

Директор по эксплуатации портала Banki.ru Андрей Никольский рассказал на прошлогодней конференции про сервисы-сироты: как опознать сироту в инфраструктуре, чем плохи сервисы-сироты, что с ними делать, и как быть, если ничего не помогает.
Под катом текстовая версия доклада.

Здравствуйте, коллеги! Меня зовут Андрей, я руковожу эксплуатацией в компании Banki.ru.
У нас есть большие сервисы, это такие монолитосервисы, есть сервисы в более классическом понимании, есть совсем маленькие. Я в своей рабоче-крестьянской терминологии говорю, что если сервис простой и маленький, то он микро, а если он не очень простой и не маленький, то он просто сервис.
Плюсы сервисов
Пробегусь быстренько по плюсам сервисов.
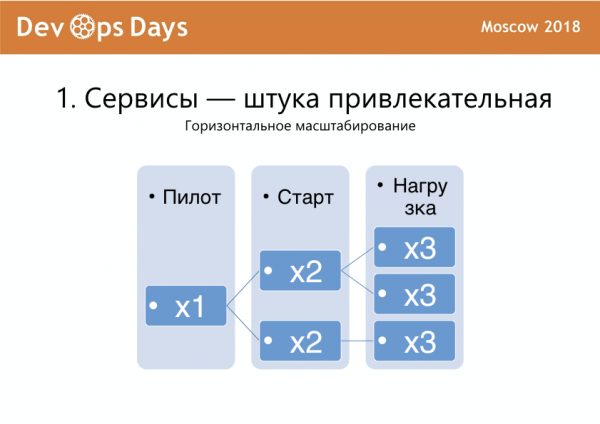
Первое — масштабирование. Вы можете быстро сделать что-нибудь на сервисе и стартовать в продакшн. У вас приехал трафик, вы сервис склонировали. У вас приехал еще трафик, вы еще склонировали и с этим живете. Это хороший бонус, и, в принципе, когда мы начинали, он считался у нас самым важным, зачем мы вообще все это делаем.
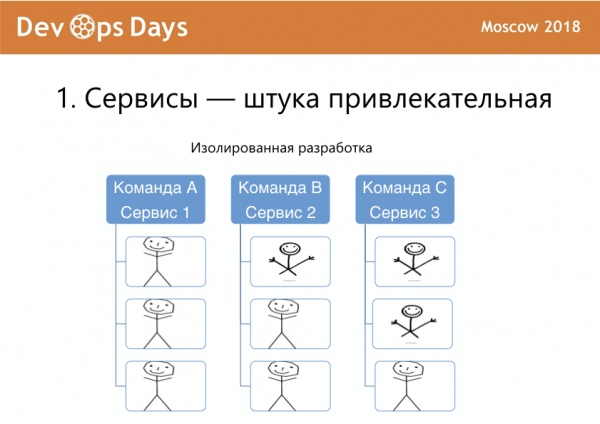
Во-вторых, изолированная разработка, когда у вас несколько команд разработки, несколько разных разработчиков в каждой команде, и каждая команда пилит какой-то свой сервис.
С командами возникает нюанс. Разработчики бывают разные. И существуют, например, . Я впервые увидел это у Максима Дорофеева. Иногда люди-снежинки есть в некоторых командах, а в некоторых их нет. Это делает разные сервисы, которые используются в компании, немного неравномерными.

Посмотрите на картинку: это хороший разработчик, у него большие руки, он может многое делать. Главная проблема — откуда эти руки растут.
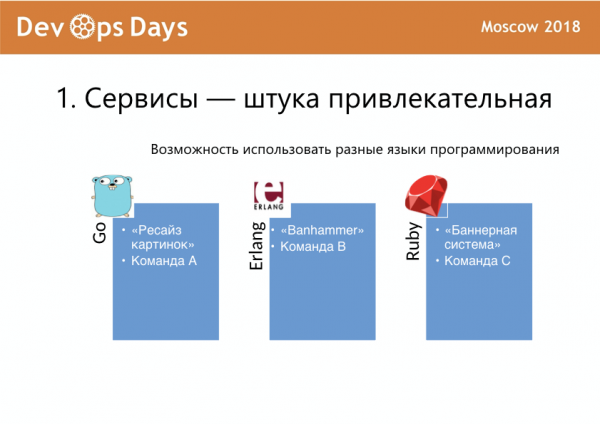
Сервисы дают возможность использовать разные языки программирования, больше подходящие для разных задач. Какой-то сервис на Go, какой-то на Erlang, какой-то на Ruby, что-то на PHP, что-то на Python. В общем, можно развернуться очень широко. Тут тоже есть нюансы.

Сервис-ориентированная архитектура — это прежде всего про devops. То есть если у вас нет автоматизации, нет процесса деплоя, если вы настраиваете руками, у вас конфигурации могут меняться от инстанса сервиса к инстансу, и вам приходится туда ходить что-то делать, то вы в аду.
Например, у вас есть 20 сервисов, и вам нужно деплоить руками, у вас 20 консолей, и вы одновременно жмете «enter», как ниндзя. Это не очень хорошо.
Если у вас сервис после тестирования (если есть тестирование, конечно), и надо еще допилить напильником, чтобы он работал в продакшене, у меня тоже для вас плохие новости.
Если вы полагаетесь на специфические сервисы Амазона и работаете при этом в России, то два месяца назад у вас тоже было «Все вокруг горит, i’m fine, все классно».
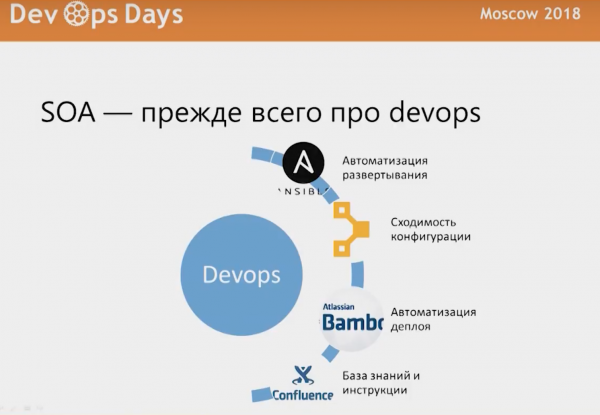
Мы используем Ansible для автоматизации развертывания, Puppet для сходимости, Bamboo для автоматизации деплоя, Confluence для того, чтобы все это как-то описывать.
Подробно на этом останавливаться не буду, потому что доклад скорее про практики взаимодействий, а не про техническую реализацию.

У нас бывали, например, проблемы, что Puppet на сервере работает с Ruby 2, а какое-то приложение написано под Ruby 1.8, и вместе они не работают. Там какой-то косяк случается. А когда вам надо на одной машине держать несколько версий Ruby, у вас обычно начинаются проблемы.
У нас, например, каждому разработчику мы выдаем площадку, на которой есть примерно все, что у нас есть, все сервисы, которые можно разрабатывать, чтобы у него было изолированное окружение, он мог ломать его и строить, как ему хочется.
Бывает, нужен какой-то специально скомпилированный пакет с поддержкой чего-то там. Это достаточно жестко. Я вот послушал доклад, где докер-образ весит по 45 Гб. В линуксе, конечно, попроще, там поменьше все, но все равно, никаких мест не хватит.
Ну, и бывают противоречивые зависимости, когда у вас один кусок проекта зависит от библиотеки одной версии, другой кусок проекта от другой версии, а библиотеки вместе не ставятся вообще никак.
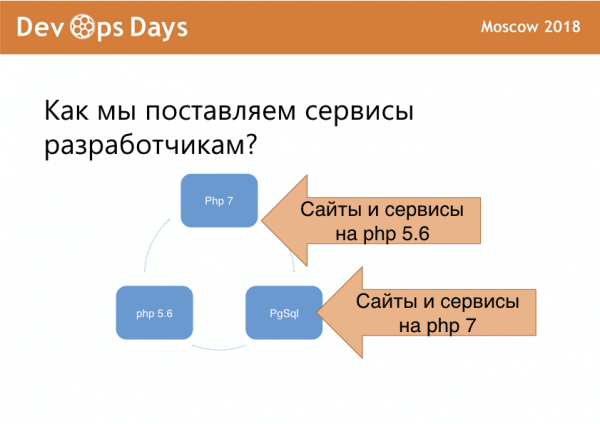
У нас есть сайты и сервисы на PHP 5.6, нам за них стыдно, но что делать. Это у нас одна площадка. Есть сайты и сервисы на PHP 7, их побольше, за них нам не стыдно. И у каждого разработчика есть своя базочка, где он радостно пилит.
Если вы пишете в компании на одном языке, то три виртуалки на разработчика — это нормально звучит. Если у вас разные языки программирования, то ситуация становится хуже.
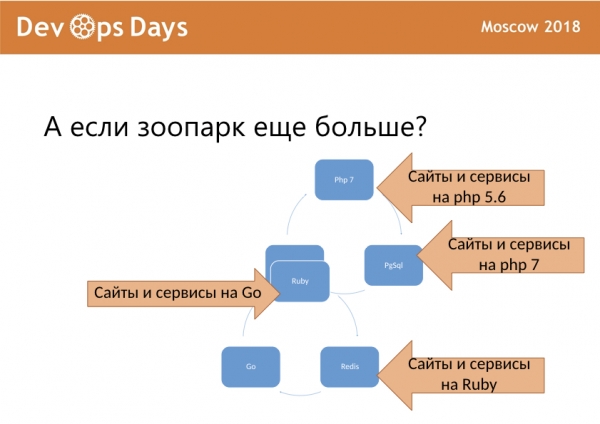
У вас появляются сайты и сервисы на этом, на этом, потом еще одна площадка для Go, одна площадка для Ruby, еще какой-нибудь Redis сбоку. В итоге все это превращается в большое поле для поддержки, и все время что-то из этого может ломаться.

Поэтому мы заменили плюшки языка программирования на использование разных фреймворков, поскольку фреймворки на PHP достаточно разные, у них есть разные возможности, разное комьюнити, разная поддержка. И можно писать сервис так, чтобы у вас уже было что-то готовое под него.
У каждого сервиса — своя команда

Наш главный плюс, который выкристаллизовался за несколько лет, — у каждого сервиса есть своя команда. Это удобно для большого проекта, можно сэкономить время на документации, менеджеры хорошо знают свой проект.
Задачи из поддержки можно отлично закидывать. Например, сломался сервис страхования. И сразу команда, которая занимается страхованием, идет чинить.
Быстро делаются новые фичи, потому что когда у вас один какой-то атомарный сервис, в него можно оперативно что-нибудь вкрутить.
И когда вы сломали свой сервис, а это неизбежно случается, вы не задели чужие сервисы, и к вам не прибегают разработчики с битами из других команд и не говорят: «Ай-ай, не надо так».

Как всегда, есть нюансы. У нас стабильные команды, к команде менеджеры прибиты гвоздями. Есть четкие документы, менеджеры плотно за этим всем следят. У каждой команды с менеджером есть по несколько сервисов, и есть конкретная точка компетенции.
Если команды плавающие (такое тоже у нас иногда используется), есть хороший метод, который называется «звездная карта».
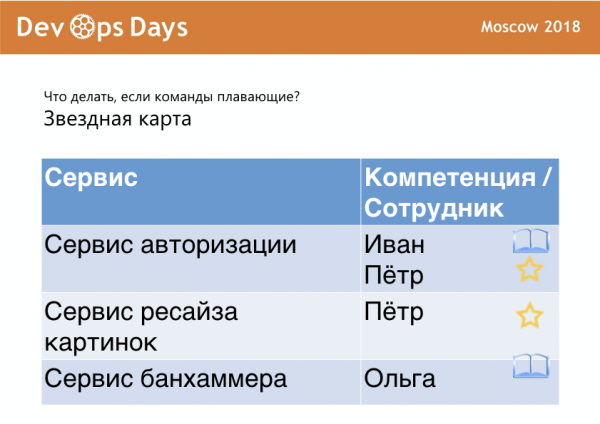
У вас есть список сервисов и люди. Звездочка означает, что человек — эксперт в этом сервисе, книжка означает, что человек изучает этот сервис. Задача человека – поменять книжечку на звездочку. А если напротив сервиса ничего не написано, то начинаются проблемы, о которых я буду дальше рассказывать.
Как появляются сервисы-сироты?

Первая проблема, первый способ, получить у себя в инфраструктуре сервис-сироту — это увольнения людей. У кого-нибудь бывало, когда из бизнеса прилетают сроки до того, как оценили задачи? Иногда бывает, что сроки жесткие и на документацию просто не хватает времени. «Надо сдавать сервис в продакшн, потом допишем».
Если команда небольшая, бывает, что в ней один разработчик, который пишет всё, остальные на подхвате. «Я написал основную архитектуру, ты давай интерфейсы накидай». Потом в какой-то момент менеджер, например, уходит. И в этот период, когда менеджер ушел, а нового еще не назначили, разработчики сами решают, куда сервис движется, что там происходит. А как мы знаем (вернемся на несколько слайдов назад), в некоторых командах есть люди-снежинки, иногда снежинка-тимлид. Потом он увольняется, и мы получаем сервис-сироту.

При этом задачи от поддержки и от бизнеса никуда не деваются, они оседают в бэклоге. Если при разработке сервиса были какие-то архитектурные ошибки, они тоже оседают в бэклоге. Сервис медленно деградирует.
Как опознать сироту?
Этот список неплохо описывает ситуацию. Кто узнал у себя что-нибудь в инфраструктуре?

Про задокументированные work-around’ы: есть сервис и, в целом, он работает, у него есть мануал на две страницы, как с ним работать, но как он работает внутри, никто не знает.
Или, например, есть какой-нибудь сокращатор ссылок. У нас, например, сейчас в ходу три сокращатора ссылок для разных целей в разных сервисах. Это последствия как раз.

Сейчас я буду капитаном очевидность. Что нужно предпринимать? Во-первых, надо передать сервис другому менеджеру, другой команде. Если у вас тимлид еще не уволился, то в эту другую команду, когда вы понимаете, что сервис похож на сироту, надо включать кого-то, кто хоть что-то в нем понимает.
Главная вещь: у вас должны быть написанные кровью процедуры передачи. В нашем случае, слежу за этим обычно я, потому что мне надо, чтобы это все работало. Менеджерам надо, чтобы это было быстро сдано, а что с ним потом будет, им уже не так важно.

Следующий способ сделать сироту — «Сделаем на аутсорсе, так будет быстрее, а потом передадим в команду». Понятно, что у всех есть какие-то планы в команде, очередь. Часто бизнес-заказчик думает, что на аутсорсере сделают так же, как и техотдел, который есть в компании. Хотя мотиваторы у них разные. На аутсорсе бывают странные технологические решения и странные алгоритмические решения.

У нас, например, был сервис, в котором был Sphinx в разных неожиданных местах. Я попозже расскажу, что пришлось сделать.
У аутсорсеров бывают самописные фреймворки. Это просто голый PHP с копипастом с предыдущего проекта, где можно найти всякое. Большие костыли в деплой-скриптах, когда вам нужно какими-то сложными Bash-скриптами поменять несколько строчек в каком-то файлике, при этом эти деплой-скрипты вызываются каким-то третьим скриптом. В итоге вы меняете систему деплоя, выбираете что-то другое, хоп, а у вас сервис не работает. Потому что там надо было еще 8 ссылок поставить между разными папочками. Или бывает, что тысяча записей работает, а сто тысяч уже нет.
Продолжу капитанить. Приемка сервиса из аутсорса — это процедура, которая обязательна. У кого бывало, что сервис из аутсорса приезжает, а его никуда не принимают? Это не так, конечно, популярно, как сервис-сирота, но все же.

Сервис надо проверять, сервис надо ревьюить, надо менять пароли. У нас был случай, когда нам подкинули сервис, там админка «if login == ‘admin’ && password == ‘admin’…», прям в коде написано. Мы сидим и думаем, и это пишут люди в 2018 году?
Тестирование объема хранилища — тоже нужная штука. Нужно смотреть, что будет на ста тысячах записях, еще до того, как вы этот сервис куда-то в продакшн пустите.

Отправлять сервис на доработку должно быть не стыдно. Когда вы говорите: «Мы этот сервис не примем, у нас есть 20 задач, сделайте их, тогда примем», это нормально. Совесть не должна болеть от того, что вы подставите менеджера или что бизнес потратит деньги. Бизнес потом больше потратит.
У нас был случай, когда мы решили сделать пилотный проект на аутсорсе.

Он был сдан вовремя, и это был единственный критерий качества. Поэтому сделали еще один пилотный проект, уже даже не совсем пилотный. Эти сервисы приняли, административными способами сказали, вот ваш код, вот команда, вот ваш менеджер. Сервисы реально уже начали приносить прибыль. При этом по факту они остались по-прежнему сиротами, никто не понимает, как они работают, и менеджеры всячески от их задач открещиваются.

Есть еще одно отличное понятие — партизанская разработка. Когда какой-то отдел, как правило, это отдел маркетинга, хотят проверить гипотезу, и заказывают сервис целиком на аутсорсе. На него начинает литься трафик, они закрывают документы, подписывают акты с подрядчиком, приходят в эксплуатацию и говорят: «Чуваки, у нас тут есть сервис, на нем уже есть трафик, он нам приносит деньги, давайте его принимать». Мы такие: «Оппа, как же так».

И еще один способ получения сервиса-сироты: когда какая-то команда вдруг оказывается нагруженной, руководство говорит: «Давайте мы передадим сервис этой команды другой команде, у нее нагрузка поменьше». А потом передадим третьей команде, и менеджера поменяем. И в итоге у нас опять сирота.
В чем проблема с сиротами?

Кто не знает, это поднятый в Швеции линейный корабль Wasa, знаменитый тем, что он утонул через 5 минут после спуска на воду. И король Швеции, кстати, никого за это не казнил. Он строился двумя поколениями инженеров, которые не умели строить такие корабли. Закономерный эффект.
Корабль мог утонуть, кстати, гораздо хуже, например, когда на нем уже ехал бы король куда-то в шторм. А так, утонул сразу, по аджайлу это хорошо — провалиться рано.
Если мы провалились рано, обычно проблем не бывает. Например, во время приемки отправили на доработку. А если мы провалились уже в продакшене, когда вложены деньги, то могут быть проблемы. Последствия, как их называют в бизнесе.
Чем опасны сервисы-сироты:
- Сервис может сломаться внезапно.
- Сервис долго чинится или не чинится вообще.
- Проблемы с безопасностью.
- Проблемы с доработками и обновлениями.
- Если ломается важный сервис, страдает репутация компании.
Что делать с сервисами-сиротами?

Еще раз повторюсь, что делать. Во-первых, должна быть документация. 7 лет в Banki.ru меня научили, что тестировщики не должны верить на слово разработчикам, а эксплуатация не должна верить на слово всем. Надо проверять.

Во-вторых, надо писать схемы взаимодействий, потому что бывает, что сервисы, которые приняты не очень хорошо, содержат зависимости, о которых никто не сказал. Например, разработчики поставили сервис на свой ключ к каким-нибудь Яндекс.Картам или к Dadata. У вас кончился бесплатный лимит, все сломалось, и вы не знаете, что случилось вообще. Все такие грабли должны быть описаны: в сервисе используется Dadata, Sms, еще что-то.
В-третьих, работа с техдолгом. Когда вы делаете какие-то костыли или принимаете сервис и говорите, что что-то надо сделать, надо следить, чтобы это делали. Потому что потом может оказаться, что маленькая ямка не такая маленькая, и вы туда провалитесь.
С архитектурными задачами у нас была история как раз про Sphinx. В одном из сервисов Sphinx использовался для того, чтобы вводить списки. Просто список с пагинацией, но при этом он переиндексировался каждую ночь. Он был собран из двух индексов: один индексировался каждую ночь большой, и был еще маленький индекс, который к нему прикручивался. Каждый день, с вероятность 50% либо бомбанет, либо нет, при выкладке индекс бился, и новости у нас переставали обновляться на главной странице. Поначалу это было 5 минут, пока индекс переиндексировался, потом индекс разросся, и в какой-то момент он начал переиндексироваться 40 минут. Когда мы это выпилили, мы вздохнули с облегчением, потому что было понятно, что пройдет еще немного времени, и у нас индекс будет переиндексироваться полный рабочий день. Это будет фейл для нашего портала, восемь часов нет новостей — все, бизнес встал.
План работы с сервисом-сиротой

На самом деле, это очень трудно делать, потому что девопс — это про общение. Хочется быть в хороших отношениях со своими коллегами, а когда ты коллег и менеджеров бьешь регламентами по голове, они могут испытывать противоречивые чувства к тем людям, которые так делают.
Помимо всех этих пунктов, есть еще важная штука: за каждый конкретный сервис, за каждый конкретный участок процедуры деплоя, должны отвечать конкретные люди. Когда людей нет и приходится привлекать каких-то других людей, изучать все это дело, становится тяжко.

Если все это не помогло, и сервис-сирота у вас по-прежнему остался сиротой, его никто не хочет к себе брать, документация не пишется, команда, которую в этот сервис призвали, отказывается что-то делать, есть простой способ — все переделать.
То есть вы берете требования к сервису заново и пишете новый сервис, более лучший, на более лучшей платформе, без странных технологических решений. И мигрируете на него в бою.

У нас была ситуация, когда мы взяли сервис на Yii 1 и поняли, что мы не можем его дальше развивать, потому что у нас кончились разработчики, которые умеют хорошо писать на Yii 1. Все разработчики хорошо пишут на третьем Symfony. Что делать? Выделили время, выделили команду, выделили менеджера, переписали проект и плавненько переключили на него трафик.
После этого старый сервис можно удалить. Это моя любимая процедура, когда из системы управления конфигурациями надо взять и вычистить какой-то сервис и потом пройтись посмотреть, чтобы все тачки на продакшене были погашены, чтобы у разработчиков никаких следов не осталось. Репозиторий в гите остается.
Это все, о чем я хотел рассказать, готов подискутировать, тема холиварная, многие в ней плавали.
На слайдах было про то, что вы унифицировали языки. В качестве примера был ресайзинг картинок. А действительно ли нужно жестко до одного языка? Потому что ресайз картинки на PHP, ну, можно было действительно и на Golang сделать.
На самом деле, это необязательно, как и все практики. Может быть, в каких-то случаях, даже нежелательно. Но надо понимать, что если у вас в компании 50 человек техотдел, их них 45 — PHP-шники, еще 3 — девопсы, которые умеют в Python, Ansible, Puppet и что-нибудь такое, и только один из них пишет на каком-нибудь Go сервис ресайза картинок, то, когда он уходит, экспертиза уходит вместе с ним. И при этом вам нужно будет искать специфического на рынке разработчика, который знает этот язык, особенно, если он редкий. То есть с организационной точки зрения, это проблемно. С точки зрения девопса, вам потребуется не просто склонировать какой-то готовый набор плейбуков, которые вы используете для того, чтобы разворачивать сервисы, а придется их писать заново.
Мы сейчас пилим сервис на Node.js, и это будет как раз площадка рядом для каждого разработчика с отдельным языком. Но мы посидели подумали, что игра стоит свеч. То есть тут вопрос на посидеть и подумать.
Как вы мониторите ваши сервисы? Как собираете и отслеживаете логи?
Логи мы собираем в Elasticsearch и кладем в Kibana, а в зависимости от того, продакшн это или тестовые среды, там используются разные сборщики. Где-то Lumberjack, где-то еще что-то, я уже не помню. И есть еще некоторые места в определенных сервисах, где мы ставим Telegraf и пуляем еще куда-то отдельно.
Как жить с Puppet и Ansible в одной среде?
На самом деле, у нас сейчас две среды, одна — Puppet, другая Ansible. Мы работаем над тем, чтобы их гибридизировать. Ansible — это хорошая среда для первоначальной настройки, Puppet — это плохая штука для первоначальной настройки, потому что требует работы руками непосредственно с площадкой, и Puppet обеспечивает сходимость конфигурации. Это значит, что площадка сама себя поддерживает в актуальном состоянии, а для того, чтобы ансиблизированная машина поддерживалась в актуальном состоянии, нужно на ней все время гонять плейбуки с какой-нибудь периодичностью. Вот такая вот разница.
Как вы поддерживаете совместимость? У вас есть конфиги и в Ansible, и в Puppet?
Это наша большая боль, мы поддерживаем совместимость руками и думаем, как бы сейчас от всего этого куда-то перейти. У нас получается, что Puppet накатывает пакеты и поддерживает там какие-то ссылки, а Ansible у нас, например, накатывает код и подгоняет туда свежие конфиги приложений.
В презентации было про разные версии Ruby. Какое решение?
Мы в одном месте с этим столкнулись, и нам приходится все время держать это в голове. Мы просто выключили ту часть, которая работала на том Ruby, который был несовместим с приложениями, и держали ее отдельно.
В этом году конференция пройдет 7 декабря в «Технополисе». До 11 ноября мы принимаем заявки на доклады. нам, если вы хотите выступить.
Регистрация для участников открыта, присоединяйтесь!
Источник: habr.com
