В некоторых простых случаях можно доставить код вместе с пакетом .
Банк очень серьезно подходит к безопасности запуска стороннего кода, поэтому мы по максимуму используем новые возможности ядра Linux, где процессу, запущенному в изоляционном окружении , можно ограничить, например, доступ к сети и локальному диску, что значительно снижает возможности вредоносного кода. Области данных каждого департамента защищены и доступны только владельцам этих данных. Платформа гарантирует, что данные из одной области могут попасть в другую область, только через процесс публикации данных с контролем на всех этапах от доступа к источникам до приземления данных в целевую витрину.
В этом году мы планируем завершить MVP запуска моделей, написанных на Python/R/Java на Hadoop. Мы поставили для себя амбициозную задачу научиться запускать любой пользовательский environment на Hadoop, чтобы ни в чем не ограничивать пользователей нашей платформы.
Кроме того, как оказалось, многие DS-специалисты отлично знают математику и статистику, делают классные модели, но не очень хорошо разбираются в трансформациях больших данных, и им требуется помощь наших data-инженеров для подготовки обучающих выборок. Мы решили помочь коллегам и создать удобные модули для типовой трансформации и подготовки фич для моделей на Spark-движке. Это позволит больше времени уделять разработке моделей и не ждать, пока дата-инженеры подготовят новый dataset.
У нас работают люди со знаниями в разных областях: Linux и DevOps, Hadoop и Spark, Java и Spring, Scala и Akka, OpenShift и Kubernetes. В следующей раз мы расскажем о библиотеке моделей, о том, как модель проходит по жизненному циклу внутри компании, как происходит валидация и внедрение.
Источник: habr.com
