

Прим. перев.: Service mesh — явление, которое ещё не имеет устойчивого перевода на русский язык (более 2 лет назад мы предлагали вариант «сетка для сервисов», а чуть позже некоторые коллеги стали активно продвигать сочетание «сервисное сито»). Постоянные разговоры об этой технологии привели к ситуации, в которой слишком тесно переплелись маркетинговая и техническая составляющие. Этот замечательный материал от одного из авторов оригинального термина призван внести ясность для инженеров и не только.

Комикс от
Введение
Если вы инженер-программист, работающий где-то в районе бэкенд-систем, термин «service mesh», вероятно, уже прочно закрепился в вашем сознании за последние пару лет. Благодаря странному стечению обстоятельств, это словосочетание захватывает отрасль все сильнее, а хайп и связанные с ним рекламные предложения нарастают словно снежный ком, летящий вниз по склону и не подающий никаких признаков замедления.
Service mesh зародилась в мутных, тенденциозных водах экосистемы cloud native. К сожалению, это означает, что значительная часть связанной с ней полемики варьируется от «низкокалорийной болтовни» до — если воспользоваться техническим термином — откровенной чуши. Но если отсеять весь шум, можно обнаружить, что у service mesh есть вполне реальная, определенная и важная функция.
В этой публикации я попытаюсь проделать именно это: представить честное, глубокое, ориентированное на инженеров руководство по service mesh. Я собираюсь ответить не только на вопрос: «Что это такое?», — но и «Зачем?», а также «Почему именно сейчас?». Наконец, попытаюсь обрисовать, почему (по моему мнению) конкретно эта технология вызвала такой сумасшедший ажиотаж, что само по себе интересная история.
Кто я?
Привет всем! Меня зовут . Я являюсь одним из создателей — самого первого проекта service mesh и проекта, который виноват в появлении термина service mesh как такового (простите, парни!). (Прим перев.: К слову, на заре появления этого термина, более 2,5 лет назад, мы уже переводили ранний материал того же автора под названием «».) Также я возглавляю — стартап, занимающийся созданием таких классных service mesh-штук, как Linkerd и .
Вы, наверное, догадываетесь, что у меня весьма пристрастное и субъективное мнение по этому вопросу. Впрочем, я постараюсь свести тенденциозность к минимуму (за исключением одного раздела: «Почему так много разговоров о service mesh?», — в котором все же поделюсь своими предвзятыми идеями). Также я приложу все силы к тому, чтобы сделать это руководство максимально объективным. В конкретных примерах я преимущественно буду полагаться на опыт Linkerd, при этом указывая на известные мне различия (если они имеются) в реализации других типов service mesh.
Окей, пора переходить к вкусняшкам.
Что такое service mesh?
Несмотря на весь хайп, структурно service mesh устроена довольно просто. Это всего лишь куча userspace-прокси, расположенных «рядом» с сервисами (потом мы немного поговорим о том, что такое «рядом»), плюс набор управляющих процессов. Прокси в совокупности получили название data plane, а управляющие процессы именуются control plane. Data plane перехватывает вызовы между сервисами и делает с ними «всякое-разное»; control plane, соответственно, координирует поведение прокси и обеспечивает доступ для вас, т.е. оператора, к API, позволяя манипулировать сетью и измерять её как единое целое.
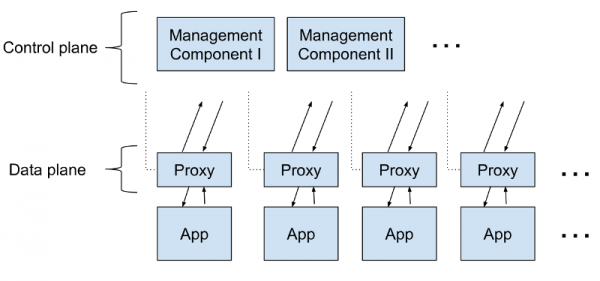
Что это за прокси? Это TCP-прокси категории «Layer 7-aware» (т.е. «учитывающие» 7 уровень модели OSI) вроде HAProxy и NGINX. Можно выбрать прокси по своему вкусу; Linkerd использует прокси на Rust, незамысловато названный . Мы собрали его специально для service mesh. Остальные mesh’и предпочитают другие прокси (Envoy — частый выбор). Впрочем, выбор прокси — это всего лишь вопрос реализации.
Что делают эти прокси-серверы? Очевидно, они проксируют вызовы к сервисам и от них (строго говоря, они выполняют функцию прокси и обратных прокси, обрабатывая как входящие, так и исходящие вызовы). И они реализуют набор функций, концентрирующийся на вызовах между сервисами. Этот фокус на трафике между сервисами и отличает service mesh-прокси от, скажем, шлюзов API или ingress-прокси (последние фокусируются на вызовах, поступающих в кластер из внешнего мира). (Прим. перев.: сравнение существующих контроллеров Ingress для Kubernetes, многие из которых используют уже упомянутый Envoy, см. в .)
Итак, с data plane мы разобрались. Control plane устроена проще: это набор компонентов, обеспечивающих всю механику, которая необходима data plane, чтобы работать скоординированным образом, включая обнаружение сервисов, выпуск сертификатов TLS, агрегацию метрик и т. д. Data plane информирует control plane о своем поведении; в свою очередь, control plane предоставляет API, позволяющий менять и отслеживать поведение data plane как единого целого.
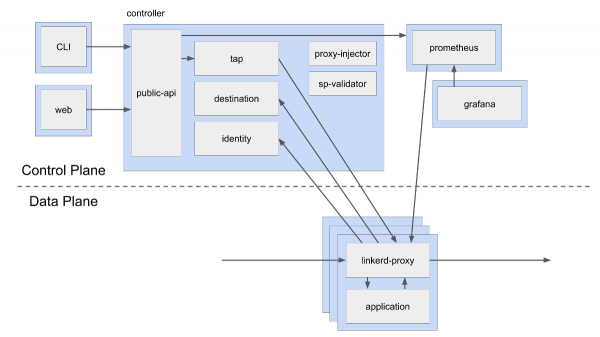
Ниже представлена схема control plane и data plane в Linkerd. Как видно, control plane включает в себя несколько различных компонентов, в том числе экземпляр Prometheus, который собирает метрики с прокси-серверов, а также другие компоненты, такие как destination (обнаружение сервисов), identity (центр сертификации, CA) и public-api (endpoint’ы для web и CLI). В отличие от этого, data plane представляет собой простой linkerd-proxy рядом с экземпляром приложения. Это всего лишь логическая схема; в реальных условиях при развертывании у вас может быть три реплики каждого компонента control plane и сотни или тысячи прокси в data plane.
(Синие прямоугольники на этой схеме символизируют границы pod’ов Kubernetes. Видно, что контейнеры с linkerd-proxy находятся в одном pod’е с контейнерами приложения. Подобная схема известна как sidecar-контейнер.)
Архитектура service mesh имеет несколько важных последствий. Во-первых, поскольку задача прокси — перехватывать вызовы между сервисами, service mesh имеет смысл только в том случае, если ваше приложение создавалось на некий набор сервисов. Mesh можно использовать с монолитами, но это явно избыточно ради одного единственного прокси, да и ее функционал вряд ли будет востребован.
Другое важное последствие состоит в том, что service mesh требует огромного количества прокси. На самом деле, Linkerd цепляет linkerd-proxy к каждому экземпляру каждого сервиса (другие реализации добавляют прокси к каждому узлу/хосту/виртуальной машине. В любом случае, это немало). Столь активное использование прокси само по себе несет ряд дополнительных осложнений:
- Прокси в data plane должны быть быстрыми, поскольку на каждый вызов приходится пара обращений к прокси: одно на стороне клиента, одно — на стороне сервера.
- Также прокси должны быть небольшими и легковесными. Каждая будет потреблять ресурсы памяти и CPU, и это потребление будет линейно расти вместе с приложением.
- Вам понадобится механизм для развертывания и обновления большого количества прокси. Делать это вручную — не вариант.
В общем, service mesh выглядит так (по крайней мере, с высоты птичьего полета): вы разворачиваете кучу userspace-прокси, которые «что-то делают» с внутренним, межсервисным трафиком, и используете control plane для мониторинга и управления ими.
Настал черед вопроса «Зачем?»
Для чего нужна service mesh?
Тем, кто впервые столкнулся с идеей service mesh, простительно испытывать легкий трепет. Конструкция service mesh означает, что она не только увеличит задержки в приложении, но также будет потреблять ресурсы и добавит кучу новых механизмов в инфраструктуру. Сперва вы устанавливаете service mesh, а потом внезапно обнаруживаете, что необходимо обслуживать сотни (если не тысячи) прокси. Спрашивается, кто добровольно пойдет на это?
Ответ на этот вопрос состоит из двух частей. Во-первых, операционные издержки, связанные с разворачиванием этих прокси, могут быть значительно снижены благодаря некоторым изменениям, происходящим в экосистеме (подробнее об этом позже).
Во-вторых, подобное устройство — на самом деле отличный способ ввести дополнительную логику в систему. И не только потому, что с помощью service mesh можно добавить множество новых функций, но и потому, что это можно сделать, не вмешиваясь в экосистему. На самом деле вся модель service mesh основана на этом постулате: в мультисервисной системе, независимо от того, что делают отдельные сервисы, трафик между ними является идеальной точкой для добавления функциональности.
Например, в Linkerd (как и в большинстве mesh’ей) функциональность сфокусирована преимущественно на вызовах HTTP, включая HTTP/2 и gRPC*. Функциональность довольно богатая — ее можно разделить на три класса:
- Функции, связанные с надежностью. Повторные запросы, таймауты, канареечный подход (разделение/перенаправление трафика) и т.д.
- Функции, связанные с мониторингом. Агрегирование показателей успешности, задержек и объемов запросов для каждого сервиса или отдельных направлений; построение топологических карт сервисов и т.д.
- Функции, связанные с безопасностью. Mutual TLS, контроль доступа и т.д.
* С точки зрения Linkerd gRPC практически ничем не отличается от HTTP/2: просто в полезной нагрузке используется protobuf. С точки зрения разработчика две эти вещи, конечно, различаются.
Многие из этих механизмов работают на уровне запросов (отсюда и «L7-прокси»). Например, если сервис Foo посылает HTTP-вызов сервису Bar, linkerd-proxy на стороне Foo может провести интеллектуальную балансировку нагрузки и направлять вызовы с Foo на экземпляры Bar в зависимости от наблюдаемой задержки; он может повторить запрос при необходимости (и если тот идемпотентен); он может записать код ответа и время ожидания, и т.д. Аналогичным образом linkerd-proxy на стороне Bar может отклонить запрос, если он не разрешен или превышен лимит запросов; может зафиксировать задержку со своей стороны, и т.д.
Прокси могут «что-то делать» и на уровне подключения. Например, linkerd-proxy на стороне Foo может инициировать TLS-подключение, а linkerd-proxy на стороне Bar — разрывать его, и обе стороны могут проверять TLS-сертификаты друг друга*. Это обеспечивает не только шифрование между сервисами, но и криптографически безопасный способ идентификации сервисов: Foo и Bar могут «доказать», что они те, кем себя называют.
* «Друг друга» означает, что сертификат клиента также проверяется (mutual TLS). В «классическом» TLS, например, между браузером и сервером, обычно проверяется сертификат только одной стороны (сервера).
Независимо от того, работают ли они на уровне запросов или подключений, важно подчеркнуть, что все функции service mesh носят эксплуатационный характер. Linkerd не в состоянии трансформировать семантику полезной нагрузки — например, добавить поля в JSON-фрагмент или внести изменения в protobuf. В этой важной особенности мы поговорим позже, когда речь пойдет о ESB и middleware.
Таков набор функций, которые предлагает service mesh. Возникает вопрос: почему бы не реализовать их непосредственно в приложении? И зачем вообще связываться с прокси?
Почему service mesh — это хорошая идея
Хотя возможности service mesh захватывают воображение, ее основная ценность на самом деле лежит не в функциях. В конце концов, мы можем реализовать их непосредственно в приложении (позже мы увидим, что таково было происхождение service mesh). Если попытаться выразить эту мысль одним предложением, ценность service mesh состоит в следующем: она предоставляет функции, критически важные для работы современного серверного программного обеспечения, единообразным для всего стека и независимым от кода приложения образом.
Давайте проанализируем это предложение.
«Функции, критически важные для работы современного серверного программного обеспечения». Если вы создаете транзакционное серверное приложение, связанное с публичным интернетом, принимающее запросы из внешнего мира и отвечающее на них в течение короткого времени — например, веб-приложение, API-сервер, да и подавляющее большинство других современных приложений, — и если вы реализуете его как набор из сервисов, которые синхронно взаимодействуют друг с другом, и если вы постоянно модернизируете это ПО, добавляя новые возможности, и если вы вынуждены поддерживать эту систему в работоспособном состоянии в процессе модификации — в этом случае поздравляю вас, вы занимаетесь созданием современного серверного ПО. И все эти замечательные функции, перечисленные выше, на самом деле оказываются критически важными для вас. Приложение должно быть надежным, безопасным, и вы должны иметь возможность наблюдать за тем, что оно делает. Как раз эти вопросы и помогает решить service mesh.
(Окей, в предыдущий абзац все же пробралась моя убежденность в том, что этот подход является современным способом создавать серверное ПО. Другие предпочитают разрабатывать монолиты, «реактивные микросервисы» и иные штуки, не подпадающие под определение, приведенное выше. У этих людей наверняка имеется свое мнение, отличное от моего. В свою очередь, я считаю, что они «не правы» — хотя в любом случае service mesh для них не слишком полезна).
«Единообразным для всего стека». Функции, предоставляемые service mesh, не просто критически важны. Они применяются ко всем сервисам в приложении независимо от того, на каком языке те написаны, какой фреймворк используют, кто их написал, как они были развернуты и от всех остальных тонкостей их разработки и применения.
«Независимым от кода приложения». Наконец, service mesh не только предоставляет единые функциональные возможности для всего стека — она делает это способом, не требующем правки приложения. Фундаментальная основа функциональности service mesh, включая задачи по настройке, обновлению, эксплуатации, обслуживанию и т.д., находится исключительно на уровне платформы и независима от приложения. Приложение может меняться, не затрагивая service mesh. В свою очередь, service mesh может меняться без какого-либо участия приложения.
Короче говоря, service mesh не только предоставляет жизненно важные функции, но и делает это глобальным, единообразным и независимым от приложения способом. И поэтому, хотя функциональность service mesh можно реализовать в коде сервиса (например, в виде библиотеки, включенной в каждый сервис), этот подход не обеспечит однородность и независимость, столь ценные в случае service mesh.
И все, что для этого нужно, — добавить кучу прокси! Обещаю, очень скоро мы рассмотрим эксплуатационные издержки, связанные с добавлением этих прокси. Но сначала давайте остановимся и взглянем на эту идею о независимости с точки зрения различных людей.
Кому помогает service mesh?
Как бы неудобно это ни было, но для того, чтобы некая технология стала важной частью экосистемы, она должна быть принята людьми. Так кто же заинтересован в service mesh? Кто выигрывает от ее использования?
Если вы разрабатываете современное серверное ПО, то можете приблизительно представить свою команду как группу владельцев сервисов, которые вместе разрабатывают и внедряют бизнес-логику, и владельцев платформы, занимающихся разработкой внутренней платформы, на которой эти сервисы работают. В малых организациях это могут быть одни и те же люди, но вместе с ростом компании эти роли, как правило, становятся более выраженными и даже делятся на подроли… (Тут можно многое сказать о меняющейся природе devops’а, организационном влиянии микросервисов и т. п. Но пока давайте примем эти описания как данность).
С такой точки зрения явными бенефициарами service mesh являются владельцы платформы. Ведь в конечном итоге цель платформенной команды состоит в том, чтобы создать внутреннюю платформу, на которой владельцы сервисов могут реализовывать деловую логику и делать это способом, который гарантирует их максимальную независимость от мрачных деталей её эксплуатации. Service mesh не только предлагает возможности, критически важные для достижения этой цели: она делает это способом, который, в свою очередь, не налагает зависимостей на владельцев сервисов.
Владельцы сервисов также выигрывают, хотя и более опосредованным образом. Цель владельца сервиса — быть максимально продуктивным в реализации логики бизнес-процесса, и чем меньше ему приходится заботиться о вопросах эксплуатации, тем лучше. Вместо того, чтобы заниматься реализацией, скажем, политик повторных запросов или TLS, они могут сосредоточиться исключительно на задачах бизнеса и надеяться, что платформа позаботится обо всем остальном. Для них это большое преимущество.
Организационную ценность такого разделения между владельцами платформ и сервисов трудно переоценить. Я думаю, что она вносит основной вклад в ценность service mesh.
Мы усвоили этот урок, когда один из первых поклонников Linkerd рассказал нам, почему они выбрали service mesh: потому что она позволила им «свести говорильню к минимуму». Вот немного подробностей: ребята из одной крупной компании мигрировали свою платформу в Kubernetes. Поскольку приложение работало с конфиденциальной информацией, они хотели зашифровать все коммуникации в кластерах. Однако ситуация осложнялась наличием сотен сервисов и сотен команд разработчиков. Перспектива связываться со всеми и убеждать внести поддержку TLS в свои планы совершенно их не радовала. Установив Linkerd, они перенесли ответственность с разработчиков (с точки зрения которых это были лишние хлопоты) на платформеров, для которых это являлось приоритетом высшего уровня. Другим словами, Linkerd решал для них не столько техническую, сколько организационную проблему.
Короче говоря, service mesh — это, скорее, решение не технической, а социо-технической проблемы. (Спасибо за знакомство с этим термином.)
Решит ли service mesh все мои проблемы?
Да. В смысле, нет!
Если посмотреть на три класса функций, озвученных выше: надежность, безопасность и наблюдаемость, — становится понятно, что service mesh не является полноценным решением ни для одной из этих проблем. Хотя Linkerd может посылать повторные запросы (если знает, что они идемпотентны), он не в состоянии принимать решения о том, что возвращать пользователю, если сервис окончательно упал — такие решения должно принимать приложение. Linkerd может вести статистику успешных запросов, однако он не в состоянии заглянуть в сервис и предоставить его внутренние метрики — подобный инструментарий должен быть у приложения. И хотя Linkerd способен организовывать mTLS, полноценные решения в деле обеспечения безопасности требуют гораздо большего.
Подмножество функций в этих областях, предлагаемых service mesh, относятся к фичам платформы. Под этим я подразумеваю функции, которые:
- Независимы от бизнес-логики. Способ, которым ведется построение гистограмм вызовов между Foo и Bar, совершенно не зависит от того, почему Foo вызывает Bar.
- Сложно правильно реализовать. В Linkerd повторные попытки параметризуются всякими навороченными штуками вроде бюджетов повторных попыток (retry budgets), поскольку бесхитростный подход-в-лоб в реализации подобных вещей наверняка приведет к возникновению так называемой «лавины запросов» (retry storm) и другим проблемам, характерным для распределенных систем.
- Наиболее эффективны, когда применяются единообразно. Механизм TLS имеет смысл только в том случае, когда применяется везде.
Поскольку эти функции реализованы на уровне прокси (а не на уровне приложения), service mesh предоставляет их на уровне платформы, а не приложения. Таким образом, не важно, на каком языке написаны сервисы, какой фреймворк они используют, кто их написал и почему. Прокси работают за границами всех этих подробностей, а фундаментальная основа этой функциональности, включая задачи по настройке, обновлению, эксплуатации, обслуживанию и т. д., лежит исключительно на уровне платформы.
Примеры возможностей service mesh
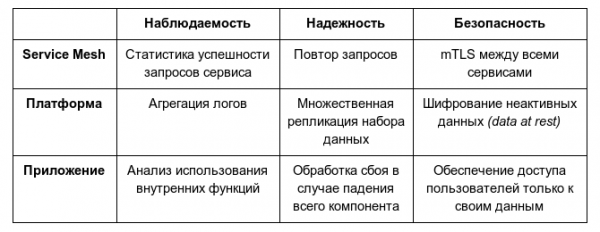
Подводя итог, хочу сказать, что service mesh не является полным решением для обеспечения надежности, наблюдаемости или безопасности. Размах этих областей подразумевает обязательное участие владельцев сервисов, Ops/SRE-команд и других субъектов компании. Service mesh предоставляет только «срез» на уровне платформы для каждой из этих областей.
Почему service mesh стала популярна именно сейчас?
Вероятно, в настоящий момент вы задаетесь вопросом: окей, если service mesh настолько хороша, почему мы не начали разворачивать миллионы прокси в стеке лет десять назад?
Есть банальный ответ на этот вопрос: десять лет назад все строили монолиты, и service mesh никому не была нужна. Это правда, но, по моему мнению, в таком ответе теряется суть. Даже десять лет назад концепция микросервисов как перспективного способа создания крупномасштабных систем широко обсуждалась и применялась в таких компаниях, как Twitter, Facebook, Google и Netflix. Общее представление — по крайней мере, в тех частях отрасли, с которыми я контактировал, — состояло в том, что микросервисы — это «правильный способ» создавать крупные системы, даже если это было чертовски трудно.
Конечно, хотя десять лет назад были компании, эксплуатирующие микросервисы, они вовсе не втыкали прокси везде где только можно, чтобы сформировать service mesh. Однако если присмотреться, они делали нечто подобное: во многих из этих компаний предписывалось использовать особую внутреннюю библиотеку для сетевого взаимодействия (иногда называемую библиотекой толстого клиента, fat client library).
У Netflix была Hysterix, у Google была Stubby, у Twitter — библиотека Finagle. Finagle, например, была обязательной для каждого нового сервиса в Twitter. Она обрабатывала как клиентскую, так и серверную часть соединений, позволяла выполнять повторные запросы, поддерживала маршрутизацию запросов, балансировку нагрузки и измерения. Она обеспечивала согласованный слой надежности и наблюдаемости для всего стека Twitter, независимо от того, чем именно занимался сервис. Конечно, она работала только для JVM-языков и основывалась на модели программирования, которую приходилось использовать для всего приложения. Однако ее функциональные возможности были почти такими же, как и у service mesh. (На самом деле первая версия Linkerd просто представляла собой Finagle, обернутый в форму прокси.)
Таким образом, десять лет назад существовали не только микросервисы, но и специальные прото-service-mesh библиотеки, решавшие те же самые проблемы, что service mesh решает сегодня. Однако самой service mesh тогда не было. Должен был произойти еще один сдвиг, прежде чем она появилась.
И именно здесь лежит более глубокий ответ, скрытый в другой перемене, случившейся за последние 10 лет: произошло резкое снижение стоимости развертывания микросервисов. Упомянутые выше компании, использовавшие микросервисы десять лет назад: Twitter, Netflix, Facebook, Google, — были компаниями огромного масштаба и огромных ресурсов. У них была не только потребность, но и возможность создавать, развертывать и эксплуатировать крупные приложения на основе микросервисов. Энергия и усилия, приложенные инженерами Twitter к переходу с монолитного на микросервисный подход, просто поражают воображение. (Честно говоря, как и тот факт, что это удалось.) Подобного рода инфраструктурные маневры тогда были невозможны для меньших по размеру компаний.
Перенесемся в настоящее. Сегодня существуют стартапы, где соотношение микросервисов к разработчикам составляет 5:1 (или даже ), и более того, они успешно с ними справляются! Если стартап из 5 человек способен, не напрягаясь, эксплуатировать 50 микросервисов, значит что-то явно снизило стоимость их внедрения.
1500 микросервисов в Monzo; каждая линия — предписанное сетевое правило, разрешающее трафик
Резкое снижение стоимости эксплуатации микросервисов является результатом одного процесса: роста популярности контейнеров и оркестраторов. Именно в этом и состоит глубокий ответ на вопрос о том, что способствовало появлению service mesh. Одна и та же технология сделала привлекательными как service mesh, так и микросервисы: Kubernetes и Docker.
Почему? Ну, Docker решает одну большую проблему — проблему упаковки. Упаковывая приложение и его (несетевые) runtime-зависимости в контейнер, Docker превращает приложение во взаимозаменяемую единицу, которую можно разместить и запустить где угодно. В то же время он значительно упрощает эксплуатацию многоязычного стека: поскольку контейнер — атомарная единица выполнения, для целей развертывания и эксплуатации не важно, что находится внутри, будь то приложение на JVM, Node, Go, Python или Ruby. Вы просто запускаете его, и все.
Kubernetes выводит все на новый уровень. Теперь, когда есть куча «выполняемых штук» и множество машин, на которых можно их запускать, возникает потребность в инструменте, способном сопоставлять их друг с другом. В широком смысле, вы даете Kubernetes множество контейнеров и множество машин, а он сопоставляет их друг с другом (конечно, это динамический и постоянно меняющийся процесс: новые контейнеры перемещаются по системе, машины запускаются и останавливаются и т.д. Однако Kubernetes учитывает все это).
После настройки Kubernetes временные затраты на развертывание и эксплуатацию одного сервиса слабо отличаются от затрат на развертывание и эксплуатацию десяти сервисов (на самом деле, они практически аналогичны и для 100 сервисов). Добавьте к этому контейнеры как механизм упаковки, поощряющий мультиязычную реализацию, и получите массу новых приложений, реализованных в форме микросервисов, написанных на различных языках — как раз ту среду, для которой так хорошо подходит service mesh.
Итак, мы подошли к ответу на вопрос, почему идея service mesh стала популярна именно сейчас: та однородность, которую Kubernetes обеспечивает для сервисов, прямым образом применима к эксплуатационным задачам, стоящим перед service mesh. Вы пакуете прокси в контейнеры, даете Kubernetes задачу прилепить их куда только можно, и вуаля! На выходе получаете service mesh, при этом всей механикой её развертывания заправляет Kubernetes. (По крайней мере, с высоты птичьего полета. Конечно, в этом процессе есть множество нюансов.)
Подводя итог: причина, по которой service mesh стала популярна именно сейчас, а не десять лет назад, состоит в том, что Kubernetes и Docker не только значительно увеличили потребность в ней, упростив реализацию приложений как наборов мультиязычных микросервисов, но и существенно сократили издержки на ее эксплуатацию, обеспечив механизмы развертывания и поддержки парков sidecar-прокси.
Почему так много разговоров о service mesh?
Предупреждение: в этом разделе я прибегаю ко всяческим предположениям, догадкам, измышлениям и внутренней информации.
Проведя поиск по фразе «service mesh», вы наткнетесь на кучу переработанного низкокалорийного контента, странных проектов и калейдоскопа искажений, достойных эхо-камеры. Любой модной новой технологии свойственно это, но в случае service mesh проблема стоит особенно остро. Почему?
Ну, частично это моя вина. Я прилагал все силы, чтобы продвинуть Linkerd и service mesh при любой удобной возможности, путем бесчисленных публикаций в блоге и статей, подобных этой. Но я не настолько могуч. Чтобы действительно ответить на этот вопрос, следует немного поговорить об общей ситуации. А говорить о ней невозможно, не упомянув один проект: — service mesh с открытым исходным кодом, разрабатываемую совместно Google, IBM и Lyft.
(У этих трех компаний совершенно разные роли: участие Lyft, похоже, сводится к одному лишь названию; они являются авторами Envoy, но не используют Istio или участвуют в его разработке. IBM участвует в разработке Istio и использует его. Google активно участвует в разработке Istio, но, насколько могу судить, на самом деле не использует его.)
Проект Istio примечателен двумя особенностями. Во-первых, это огромные маркетинговые усилия, которые Google, в частности, прикладывает к его продвижению. По моим оценкам, большинство людей, осведомленных о концепции service mesh в настоящее время, впервые узнали о ней благодаря Istio. Вторая особенность состоит в том, насколько плохо Istio был принят. В этом вопросе я, очевидно, сторона заинтересованная, но пытаясь оставаться максимально объективным, всё же не могу не , не очень-то характерный (хотя и не уникальный: на ум приходит systemd, …) для Open Source-проекта.
(На практике у Istio, похоже, проблемы не только со сложностью и UX, но и с производительностью. Например, во время , проведенной третьей стороной, специалисты обнаружили ситуации, в которых хвосты задержек (tail latency) Istio в 100 раз превышали аналогичный показатель для Linkerd, а также ситуации с недостатком ресурсов, когда Linkerd продолжал успешно функционировать, а Istio полностью прекращал работу.)
Оставляя в стороне мои теории о том, почему так произошло, я считаю, что зашкаливающий ажиотаж вокруг service mesh объясняется как раз участием Google. А именно, комбинацией следующих трех факторов:
- навязчивое продвижение Istio со стороны Google;
- соответствующее неодобрительное, критическое отношение к проекту;
- недавний стремительный взлет популярности Kubernetes, воспоминания о котором ещё свежи.
Вместе эти факторы объединяются в некое дурманящее, бескислородное окружение, в котором способность к рациональному суждению ослабевает, и остается только чудная разновидность .
С точки зрения Linkerd это… я бы описал как неоднозначное благо. Я имею в виду, замечательно, что service mesh вошла в мейнстрим — чего не было в 2016-м, когда Linkerd только появился и было по-настоящему трудно привлечь внимание окружающих к проекту. Теперь такой проблемы нет! Но плохо то, что ситуация с service mesh сегодня настолько запутанная, что практически невозможно понять, какие проекты действительно относятся к категории service mesh (не говоря уже о том, чтобы понять, какой из них лучше всего подходит для конкретного варианта использования). Это, безусловно, мешает всем (и, определено, в некоторых случаях Istio или другой проект подходит больше, чем Linkerd, поскольку последний все же не является универсальным решением).
Со стороны Linkerd наша стратегия заключалась в том, чтобы игнорировать шум, продолжать концентрироваться на решении реальных проблем сообщества и, по сути, ждать, когда ажиотаж поутихнет. В конечном итоге хайп пойдет на убыль, и мы сможем продолжать спокойно работать.
Пока же нам всем придется немного потерпеть.
Пригодится ли service mesh мне, скромному software engineer?
С ответом на этот вопрос поможет определиться следующий опросник:
Вы занимаетесь исключительно реализацией бизнес-логики? В этом случае service mesh вам не пригодится. То есть, конечно, вы можете ею заинтересоваться, но в идеале service mesh не должна прямым образом влиять на что-либо в вашем окружении. Продолжайте работать над тем, за что вам платят.
Вы поддерживаете платформу в компании, которая использует Kubernetes? Да, в этом случае service mesh вам необходима (конечно, если вы не используете K8s просто для запуска монолита или пакетной обработки — но тогда я хотел бы поинтересоваться, зачем вам K8s). Скорее всего, вы окажетесь в ситуации со множеством микросервисов, написанных разными людьми. Все они взаимодействуют друг с другом и связаны в клубок runtime-зависимостей, а вам нужно найти способ справиться со всем этим. Применение Kubernetes позволяет выбрать service mesh «под себя». Для этого ознакомьтесь с их возможностями и особенностями и ответьте на вопрос, подходит ли вам вообще какой-либо проект из имеющихся (рекомендую начать исследование с Linkerd).
Вы занимаетесь платформой в компании, которая НЕ использует Kubernetes, но использует микросервисы? В этом случае service mesh вам будет полезна, однако ее использование будет нетривиальным. Конечно, вы можете имитировать работу service mesh, разместив кучу прокси, но важным преимуществом Kubernetes является именно модель развертывания: обслуживание этих прокси вручную потребует гораздо больших времени, сил и затрат.
Вы отвечаете за платформу в компании, которая работает с монолитами? В этом случае service mesh вам, вероятно, не нужна. Если вы работаете с монолитами (или даже с наборами монолитов), имеющими четко определенные и редко меняющиеся паттерны взаимодействия, то service mesh мало что сможет вам предложить. Так что можете просто не замечать ее и надеяться, что она исчезнет как страшный сон…
Заключение
Наверное, service mesh всё-таки не стоит называть «самой хайповой технологией мира» — эта сомнительная честь, вероятно, принадлежит биткоину или ИИ. Возможно, она входит в первую пятерку. Но если пробиться сквозь слои шума и гама, становится ясно, что service mesh приносит реальную пользу тем, кто создает приложения в Kubernetes.
Я хотел бы, чтобы вы попробовали Linkerd — его установка в кластер Kubernetes (или даже в Minikube на ноутбуке) , и вы сможете сами увидеть, о чем я говорю.
FAQ
— Если я буду игнорировать service mesh, она исчезнет?
— Должен огорчить вас: service mesh с нами надолго.
— Но я НЕ ХОЧУ использовать service mesh!
— Ну и не надо! Только почитайте мой опросник выше, чтобы понять, следует ли ознакомиться хотя бы с ее азами.
— Разве это не старое доброе ESB/middleware под новым соусом?
— Service mesh занимается эксплуатационной логикой, а не смысловой. сервисной шины предприятия (). Сохранение этого разделения помогает service mesh избежать той же участи.
— Чем service mesh отличается от API-шлюзов?
— Существует миллион статей на эту тему. Просто погуглите.
— Envoy — это service mesh?
— Нет, Envoy — это не service mesh, это прокси-сервер. Его можно использовать для организации service mesh (и многого другого — это прокси общего назначения). Но сам по себе он не является service mesh.
— Network Service Mesh — это service mesh?
— Нет. Несмотря на название, это не service mesh (как вам чудеса маркетинга?).
— Поможет ли service mesh с моей реактивной асинхронной системой на базе очереди сообщений?
— Нет, service mesh вам не поможет.
— Какую service mesh мне использовать?
— , ежу понятно.
— Статья — отстой! / Автора — на мыло!
— Пожалуйста, поделитесь ссылкой на неё со всеми друзьями, чтобы они смогли в этом убедиться!
Благодарности
Как вы могли догадаться по названию, эта статья была вдохновлена фантастическим трактатом Jay Kreps «». Я встретил Jay’я десять лет назад, когда брал интервью в Linked In, и с тех пор он служит вдохновением для меня.
Хотя я люблю называть себя «разработчиком Linkerd», реальность такова, что я скорее maintainer файла README.md в проекте. Над Linkerd сегодня работает , , людей, и этот проект не состоялся бы без участия замечательного сообщества контрибьюторов и пользователей.
И в завершение особая благодарность создателю Linkerd, (primus inter pares), который вместе со мной много лет назад нырнул с головой во всю эту суету с service mesh.
P.S. от переводчика
Читайте также в нашем блоге:
- «»;
- «»;
- «»;
- «»;
- «».
Источник: habr.com
