

Случаются ситуации, когда в таблицу без первичного ключа или какого-то другого уникального индекса по недосмотру попадают полные клоны уже существующих записей.

Например, пишутся в PostgreSQL COPY-потоком значения хронологической метрики, а потом внезапный сбой, и часть полностью идентичных данных приходит повторно.
Как избавить базу от ненужных клонов?
Когда PK не помощник
Самый простой способ — вообще не допустить возникновения такой ситуации. Например, накатить-таки PRIMARY KEY. Но это возможно не всегда без увеличения объема хранимых данных.
Например, если точность исходной системы выше, чем точность поля в БД:
metric | ts | data
--------------------------------------------------
cpu.busy | 2019-12-20 00:00:00 | {"value" : 12.34}
cpu.busy | 2019-12-20 00:00:01 | {"value" : 10}
cpu.busy | 2019-12-20 00:00:01 | {"value" : 11.2}
cpu.busy | 2019-12-20 00:00:03 | {"value" : 15.7}
Заметили? Отсчет вместо 00:00:02 записался в базу с ts на секунду раньше, но остался вполне валидным с прикладной точки зрения (ведь значения data — разные!).
Конечно, можно сделать PK(metric, ts) — но тогда мы будем получать конфликты вставки для валидных данных.
Можно сделать PK(metric, ts, data) — но это сильно увеличит его объем, которым мы и пользоваться-то не будем.
Поэтому самый правильный вариант — сделать обычный неуникальный индекс (metric, ts) и разбираться с проблемами постфактум, если они все-таки возникнут.
«Война клоническая началась»
Случилась какая-то авария, и теперь нам предстоит уничтожить клон-записи из таблицы.

Давайте смоделируем исходные данные:
CREATE TABLE tbl(k text, v integer);
INSERT INTO tbl
VALUES
('a', 1)
, ('a', 3)
, ('b', 2)
, ('b', 2) -- oops!
, ('c', 3)
, ('c', 3) -- oops!!
, ('c', 3) -- oops!!
, ('d', 4)
, ('e', 5)
;Тут у нас трижды дрогнула рука, залип Ctrl+V, и вот…
Сначала давайте поймем, что таблица у нас может быть очень немаленькой, поэтому после того, как мы найдем все клоны, нам желательно буквально «тыкать пальцем», чтобы удалять конкретные записи без повторного их поиска.
И такой способ есть — это , физическому идентификатору конкретной записи.
То есть, прежде всего, нам надо собрать ctid записей в разрезе полного контента строки таблицы. Самый просто вариант — скастовать всю строку в text:
SELECT
T::text
, array_agg(ctid) ctids
FROM
tbl T
GROUP BY
1;
t | ctids
---------------------------------
(e,5) | {"(0,9)"}
(d,4) | {"(0,8)"}
(c,3) | {"(0,5)","(0,6)","(0,7)"}
(b,2) | {"(0,3)","(0,4)"}
(a,3) | {"(0,2)"}
(a,1) | {"(0,1)"}
А можно ли не кастовать?В принципе — можно в большинстве случаев. Пока вы не начнете использовать в этой таблице поля типов без оператора равенства:
CREATE TABLE tbl(k text, v integer, x point);
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T;
-- ERROR: could not identify an equality operator for type tbl
Ага, сразу видим, что если в массиве оказалось больше одной записи — это все и есть клоны. Давайте оставим только их:
SELECT
unnest(ctids[2:])
FROM
(
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T::text
) T;unnest
------
(0,6)
(0,7)
(0,4)Любителям писать покорочеМожно написать и вот так:
SELECT
unnest((array_agg(ctid))[2:])
FROM
tbl T
GROUP BY
T::text;Поскольку само значение сериализованной строки нам неинтересно, то мы его просто выкинули из возвращаемых столбцов подзапроса.
Осталось всего немного — заставить DELETE использовать полученный нами набор:
DELETE FROM
tbl
WHERE
ctid = ANY(ARRAY(
SELECT
unnest(ctids[2:])
FROM
(
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T::text
) T
)::tid[]);Проверим себя:
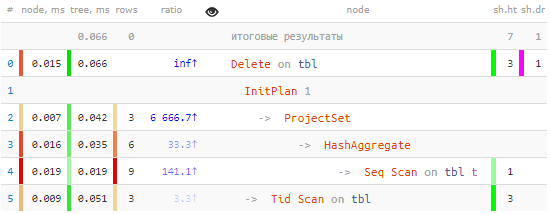
Да, все правильно: наши 3 записи отобрались за единственный Seq Scan всей таблицы, а Delete-узел использовал для поиска данных однократный проход с помощью Tid Scan:
-> Tid Scan on tbl (actual time=0.050..0.051 rows=3 loops=1)
TID Cond: (ctid = ANY ($0))Если зачистили много записей, .
Проверим для таблицы побольше и с большим количеством дублей:
TRUNCATE TABLE tbl;
INSERT INTO tbl
SELECT
chr(ascii('a'::text) + (random() * 26)::integer) k -- a..z
, (random() * 100)::integer v -- 0..99
FROM
generate_series(1, 10000) i; 
Итак, способ успешно работает, но применять надо с известной осторожностью. Потому что на каждую удаляемую запись приходится одно чтение страницы данных в Tid Scan, и одно — в Delete.
Источник: habr.com
