

В интернете сотни статей о том, какую пользу приносит анализ поведения клиентов. Чаще всего это касается сферы ритейла. От анализа продуктовых корзин, ABC и XYZ анализа до retention-маркетинга и персональных предложений. Различные методики используются уже десятилетиями, алгоритмы продуманы, код написан и отлажен — бери и используй. В нашем случае возникла одна фундаментальная проблема — мы в ISPsystem занимаемся разработкой ПО, а не ритейлом.
Меня зовут Денис и на данный момент я отвечаю за бэкенд аналитических систем в ISPsystem. И это история о том, как мы с моим коллегой — ответственным за визуализацию данных — попытались посмотреть на наши программные продукты сквозь призму этих знаний. Начнем, как обычно, с истории.
В начале было слово, и слово было «Попробуем?»
В тот момент я работал разработчиком в R&D отделе. Все началось с того, что здесь, на Хабре, Данил прочитал — инструмент для анализа переходов пользователей в приложениях. Идею его применения у нас я воспринял несколько скептически. В качестве примеров разработчики библиотеки приводили анализ приложений, где целевое действие было четко определено — оформление заказа или иная вариация того, как заплатить компании-владельцу. У нас же продукты поставляются on-premise. То есть пользователь сначала покупает лицензию, и только после начинает свой путь в приложении. Да, у нас есть демо-версии. В них можно опробовать продукт, чтобы не брать кота в мешке.
Но большая часть наших продуктов ориентирована на рынок хостинга. Это крупные клиенты, и о возможностях продукта их консультирует отдел бизнес-девелоперов. Из этого же следует, что на момент покупки наши клиенты уже знают в решении каких задач им поможет наше ПО. Их маршруты в приложении должны совпадать с заложенным в продукт CJM, а UX-решения помогут с них не сбиваться. Спойлер: так происходит не всегда. Знакомство с библиотекой было отложено… но ненадолго.
Все изменилось с релизом нашего стартапа — — платформы для создания интернет-магазина из аккаунта в Instagram. В этом приложении пользователю предоставлялся двухнедельный период на бесплатное использование всей функциональности. После нужно было принять решение, оформлять ли подписку. И это как нельзя хорошо ложилось в концепцию «маршрут-целевое действие». Было решено: пробуем!
Первые результаты или откуда брать идеи
Мы с командой разработки буквально за день подключили продукт к системе сбора событий. Скажу сразу, что в ISPsystem используется своя система сбора событий о посещении страниц, однако ничто не мешает применять для тех же целей Яндекс.Метрику, которая позволяет бесплатно выгружать сырые данные. Были изучены примеры использования библиотеки, и спустя неделю сбора данных мы получили граф переходов.
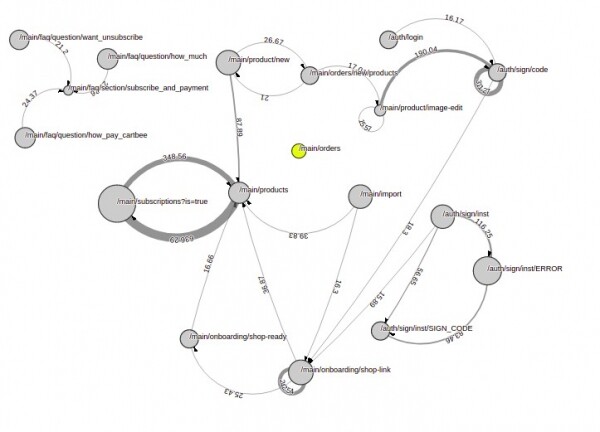
Граф переходов. Основная функциональность, остальные переходы убраны для наглядности
Вышло прямо как в примере: планарно, понятно, красиво. Из этого графа мы смогли выявить самые частые маршруты и переходы, на которых люди задерживаются дольше всего. Это позволило нам понять следующее:
- Вместо крупного CJM, который охватывает с десяток сущностей, активно используются всего две. Необходимо дополнительно направлять пользователей в нужные нам места при помощи UX-решений.
- На некоторых страницах, задуманных UX-проектировщиками как сквозные, люди проводят неоправданно много времени. Нужно выяснять, что является стоп-элементами на конкретной странице и корректировать это.
- После 10 переходов 20% людей начинали уставать и бросать сессию в приложении. И это с учетом того, что у нас в приложении было целых 5 страниц онбординга! Нужно выявлять страницы, на которых пользователи регулярно бросают сессии, и сокращать путь до них. Еще лучше: выявлять любые регулярные маршруты и позволять совершать быстрый переход из страницы-источника в страницу-назначение. Что-то общее с ABC-анализом и анализом брошенных корзин, не находите?
И здесь мы пересмотрели свое отношение к применимости этого инструмента для on-premise продуктов. Было решено проанализировать активно продающийся и использующийся продукт — . Он значительно сложнее, сущностей на порядок больше. Мы с волнением ждали, каким же окажется граф переходов.
О разочарованиях и воодушевлениях
Разочарование #1
Это был конец рабочего дня, конец месяца и конец года одновременно — 27 декабря. Данные были накоплены, запросы написаны. Оставались секунды до того, как все обработается, и мы сможем взглянуть на результат своих трудов, чтобы узнать, с чего начнётся следующий рабочий год. R&D отдел, продакт-менеджер, UX-дизайнеры, тимлид, разработчики собрались перед монитором, чтобы увидеть как выглядят пути пользователей в их продукте, но… мы увидели это:

Граф переходов, построенный библиотекой Retentioneering
Воодушевление #1
Сильно-связный, десятки сущностей, неочевидные сценарии. Понятно было лишь только то, что новый рабочий год начнется не с анализа, а с изобретения способа упростить работу с таким графом. Но меня не покидало чувство, что все намного проще, чем кажется. И после пятнадцати минут изучения исходников Retentioneering удалось экспортировать построенный граф в формат dot. Это позволило выгрузить граф в другой инструмент — Gephi. А уже там раздолье для анализа графов: укладки, фильтры, статистики — только и делай, что настраивай в интерфейсе нужные параметры. С этой мыслью мы ушли на новогодние выходные.
Разочарование #2
После выхода на работу оказалось, что пока все отдыхали, наши клиенты изучали продукт. Да так усердно, что в хранилище появились события, которых раньше не было. Это означало то, что нужно актуализировать запросы.
Немного предыстории для осознания всей печальности этого факта. У нас передаются как размеченные нами события (например, нажатия на некоторые кнопки), так и URL страниц, которые посещал пользователь. В случае с Cartbee работала модель «одно действие — одна страница». Но с VMmanager ситуация была уже совершенно другой: на одной странице могли открываться несколько модальных окон. В них пользователь мог решать различные задачи. Например, URL:
/host/item/24/ip(modal:modal/host/item/ip/create)
значит, что на странице «IP-адреса» пользователь добавлял IP-адрес. И здесь видны сразу две проблемы:
- В URL есть какой-то path parameter — ID виртуальной машины. Нужно его исключать.
- В URL есть идентификатор модального окна. Нужно как-то «распаковывать» такие URL.
Другая проблема заключалась в том, что в тех самых размеченных нами событиях были параметры. Например, попасть на страницу с информацией о виртуальной машине из списка можно было пятью различными способами. Соответственно, событие отправлялось одно, но с параметром, которые указывал, каким из способов пользователь осуществил переход. Таких событий было множество, и все параметры разные. А у нас вся логика извлечения данных на диалекте SQL для Clickhouse. Запросы на 150-200 строк начинали казаться чем-то привычным. Проблемы окружали нас.
Воодушевление #2
Одним ранним утром Данил, грустно скроля запрос вторую минуту, предложил мне: «А давай пайплайны обработки данных напишем?» Мы подумали и решили, что раз уж делать, то нечто вроде ETL. Чтобы и фильтровало сразу, и из других источников нужные данные подтягивало. Так родился наш первый аналитический сервис с полноценным бэкендом. Он реализует пять основных стадий обработки данных:
- Выгрузка событий из хранилища «сырых» данных и подготовка их к обработке.
- Уточнение — «распаковка» тех самых идентификаторов модальных окон, параметров событий и прочих уточняющих событие деталей.
- Обогащение (от слова «стать богатым») — дополнение событий данными из сторонних источников. На тот момент сюда входила только наша биллинговая система BILLmanager.
- Фильтрация — процесс отсеивания событий, которые искажают результаты анализа (события со внутренних стендов, выбросы и т.д.).
- Выгрузка полученных событий в хранилище, которое мы назвали чистыми данными.
Теперь поддерживать актуальность можно было добавляя правила обработки события или даже группы похожих событий. Например, c того момента мы ни разу не актуализировали распаковку URL. Хотя, за это время добавилось несколько новых вариаций URL. Они соответствуют уже заложенным в сервис правилам и корректно обрабатываются.
Разочарование #3
Как только мы приступили к анализу, мы осознали, почему граф был настолько связным. Дело в том, что практически каждая N-грамма содержала в себе переходы, которые невозможно осуществить через интерфейс.
Началось небольшое расследование. Меня смущало, что не было неосуществимых переходов в рамках одной сущности. Значит, это не баг системы сбора событий или нашего ETL-сервиса. Складывалось ощущение, что пользователь одновременно работает в нескольких сущностях, не переходя из одной в другую. Как такого добиться? Используя разные вкладки в браузере.
При анализе Cartbee нас спасла его специфика. Приложение использовали с мобильных устройств, где работать из нескольких вкладок попросту неудобно. Здесь же — десктоп и, пока выполняется задача в одной сущности, резонно хочется занять это время настройками или мониторингом состояния в другой. А чтобы не терять прогресс, просто открываешь еще одну вкладку.
Воодушевление #3
Коллеги из фронтед-разработки научили систему сбора событий различать вкладки. Можно было приступать к анализу. И мы приступили. Как и ожидалось, CJM не совпадали с реальными путями: пользователи проводили много времени на страницах-каталогах, бросали сессии и вкладки в самых неожиданных местах. При помощи анализа переходов мы смогли найти проблемы в некоторых билдах Mozilla. В них, из-за особенностей реализации, пропадали элементы навигации или отображались полупустые страницы, которые должны быть доступны только администратору. Страница открывалась, но контент с бэкенда не приходил. Подсчет переходов позволял оценить, какие фичи реально используются. Цепочки давали возможность понять, как пользователь получил ту или иную ошибку. Данные позволяли проводить тестирование на основе поведения пользователей. Это был успех, затея была не напрасной.
Автоматизация аналитики
На одной из демонстраций результатов мы показывали, как применяется Gephi для анализа графов. В этом инструменте данные о переходах можно вывести в таблицу. И руководитель отдела UX сказал одну очень важную мысль, которая повлияла на развитие всего направления аналитики поведения в компании: «А давайте сделаем так же, но в Tableau и с фильтрами — так будет удобнее».
Тогда я подумал: а почему бы и нет, Retentioneering хранит все данные в pandas.DataFrame структуре. А это уже, по большому счету, таблица. Так появился еще один сервис: Data Provider. Он не только делал из графа таблицу, но и рассчитывал, насколько страница и привязанная к ней функциональность пользуются популярностью, как влияет на удержание пользователей, насколько пользователи задерживаются на ней, с каких страниц чаще всего уходят пользователи. А использование визуализации в Tableau настолько сократило затраты на изучение графа, что время итерации анализа поведения в продукте сократилось практически вдвое.
О том, как данная визуализация применяется и какие выводы позволяет сделать расскажет Данил.
Больше таблиц богу таблиц!
В упрощенном виде задача была сформулирована так: отобразить граф переходов в Tableau, обеспечить возможность фильтрации, сделать максимально понятным и удобным.
Рисовать ориентированный граф в Tableau не очень-то хотелось. Да и в случае успеха выигрыш, по сравнению с Gephi, представлялся неочевидным. Нужно было что-то гораздо проще и доступнее. Таблица! Ведь граф легко представить в виде строк таблицы, где каждая строка — ребро вида «источник-назначение». Более того, такая таблица у нас уже была заботливо подготовлена средствами Retentioneering и Data Provider. Дело оставалось за малым: вывести таблицу в Tableau и пошарить отчет.

К слову о том, как все любят таблицы
Однако здесь мы столкнулись еще с одной проблемой. Что делать с источником данных? Подключить pandas.DataFrame было нельзя, такого коннектора у Tableau нет. Поднимать отдельную базу для хранения графа казалось слишком радикальным решением с туманными перспективами. А варианты локальных выгрузок не подходили из-за необходимости постоянных ручных операций. Мы полистали список доступных коннекторов, и взгляд упал на пункт , который сиротливо ютился в самом низу.
У Tableau богатый выбор коннекторов. Нашли и тот, который решил нашу задачу
Что за зверь? Несколько новых открытых вкладок в браузере — и стало понятно, что этот коннектор позволяет получать данные при обращении по URL. Backend для расчета самих данных уже был почти готов, оставалось подружить его с WDC. Несколько дней Денис изучал документацию и воевал с механизмами Tableau, а затем скинул мне ссылку, которую я вставил в окно подключения.
Форма подключения к нашему WDC. Денис сделал свой фронт и позаботился о безопасности
Через пару минут ожидания (данные рассчитываются динамически при запросе) появилась таблица:
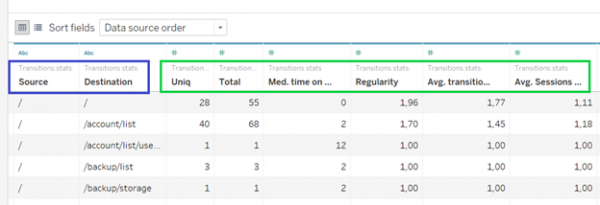
Так выглядит сырой массив данных в интерфейсе Tableau
Как и было обещано, каждая строка такой таблицы представляла собой ребро графа, то есть направленный переход пользователя. Также она содержала несколько дополнительных характеристик. Например, количество уникальных юзеров, общее количество переходов и другие.
Можно было бы вывести эту таблицу в отчет как есть, щедро посыпать фильтров и отправить инструмент в плавание. Звучит логично. Что можно сделать с таблицей? Но это не наш путь, ведь мы делаем не просто таблицу, а инструмент для анализа и принятия продуктовых решений.
Как правило, при анализе данных человек хочет получить ответы на вопросы. Отлично. С них и начнем.
- Какие переходы самые частые?
- Куда уходят с конкретных страниц?
- Сколько в среднем проводят на этой странице до того, как ушли?
- Как часто делают переход из A в B?
- А на каких страницах заканчивается сессия?
Каждый из отчетов или их комбинация должны позволять пользователю самостоятельно находить ответы на эти вопросы. Ключевая стратегия здесь — дать инструмент для самостоятельной работы. Это полезно как для уменьшения нагрузки на отдел аналитики, так и для уменьшения времени на принятие решения — ведь больше не нужно идти в Youtrack и заводить задачу аналитику, достаточно просто открыть отчет.
Что же у нас получилось?
Куда чаще всего расходятся с дашборда?
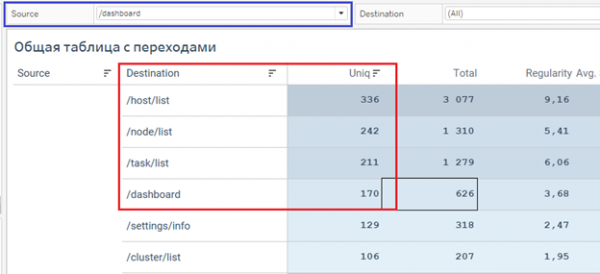
Фрагмент нашего отчета. После дашборда все уходили либо на список ВМ либо на список нод
Возьмем общую таблицу с переходами и отфильтруем по странице источника. Чаще всего с дашборда уходят на список виртуальных машин. Причем, колонка Regularity подсказывает, что это повторяющееся действие.
Откуда приходят в список кластеров?
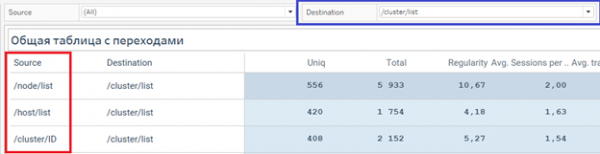
Фильтры в отчетах работают в обе стороны: можно узнать откуда ушли, а можно куда шли
Из примеров видно, что даже наличие двух простых фильтров и ранжирование строк по значениям позволяют быстро получать информацию.
Спросим кое-что посложнее.
Откуда пользователи чаще всего бросают сессию?
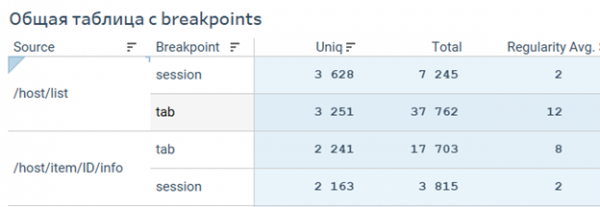
Пользователи VMmanager часто работают в отдельных вкладках
Для этого нам нужен отчет данные которого агрегированы по источникам переходов. А в качестве назначений были взяты так называемые breakepoints – события, которые послужили концом цепочки переходов.
Здесь важно заметить, что это может быть, как конец сессии, так и открытие новой вкладки. Из примера видно, что цепочка чаще всего заканчивается на таблице со списком виртуальных машин. При этом характерное поведение — это переход в другую вкладку, что согласуется с ожидаемым паттерном.
Пользу этих отчетов мы прежде всего проверили на себе, когда подобным образом проводили анализ , еще одного нашего продукта. С появлением таблиц и фильтров гипотезы проверялись быстрее, а глаза уставали меньше.
При разработке отчетов мы не забыли и про визуальное оформление. При работе с таблицами такого объема это немаловажный фактор. Например, использовали спокойную гамму цветов, легкий для восприятия для цифр, цветовую подсветку строк в соответствии с числовыми значениями характеристик. Такие детали улучшают пользовательский опыт и повышают вероятность успешного взлета инструмента внутри компании.
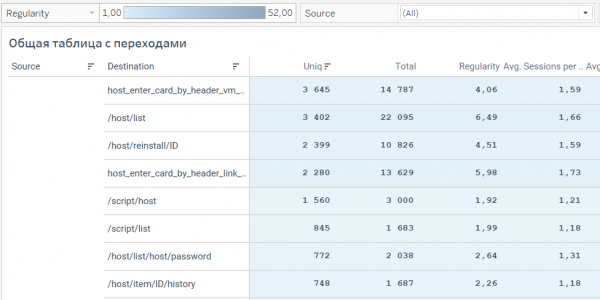
Таблица получилась довольно объемной, но как мы надеемся, не перестала быть читаемой
Отдельно стоит сказать про обучение наших внутренних клиентов: продуктологов и UX-проектировщиков. Для них специально были подготовлены мануалы с примерами анализа и подсказками при работе с фильтрами. Ссылки на мануалы мы вставили прямо в страницы отчетов.
Мануал мы сделали просто в виде презентации в Google Docs. Средства Tableau позволяют отображать веб-страницы прямо внутри книги с отчетами.
Вместо послесловия
Что в сухом остатке? Мы относительно быстро и дешево смогли получить инструмент на каждый день. Да, определённо это не замена самого графа, тепловой карты кликов или веб-визора. Но такие отчеты существенно дополняют перечисленные инструменты, дают пищу для размышлений и новых продуктовых и интерфейсных гипотез.
Эта история послужила лишь началом для развития аналитики в ISPsystem. За полгода появилось еще семь новых сервисов, включая цифровые портреты пользователя в продукте и сервис для формирования баз для Look-alike таргетинга, но о них в следующих эпизодах.
Источник: habr.com
